Download as PDF, PPTX




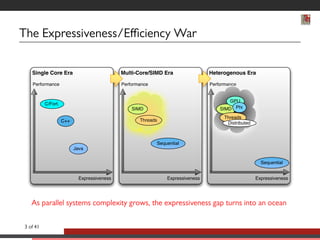



![Bulk Synchronous Parallelism [Valiant, McColl 90]
Principles
Machine Model
Execution Model
Analytic Cost Model
C
o
m
p
u
t
e
B
a
r
r
i
e
r
C
o
m
m
Wmax h.g
P0
P1
P2
P3
Superstep T Superstep T+1
Wmax h.g L
BSP Execution Model
7 of 41](https://image.slidesharecdn.com/main-141205025134-conversion-gate02/85/Software-Abstractions-for-Parallel-Hardware-11-320.jpg)
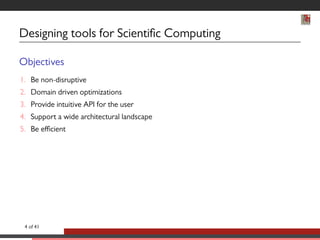
![Bulk Synchronous Parallelism [Valiant, McColl 90]
Advantages
Simple set of primitives
Implementable on any
kind of hardware
Possibility to reason about
BSP programs
C
o
m
p
u
t
e
B
a
r
r
i
e
r
C
o
m
m
Wmax h.g
P0
P1
P2
P3
Superstep T Superstep T+1
Wmax h.g L
BSP Execution Model
7 of 41](https://image.slidesharecdn.com/main-141205025134-conversion-gate02/85/Software-Abstractions-for-Parallel-Hardware-12-320.jpg)
![Parallel Skeletons [Cole 89]
Principles
There are patterns in parallel applications
Those patterns can be generalized in Skeletons
Applications are assembled as a combination of such patterns
Functional point of view
Skeletons are Higher-Order Functions
Skeletons support a compositionnal semantic
Applications become composition of state-less functions
8 of 41](https://image.slidesharecdn.com/main-141205025134-conversion-gate02/85/Software-Abstractions-for-Parallel-Hardware-13-320.jpg)
![Parallel Skeletons [Cole 89]
Principles
There are patterns in parallel applications
Those patterns can be generalized in Skeletons
Applications are assembled as a combination of such patterns
Classical Skeletons
Data parallel: map, fold, scan
Task parallel: par, pipe, farm
More complex: Distribuable Homomorphism, Divide Conquer, …
8 of 41](https://image.slidesharecdn.com/main-141205025134-conversion-gate02/85/Software-Abstractions-for-Parallel-Hardware-14-320.jpg)

![Domain Specic Embedded Languages
Domain Specic Languages
Non-Turing complete declarative languages
Solve a single type of problems
Express what to do instead of how to do it
E.g: SQL, M, M, …
From DSL to DSEL [Abrahams 2004]
A DSL incorporates domain-specic notation, constructs, and abstractions as
fundamental design considerations.
A Domain Specic Embedded Languages (DSEL) is simply a library that meets the
same criteria
Generative Programming is one way to design such libraries
10 of 41](https://image.slidesharecdn.com/main-141205025134-conversion-gate02/85/Software-Abstractions-for-Parallel-Hardware-16-320.jpg)
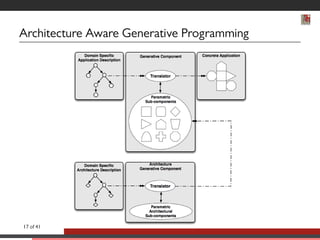
![Generative Programming [Eisenecker 97]
Domain Specific
Application Description
Generative Component Concrete Application
Translator
Parametric
Sub-components
11 of 41](https://image.slidesharecdn.com/main-141205025134-conversion-gate02/85/Software-Abstractions-for-Parallel-Hardware-17-320.jpg)














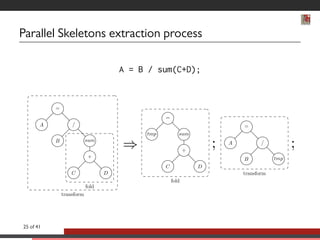


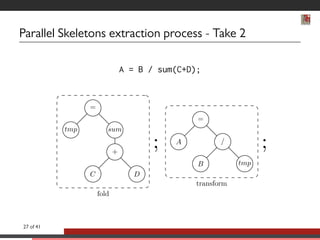
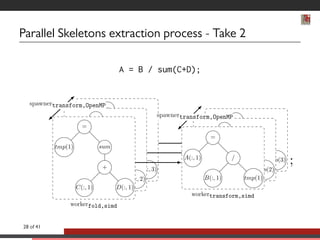

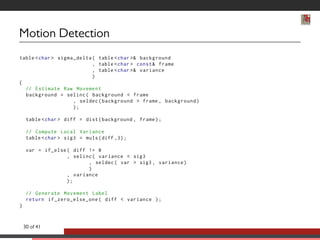
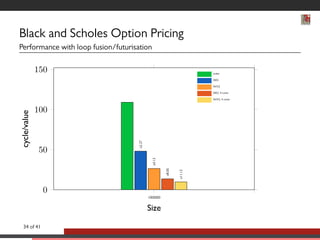

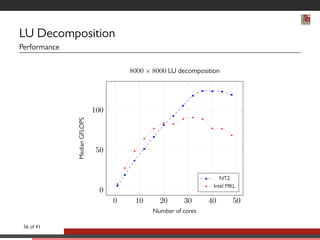




This document discusses advancements in software abstractions for parallel architectures, specifically focusing on the challenges and objectives in high-performance computing (HPC). It emphasizes the shift from single-core to multi-core and heterogeneous systems, detailing the need for effective parallel programming tools and methodologies. The author explores domain-specific embedded languages (DSEL) and generative programming to enhance efficiency and expressiveness in modern scientific computing applications.













































































