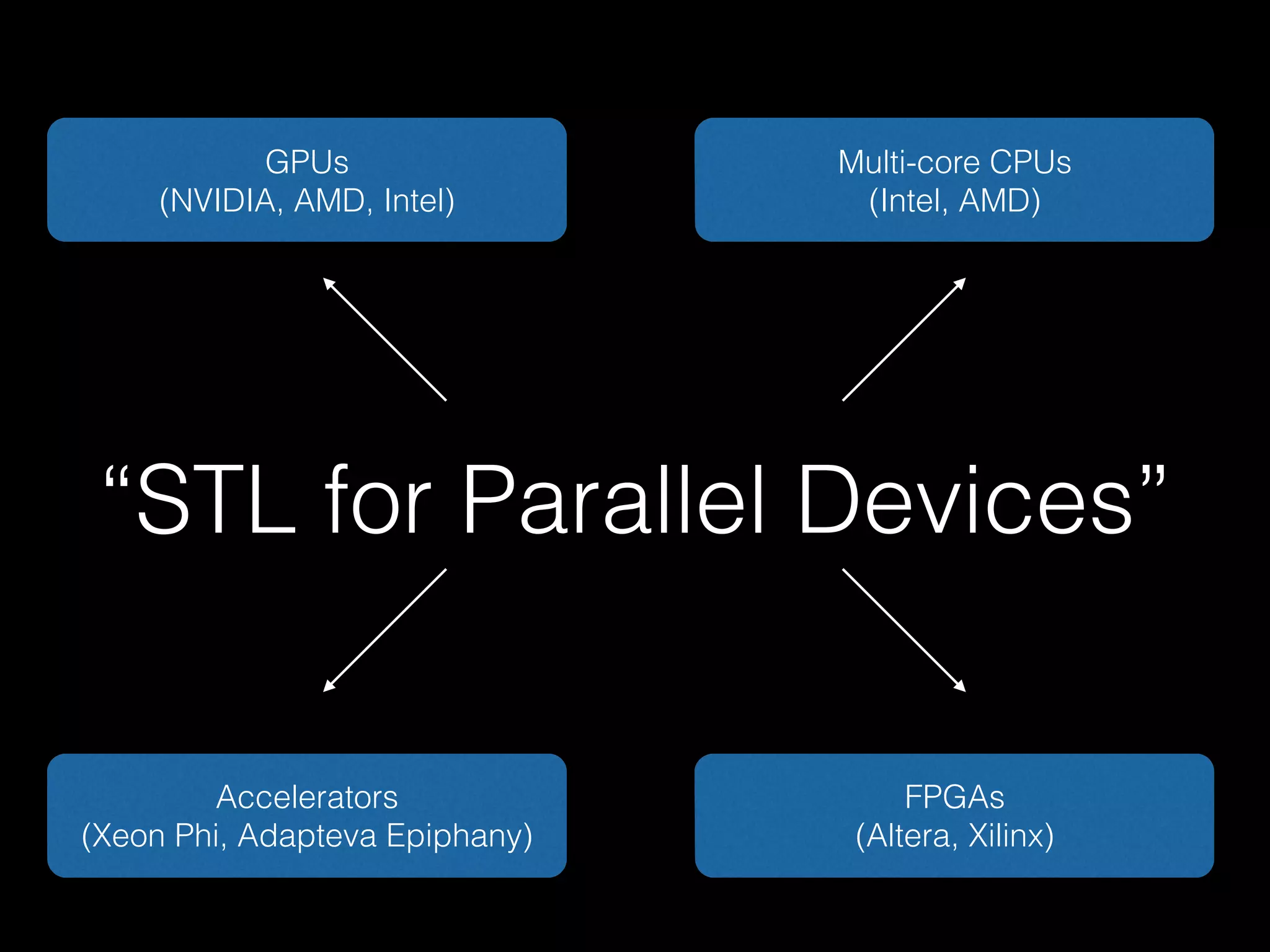
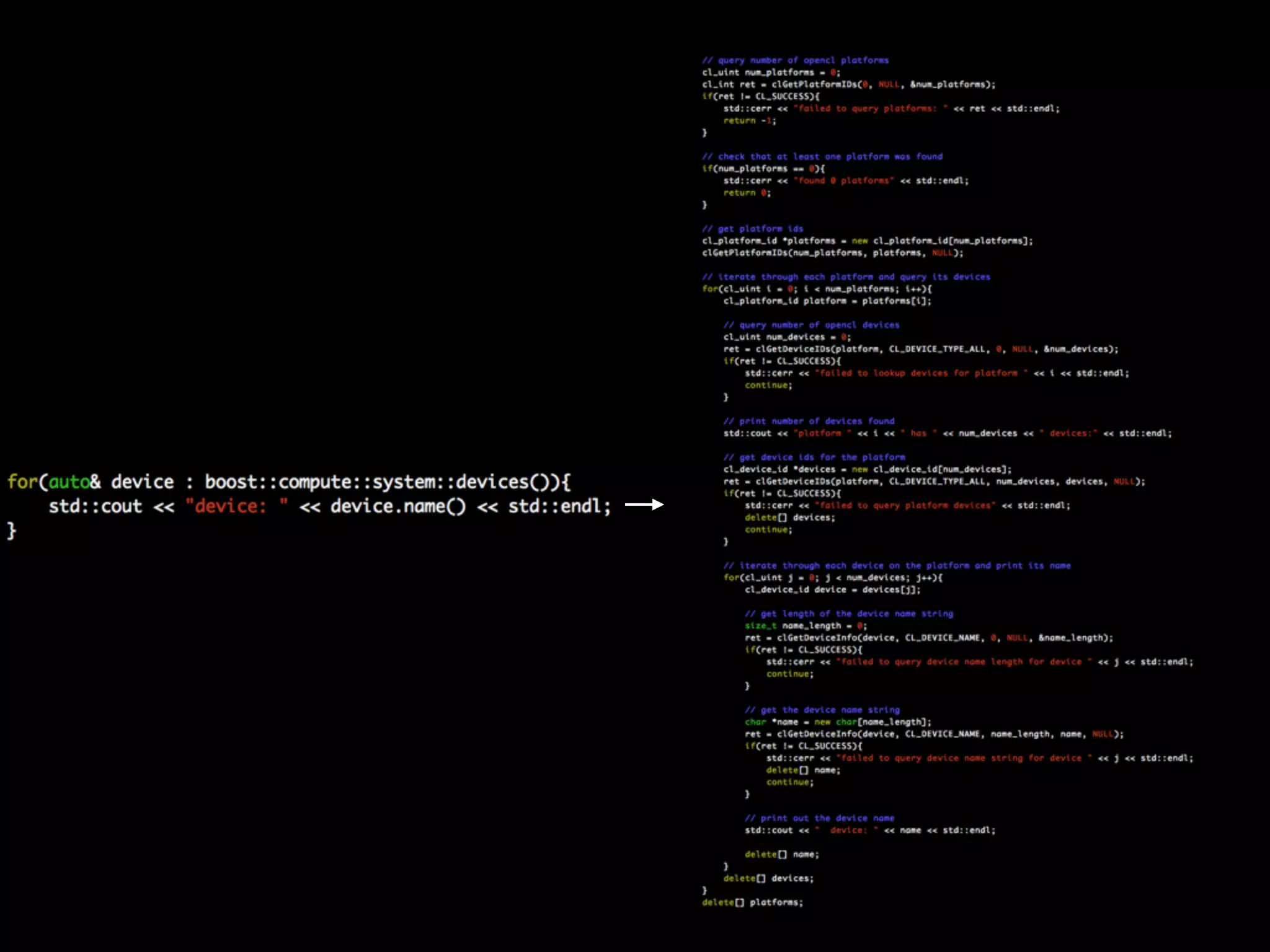
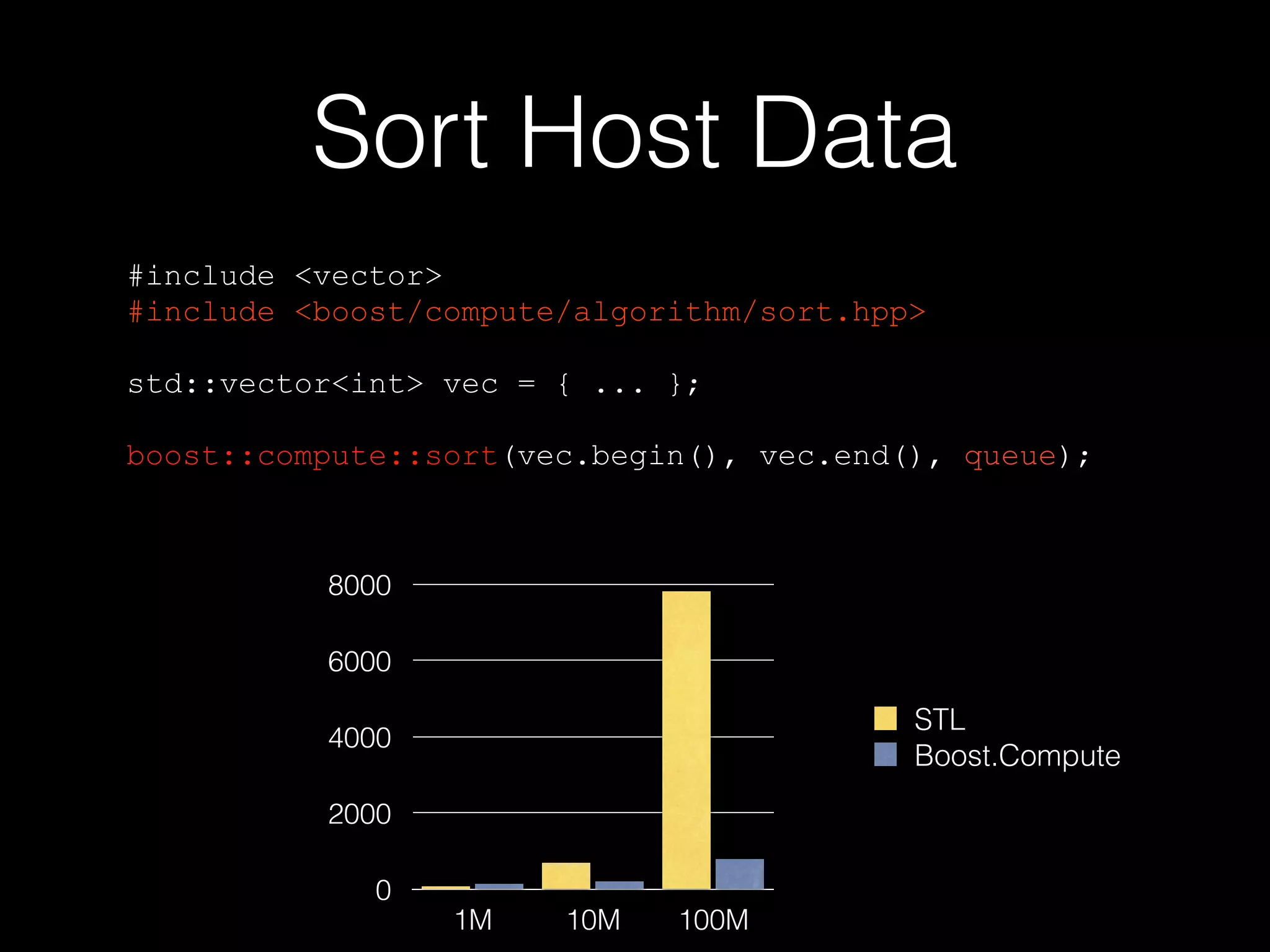
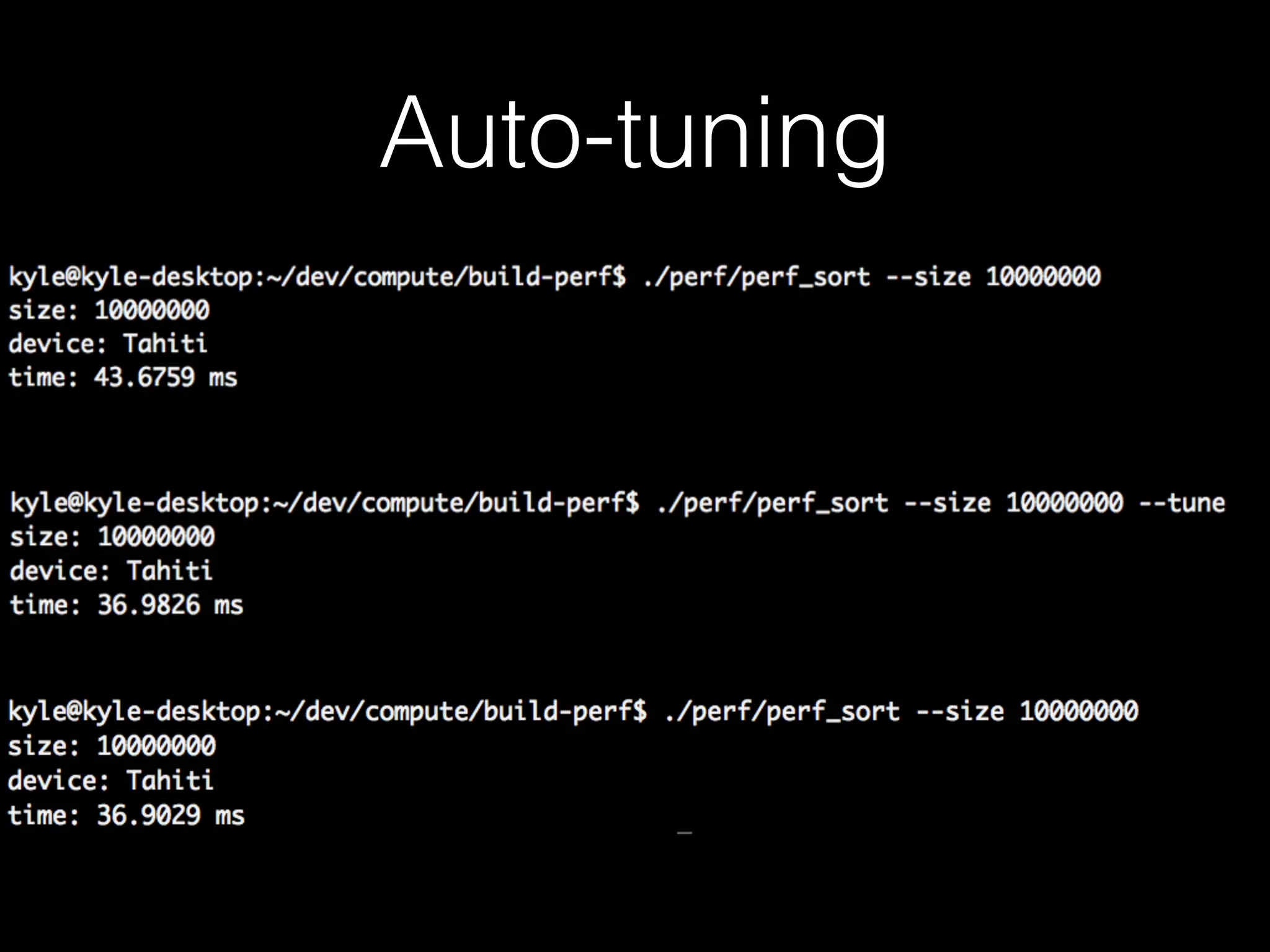
Boost.Compute is a C++ library that provides a standardized interface for GPU and parallel computing. It uses OpenCL to support GPUs and other accelerators from different vendors. The library includes algorithms, containers, iterators, and random number generators organized similarly to the C++ Standard Template Library (STL) to enable parallel operations. Boost.Compute handles low-level OpenCL details while exposing a high-level interface for parallel programming.

































































![[Td 2015] what is new in visual c++ 2015 and future directions(ulzii luvsanba...](https://cdn.slidesharecdn.com/ss_thumbnails/td2015whatisnewinvisualc2015andfuturedirectionsulziiluvsanbatandaymanshoukly-151104050956-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)































