Downloaded 208 times

























A data warehouse is a subject-oriented, integrated, time-variant collection of data that supports management's decision-making processes. It contains data extracted from various operational databases and data sources. The data is cleaned, transformed, integrated and loaded into the data warehouse for analysis. A data warehouse uses a multidimensional model with facts and dimensions to allow for complex analytical and ad-hoc queries from multiple perspectives. It is separately administered from operational databases to avoid impacting transaction processing systems and allow optimized access for decision support.
Definition of Data Warehouse, its properties: subject-oriented, integrated, time-variant, nonvolatile.
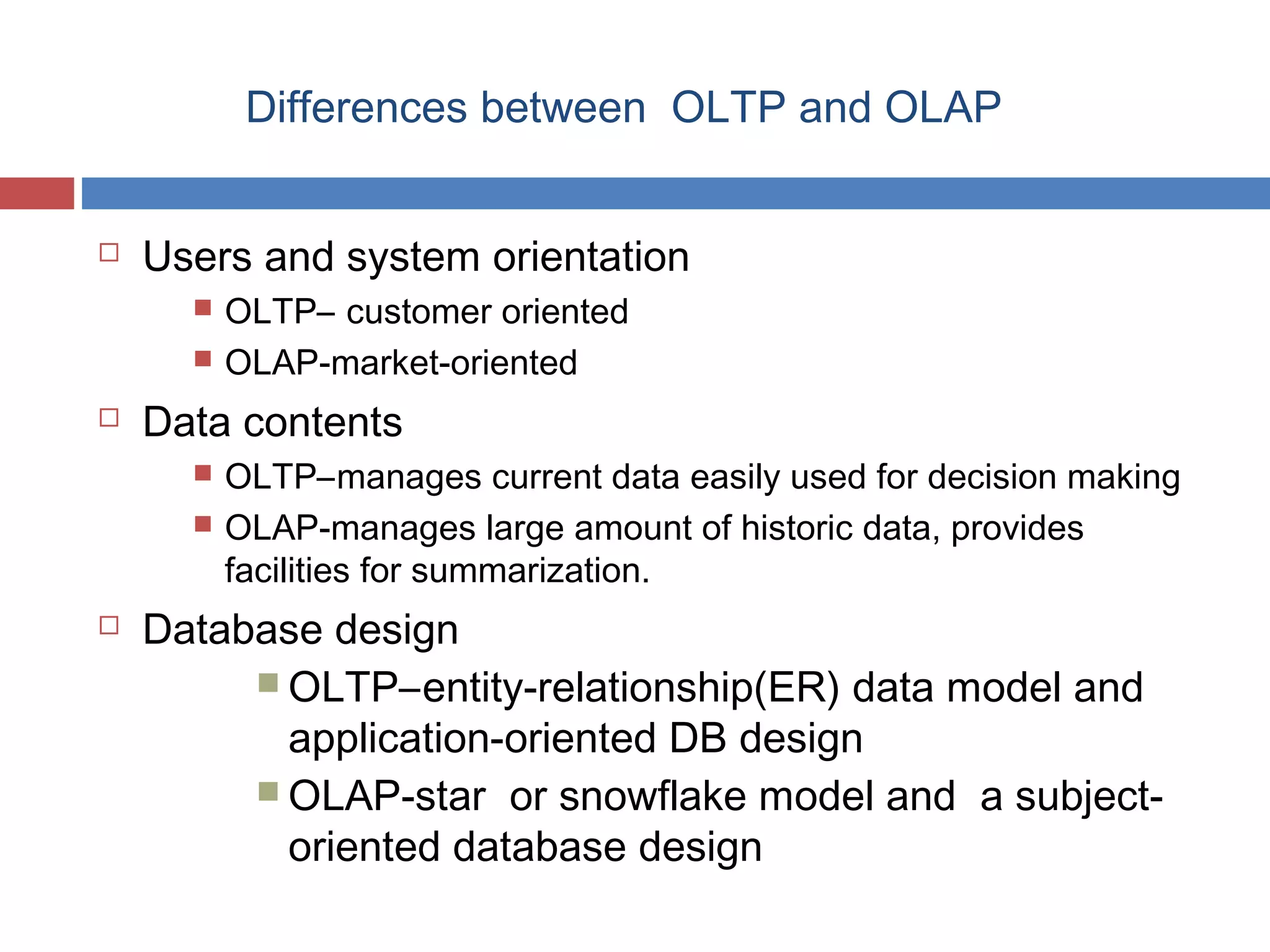
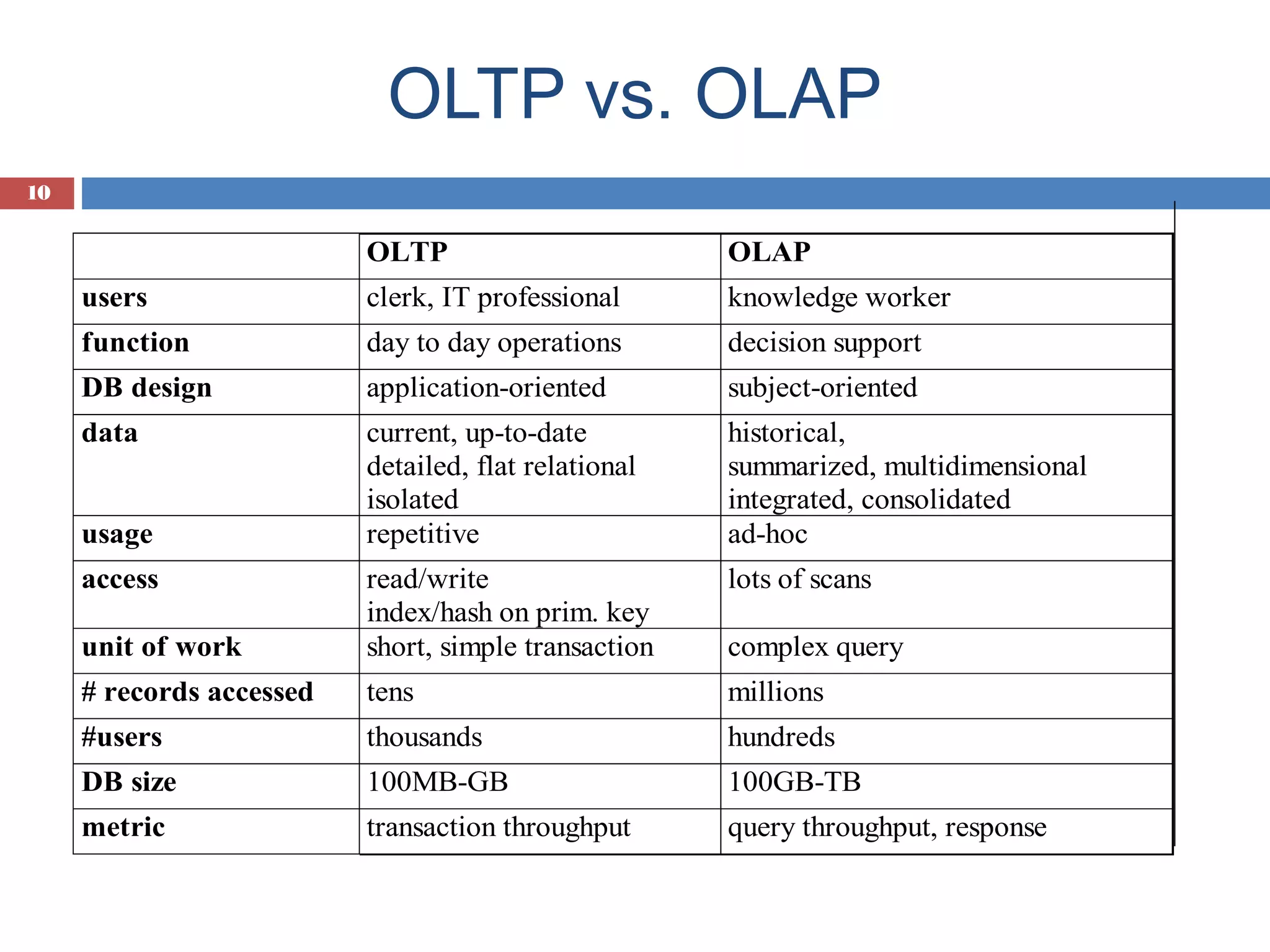
Differences between OLTP and OLAP systems focusing on functionality, data handling, user roles.
Performance benefits of OLTP vs OLAP systems, supporting decision-making with historical data.
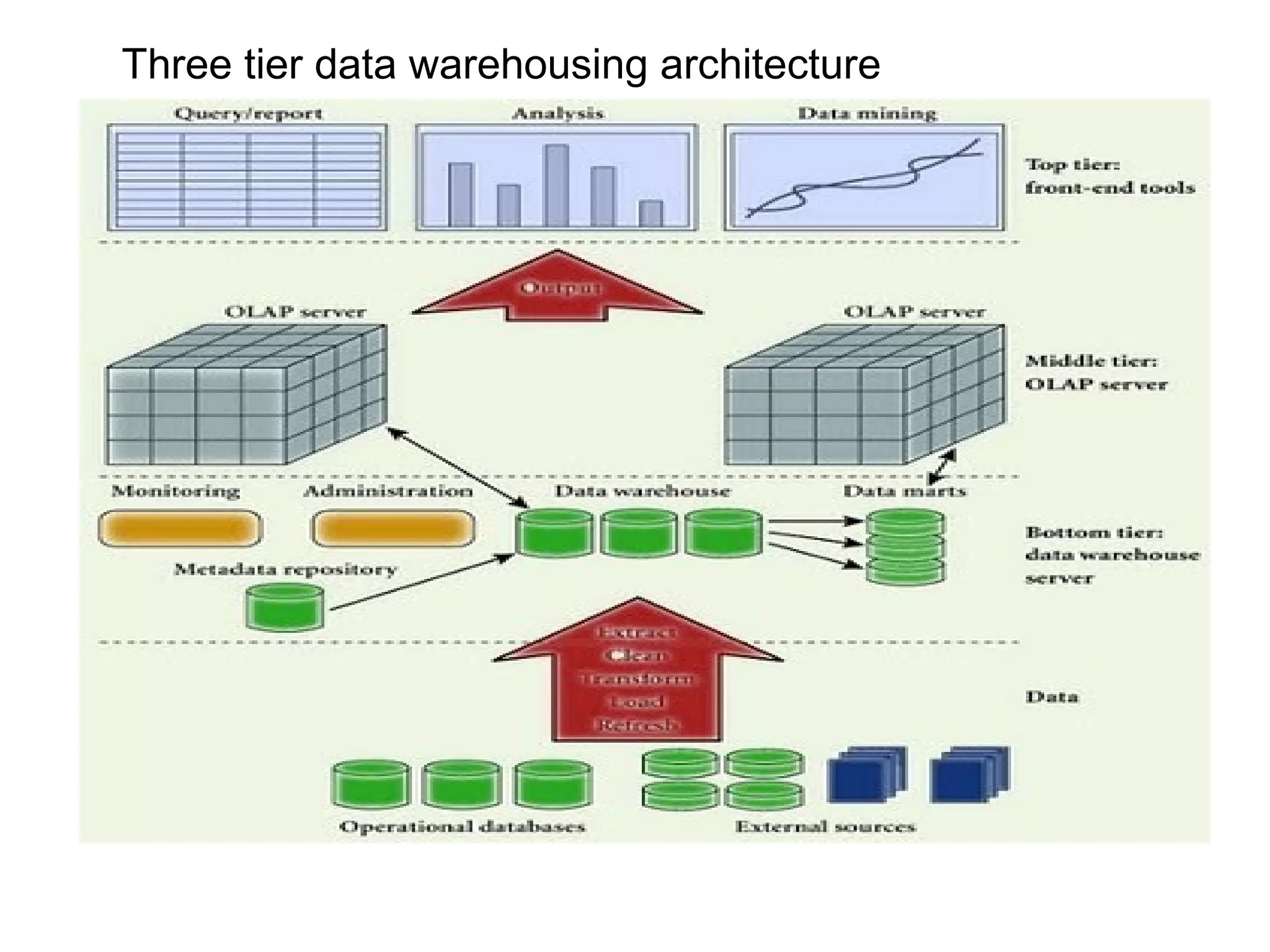
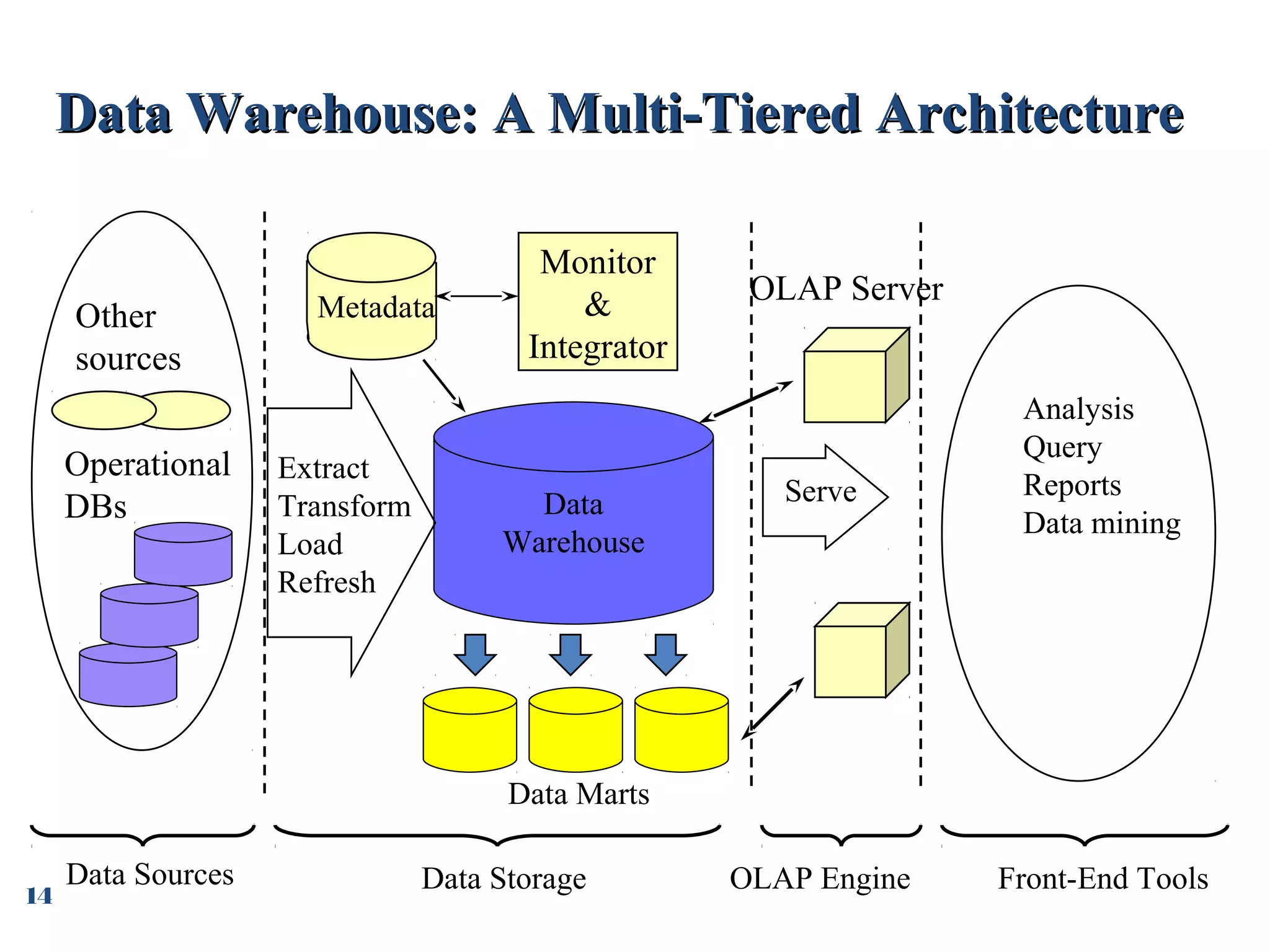
Overview of multi-tiered architecture, including data extraction, storage, OLAP servers, and front-end tools.
Enterprise warehouse, data mart types, and the concept of virtual warehouses.
ETL functions: extraction, cleaning, transformation, loading, and refreshing data for warehouses.
Definition and importance of metadata, including structure, operational data lineage, and performance.
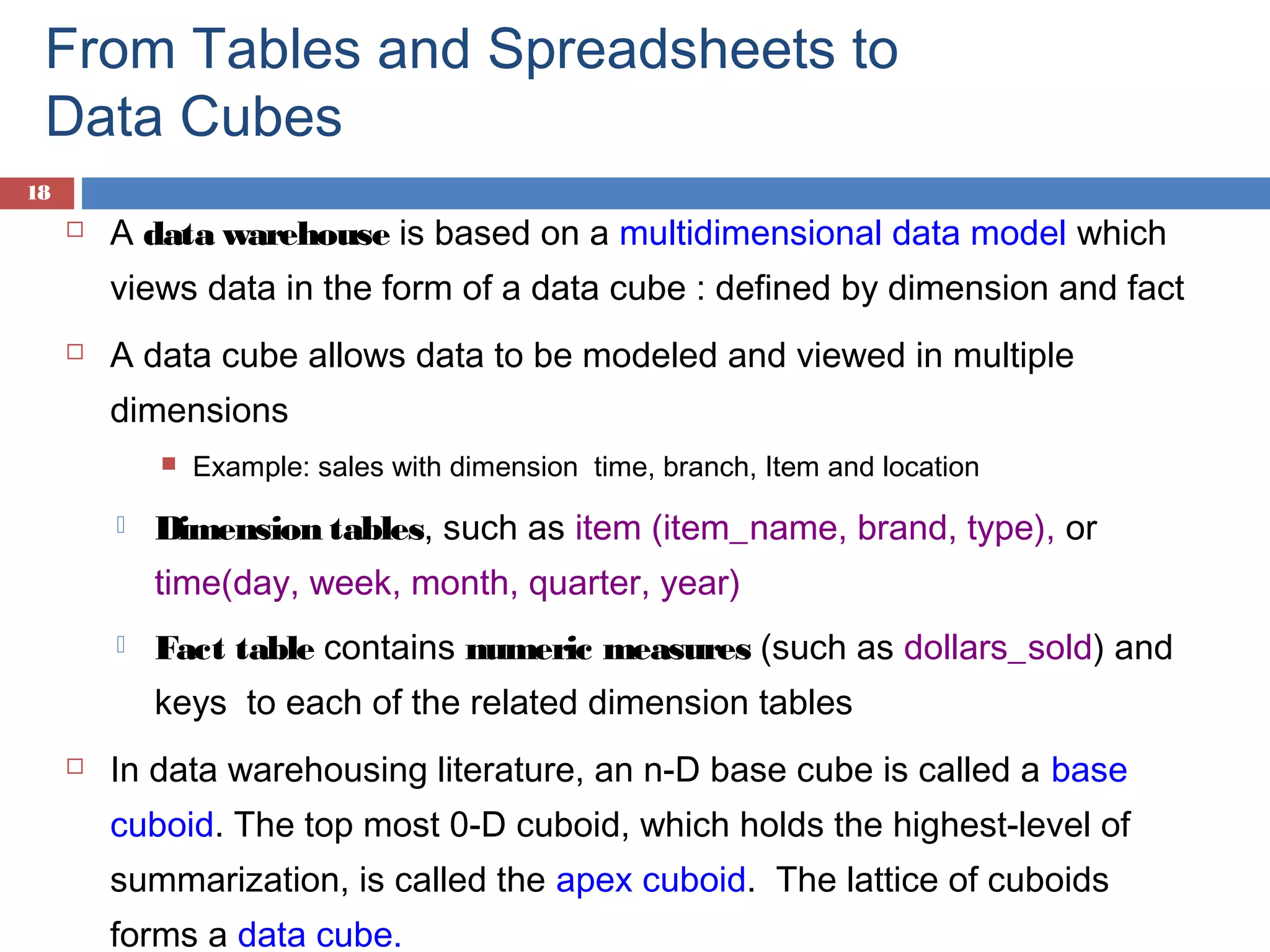
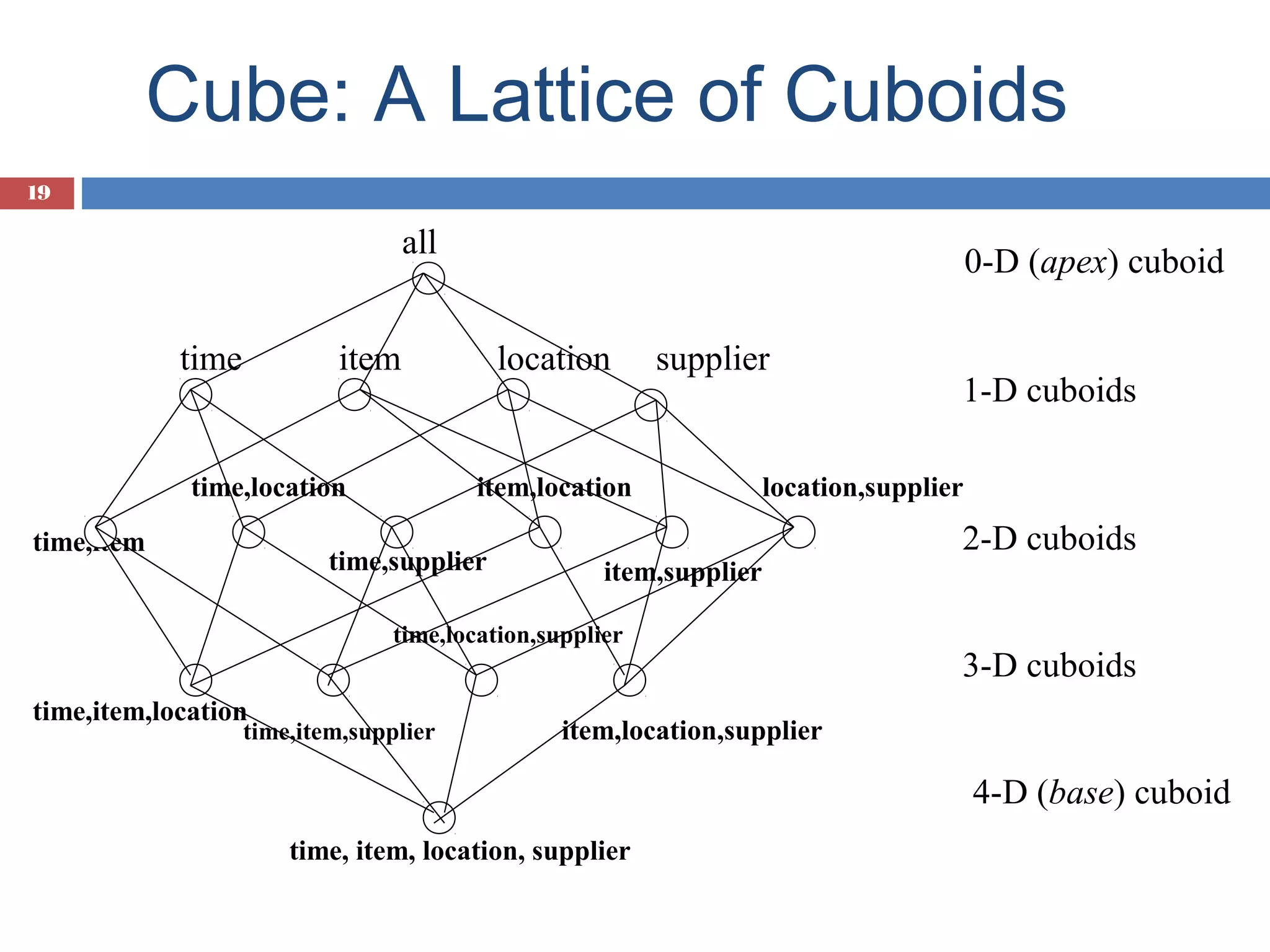
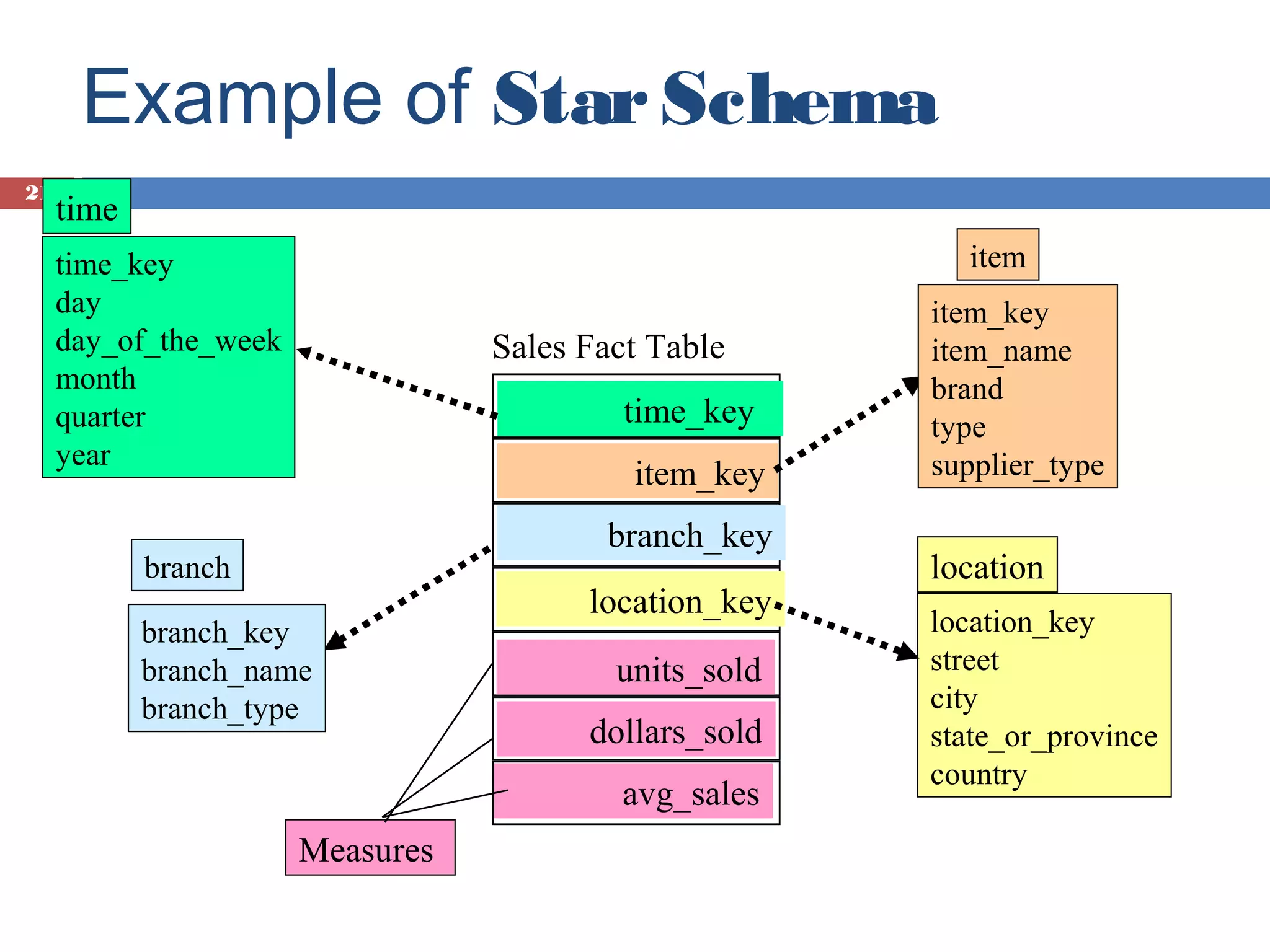
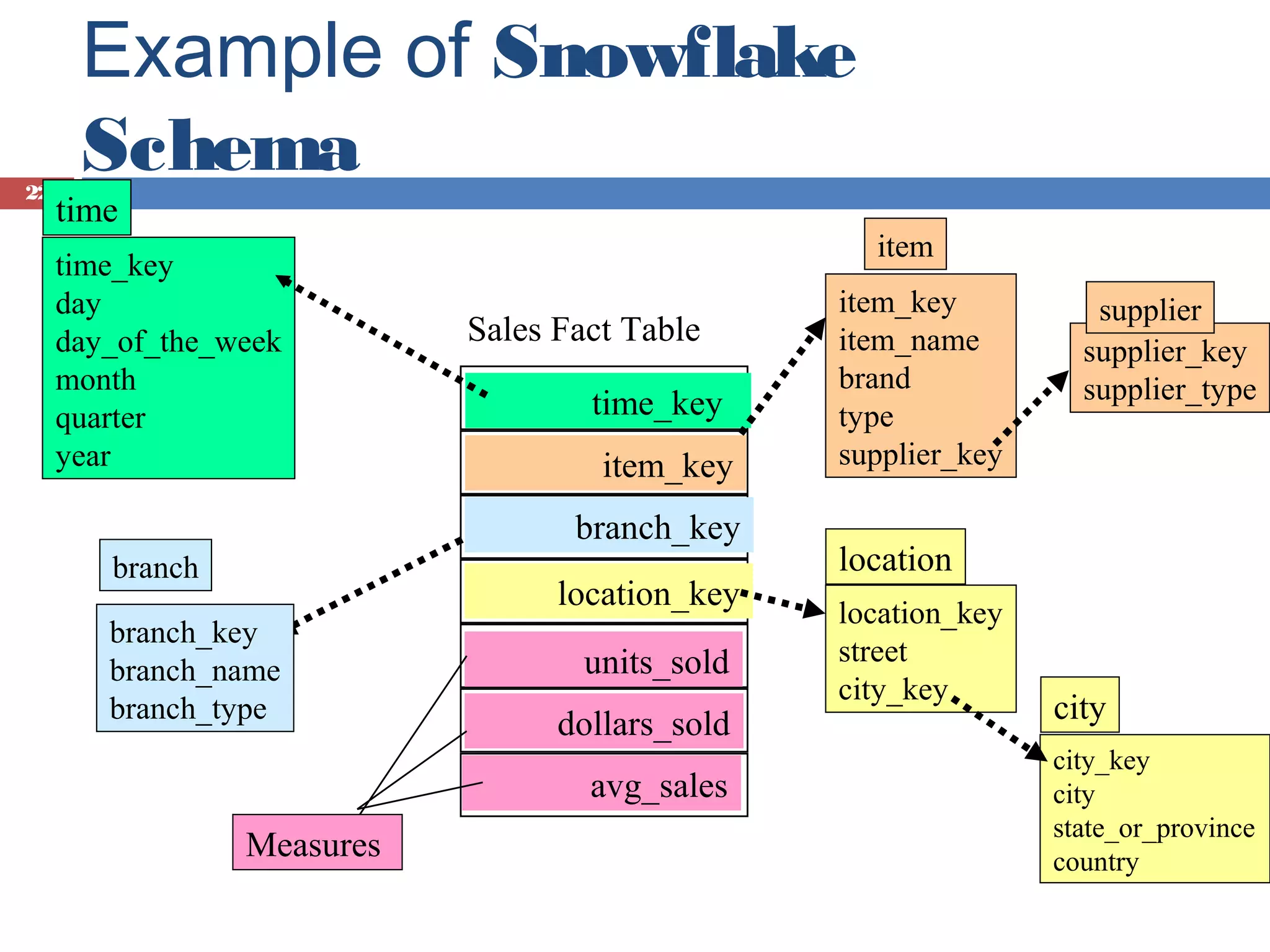
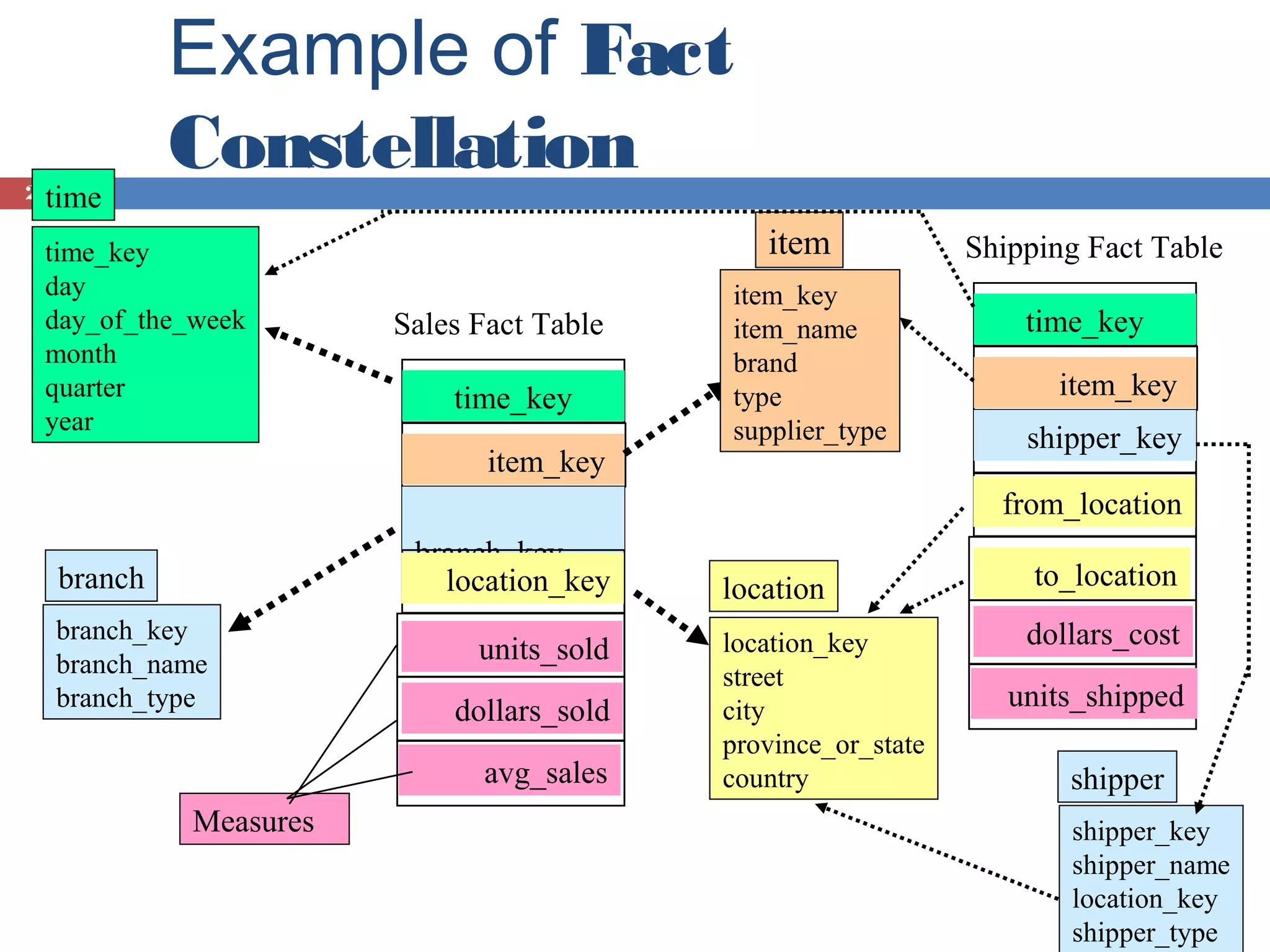
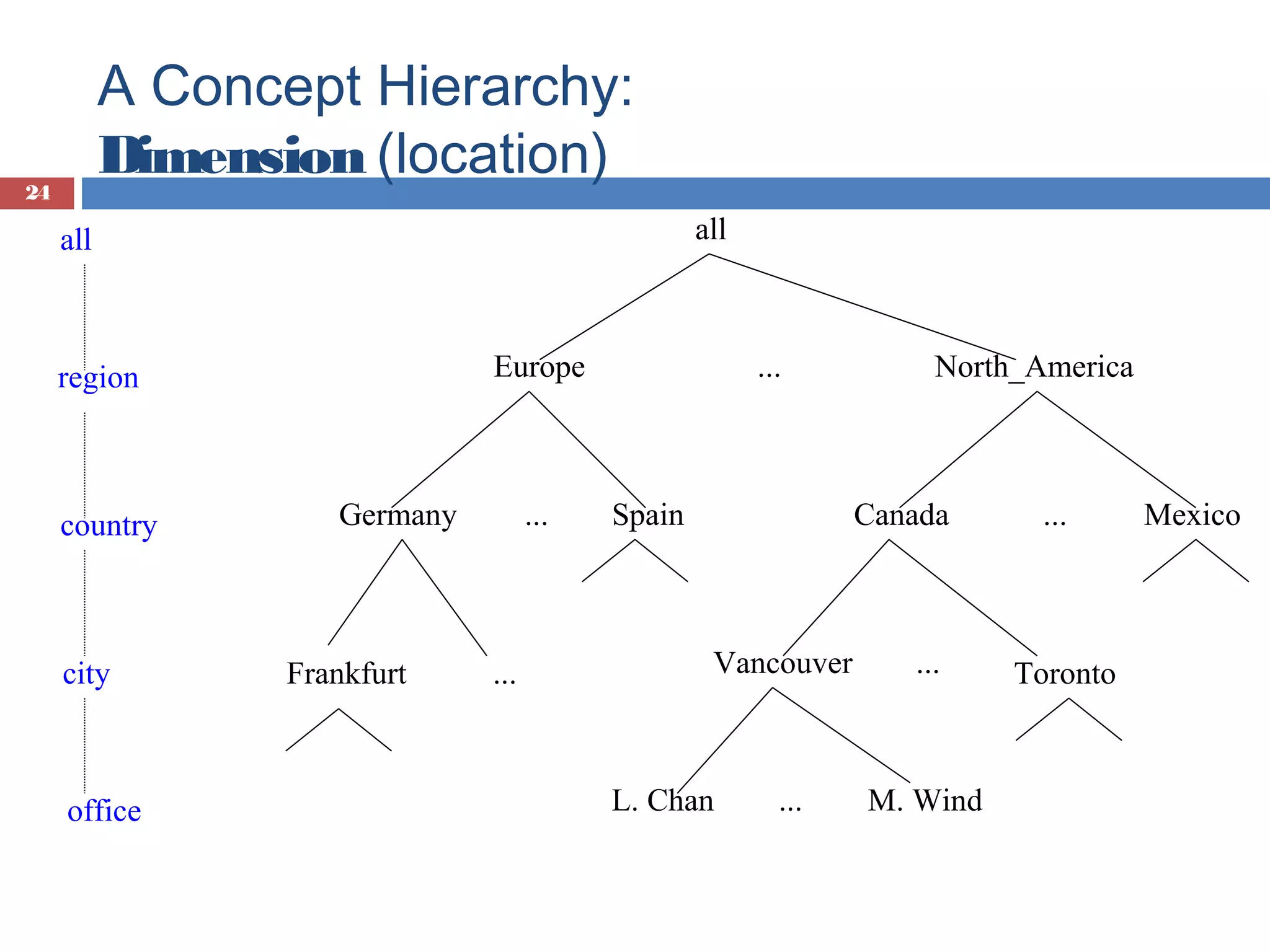
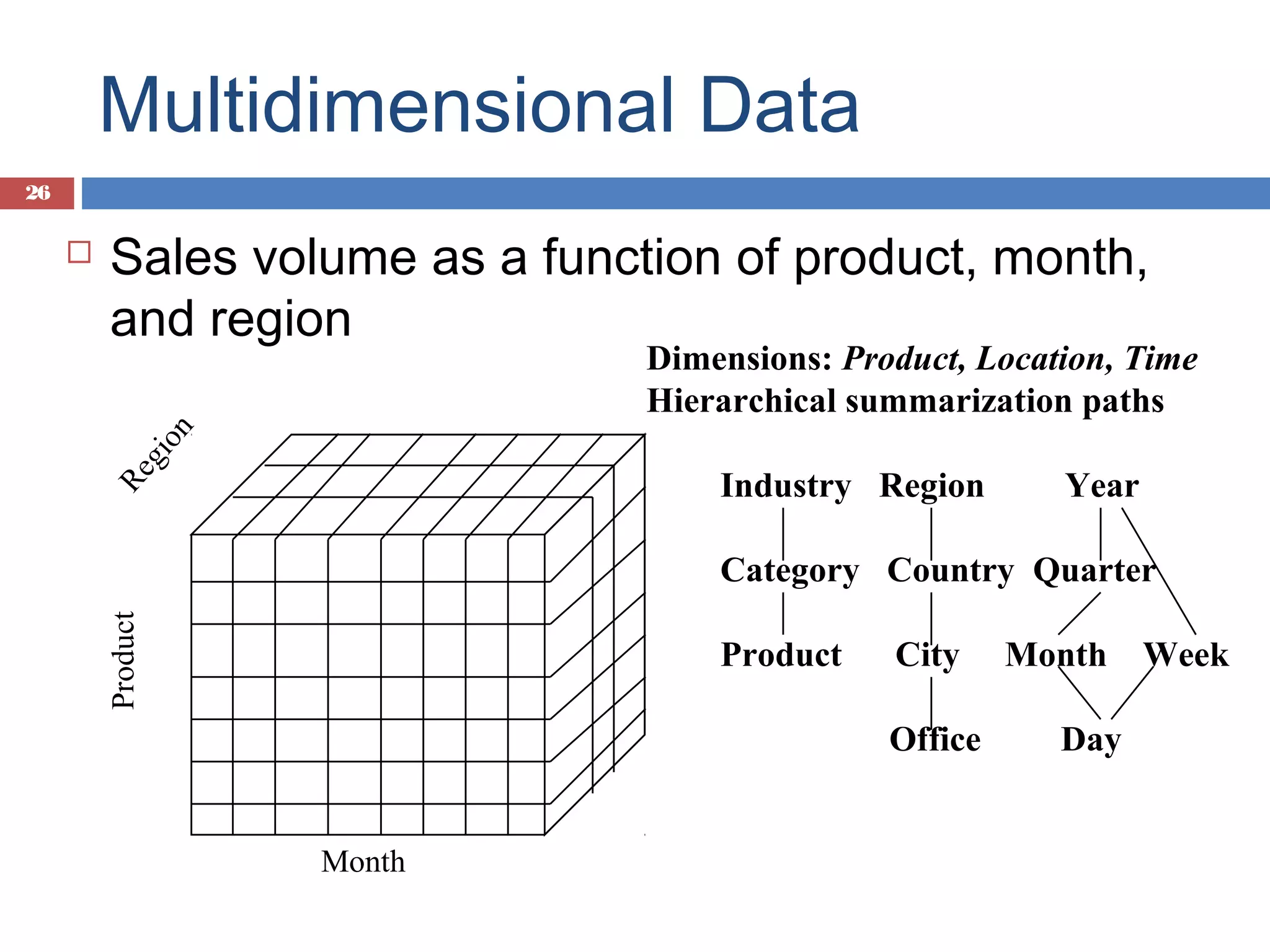
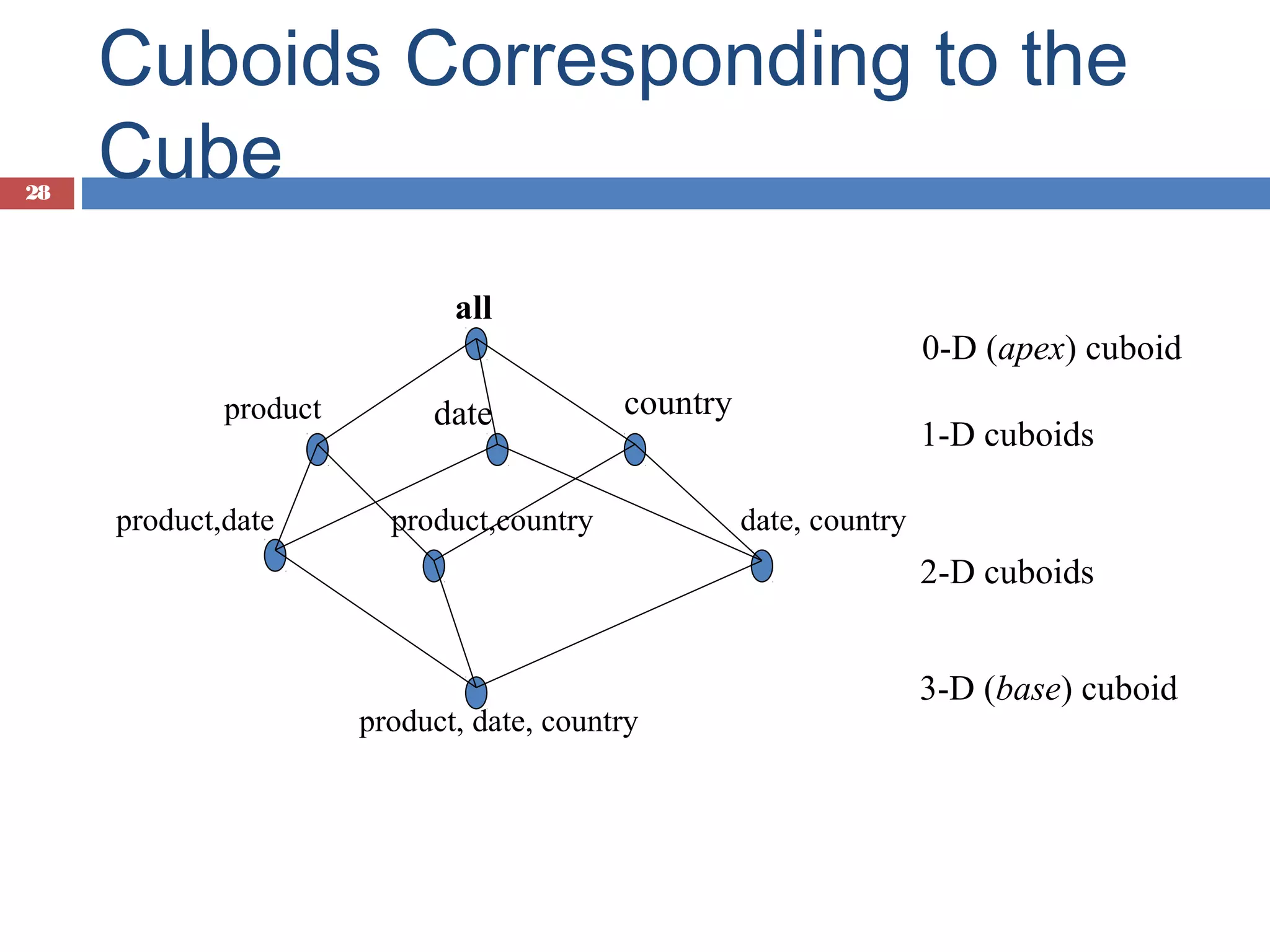
Introduction to data cubes, dimensions vs facts, cube structures including star and snowflake schemas.
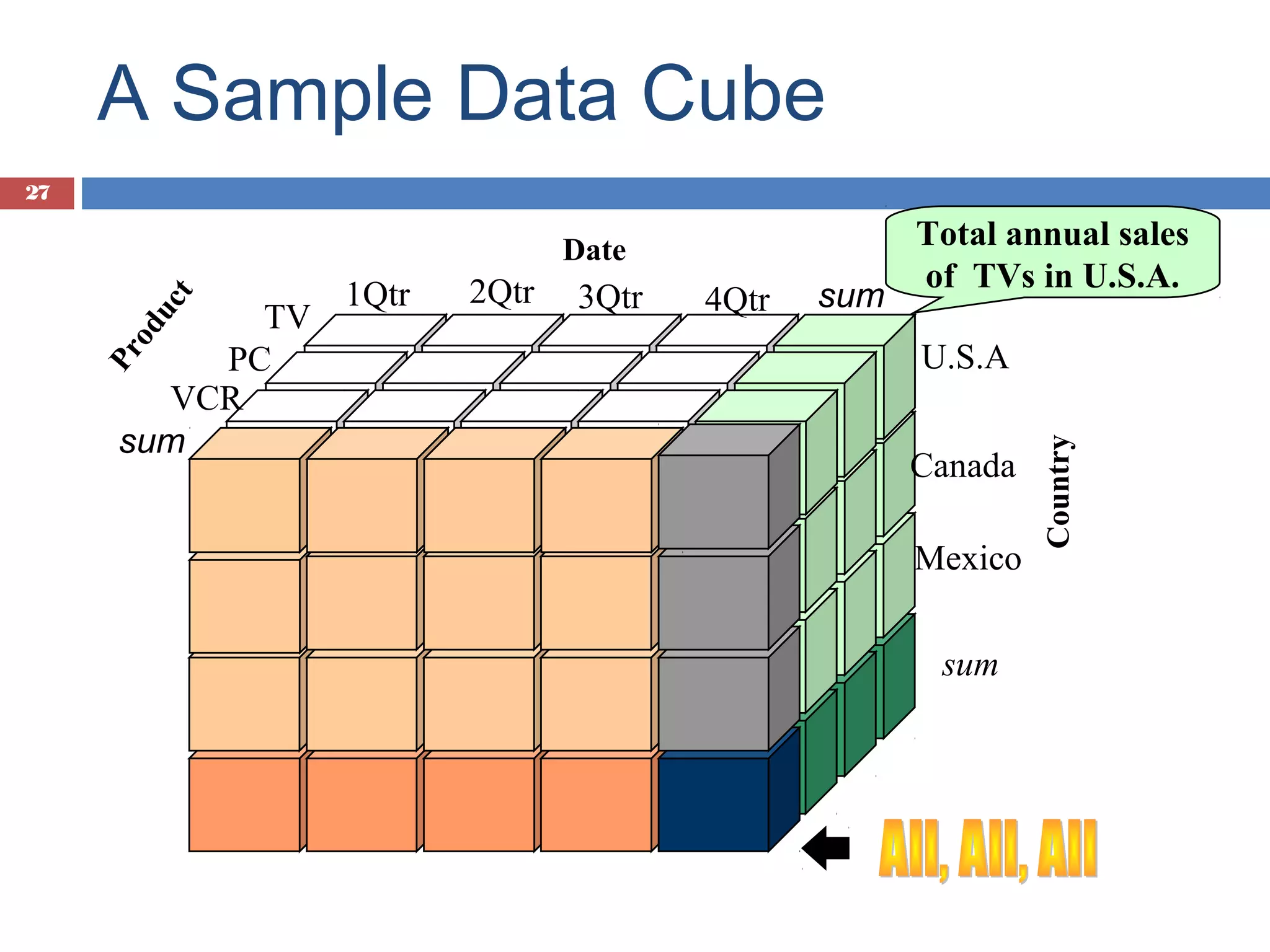
Types of measures: distributive, algebraic, holistic, with examples and a sample data cube illustration.
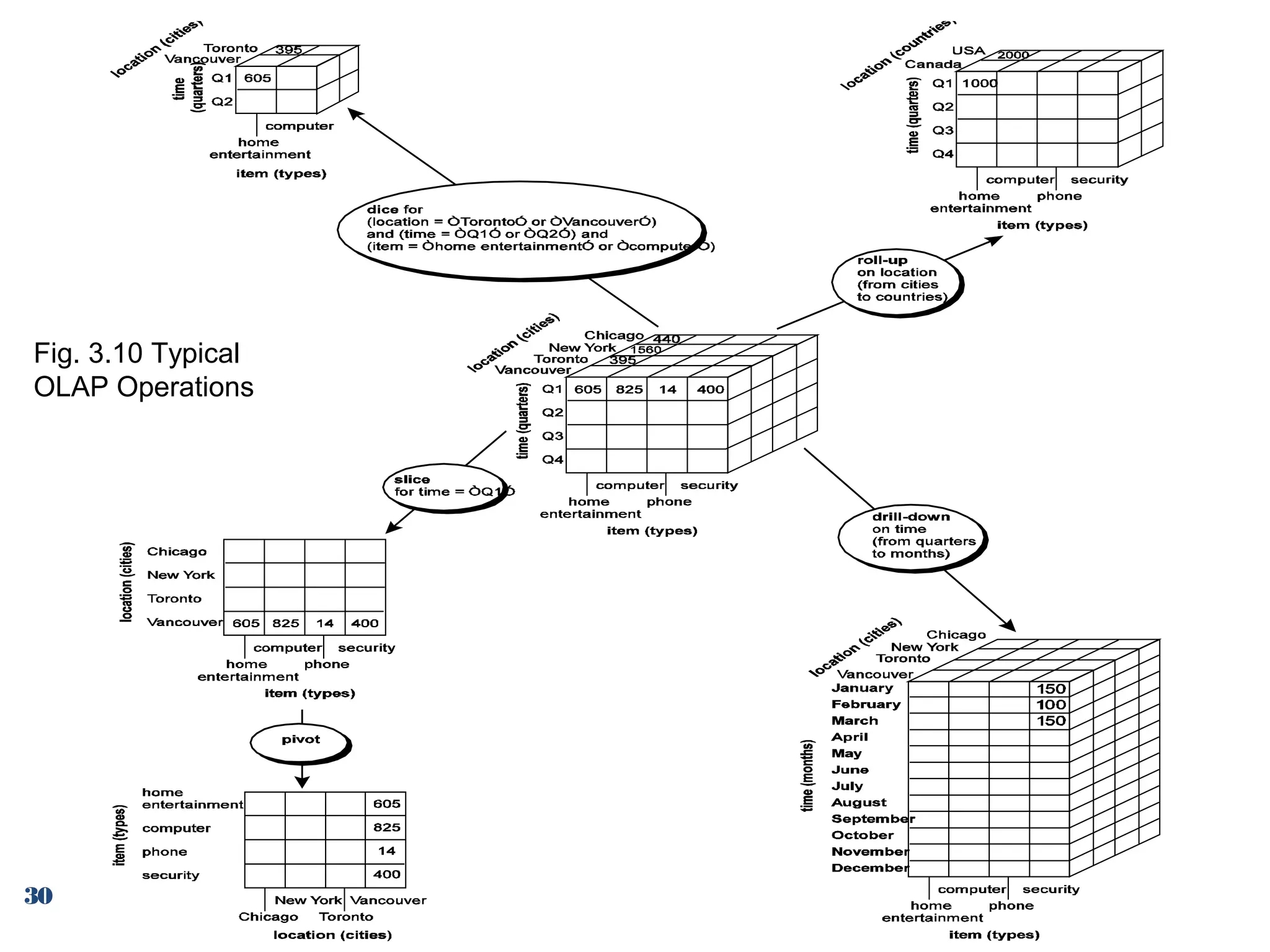
Common OLAP operations: roll-up, drill-down, slice, dice, pivot, and other functionalities.
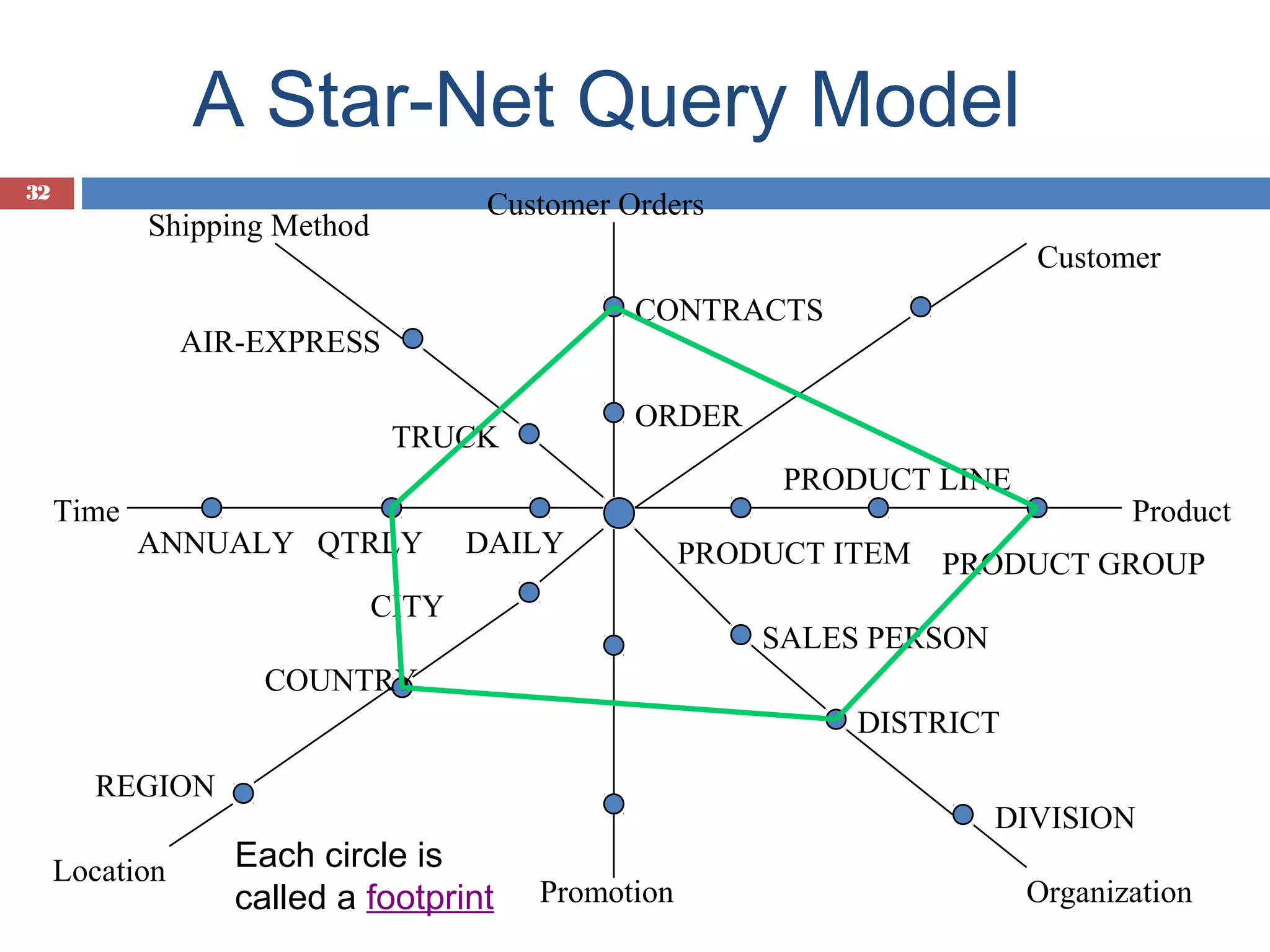
How querying in multidimensional databases works using a star-net model for data visualization.
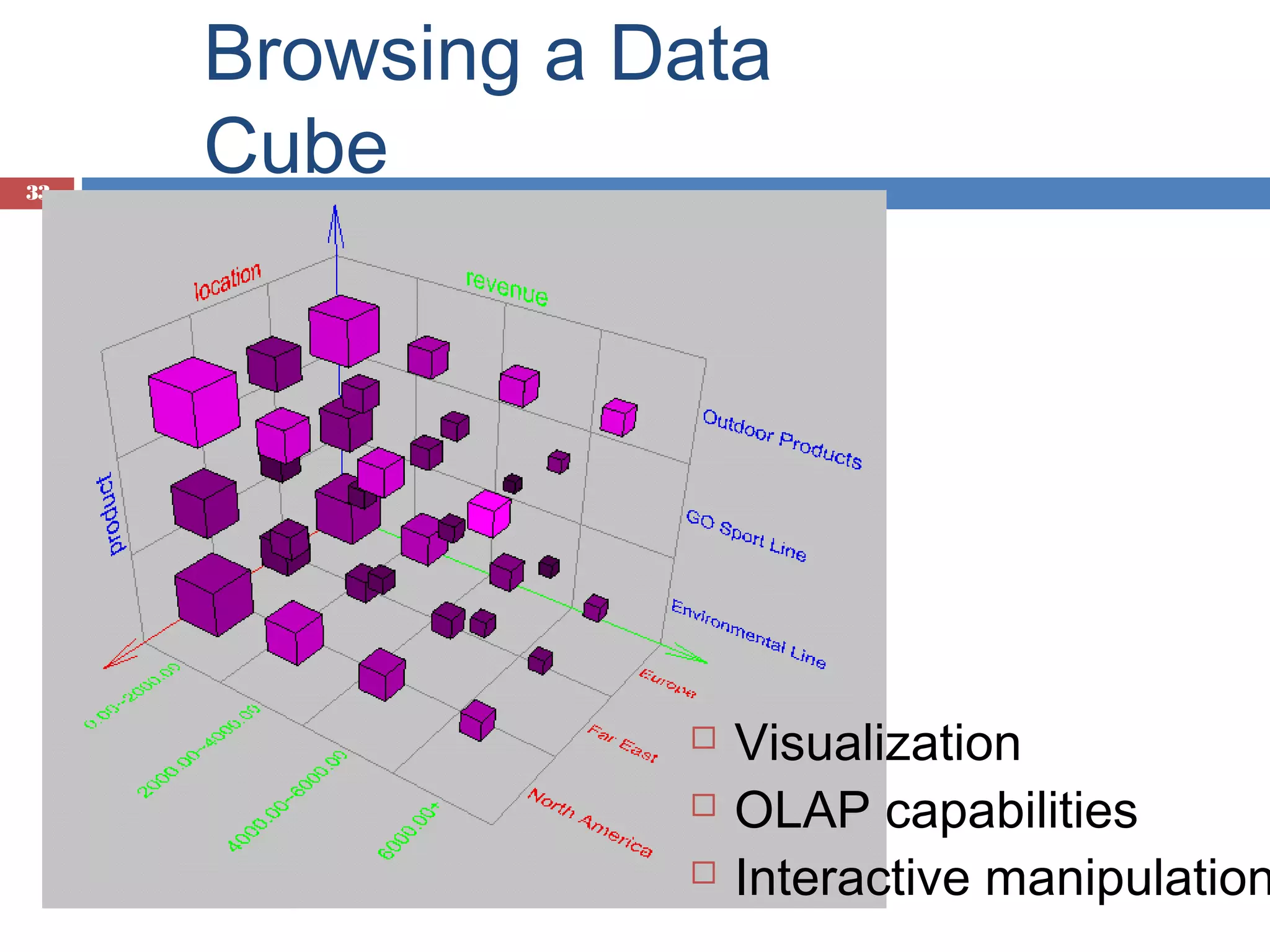
Capabilities for browsing and visualizing data cubes within an OLAP framework.
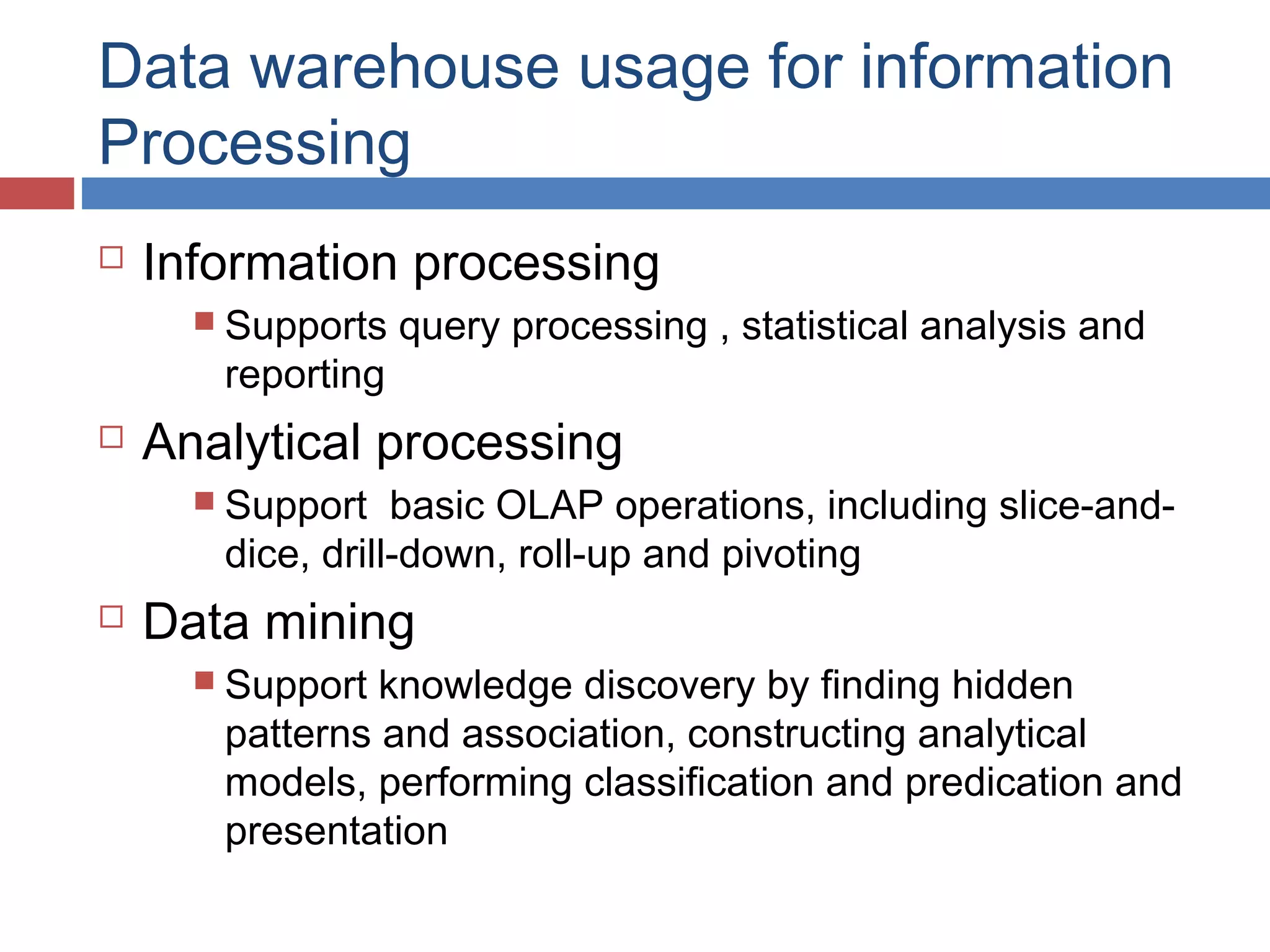
Design principles, frameworks for effective data warehouse implementation, usage in OLAP, and OLAM integration.



































































