Downloaded 31 times






![10
ParallelAccelerator.jl Usage
• Use high-level array operations (MATLAB®-style)
• Unary functions: -, +, acos, cbrt, cos, cosh, exp10, exp2, exp, lgamma, log10, log, sin, sinh,
sqrt, tan, tanh, abs, copy, erf …
• Binary functions: -, +, .+, .-, .*, ./, .,.>, .<,.==, .<<, .>>, .^, div, mod, &, |, min, max …
• Reductions, comprehensions, stencils
• minimum, maximum, sum, prod, any, all
• A = [ f(i) for i in 1:n]
• runStencil(dst, src, N, :oob_skip) do b, a
b[0,0] = (a[0,-1] + a[0,1] + a[-1,0] + a[1,0]) / 4
return a, b
end
• Avoid sequential for-loops
• Hard to analyze by ParallelAccelerator](https://image.slidesharecdn.com/ehsanparallelaccelerator-dec2015-151220165029/75/Ehsan-parallel-accelerator-dec2015-10-2048.jpg)

![using ParallelAccelerator
@acc function blur(img::Array{Float32,2}, iterations::Int)
buf = Array(Float32, size(img)...)
runStencil(buf, img, iterations, :oob_skip) do b, a
b[0,0] =
(a[-2,-2] * 0.003 + a[-1,-2] * 0.0133 + a[0,-2] * ...
a[-2,-1] * 0.0133 + a[-1,-1] * 0.0596 + a[0,-1] * ...
a[-2, 0] * 0.0219 + a[-1, 0] * 0.0983 + a[0, 0] * ...
a[-2, 1] * 0.0133 + a[-1, 1] * 0.0596 + a[0, 1] * ...
a[-2, 2] * 0.003 + a[-1, 2] * 0.0133 + a[0, 2] * ...
return a, b
end
return img
end
img = blur(img, iterations)
12
Example (2): Gaussian blur
runStencil
construct](https://image.slidesharecdn.com/ehsanparallelaccelerator-dec2015-151220165029/75/Ehsan-parallel-accelerator-dec2015-12-2048.jpg)
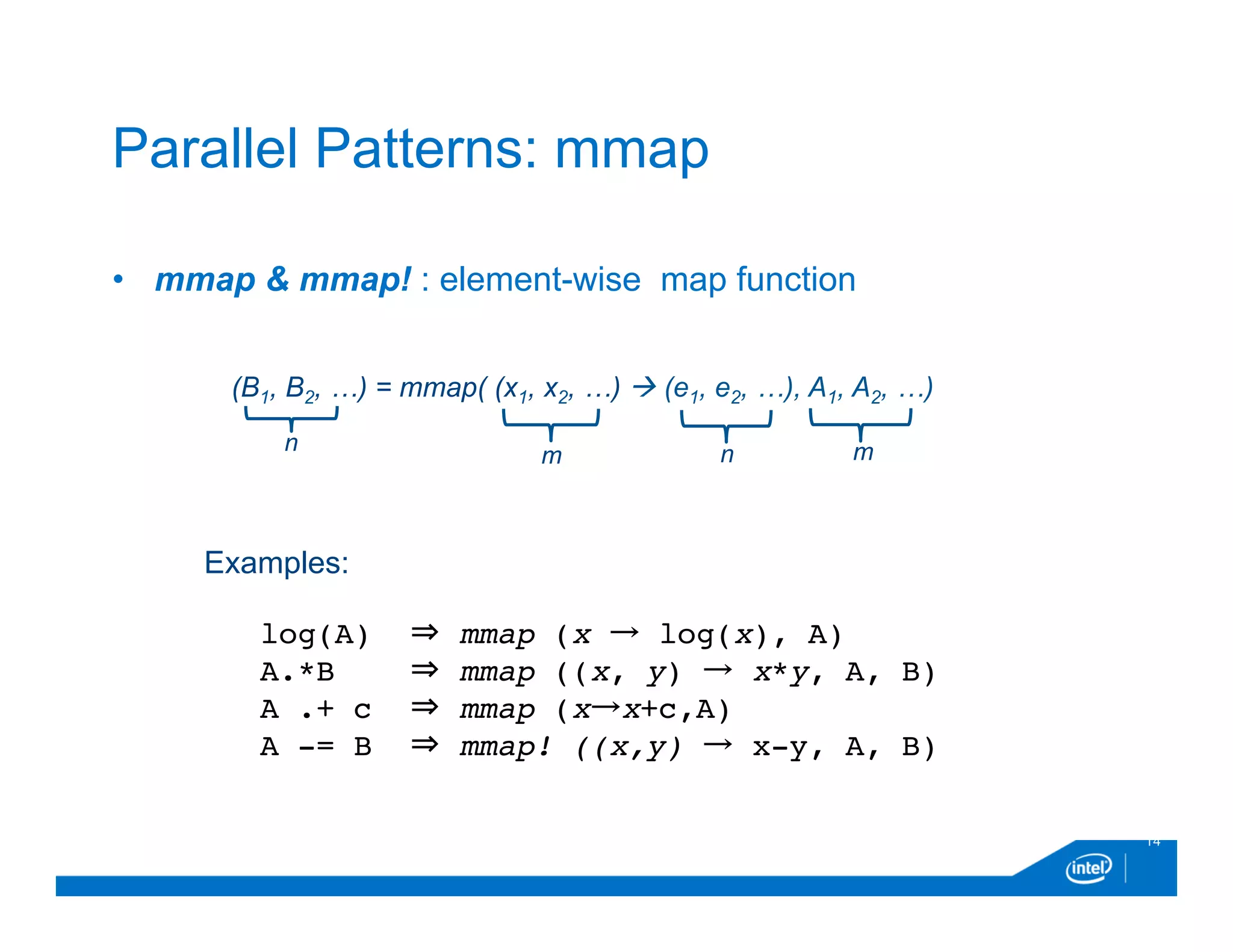

![• Comprehension: creates a rank-n array that is the cartesian
product of the range of variables
16
Parallel Patterns: comprehension
A = [ f(x1, x2, …, xn) for x1 in r1, x2 in r2, …, xn in rn]
where, function f is applied over cartesian product
of points (x1, x2, …, xn) in the ranges (r1, r2, …, rn)
Example:
avg(x) = [ 0.25*x[i-1]+0.5*x[i]+0.25*x[i+1] for i in 2:length(x)-1 ]](https://image.slidesharecdn.com/ehsanparallelaccelerator-dec2015-151220165029/75/Ehsan-parallel-accelerator-dec2015-16-2048.jpg)
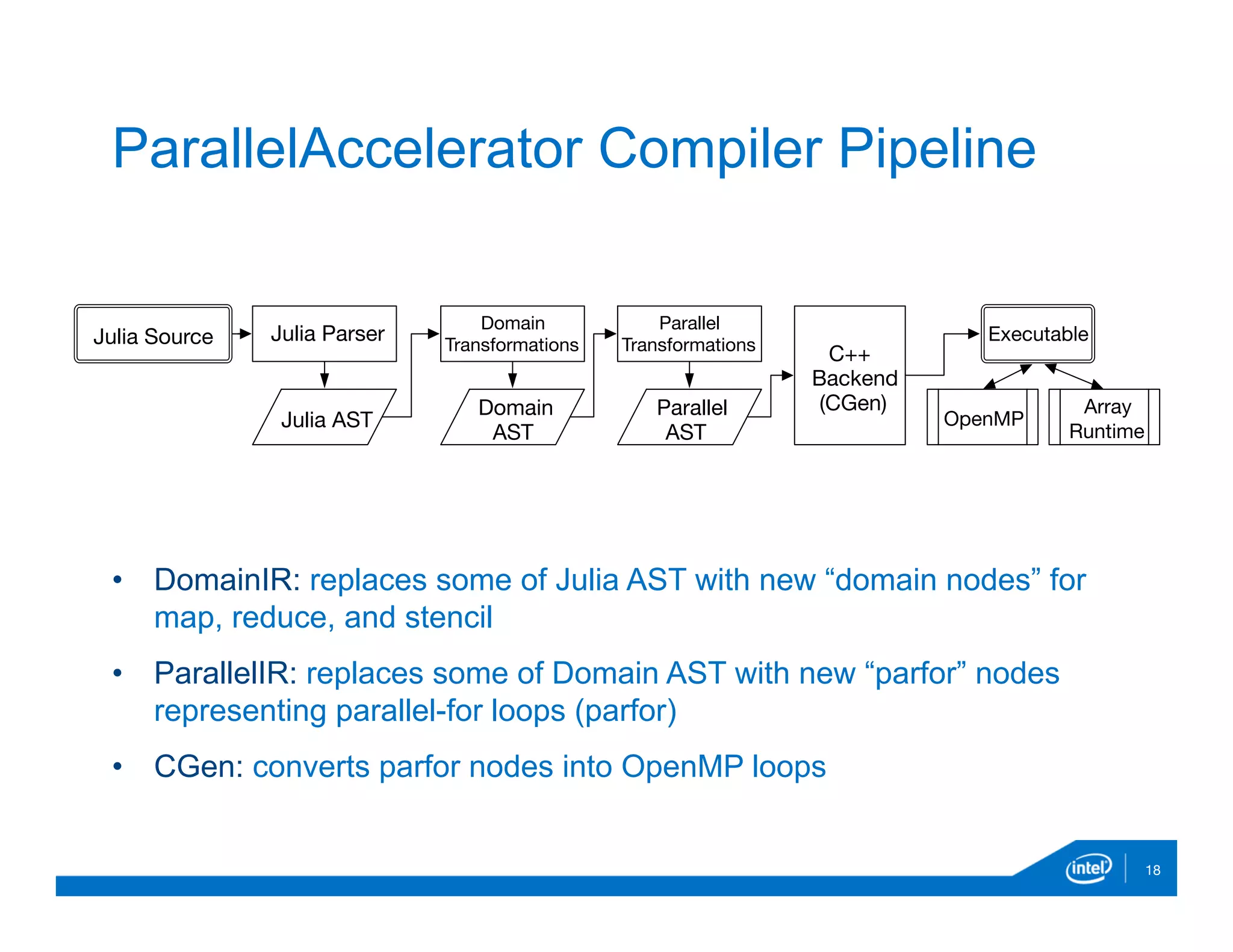
![• runStencil: user-facing language construct to perform stencil
operation
17
Parallel Patterns: stencil
runStencil((A, B, …) à f(A, B, …), A, B, …, n, s)
m mm
all arrays in function f are relatively indexed,
n is the trip count for iterative stencil
s specifies how stencil borders are handled
Example:
runStencil(b, a, N, :oob_skip) do b, a
b[0,0] =
(a[-1,-1] + a[-1,0] + a[1, 0] + a[1, 1]) / 4)
return a, b
end](https://image.slidesharecdn.com/ehsanparallelaccelerator-dec2015-151220165029/75/Ehsan-parallel-accelerator-dec2015-17-2048.jpg)

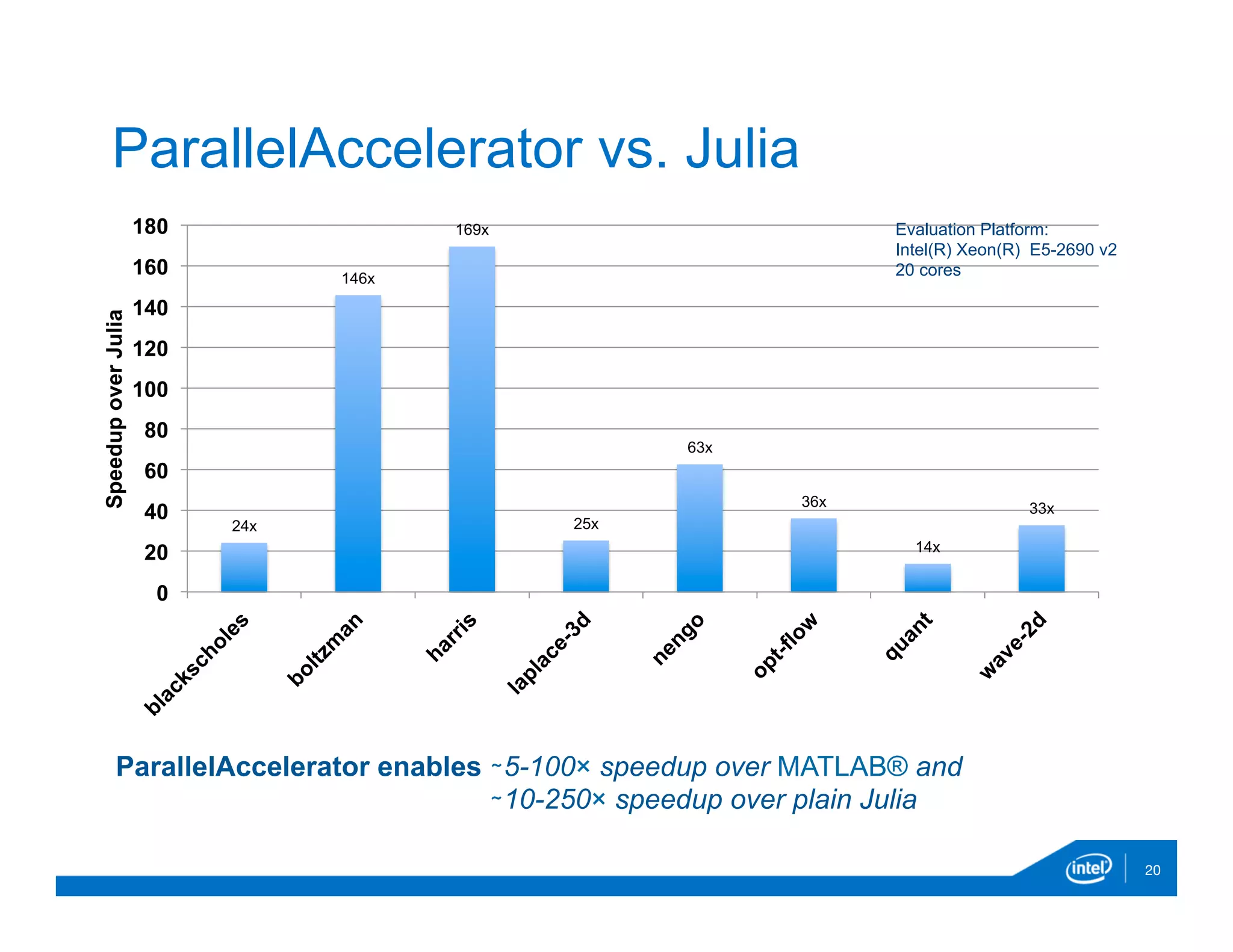






![@acc function blackscholes(iterations::Int64)
sptprice = [ 42.0 for i=1:iterations]
strike = [ 40.0+(i/iterations) for i=1:iterations]
logterm = log10(sptprice ./ strike)
powterm = .5 .* volatility .* volatility
den = volatility .* sqrt(time)
d1 = (((rate .+ powterm) .* time) .+ logterm) ./ den
d2 = d1 .- den
NofXd1 = cndf2(d1)
...
put = call .- futureValue .+ sptprice
return sum(put)
end
checksum = blackscholes(iterations)
28
Example: Black-Scholes
Parallel
initialization](https://image.slidesharecdn.com/ehsanparallelaccelerator-dec2015-151220165029/75/Ehsan-parallel-accelerator-dec2015-28-2048.jpg)
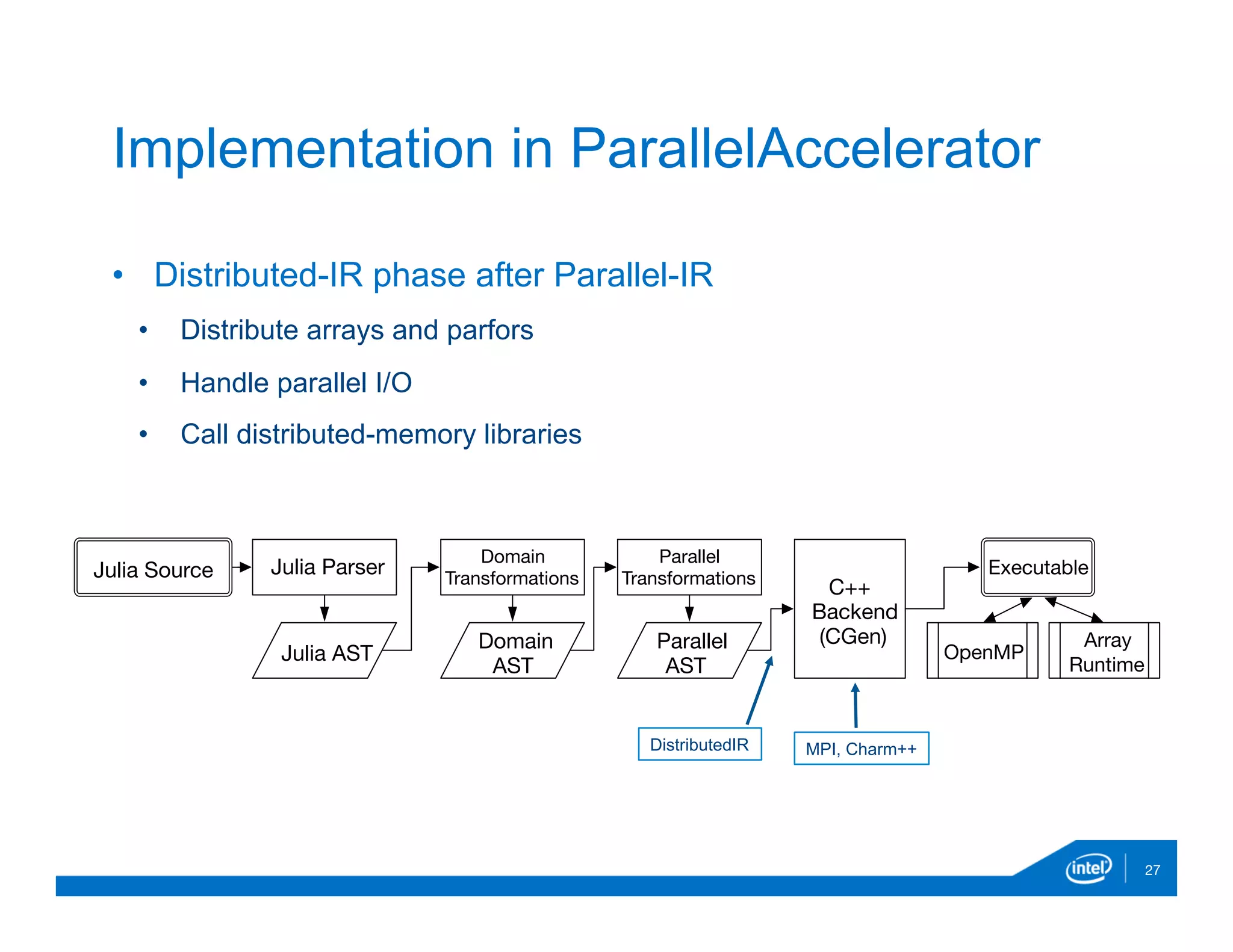
![double blackscholes(int64_t iterations)
{
int mpi_rank , mpi_nprocs;
MPI_Comm_size(MPI_COMM_WORLD,&mpi_nprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&mpi_rank);
int mystart = mpi_rank∗(iterations/mpi_nprocs);
int myend = mpi_rank==mpi_nprocs ? iterations:
(mpi_rank+1)∗(iterations/mpi_nprocs);
double *sptprice = (double*)malloc(
(myend-mystart)*sizeof(double));
…
for(i=mystart ; i<myend ; i++) {
sptprice[i-mystart] = 42.0 ;
strike[i-mystart] = 40.0+(i/iterations);
. . .
loc_put_sum += Put;
}
double all_put_sum ;
MPI_Reduce(&loc_put_sum , &all_put_sum , 1 , MPI_DOUBLE,
MPI_SUM, 0 , MPI_COMM_WORLD);
return all_put_sum;
} 29
Example: Black-Scholes](https://image.slidesharecdn.com/ehsanparallelaccelerator-dec2015-151220165029/75/Ehsan-parallel-accelerator-dec2015-29-2048.jpg)



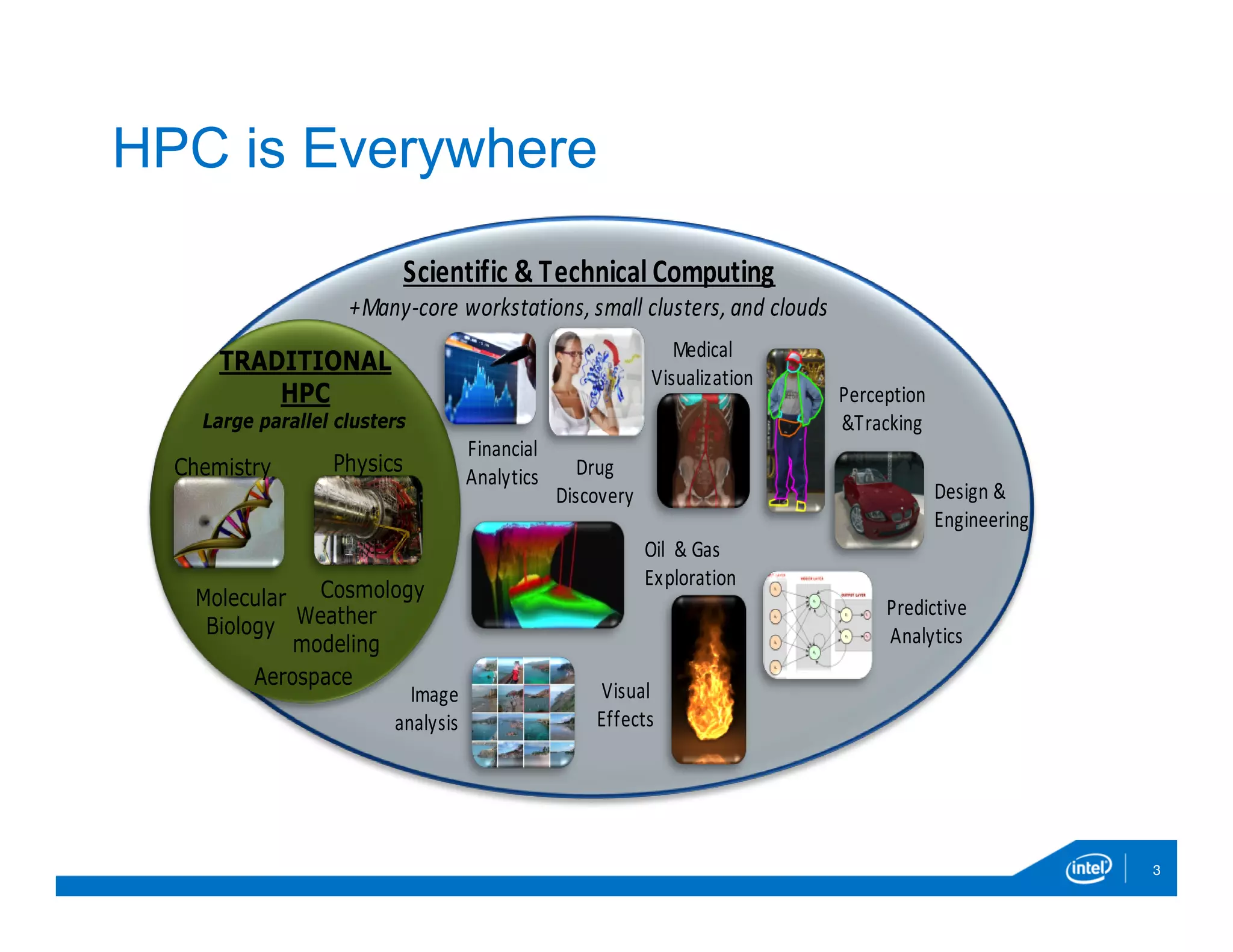
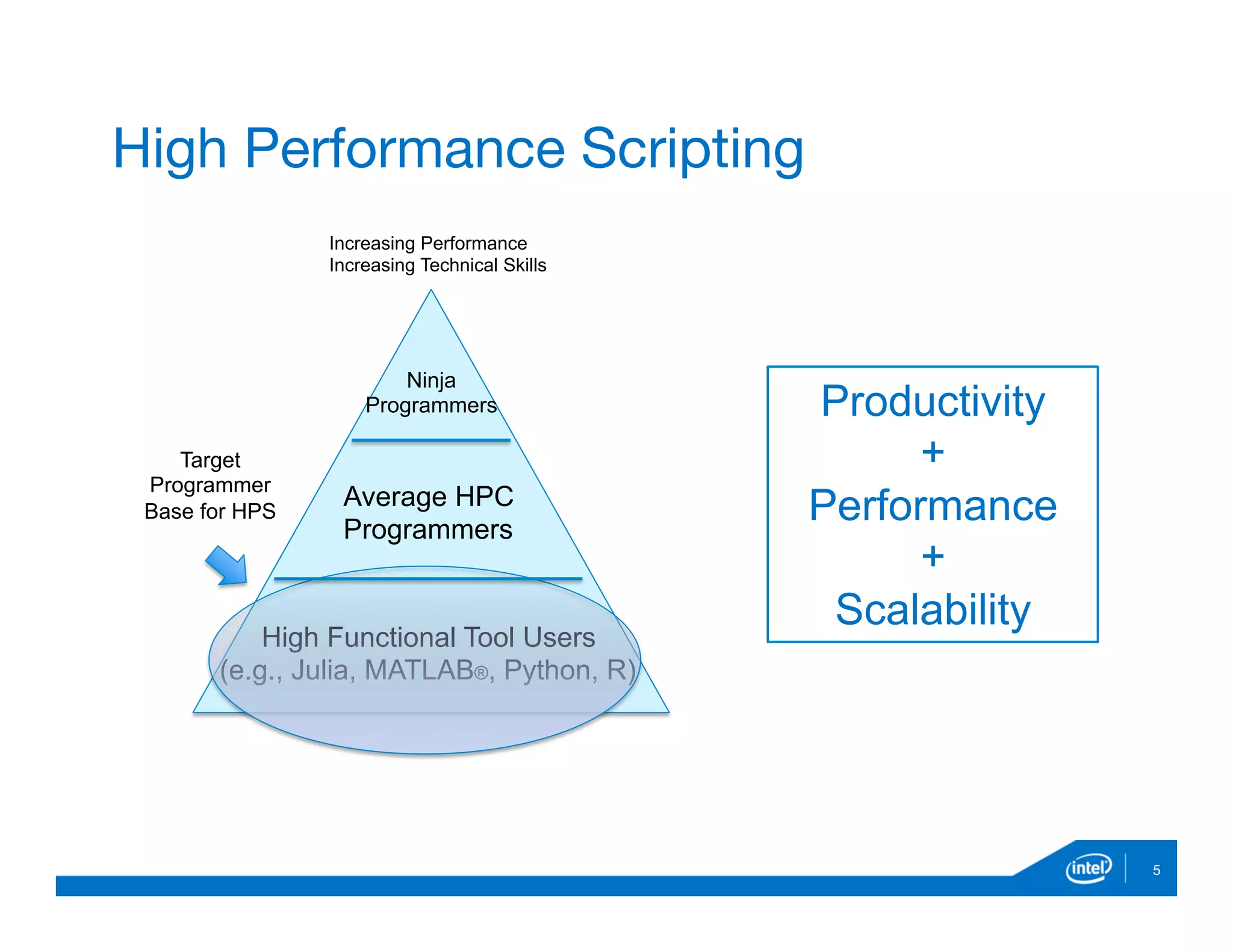
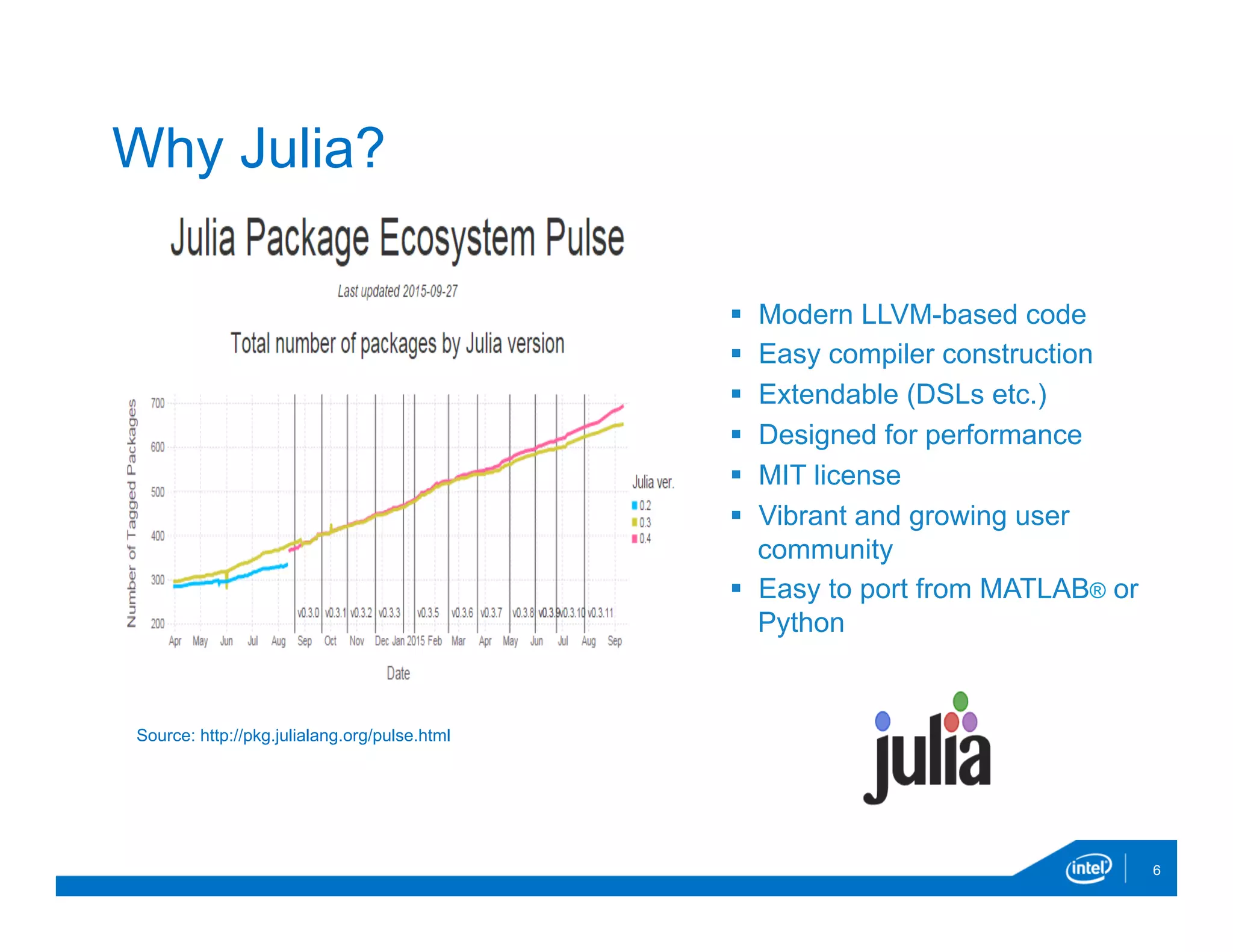
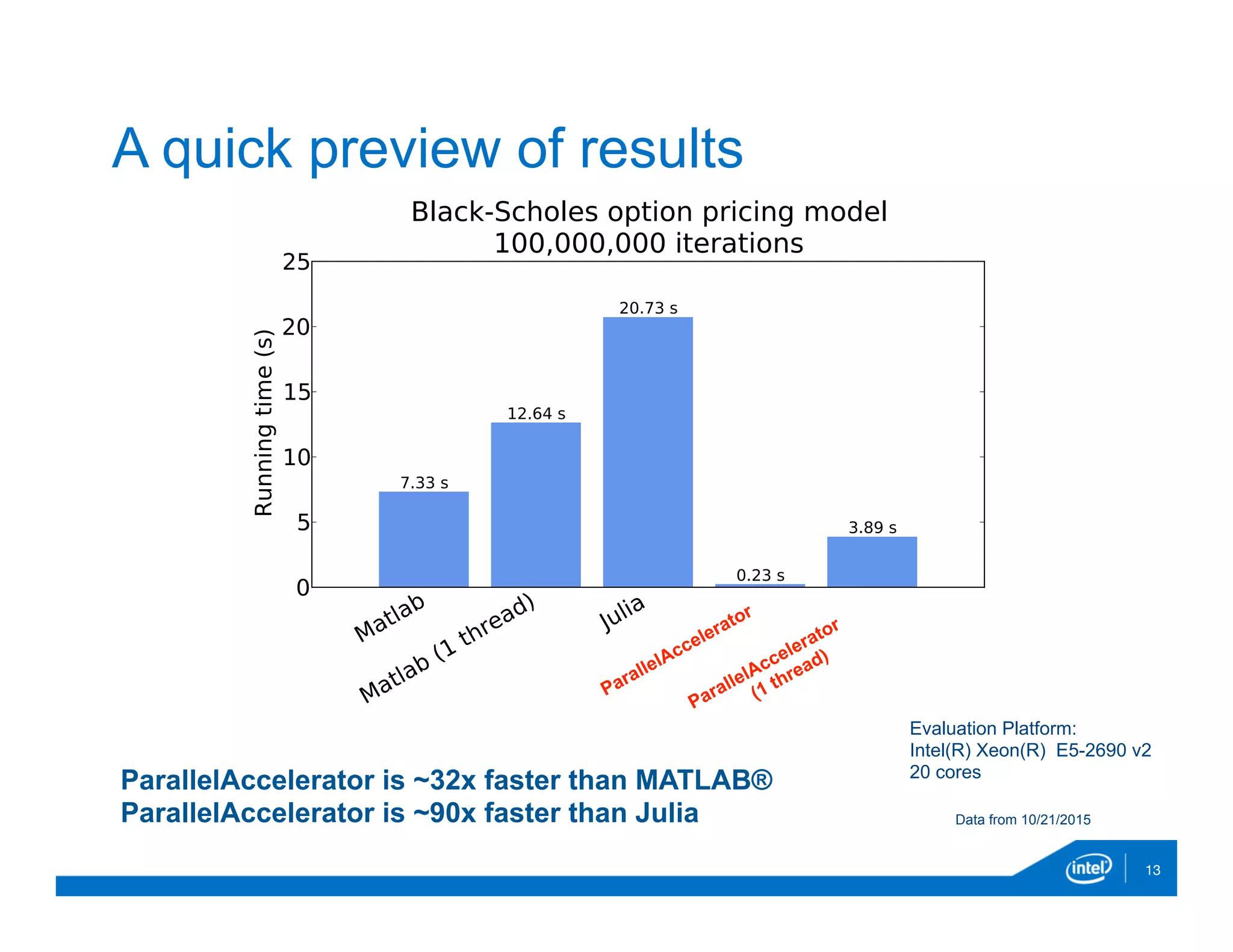
The document discusses the development and capabilities of 'parallelaccelerator.jl', a high-performance scripting tool designed for efficient parallel computing in Julia. It highlights the project's motivation, parallel programming patterns, notable performance improvements compared to MATLAB and Julia, along with installation, usage, and limitations. The future direction of the project includes enhancing native threading support and applying the tool in real-world data-intensive applications.
















































![Seller Deck - Presentation [Concert L2].PPTX](https://cdn.slidesharecdn.com/ss_thumbnails/sellerdeck-presentationconcertl2-251219171156-24982daf-thumbnail.jpg?width=640&height=640&fit=bounds)


















