![© Hortonworks Inc. 2014
Apache Hadoop YARN
Best Practices
Zhijie Shen
zshen [at] hortonworks.com
Varun Vasudev
vvasudev [at] hortonworks.com
Page 1](https://image.slidesharecdn.com/w-525-hall1-shen-v2-140617161539-phpapp02/75/Apache-Hadoop-YARN-best-practices-1-2048.jpg)








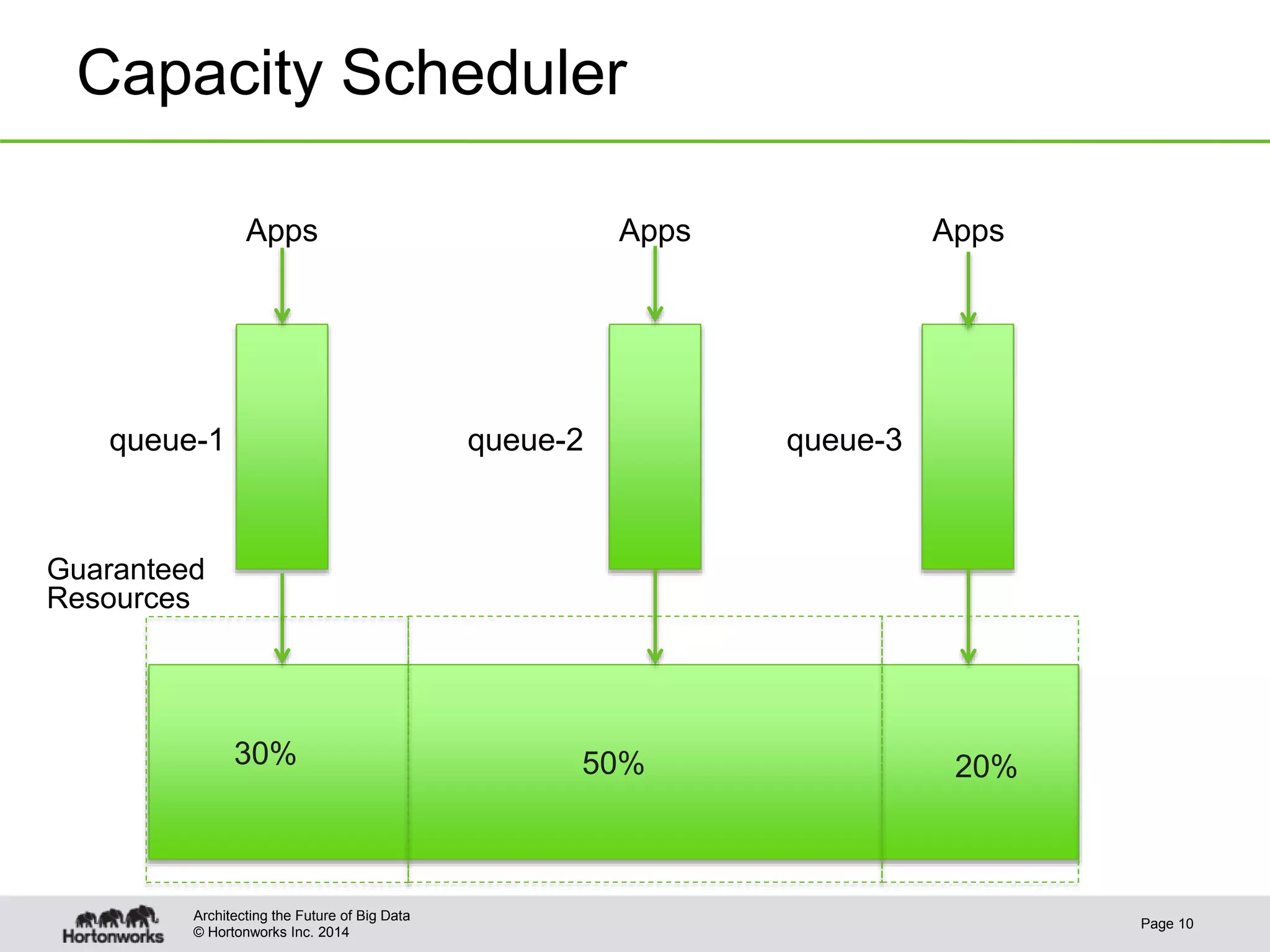









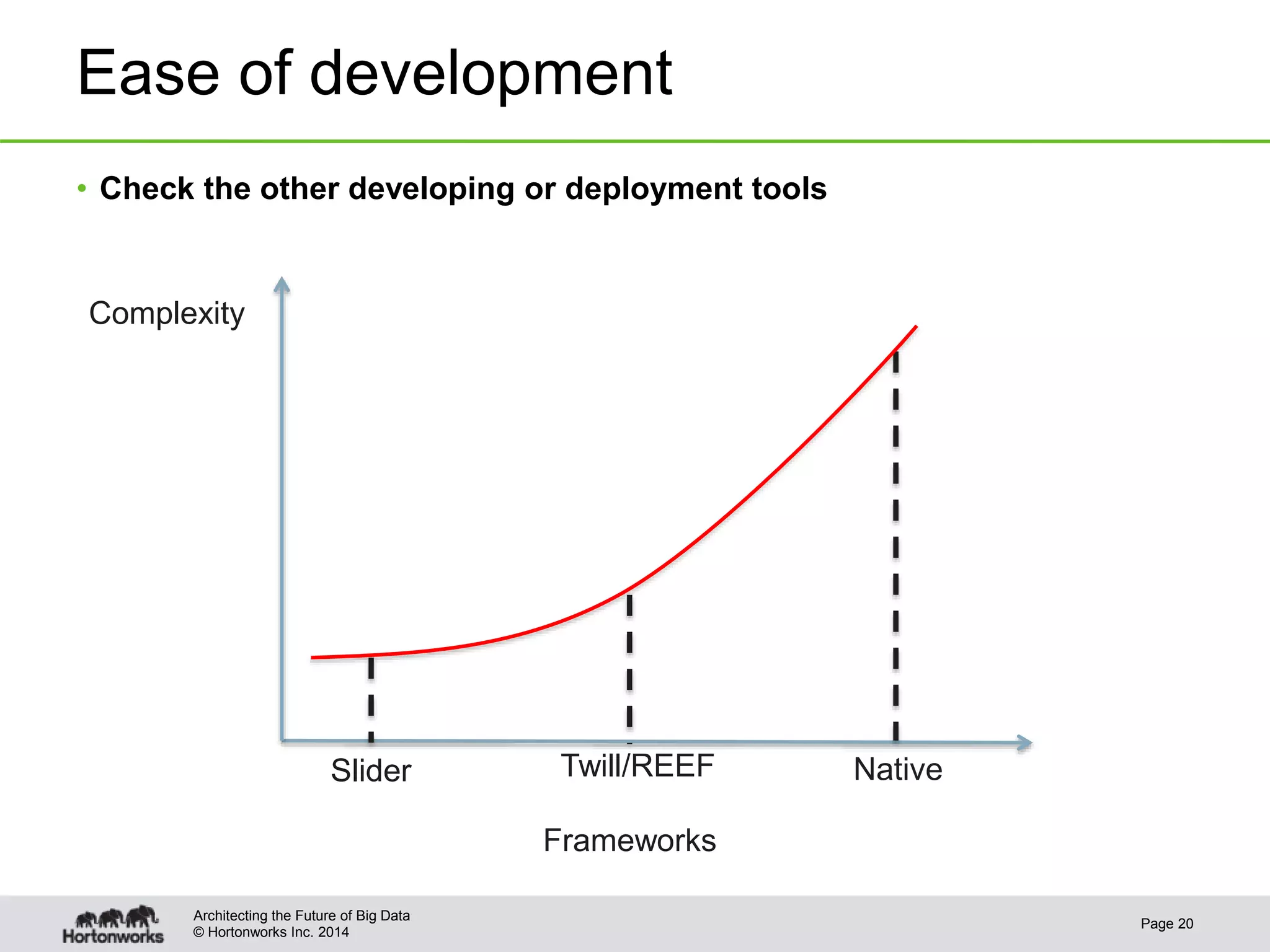
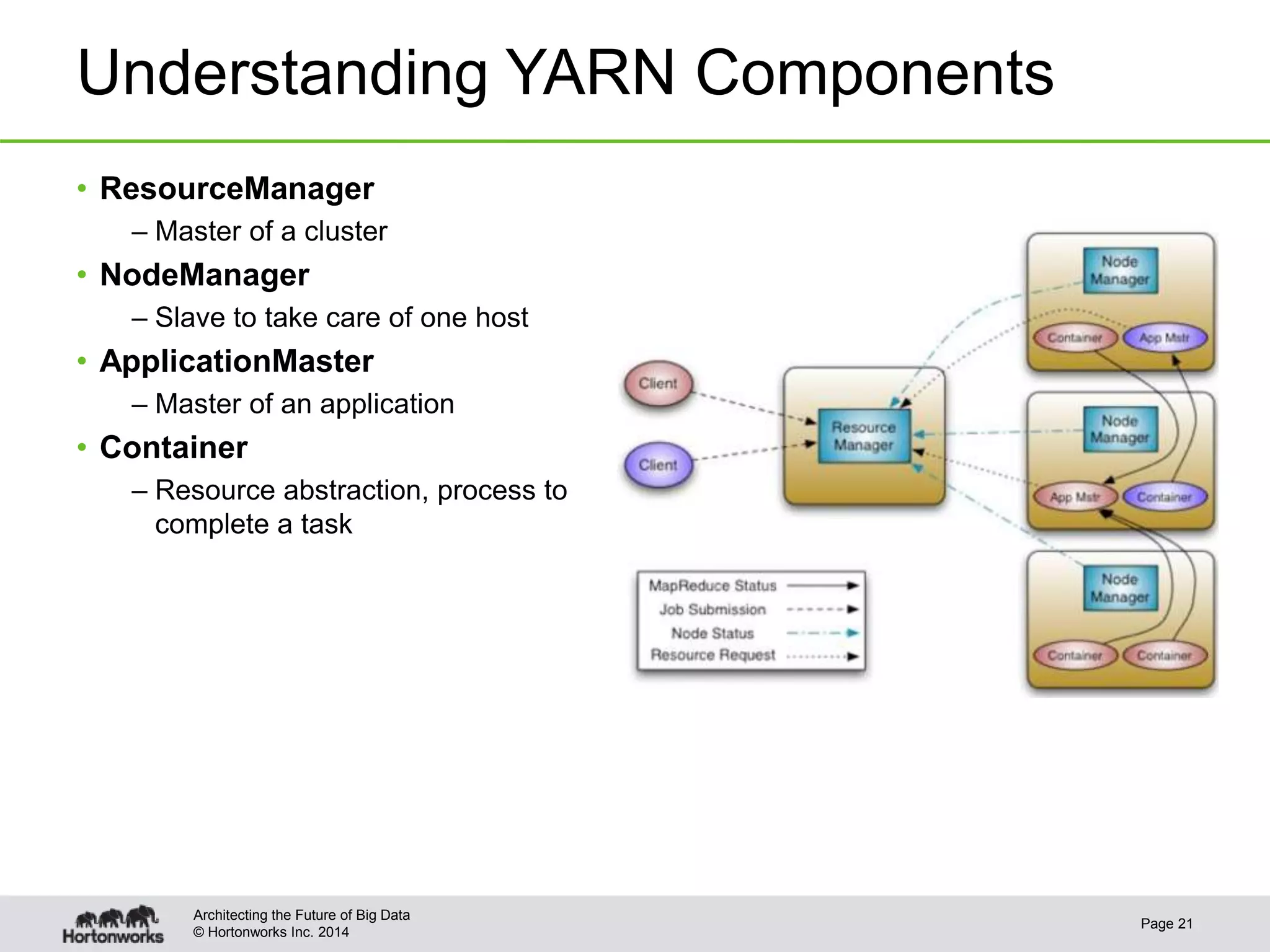







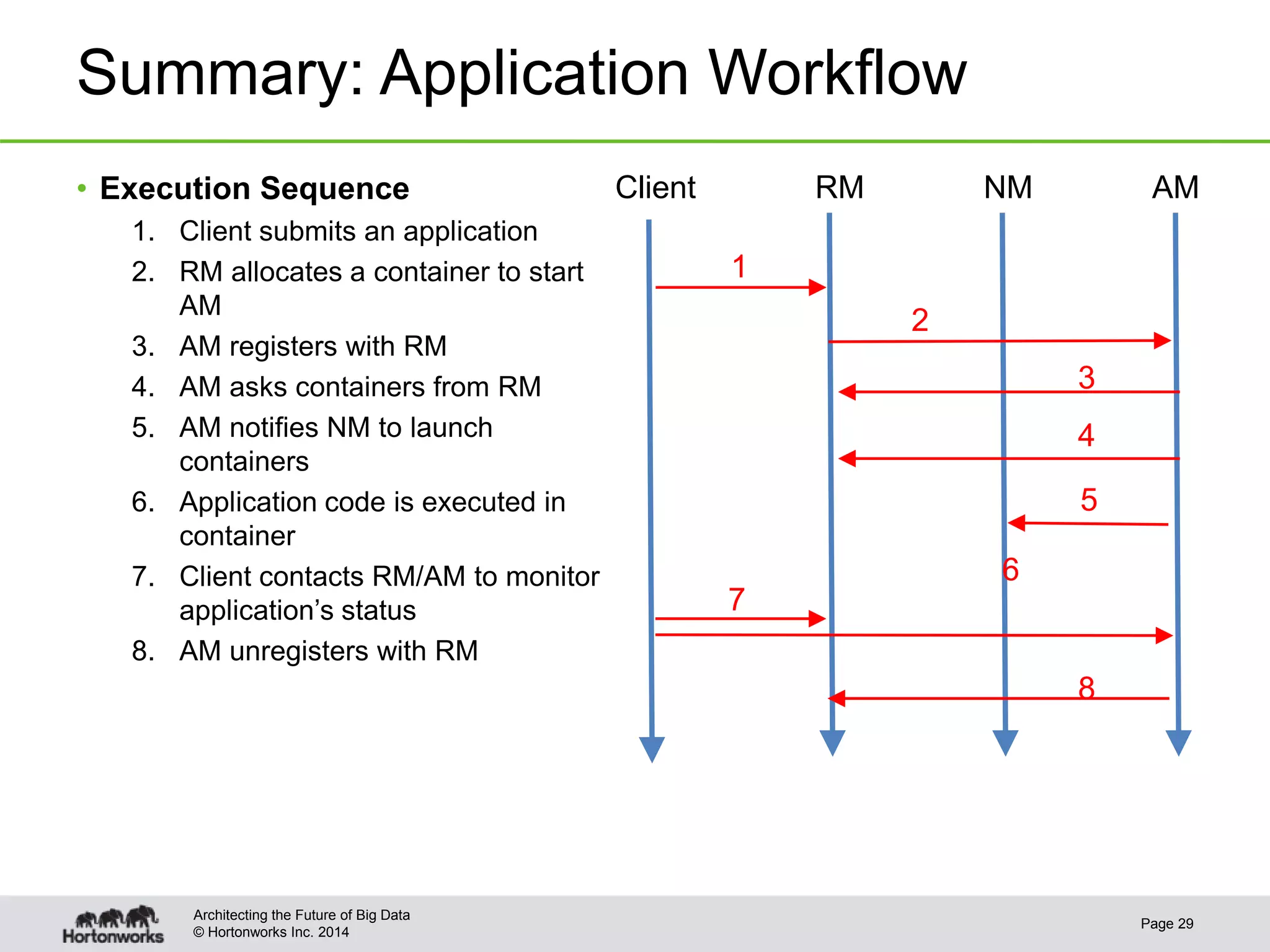




This document provides best practices for YARN administrators and application developers. For administrators, it discusses YARN configuration, enabling ResourceManager high availability, configuring schedulers like Capacity Scheduler and Fair Scheduler, sizing containers, configuring NodeManagers, log aggregation, and metrics. For application developers, it discusses whether to use an existing framework or develop a native application, understanding YARN components, writing the client, and writing the ApplicationMaster.





























































































