Downloaded 240 times







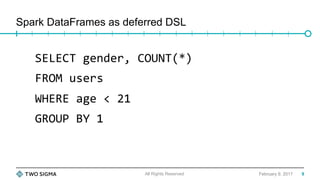
![Spark DataFrames as deferred DSL
February 9, 2017
young = users[users.age < 21]
young.groupBy(“gender”).count()
All Rights Reserved 8](https://image.slidesharecdn.com/mckinneysparksummiteast2017final-170209204415/85/Improving-Python-and-Spark-PySpark-Performance-and-Interoperability-8-320.jpg)
![Spark DataFrames as deferred DSL
February 9, 2017
Aggregation[table]
table:
Table: users
metrics:
count = Count[int64]
Table: ref_0
by:
gender = Column[array(string)] 'gender' from users
predicates:
Less[array(boolean)]
age = Column[array(int32)] 'age' from users
Literal[int8]
21
All Rights Reserved 10](https://image.slidesharecdn.com/mckinneysparksummiteast2017final-170209204415/85/Improving-Python-and-Spark-PySpark-Performance-and-Interoperability-10-320.jpg)




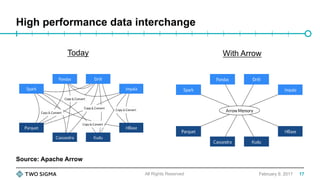

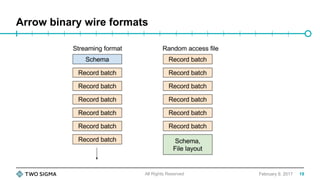



![For illustration purposes only. Not an offer to buy or sell securities. Two Sigma may modify its investment approach and portfolio parameters in the future in any manner that it believes is consistent with its fiduciary duty to its clients. There is no
guarantee that Two Sigma or its products will be successful in achieving any or all of their investment objectives. Moreover, all investments involve some degree of risk, not all of which will be successfully mitigated. Please see the last page of
this presentation for important disclosure information.
Making DataFrame.toPandas faster
February 9, 2017All Rights Reserved
df = sqlContext.read.parquet('example2.parquet')
df = df.cache()
df.count()
Then
%%prun -s cumulative
dfs = [df.toPandas() for i in range(5)]
24](https://image.slidesharecdn.com/mckinneysparksummiteast2017final-170209204415/85/Improving-Python-and-Spark-PySpark-Performance-and-Interoperability-24-320.jpg)

![For illustration purposes only. Not an offer to buy or sell securities. Two Sigma may modify its investment approach and portfolio parameters in the future in any manner that it believes is consistent with its fiduciary duty to its clients. There is no
guarantee that Two Sigma or its products will be successful in achieving any or all of their investment objectives. Moreover, all investments involve some degree of risk, not all of which will be successfully mitigated. Please see the last page of
this presentation for important disclosure information.
Making DataFrame.toPandas faster
February 9, 2017All Rights Reserved
Now, using pyarrow
%%prun -s cumulative
dfs = [df.toPandas(useArrow) for i in range(5)]
26](https://image.slidesharecdn.com/mckinneysparksummiteast2017final-170209204415/85/Improving-Python-and-Spark-PySpark-Performance-and-Interoperability-26-320.jpg)





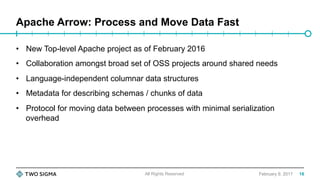
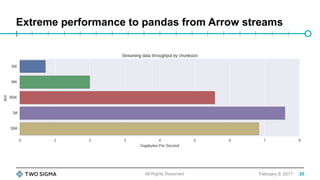
![Digging deeper
February 9, 2017
• Why does it take Spark ~1.8 seconds to send 128MB of data over the wire?
val collectedRows = queryExecution.executedPlan.executeCollect()
cnvtr.internalRowsToPayload(collectedRows, this.schema)
All Rights Reserved
Array[InternalRow]
32](https://image.slidesharecdn.com/mckinneysparksummiteast2017final-170209204415/85/Improving-Python-and-Spark-PySpark-Performance-and-Interoperability-32-320.jpg)
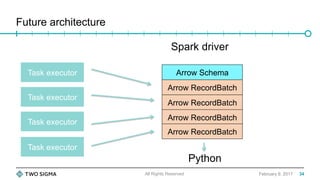
![Digging deeper
February 9, 2017
• In our 128MB test case, on average:
• 75% of time is being spent collecting Array[InternalRow] from the task
executors
• 25% of the time is spent on a single-threaded conversion of all the data
from Array[InternalRow] to ArrowRecordBatch
• We can go much faster by performing the Spark SQL -> Arrow
conversion locally on the task executors, then streaming the batches to
Python
All Rights Reserved 33](https://image.slidesharecdn.com/mckinneysparksummiteast2017final-170209204415/85/Improving-Python-and-Spark-PySpark-Performance-and-Interoperability-33-320.jpg)




The document discusses the performance issues and interoperability challenges associated with PySpark, particularly focusing on the limitations of Python in executing Spark jobs efficiently. It highlights Apache Arrow as a solution for improving data interchange speed and memory efficiency between Spark and Python. Future improvements and the importance of collaboration within the open-source community for enhancing these technologies are also emphasized.























































































