Downloaded 1,164 times















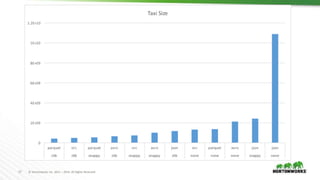

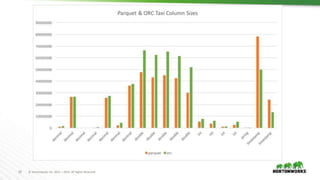
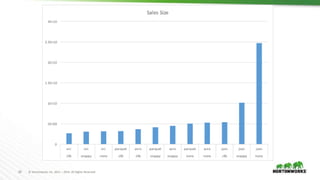

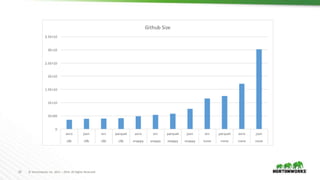



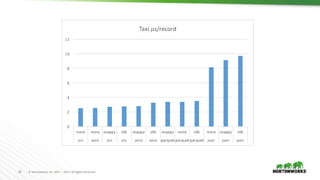

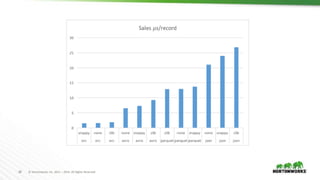

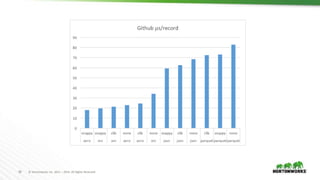

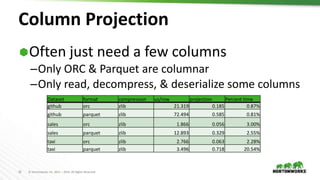









The document evaluates the performance of various file formats for Hadoop, including Avro, JSON, ORC, and Parquet, using real datasets to ascertain strengths and weaknesses. It provides benchmark analyses on data size, read performance, and compression effectiveness, concluding that JSON is less efficient for processing, while ORC and Parquet are recommended for columnar access and filtering. Recommendations include using Avro with Snappy for complex tables and ORC or Parquet with Zlib or Snappy for others.



















































































