Download as PDF, PPTX


















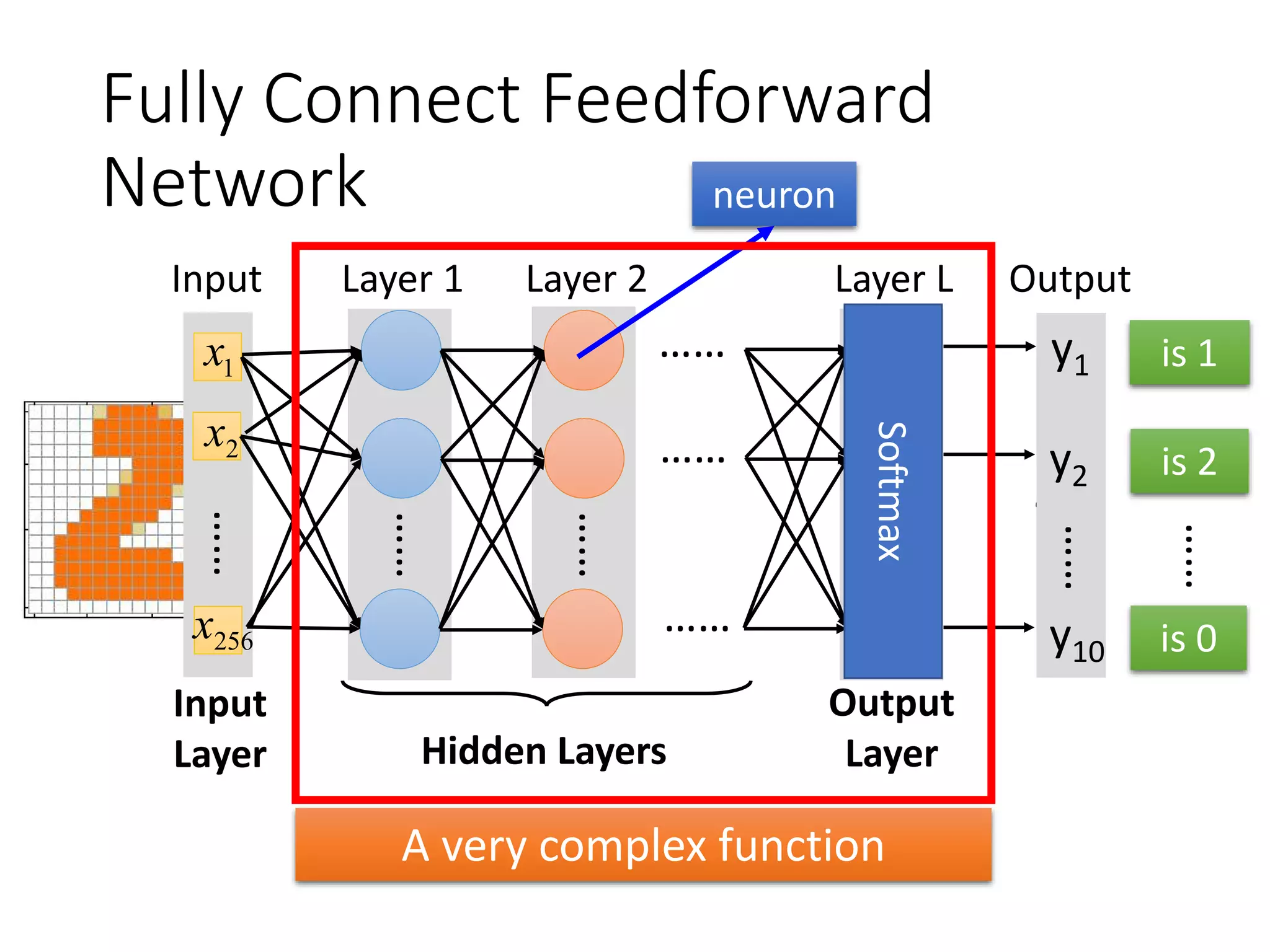






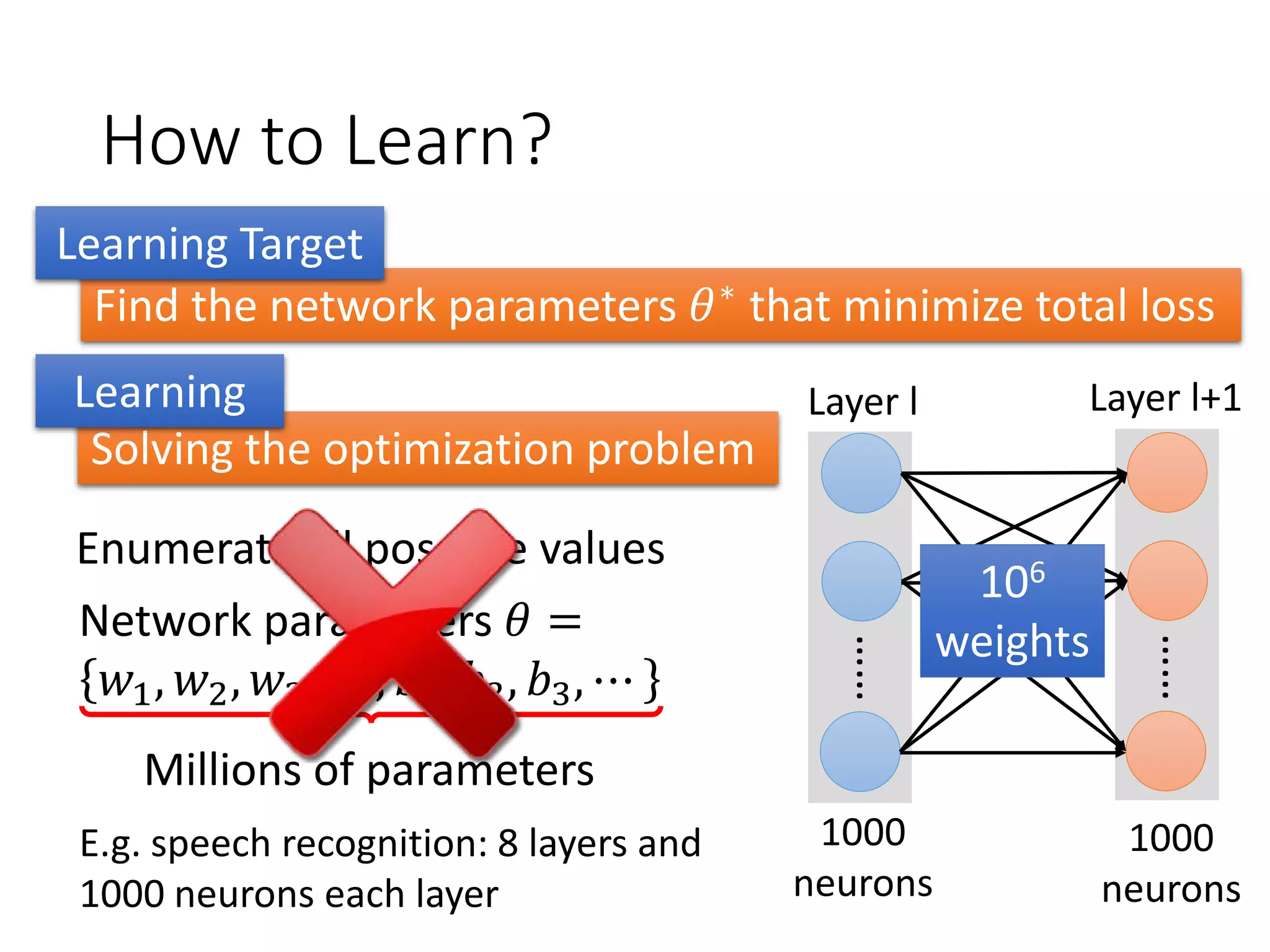
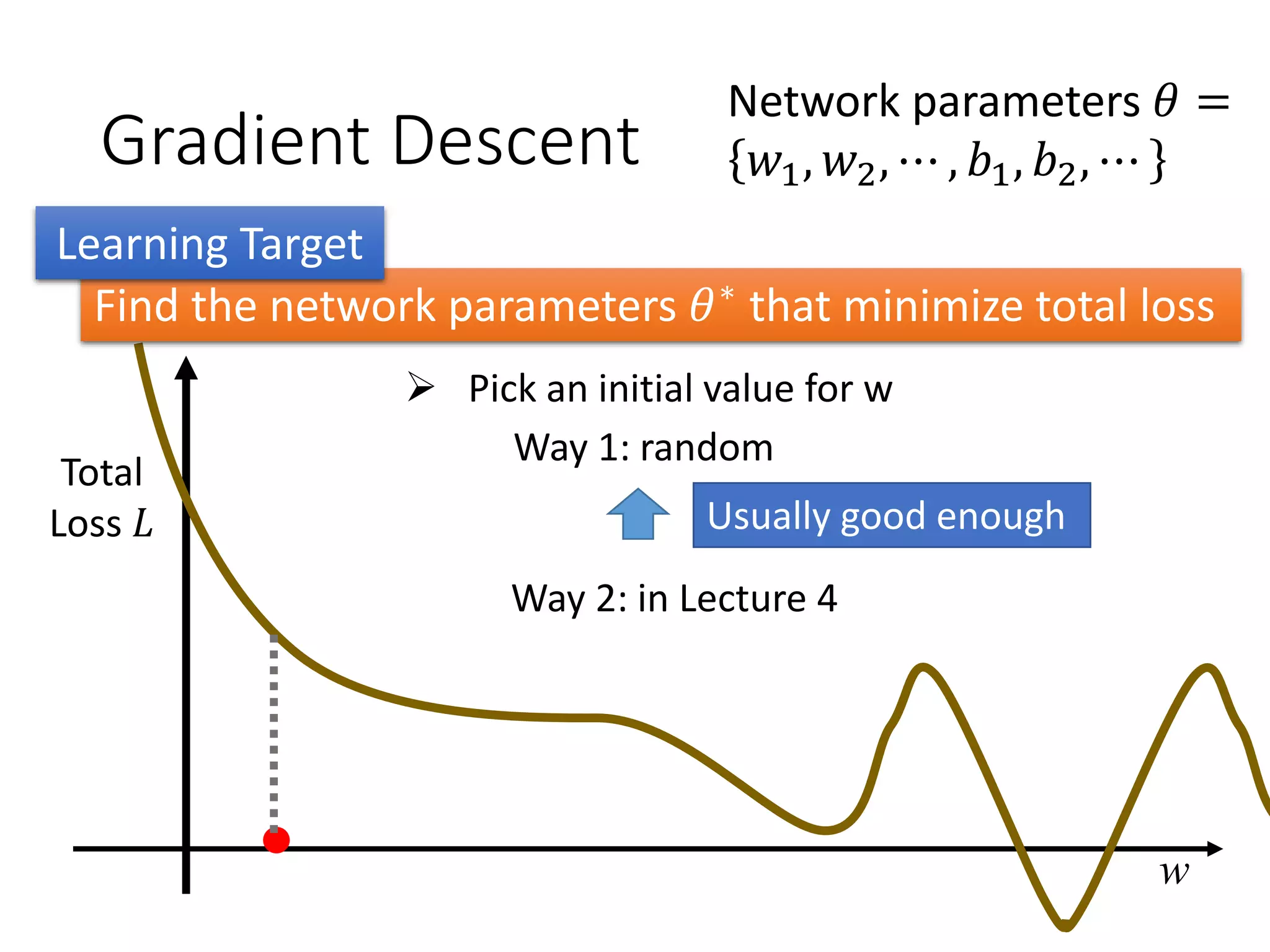

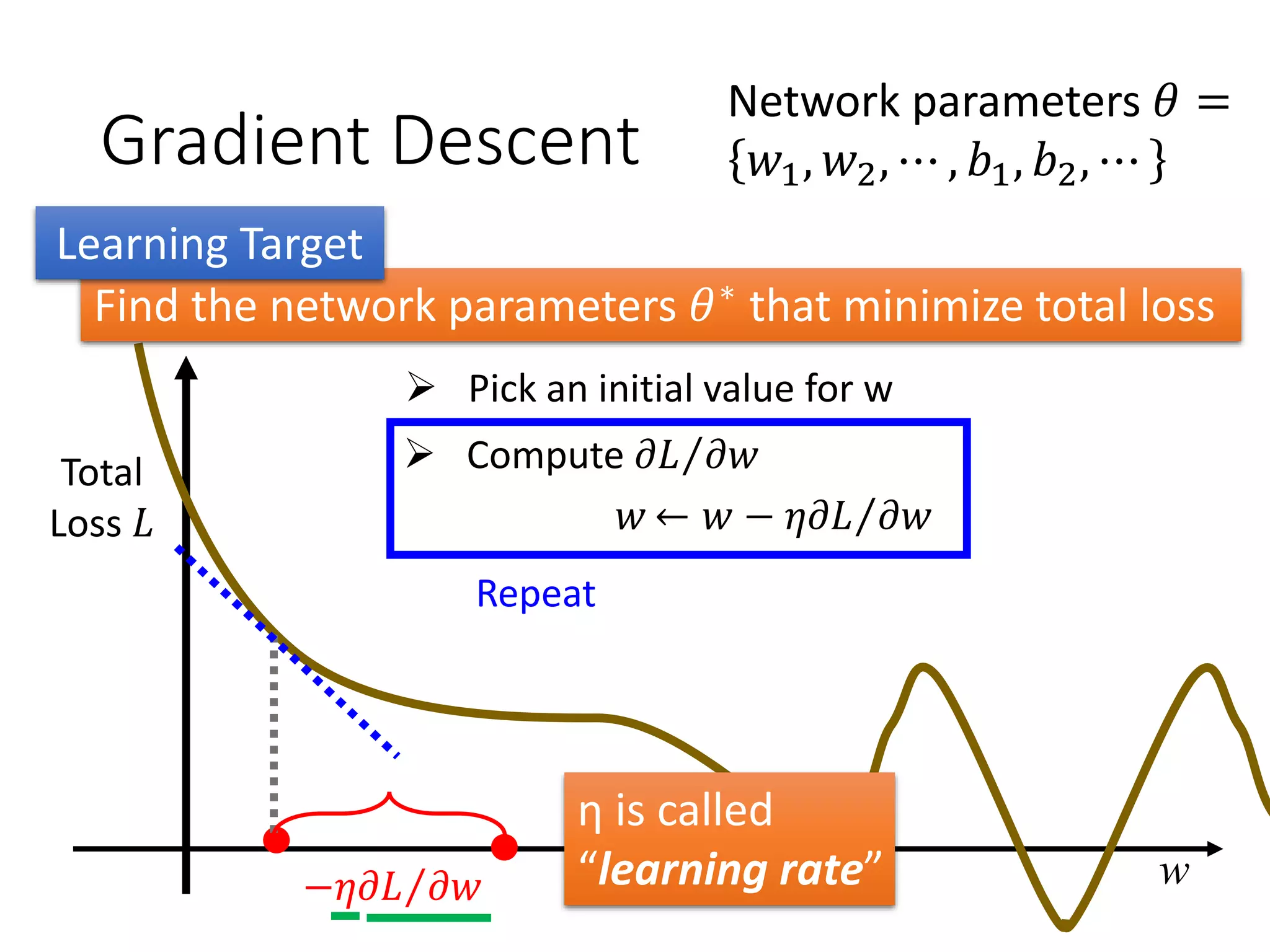























![Keras
• Using GPU to speed training
• Way 1
• THEANO_FLAGS=device=gpu0 python
YourCode.py
• Way 2 (in your code)
• import os
• os.environ["THEANO_FLAGS"] =
"device=gpu0"](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-67-2048.jpg)

















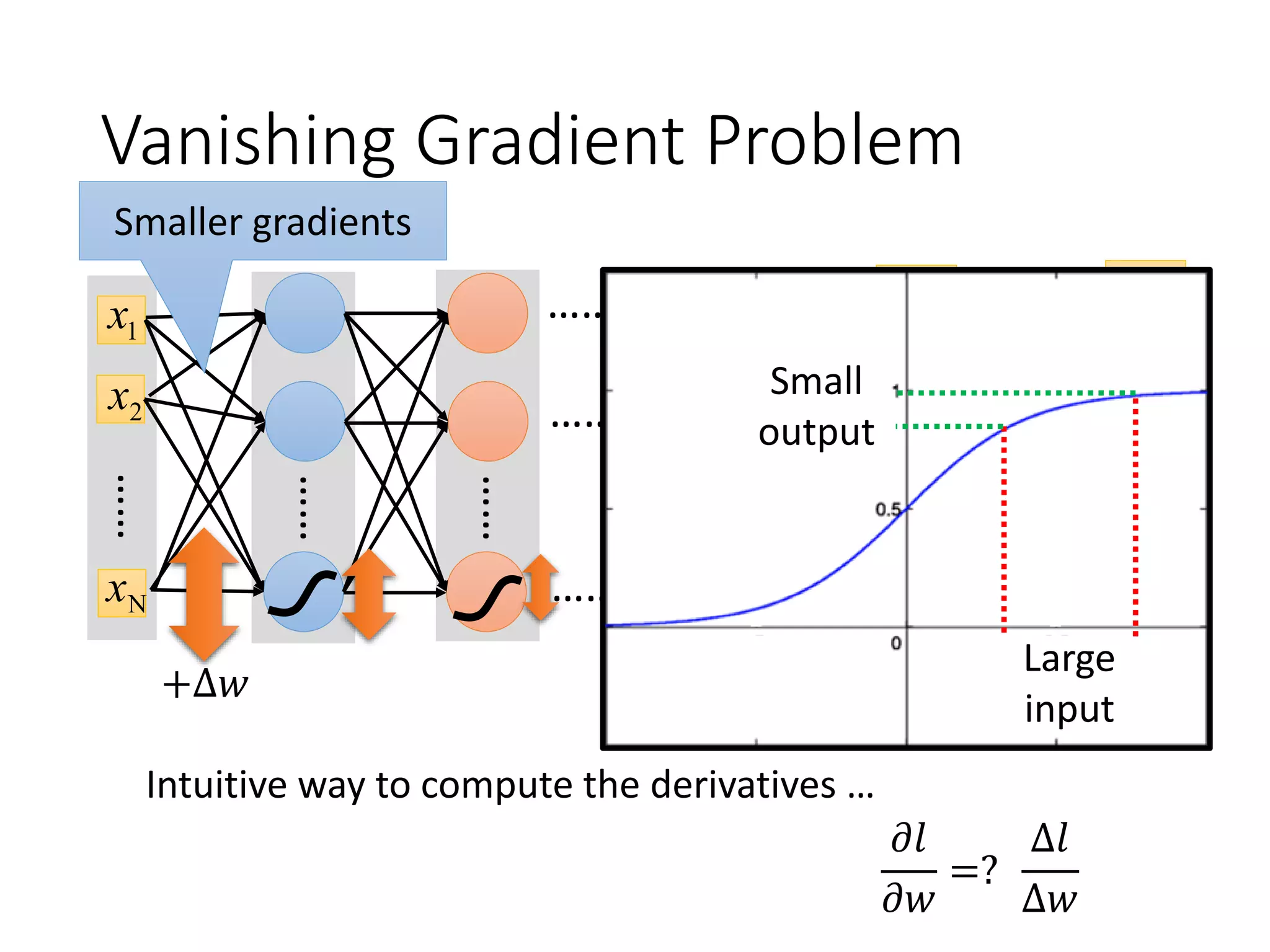
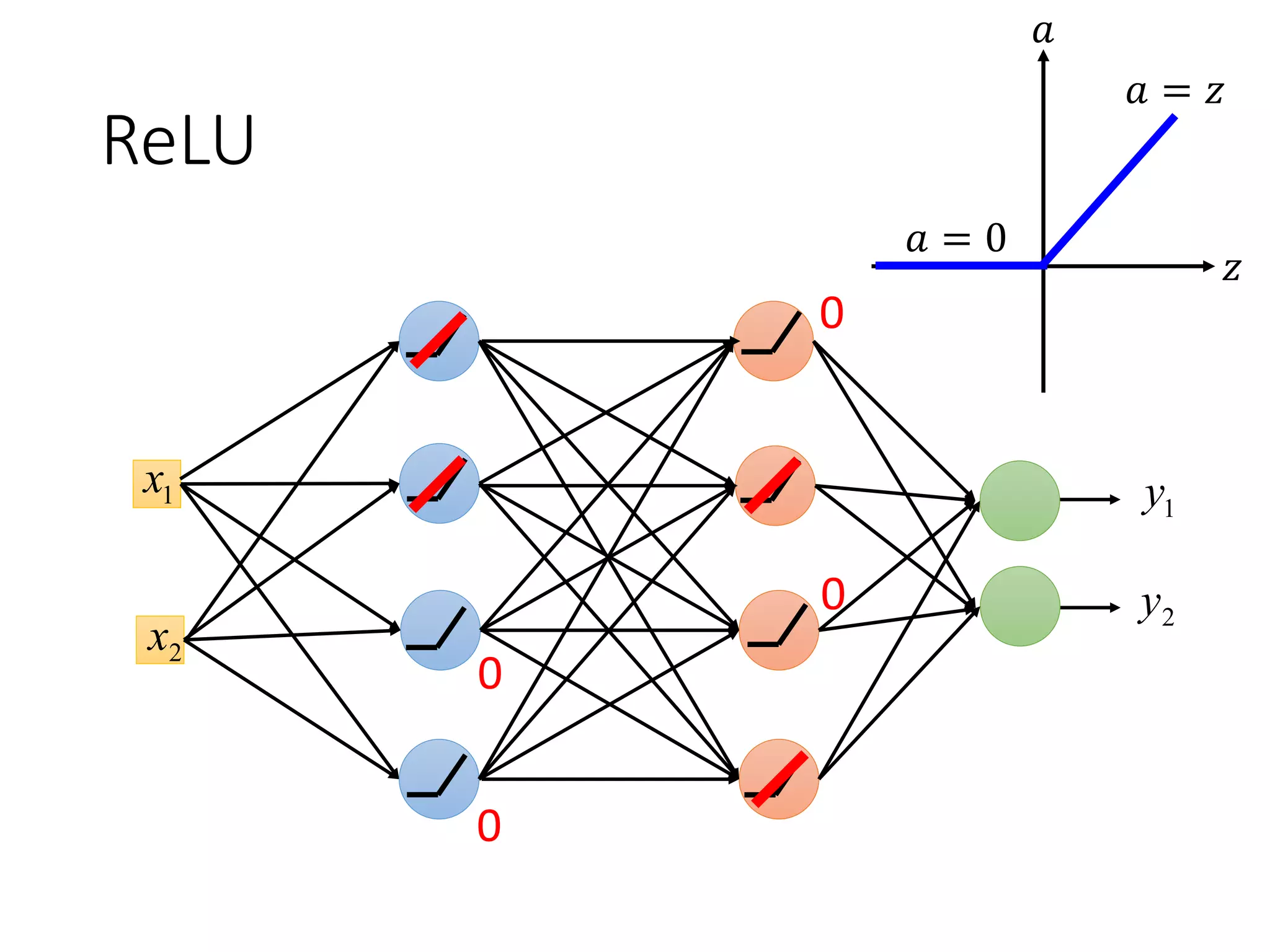
![ReLU
• Rectified Linear Unit (ReLU)
Reason:
1. Fast to compute
2. Biological reason
3. Infinite sigmoid
with different biases
4. Vanishing gradient
problem
𝑧
𝑎
𝑎 = 𝑧
𝑎 = 0
𝜎 𝑧
[Xavier Glorot, AISTATS’11]
[Andrew L. Maas, ICML’13]
[Kaiming He, arXiv’15]](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-92-2048.jpg)




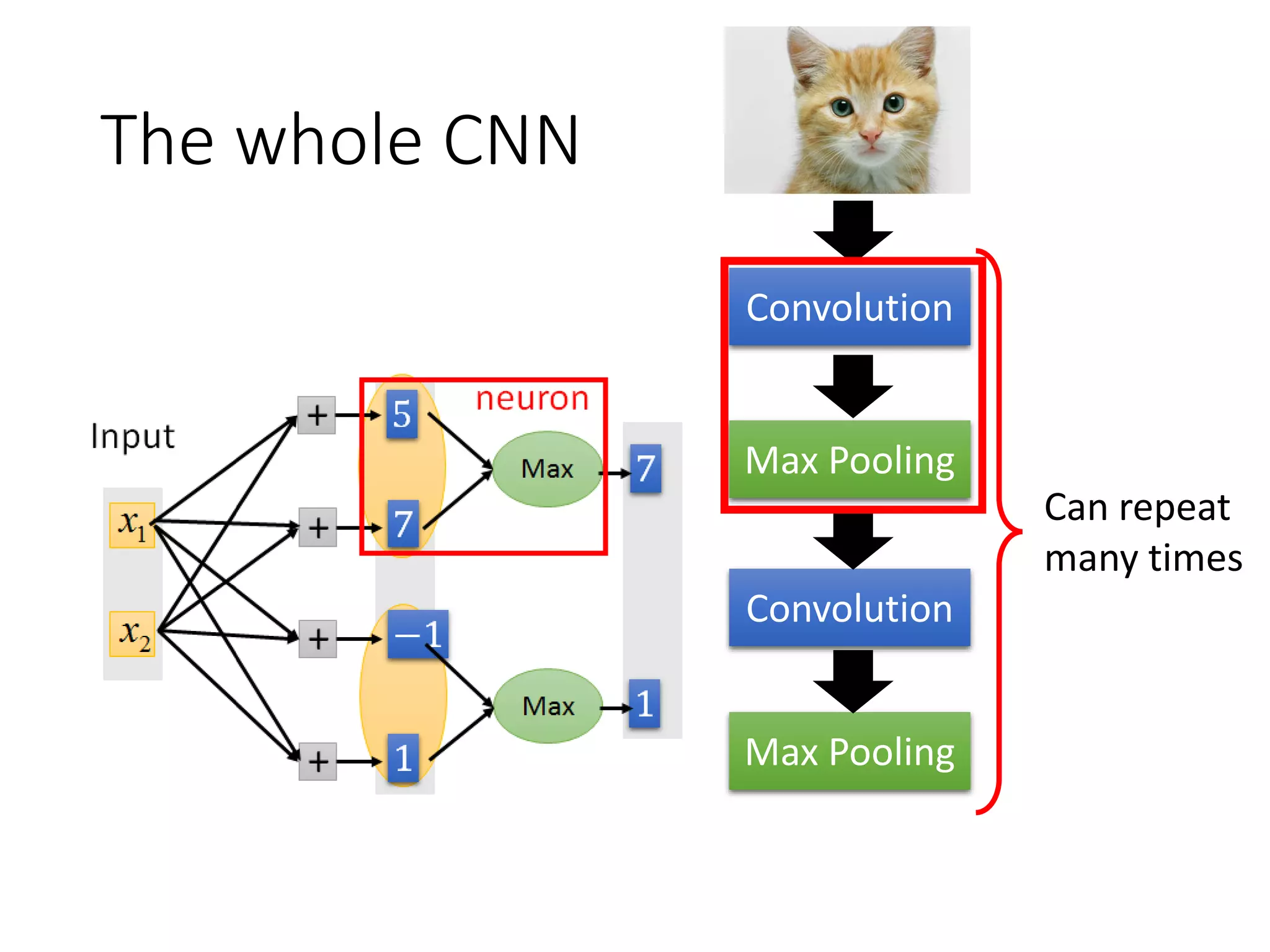
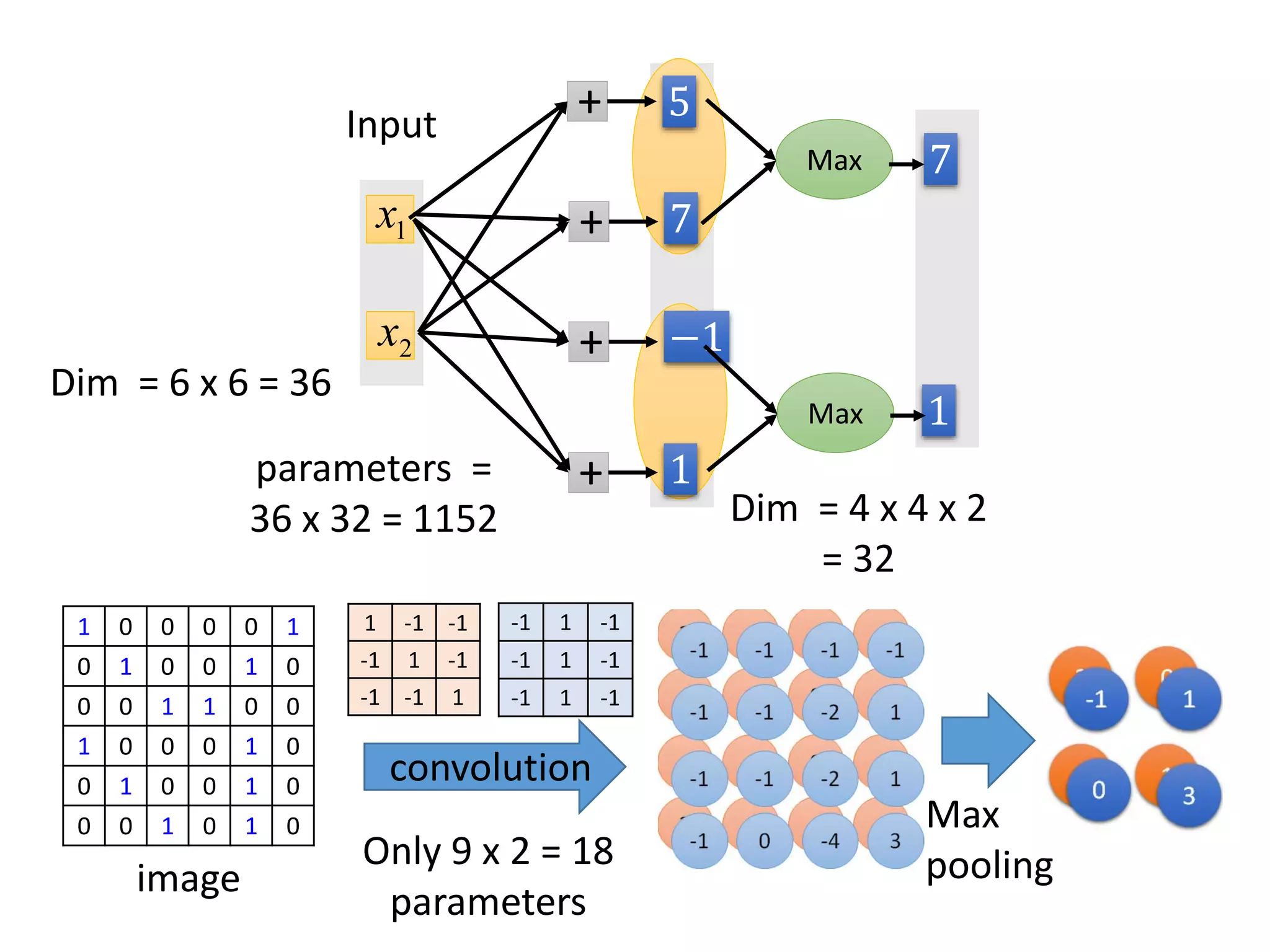
![Maxout
• Learnable activation function [Ian J. Goodfellow, ICML’13]
Max
1x
2x
Input
Max
+ 5
+ 7
+ −1
+ 1
7
1
Max
Max
+ 1
+ 2
+ 4
+ 3
2
4
ReLU is a special cases of Maxout
You can have more than 2 elements in a group.
neuron](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-98-2048.jpg)
![Maxout
• Learnable activation function [Ian J. Goodfellow, ICML’13]
• Activation function in maxout network can be
any piecewise linear convex function
• How many pieces depending on how many
elements in a group
ReLU is a special cases of Maxout
2 elements in a group 3 elements in a group](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-99-2048.jpg)





![Not the whole story ……
• Adagrad [John Duchi, JMLR’11]
• RMSprop
• https://www.youtube.com/watch?v=O3sxAc4hxZU
• Adadelta [Matthew D. Zeiler, arXiv’12]
• “No more pesky learning rates” [Tom Schaul, arXiv’12]
• AdaSecant [Caglar Gulcehre, arXiv’14]
• Adam [Diederik P. Kingma, ICLR’15]
• Nadam
• http://cs229.stanford.edu/proj2015/054_report.pdf](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-107-2048.jpg)








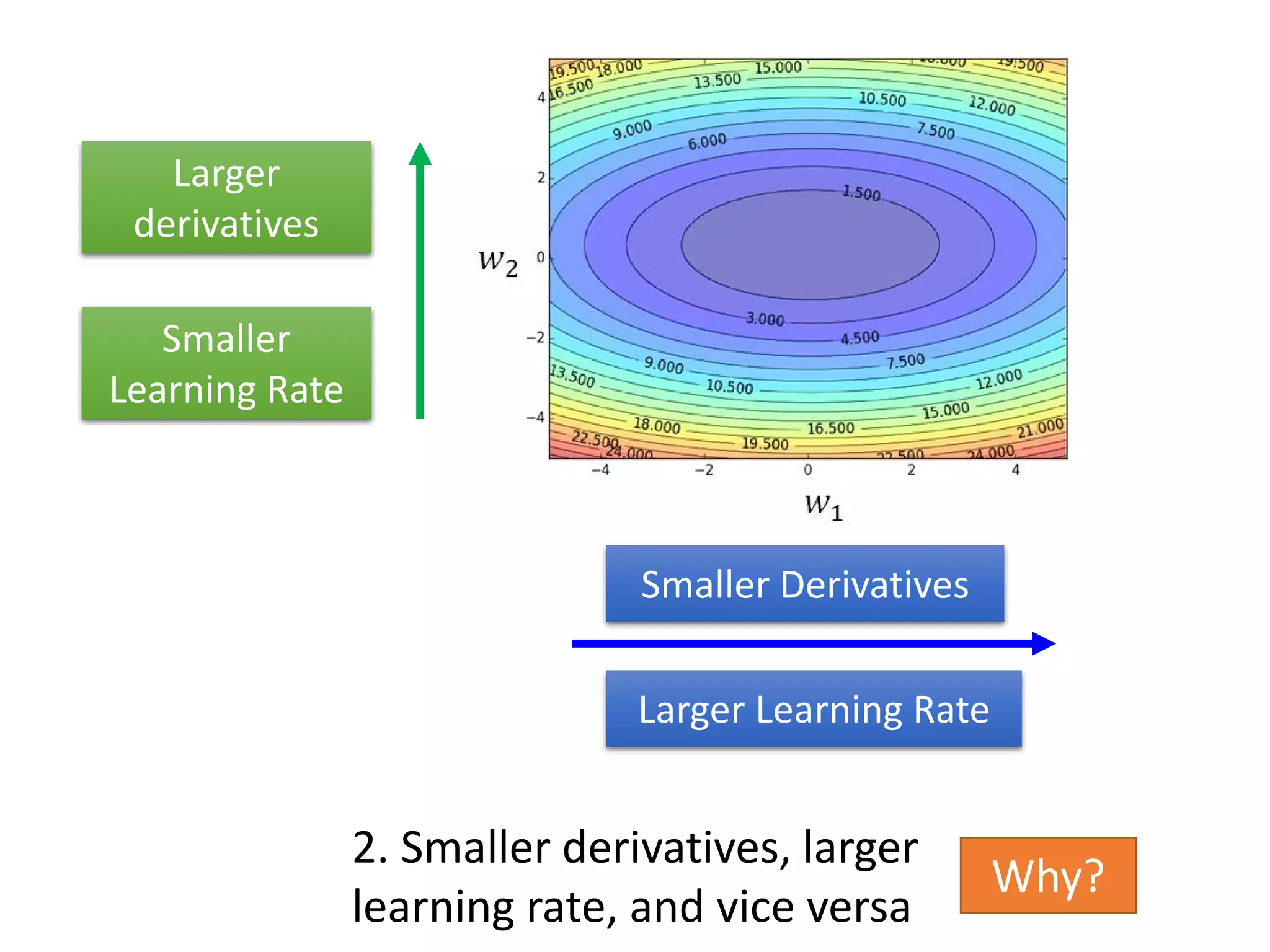

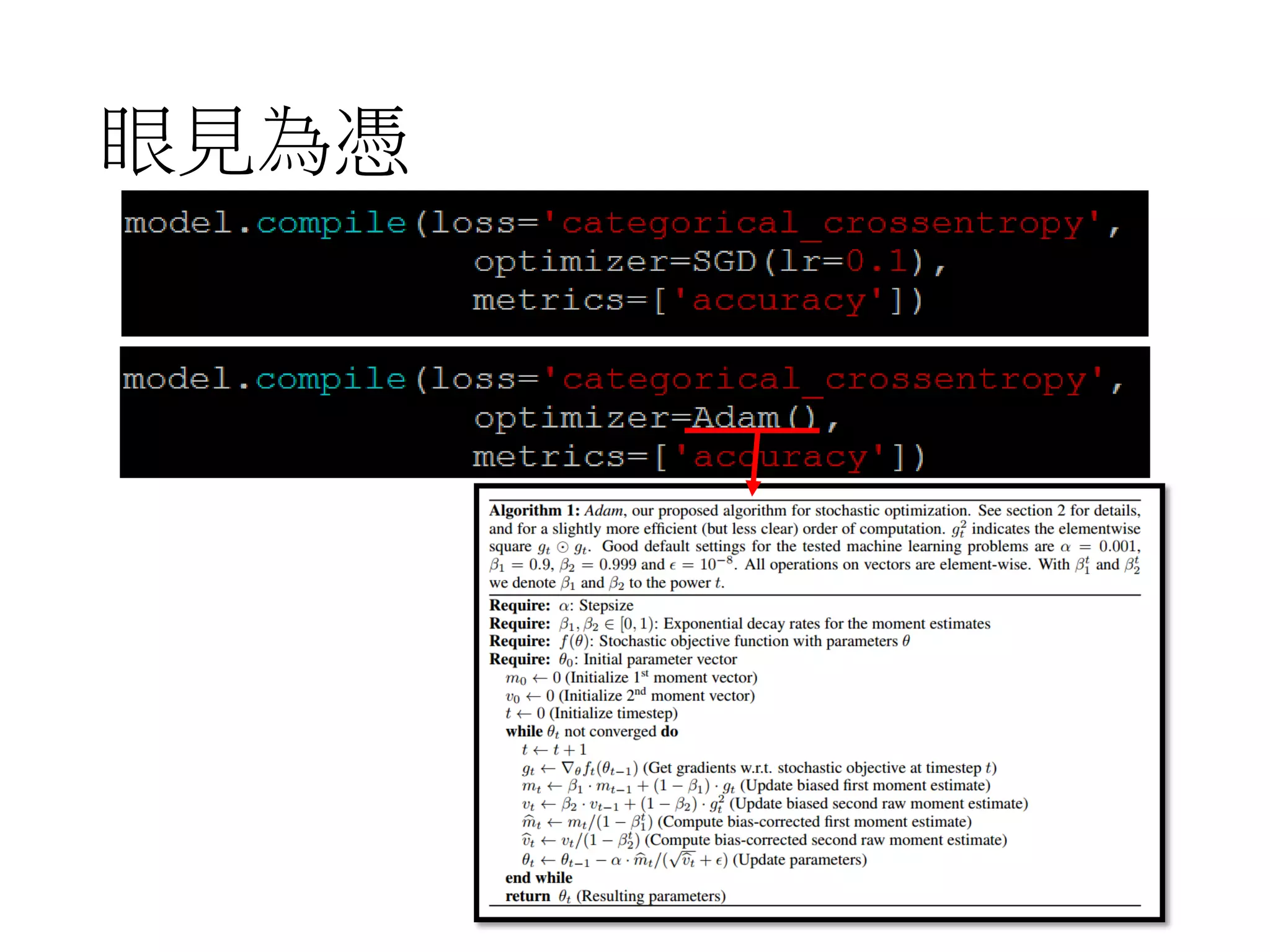

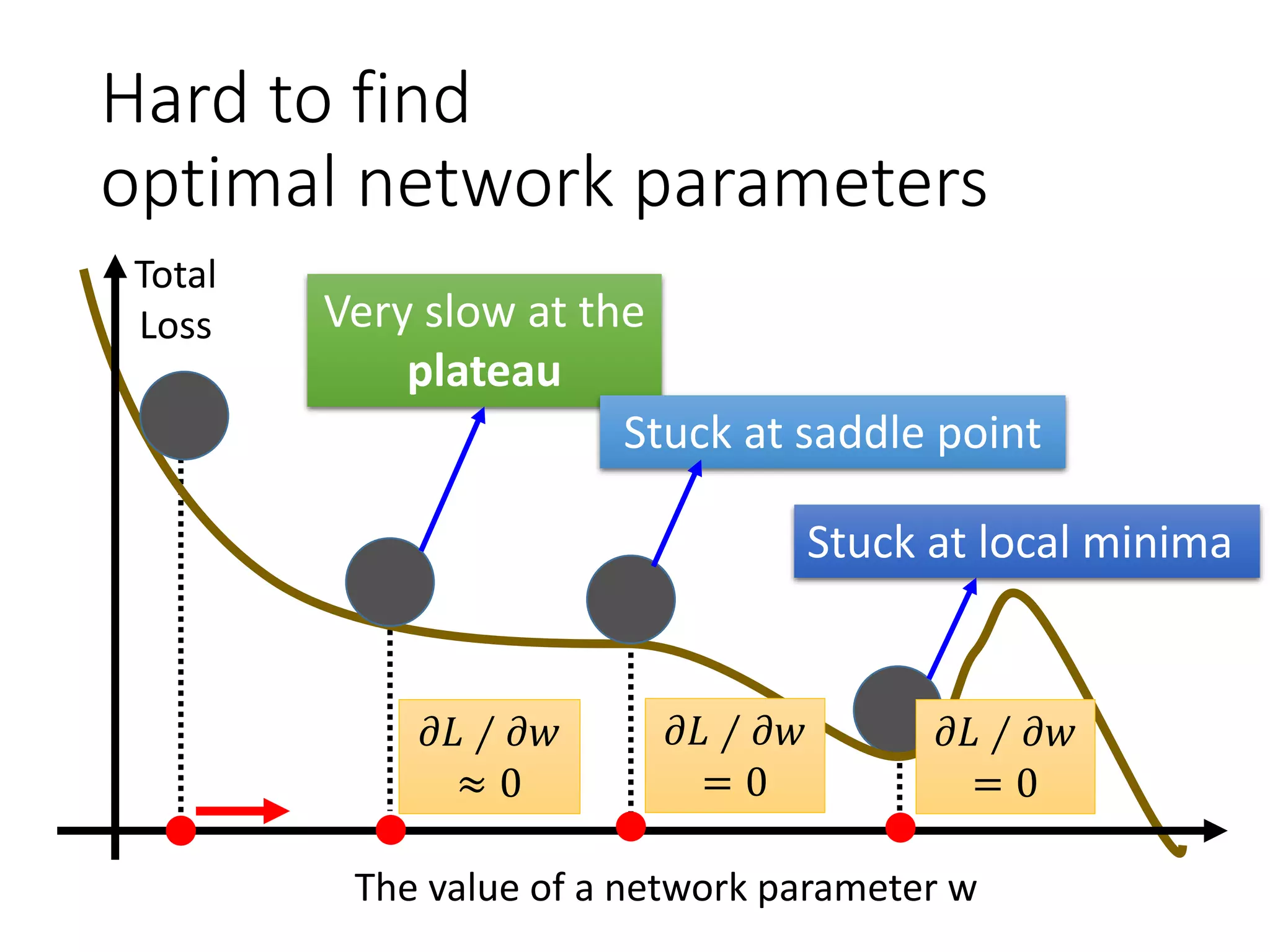









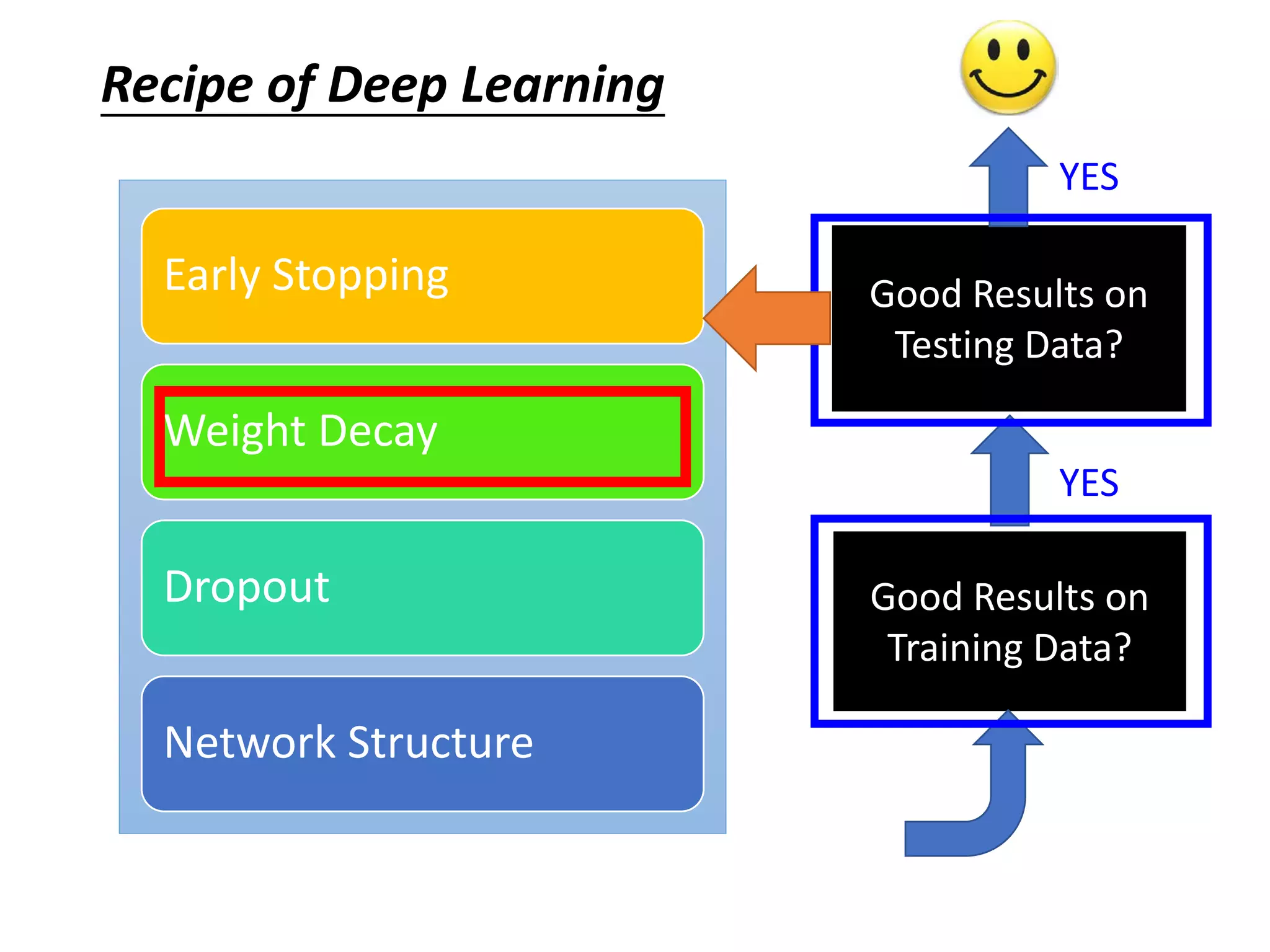



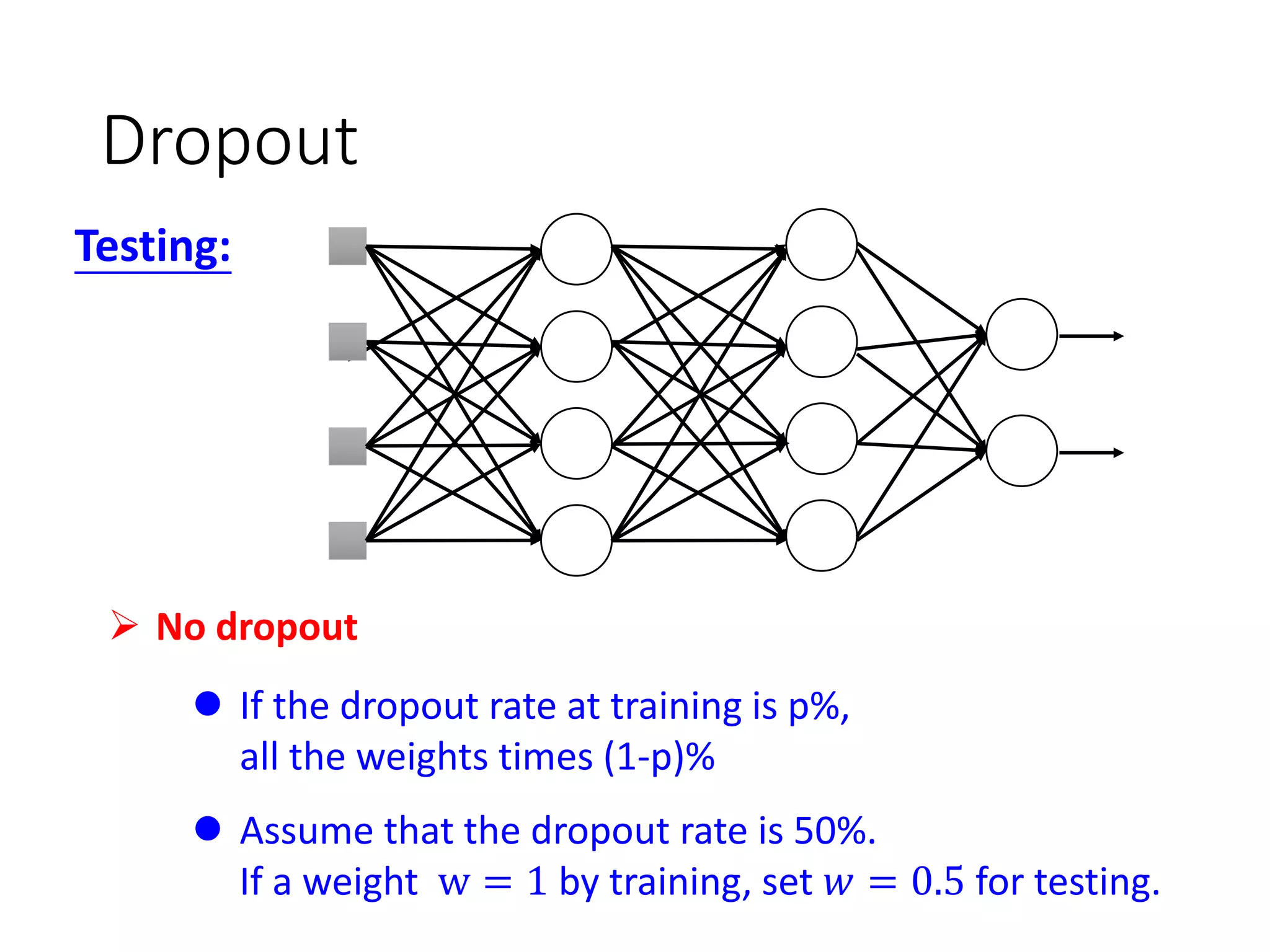
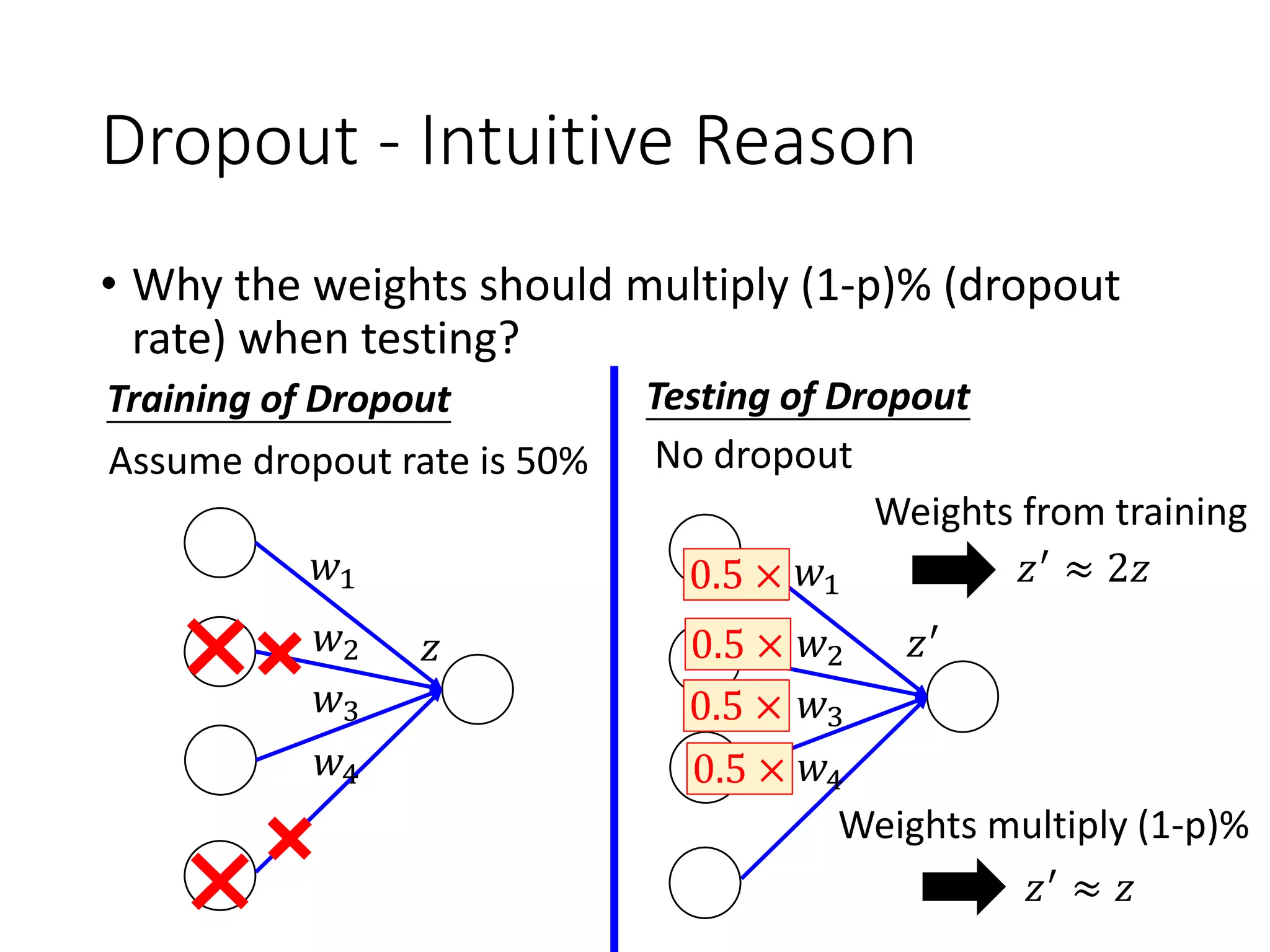
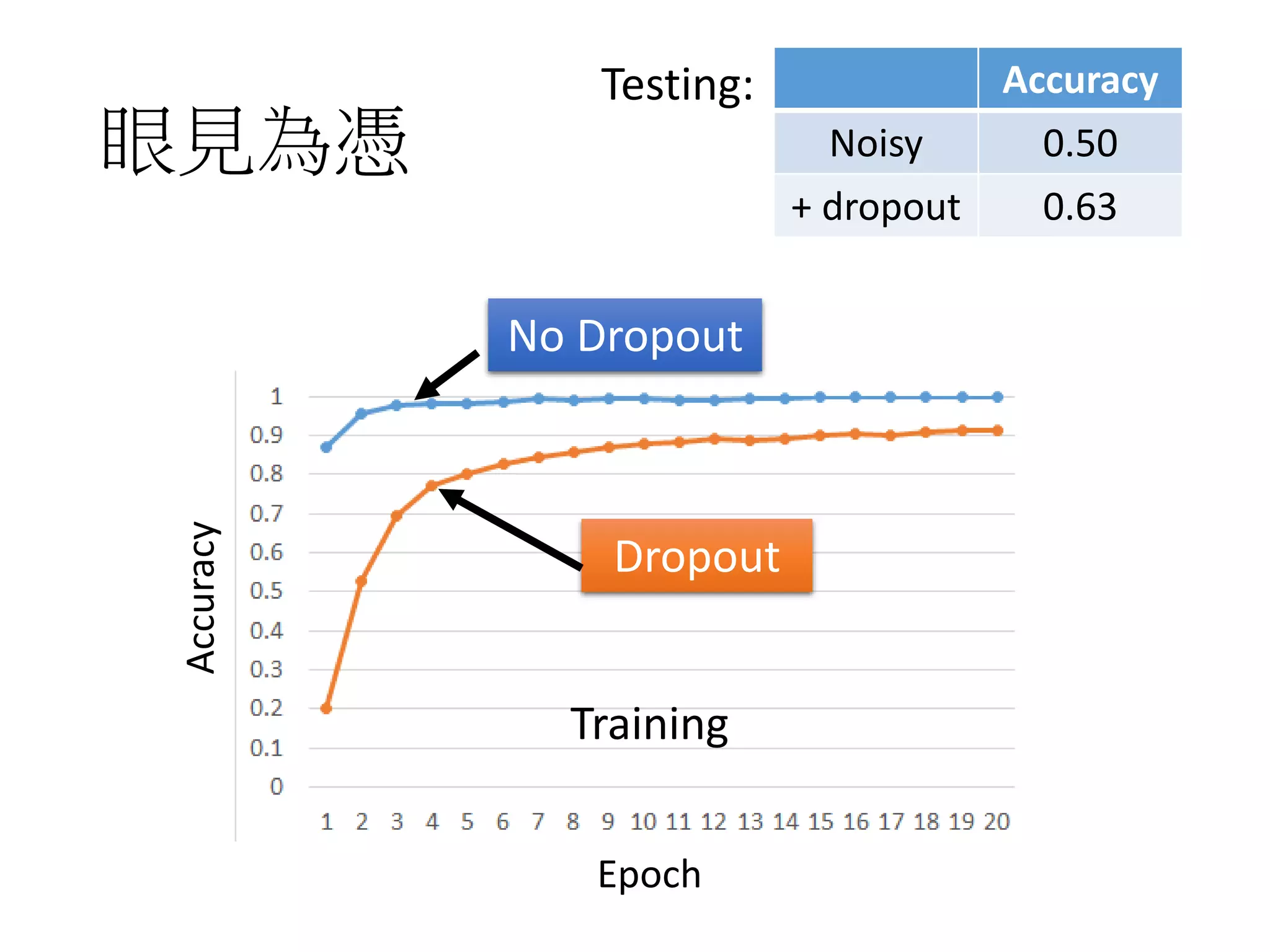
![More about dropout
• More reference for dropout [Nitish Srivastava, JMLR’14] [Pierre Baldi,
NIPS’13][Geoffrey E. Hinton, arXiv’12]
• Dropout works better with Maxout [Ian J. Goodfellow, ICML’13]
• Dropconnect [Li Wan, ICML’13]
• Dropout delete neurons
• Dropconnect deletes the connection between neurons
• Annealed dropout [S.J. Rennie, SLT’14]
• Dropout rate decreases by epochs
• Standout [J. Ba, NISP’13]
• Each neural has different dropout rate](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-135-2048.jpg)











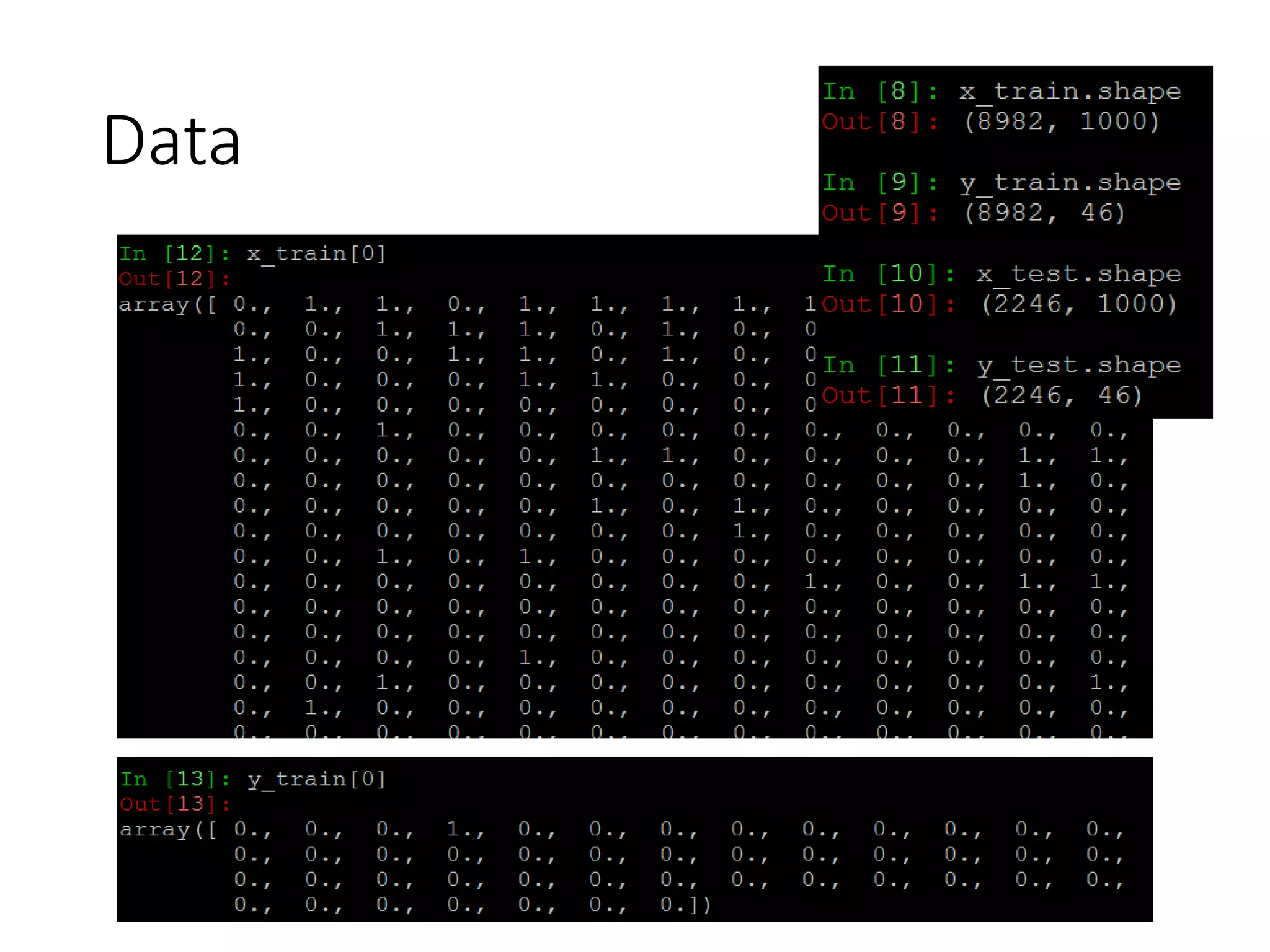






















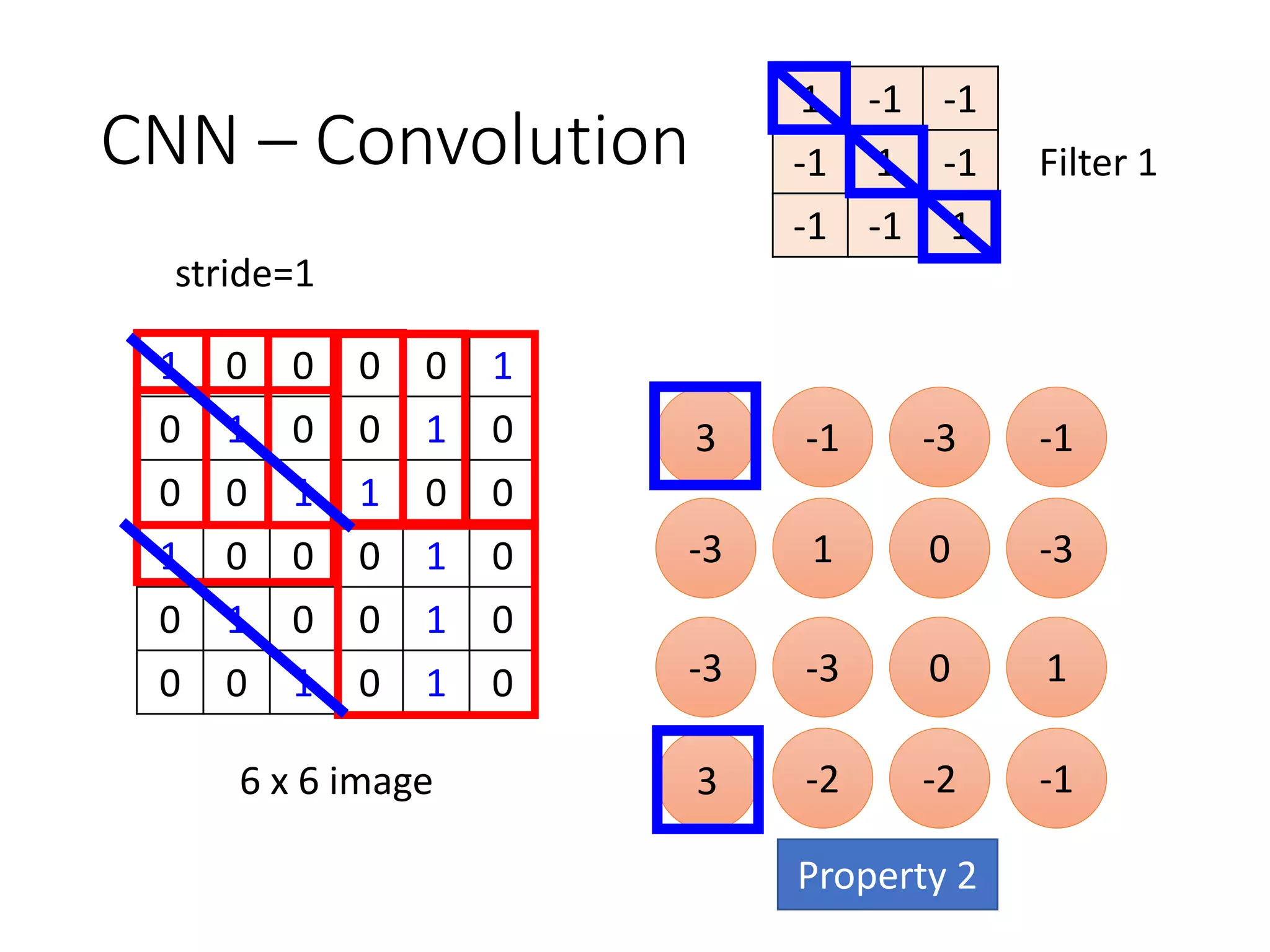




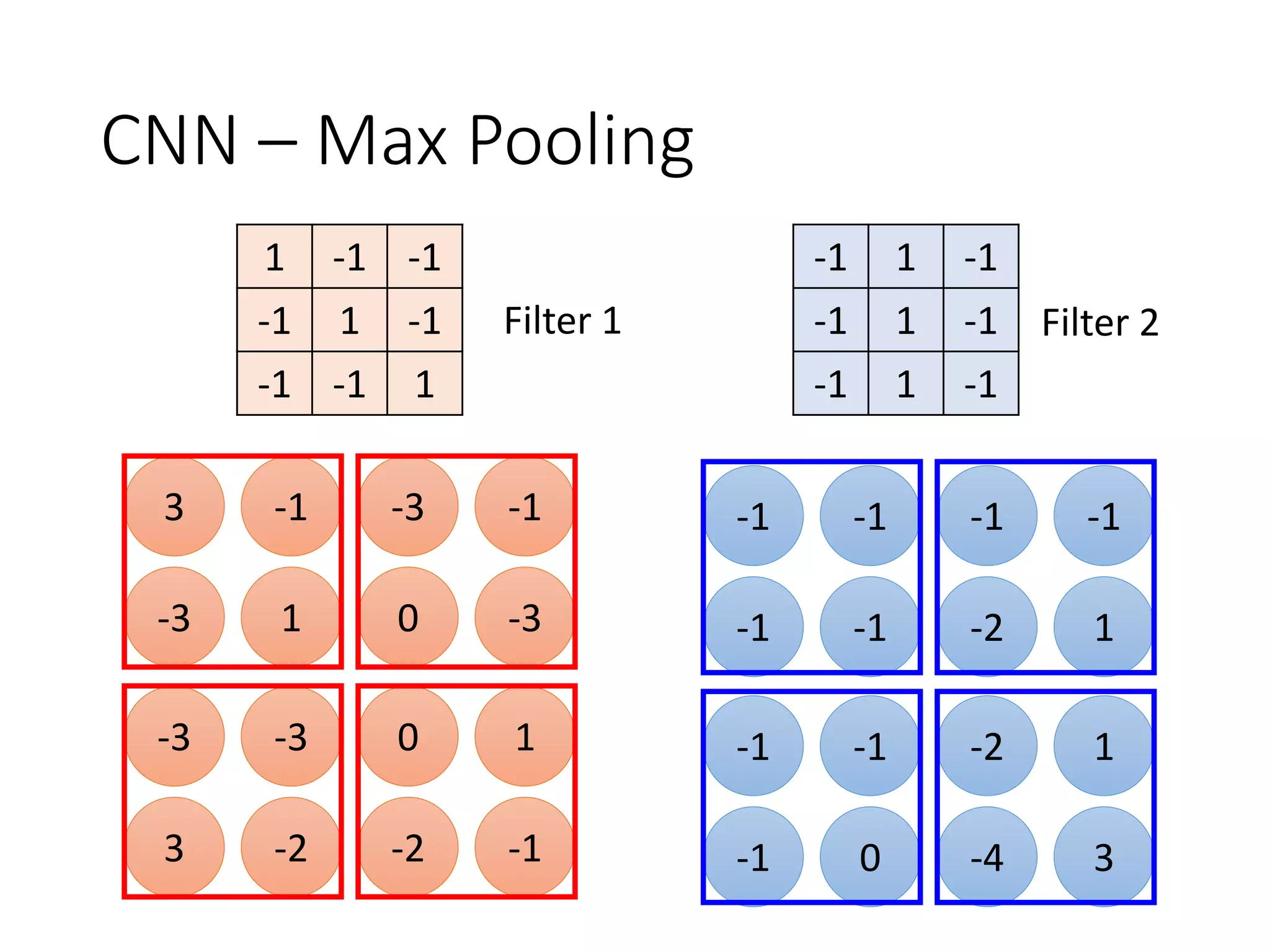

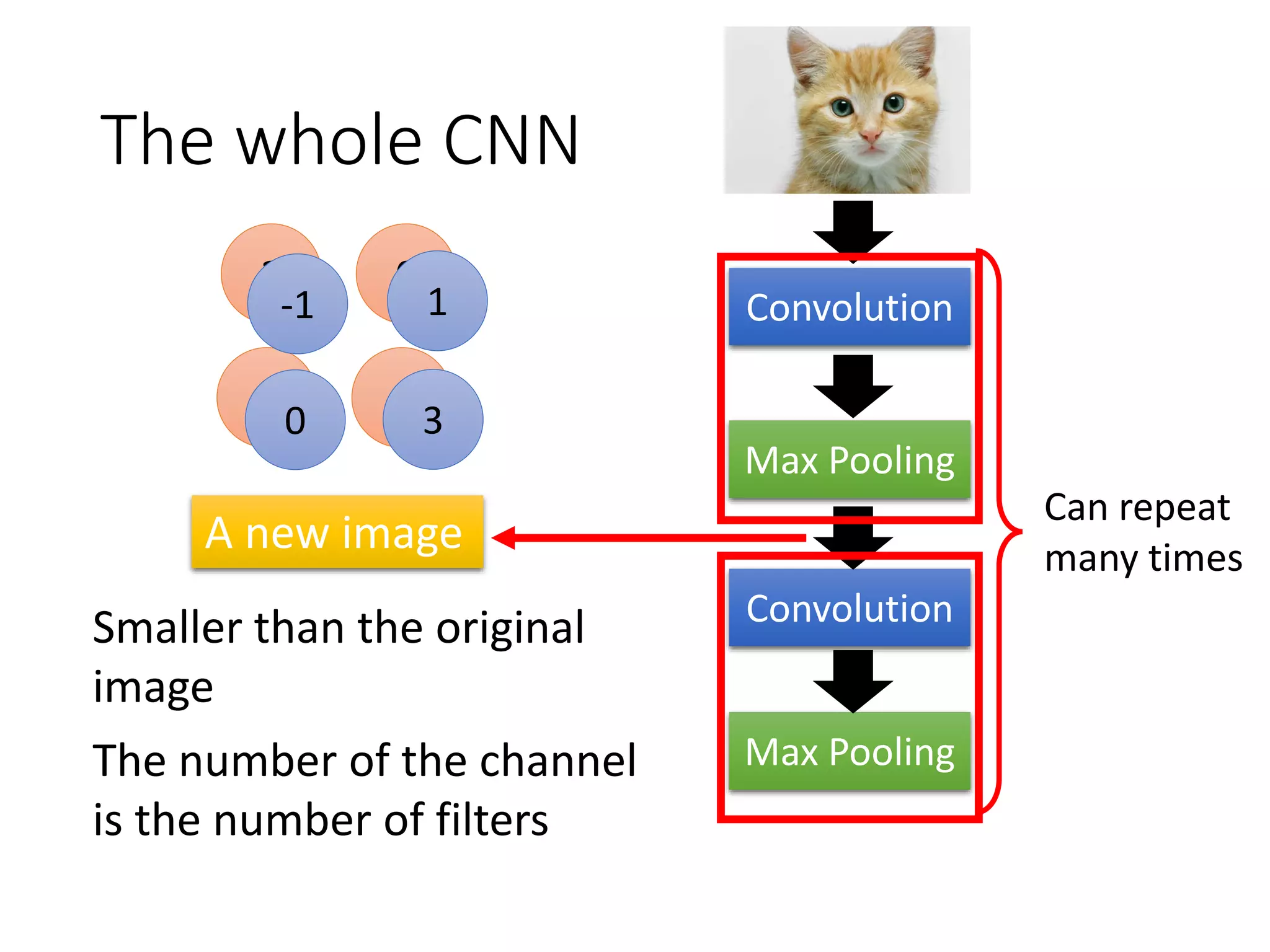

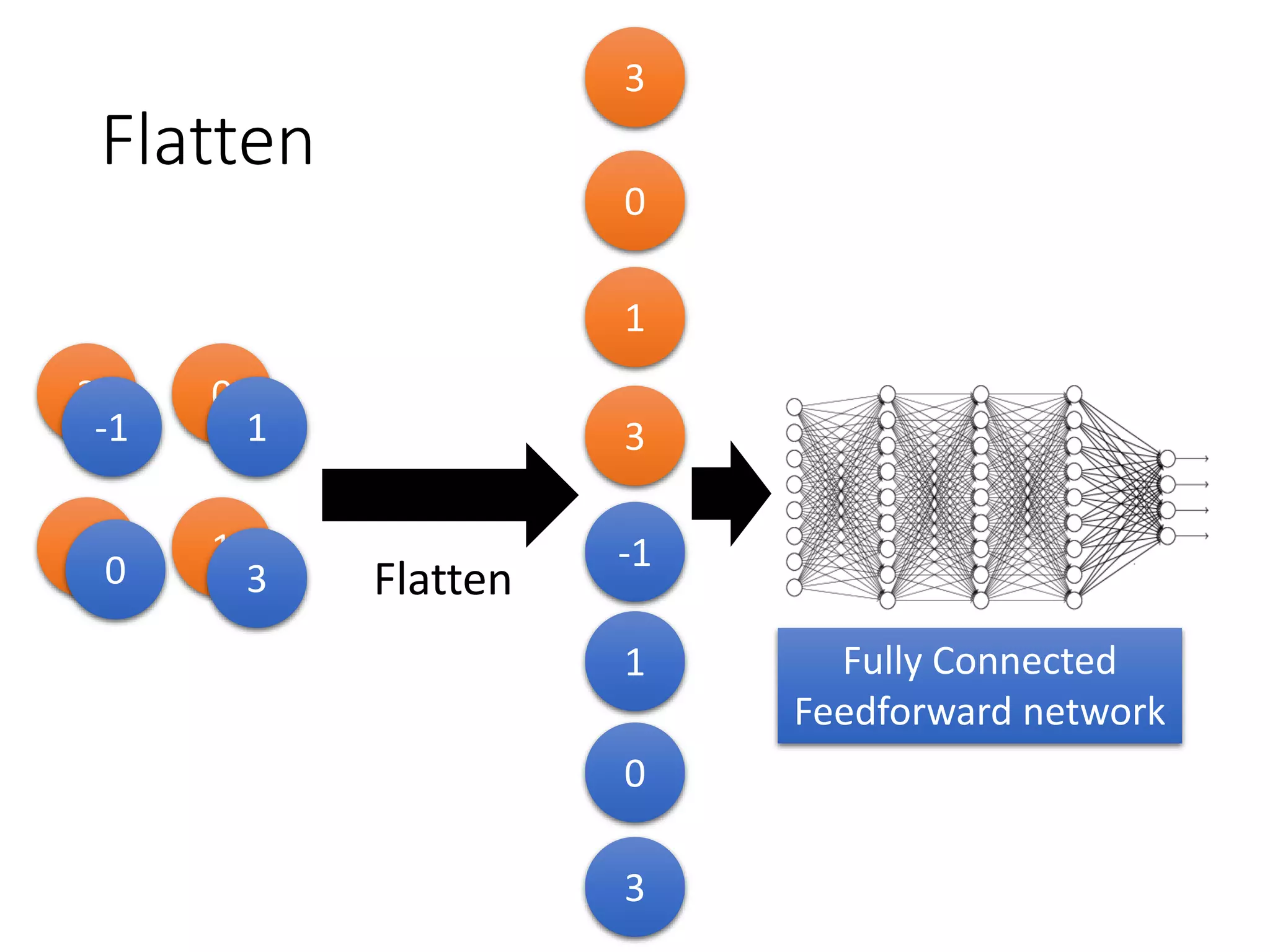


![1-of-N encoding
Each dimension corresponds
to a word in the lexicon
The dimension for the word
is 1, and others are 0
lexicon = {apple, bag, cat, dog, elephant}
apple = [ 1 0 0 0 0]
bag = [ 0 1 0 0 0]
cat = [ 0 0 1 0 0]
dog = [ 0 0 0 1 0]
elephant = [ 0 0 0 0 1]
The vector is lexicon size.
1-of-N Encoding
How to represent each word as a vector?](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-186-2048.jpg)













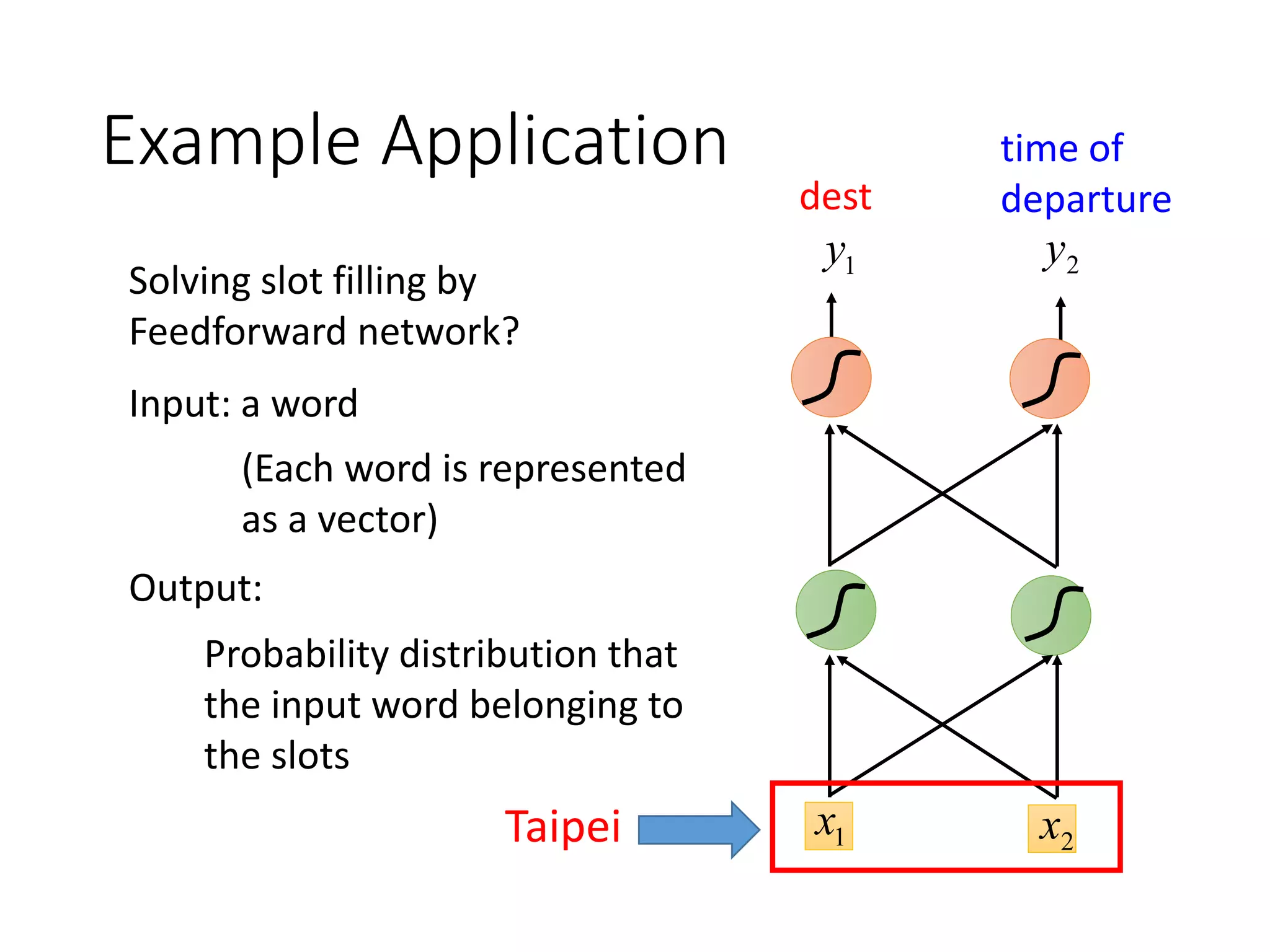
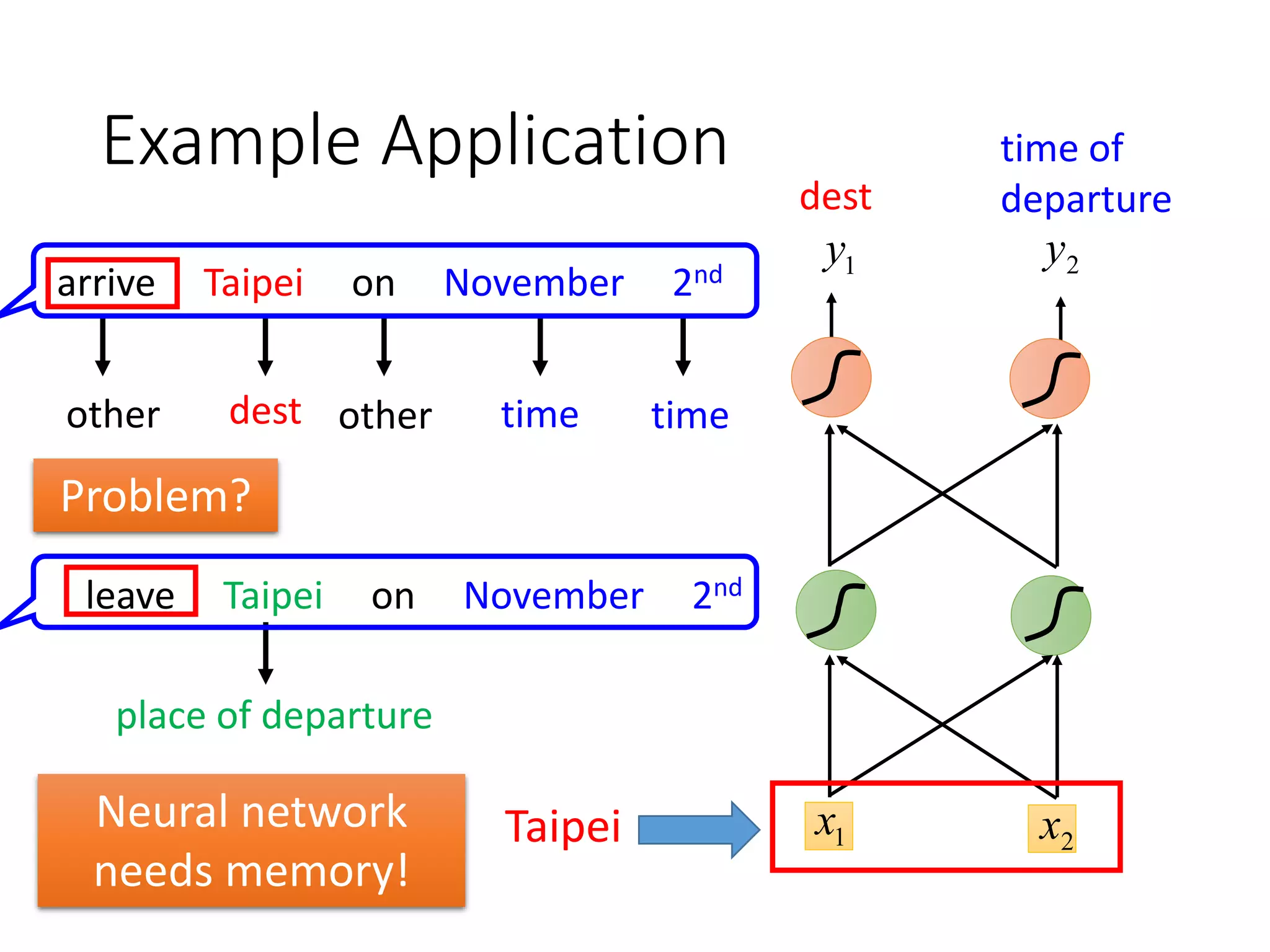


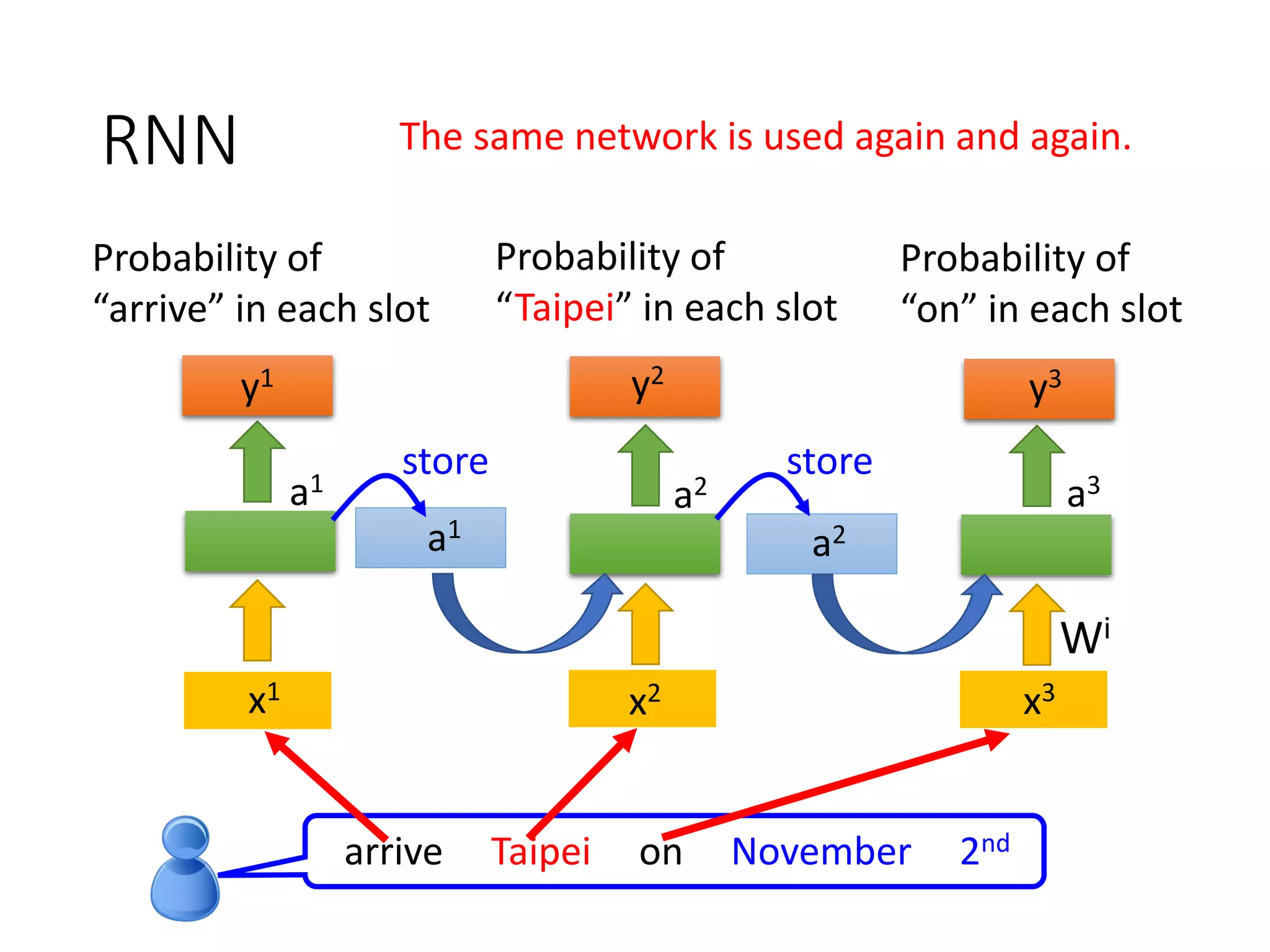


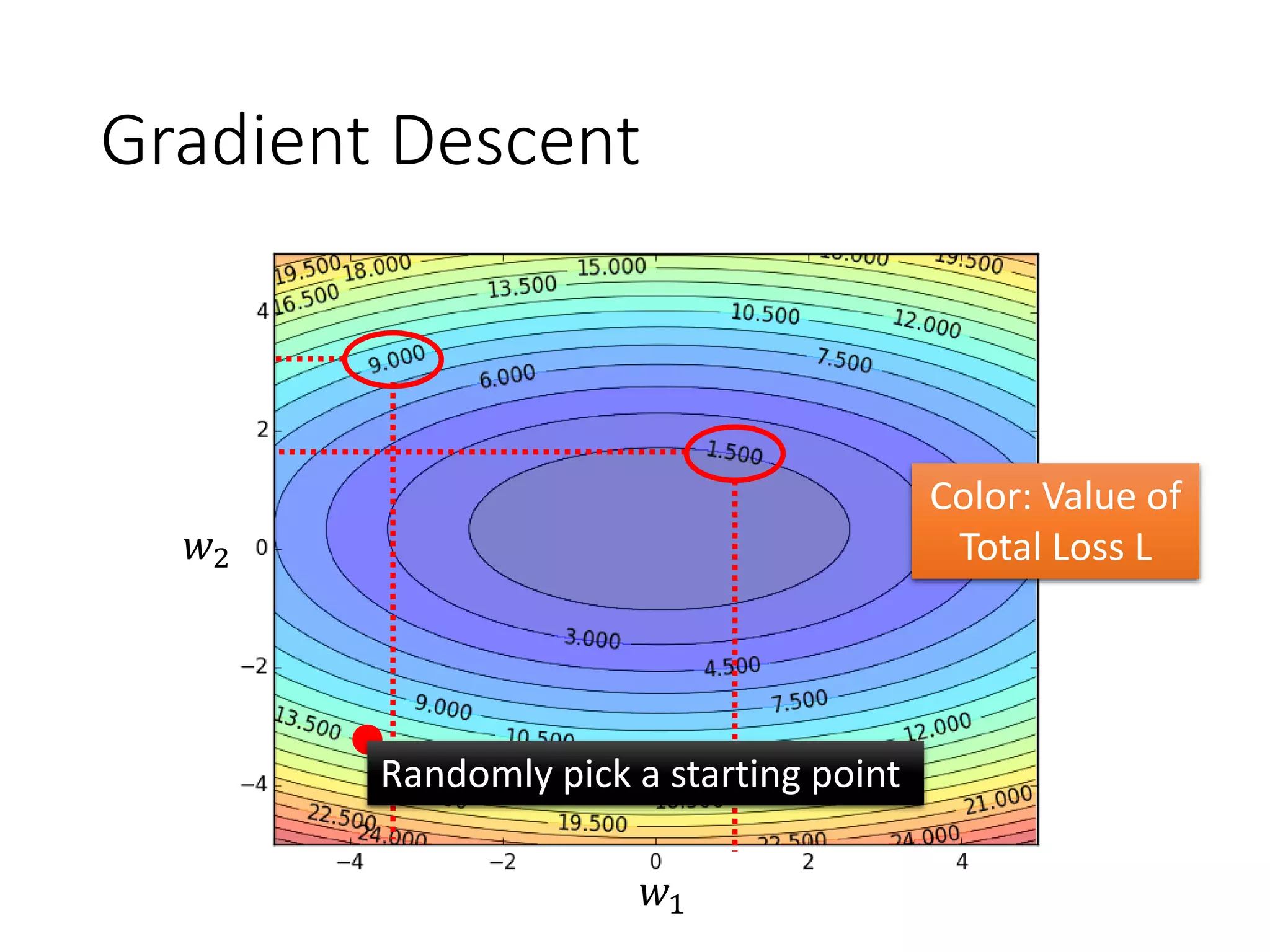
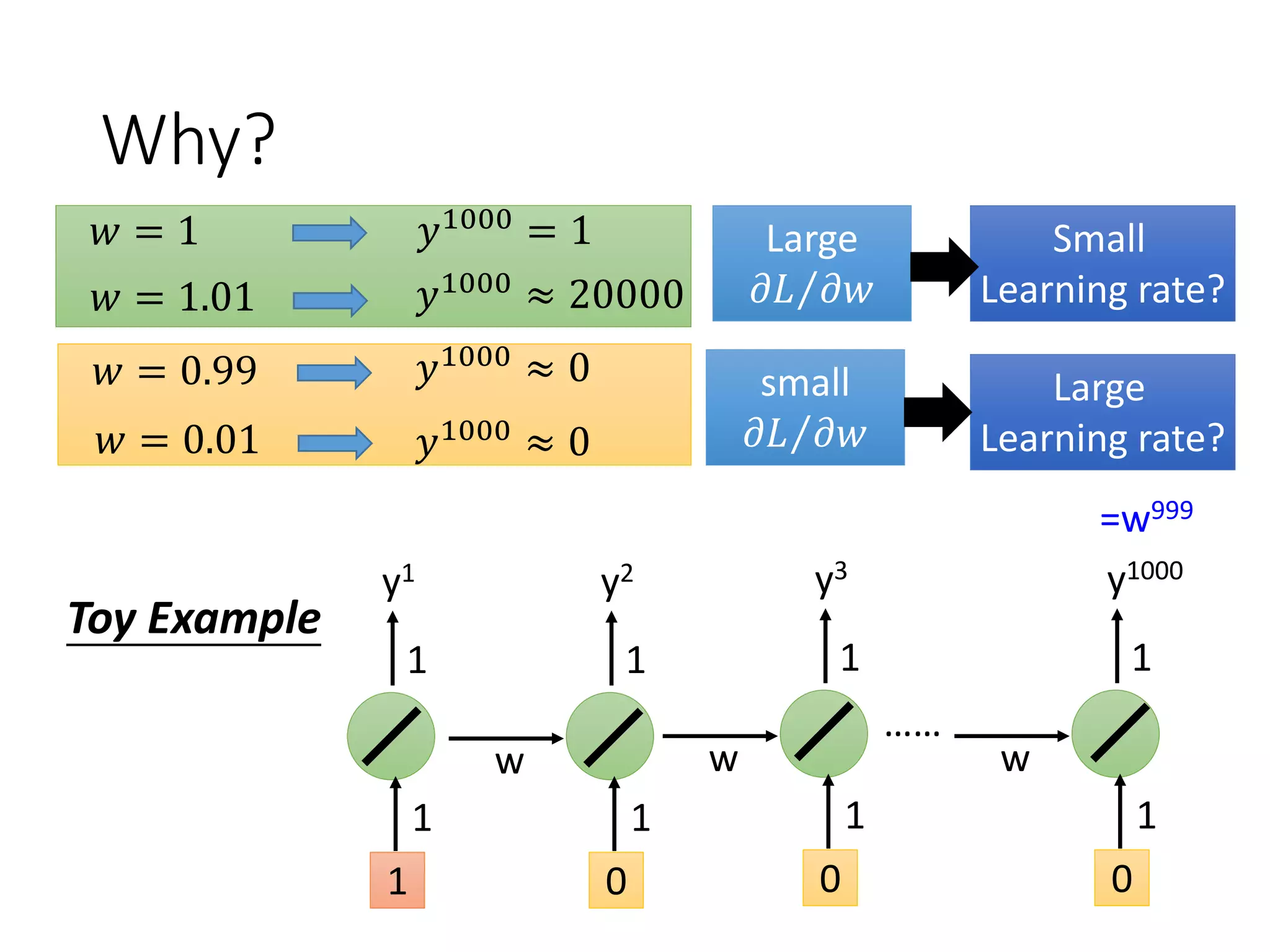
![The error surface is rough.
w1
w2
Cost
The error surface is either
very flat or very steep.
Clipping
[Razvan Pascanu, ICML’13]
TotalLoss](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-209-2048.jpg)

![add
• Long Short-term Memory (LSTM)
• Can deal with gradient vanishing (not gradient
explode)
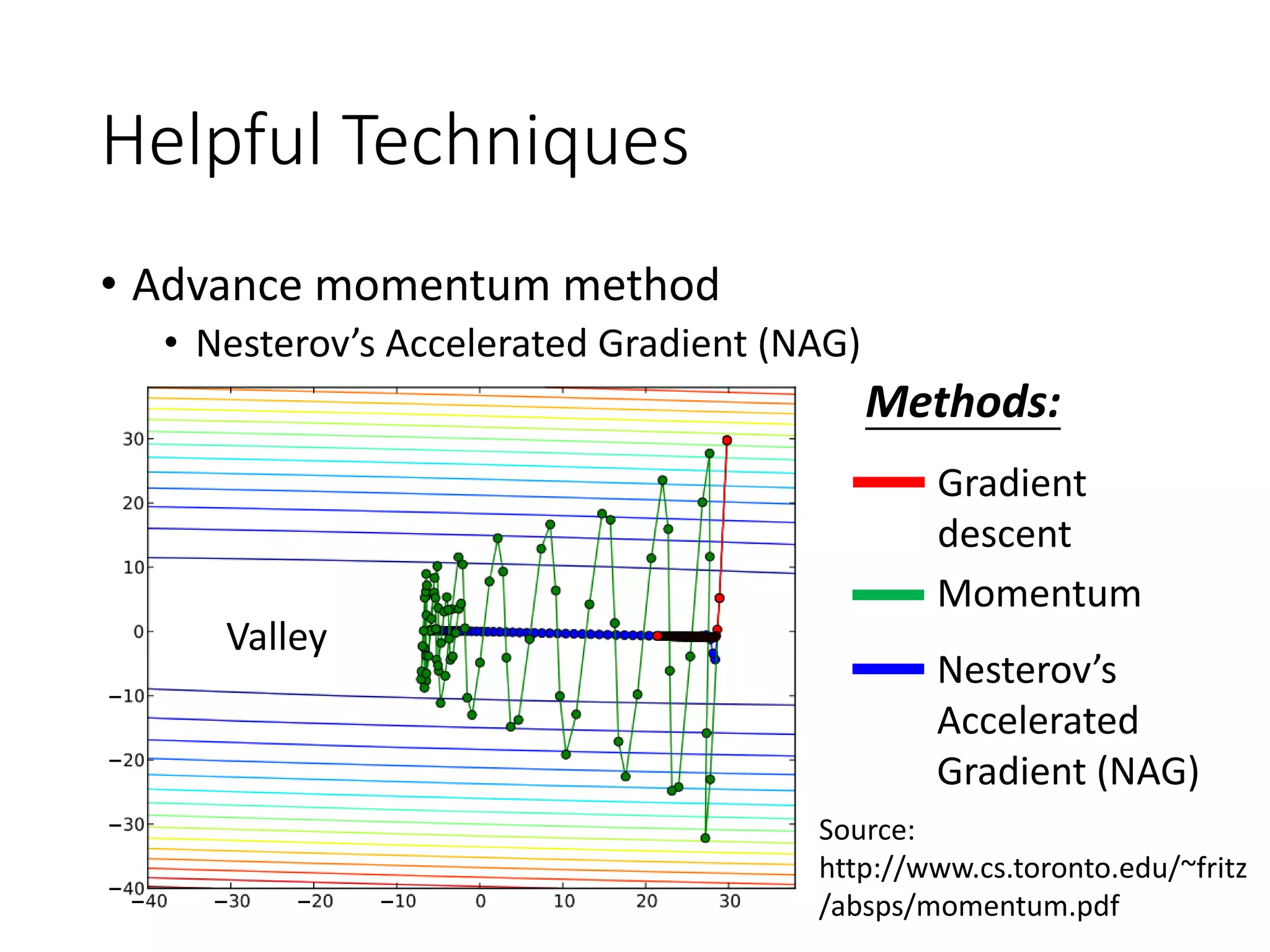
Helpful Techniques
Memory and input are
added
The influence never disappears
unless forget gate is closed
No Gradient vanishing
(If forget gate is opened.)
[Cho, EMNLP’14]
Gated Recurrent Unit (GRU):
simpler than LSTM](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-211-2048.jpg)
![Helpful Techniques
Vanilla RNN Initialized with Identity matrix + ReLU activation
function [Quoc V. Le, arXiv’15]
Outperform or be comparable with LSTM in 4 different tasks
[Jan Koutnik, JMLR’14]
Clockwise RNN
[Tomas Mikolov, ICLR’15]
Structurally Constrained
Recurrent Network (SCRN)](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-212-2048.jpg)

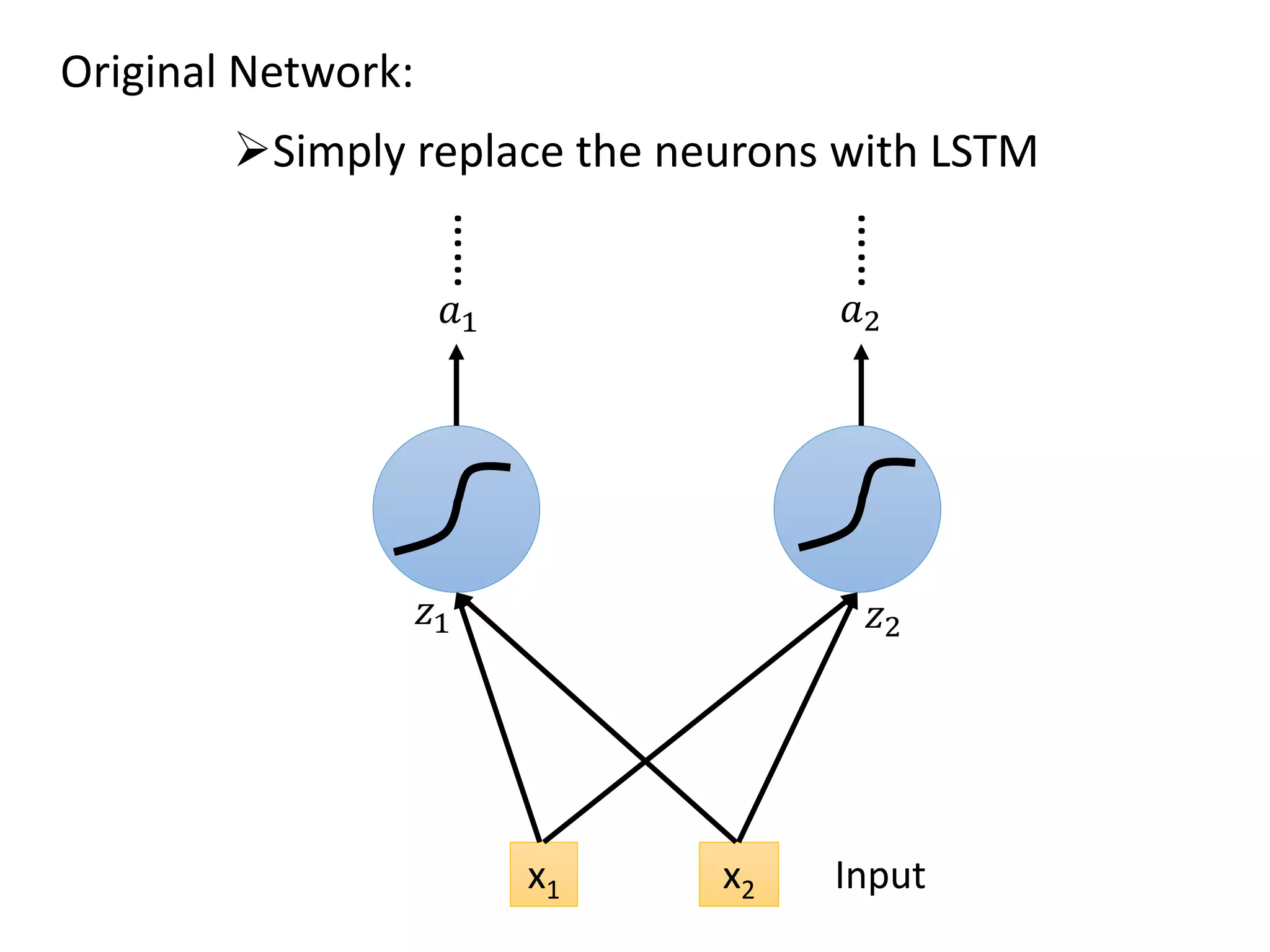

![Many to Many (Output is shorter)
• Both input and output are both sequences, but the output
is shorter.
• Connectionist Temporal Classification (CTC) [Alex Graves,
ICML’06][Alex Graves, ICML’14][Haşim Sak, Interspeech’15][Jie Li,
Interspeech’15][Andrew Senior, ASRU’15]
好 φ φ 棒 φ φ φ φ 好 φ φ 棒 φ 棒 φ φ
“好棒” “好棒棒”Add an extra symbol “φ”
representing “null”](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-216-2048.jpg)



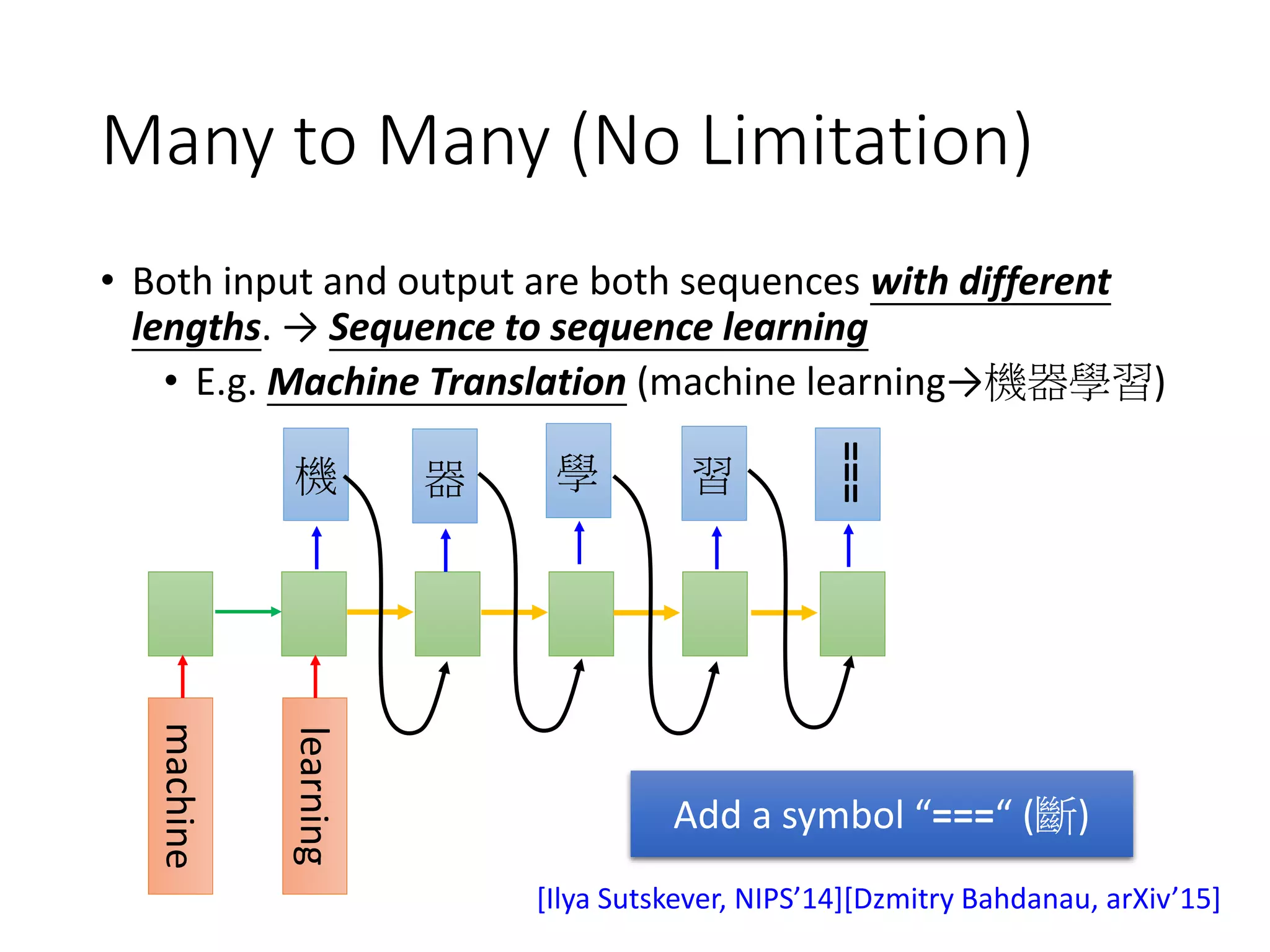
![learning
Many to Many (No Limitation)
• Both input and output are both sequences with different
lengths. → Sequence to sequence learning
• E.g. Machine Translation (machine learning→機器學習)
machine
機 習器 學
Add a symbol “===“ (斷)
[Ilya Sutskever, NIPS’14][Dzmitry Bahdanau, arXiv’15]
===](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-220-2048.jpg)
![One to Many
• Input an image, but output a sequence of words
Input
image
a woman is
……
===
CNN
A vector
for whole
image
[Kelvin Xu, arXiv’15][Li Yao, ICCV’15]
Caption Generation](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-221-2048.jpg)





















![Supervised Learning
Accuracy(%)
(1) (2) (3) (4) (5) (6) (7)
Memory Network: 39.2%
Naive Approaches
Word-based Attention: 48.8%
(proposed by FB AI group)
[Fang & Hsu & Lee, SLT 16]
[Tseng & Lee, Interspeech 16]](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-251-2048.jpg)
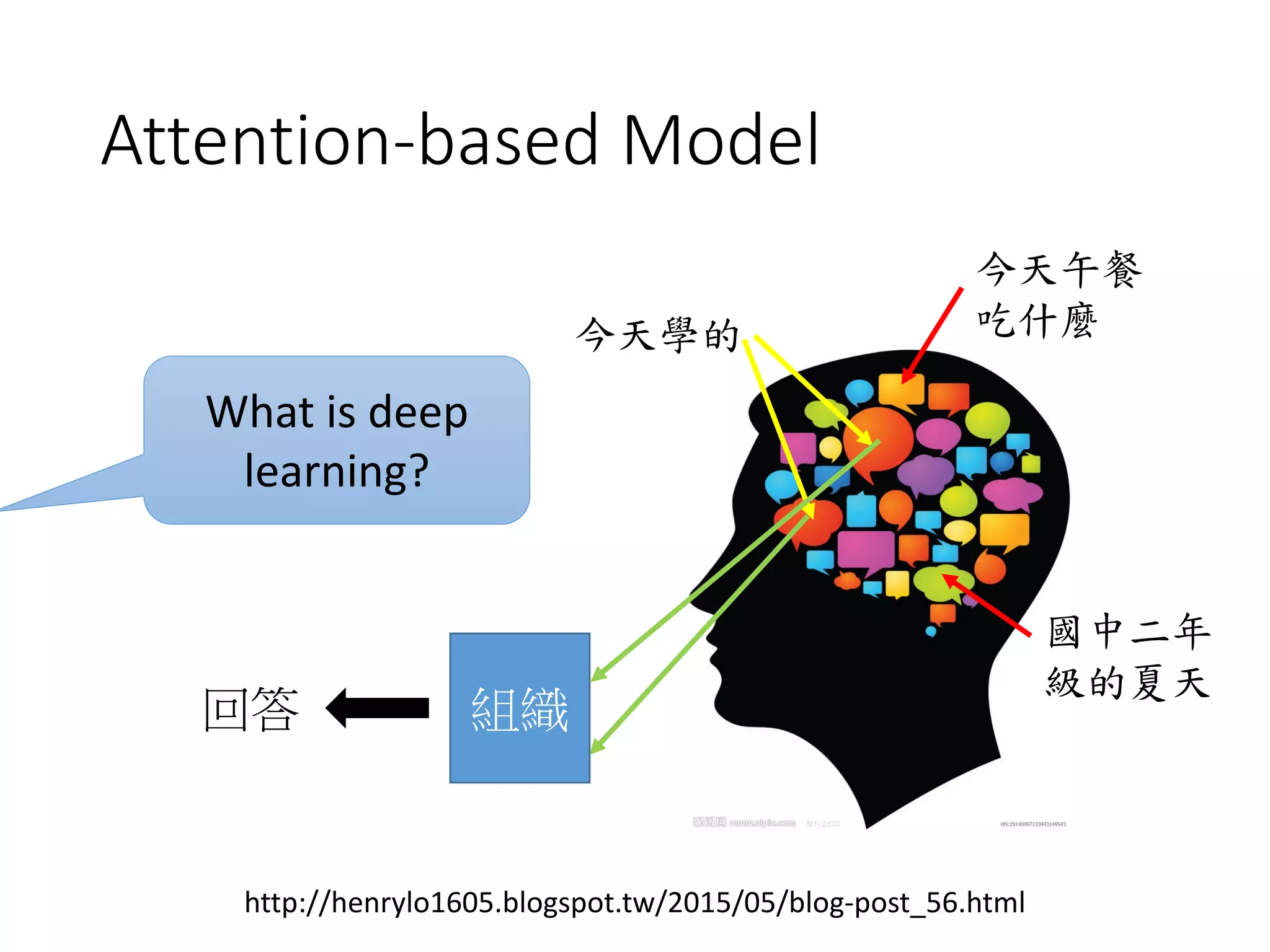


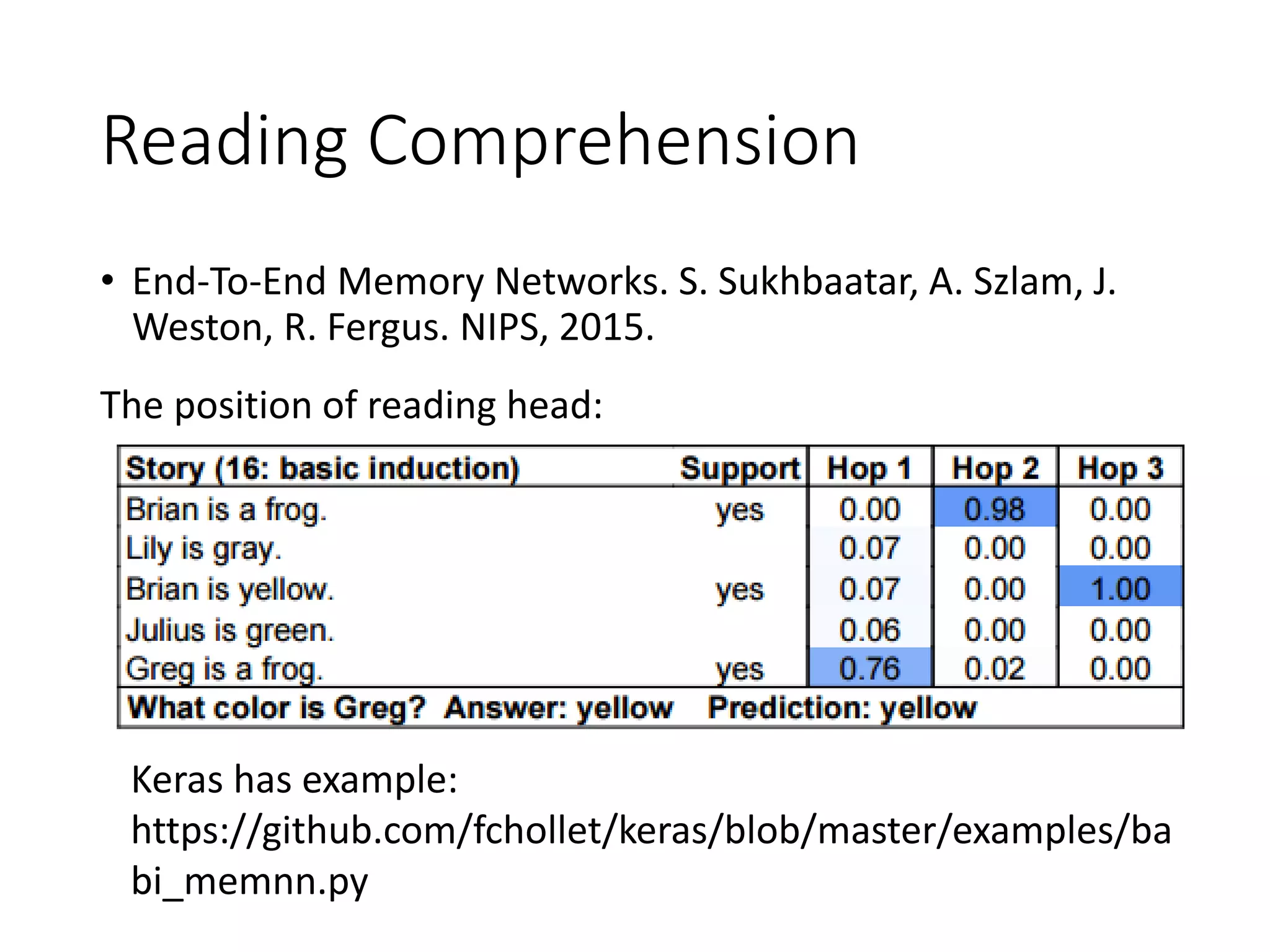

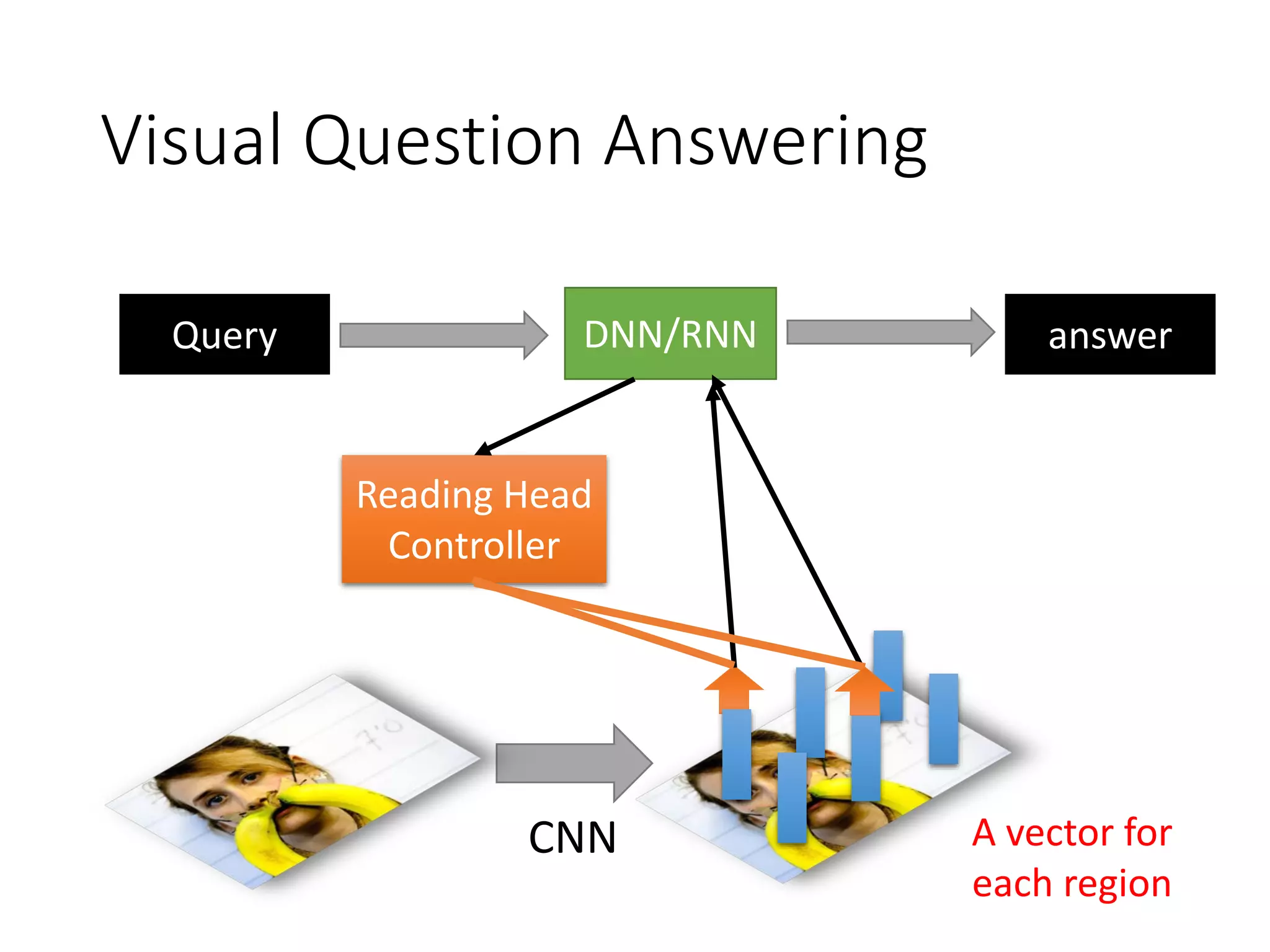


![Application: Interactive Retrieval
• Interactive retrieval is helpful.
user
“Deep Learning”
“Deep Learning” related to Machine Learning?
“Deep Learning” related to Education?
[Wu & Lee, INTERSPEECH 16]](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-260-2048.jpg)

















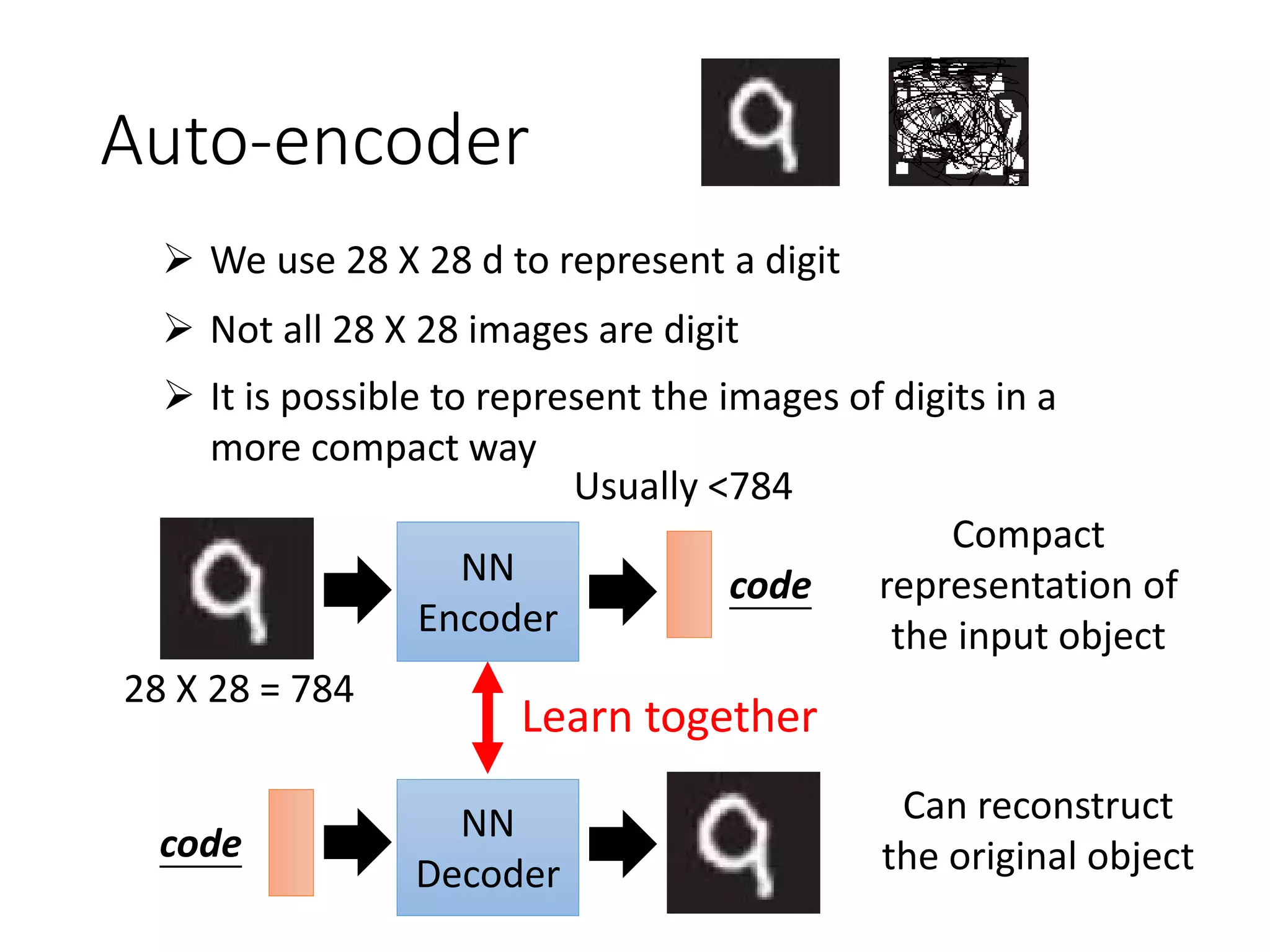
















![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://image.slidesharecdn.com/1-160521014039/75/DSC-2016-301-2048.jpg)

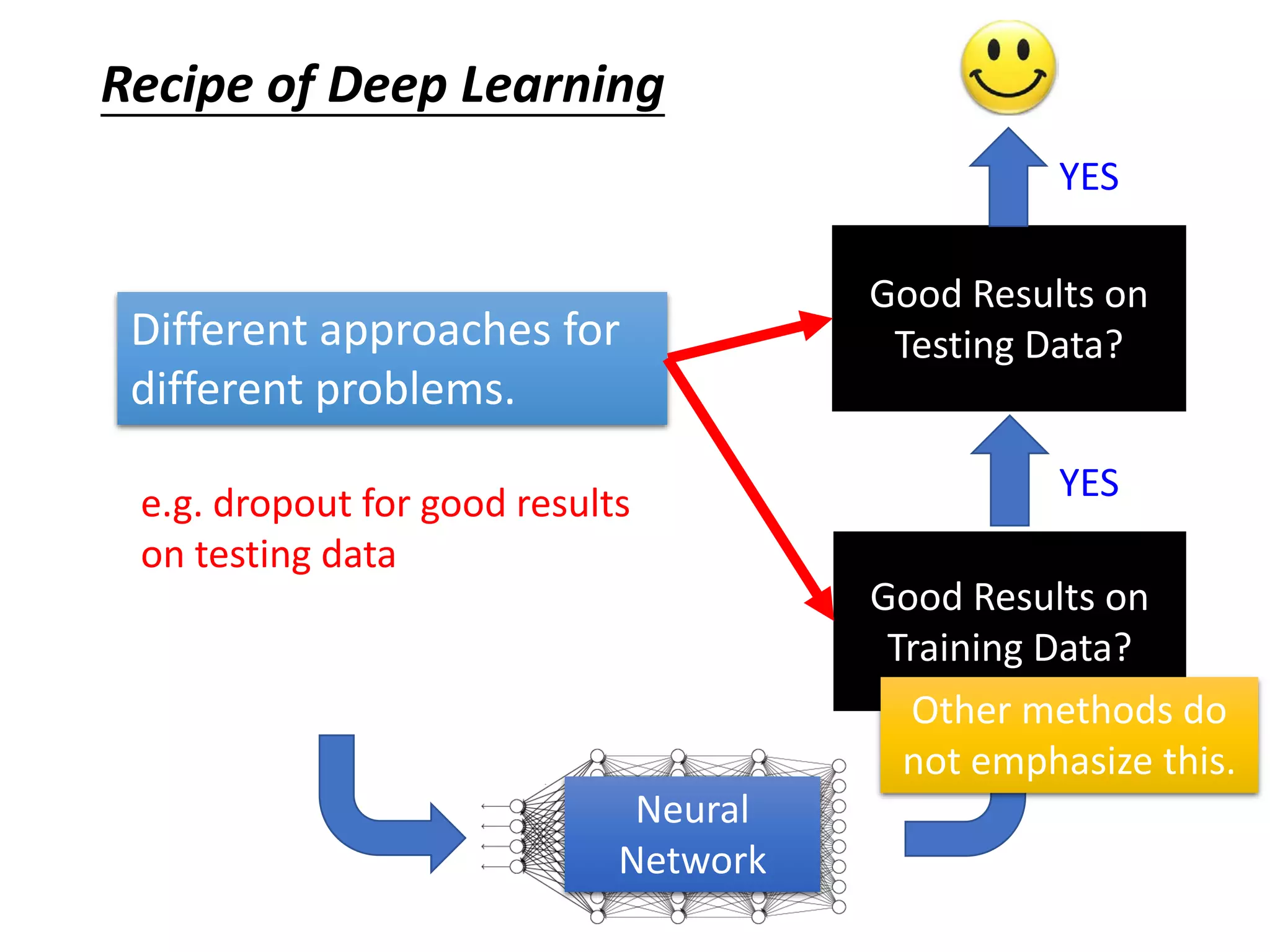
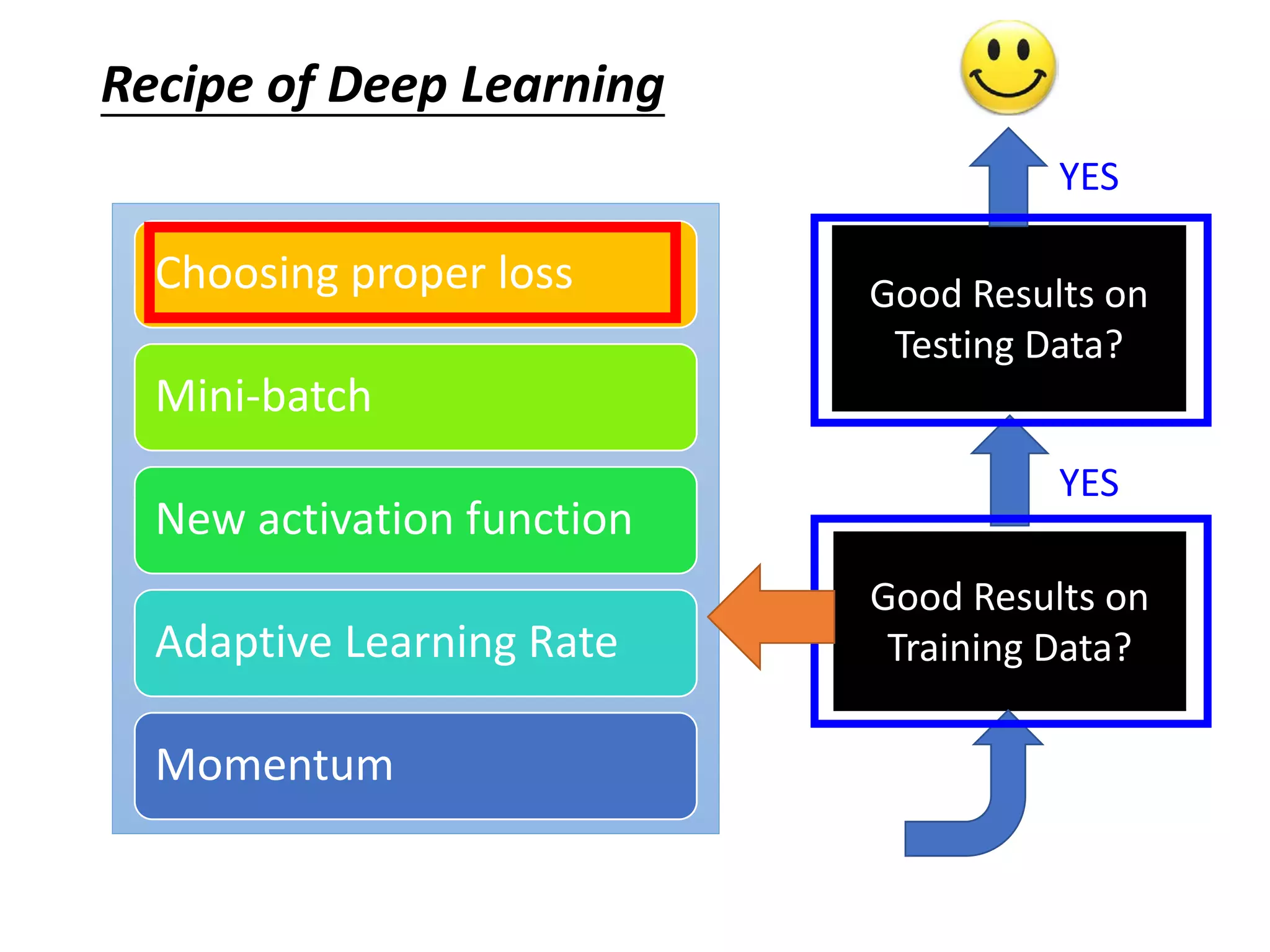
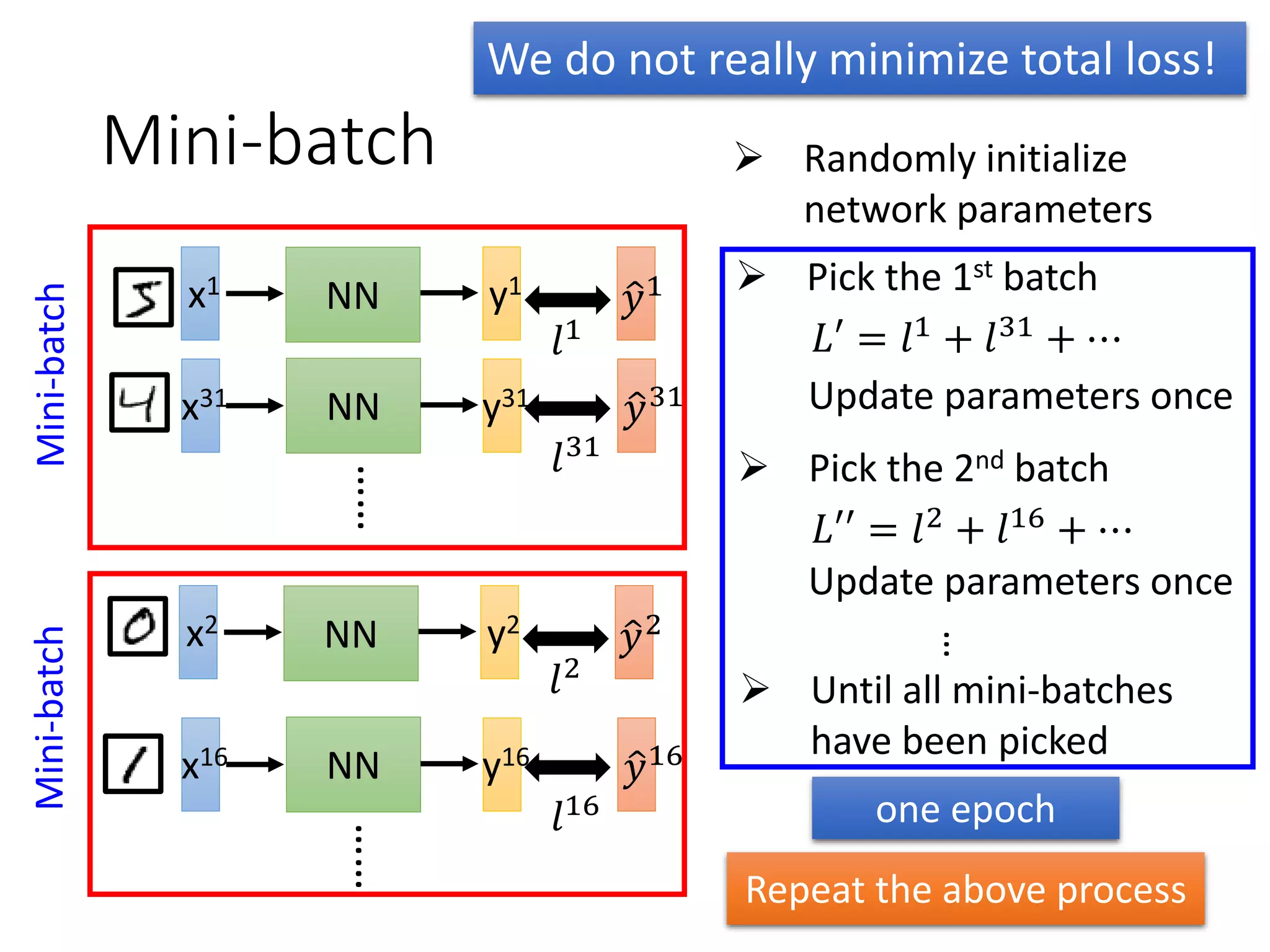
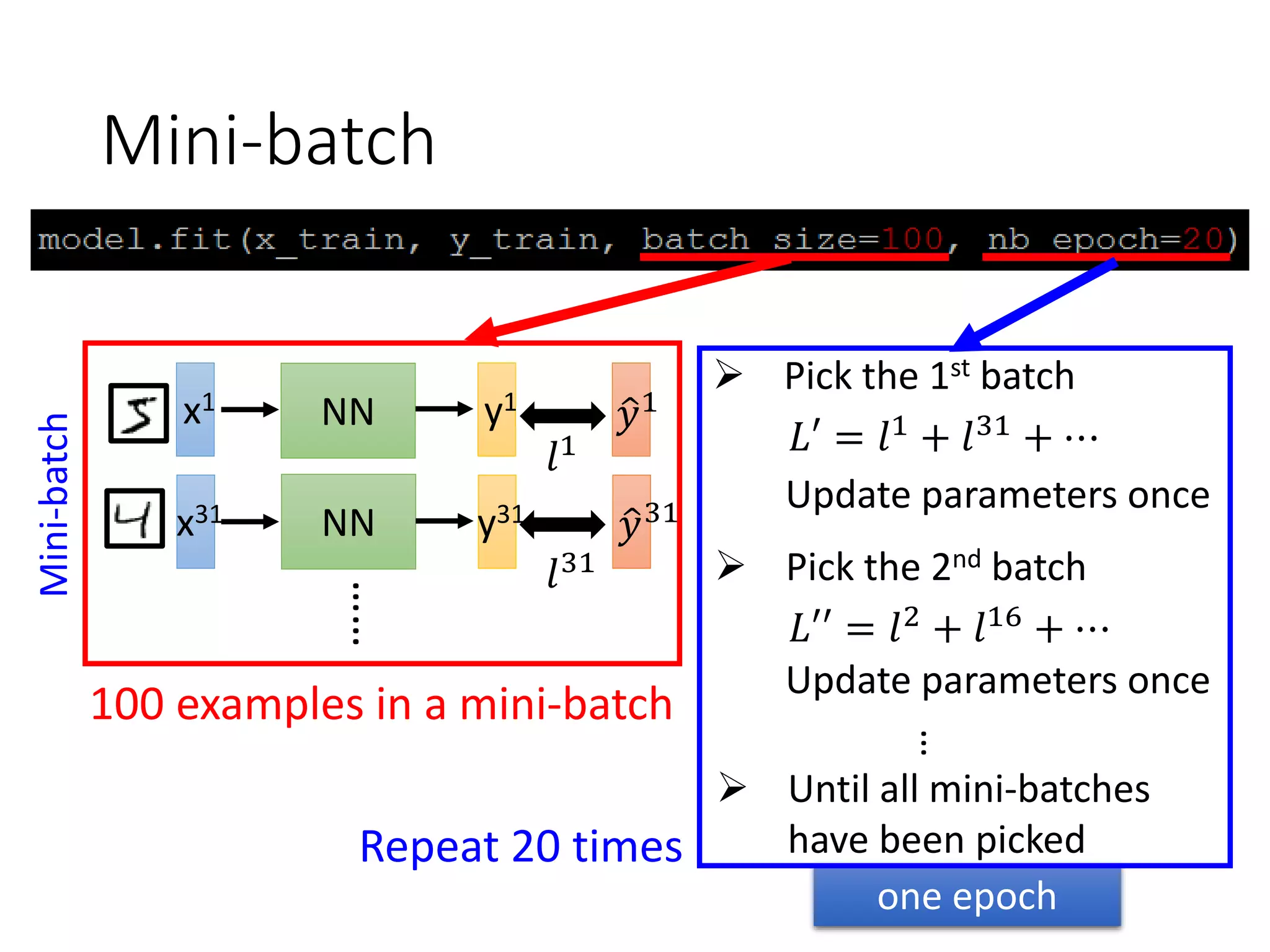
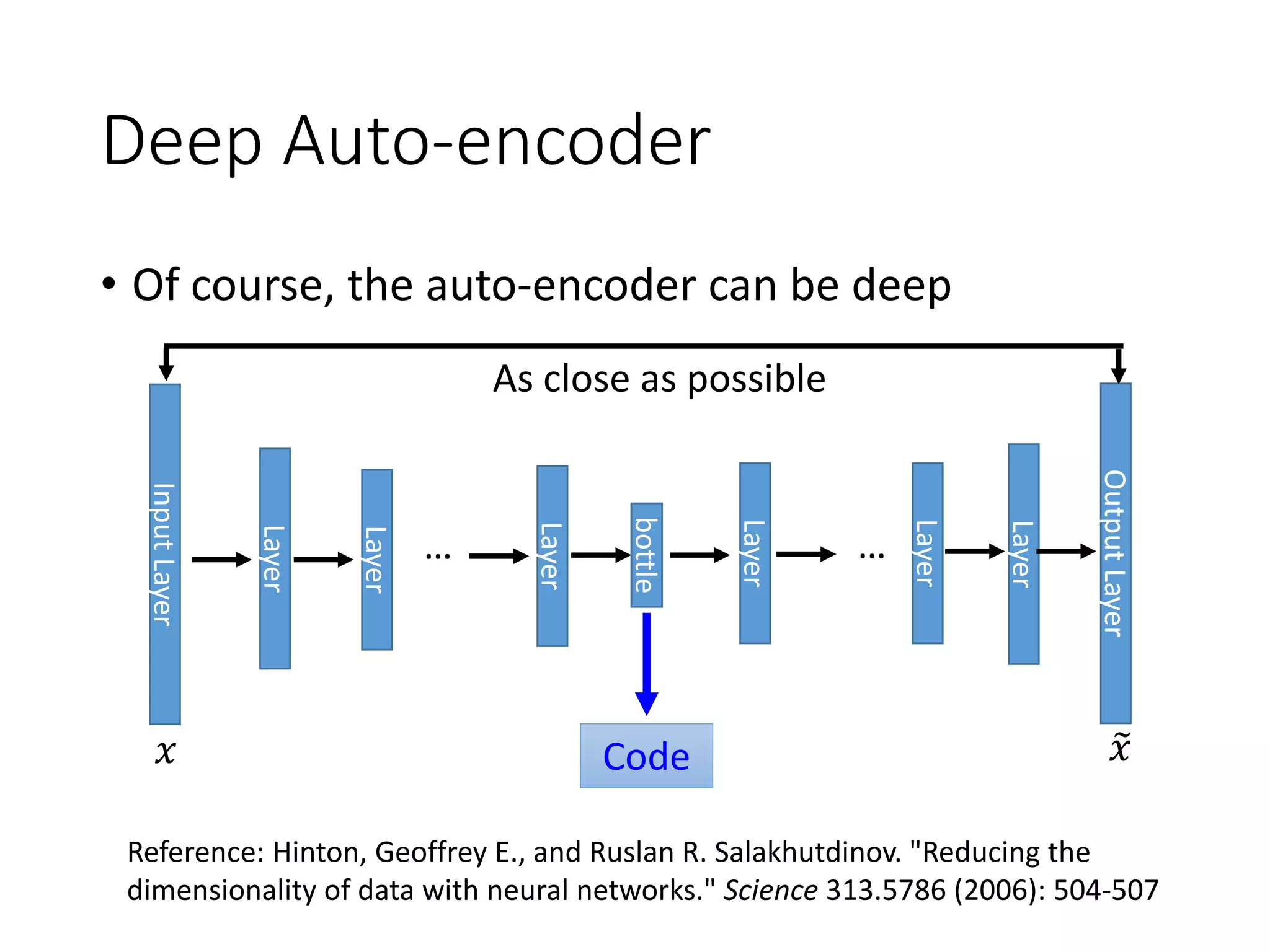
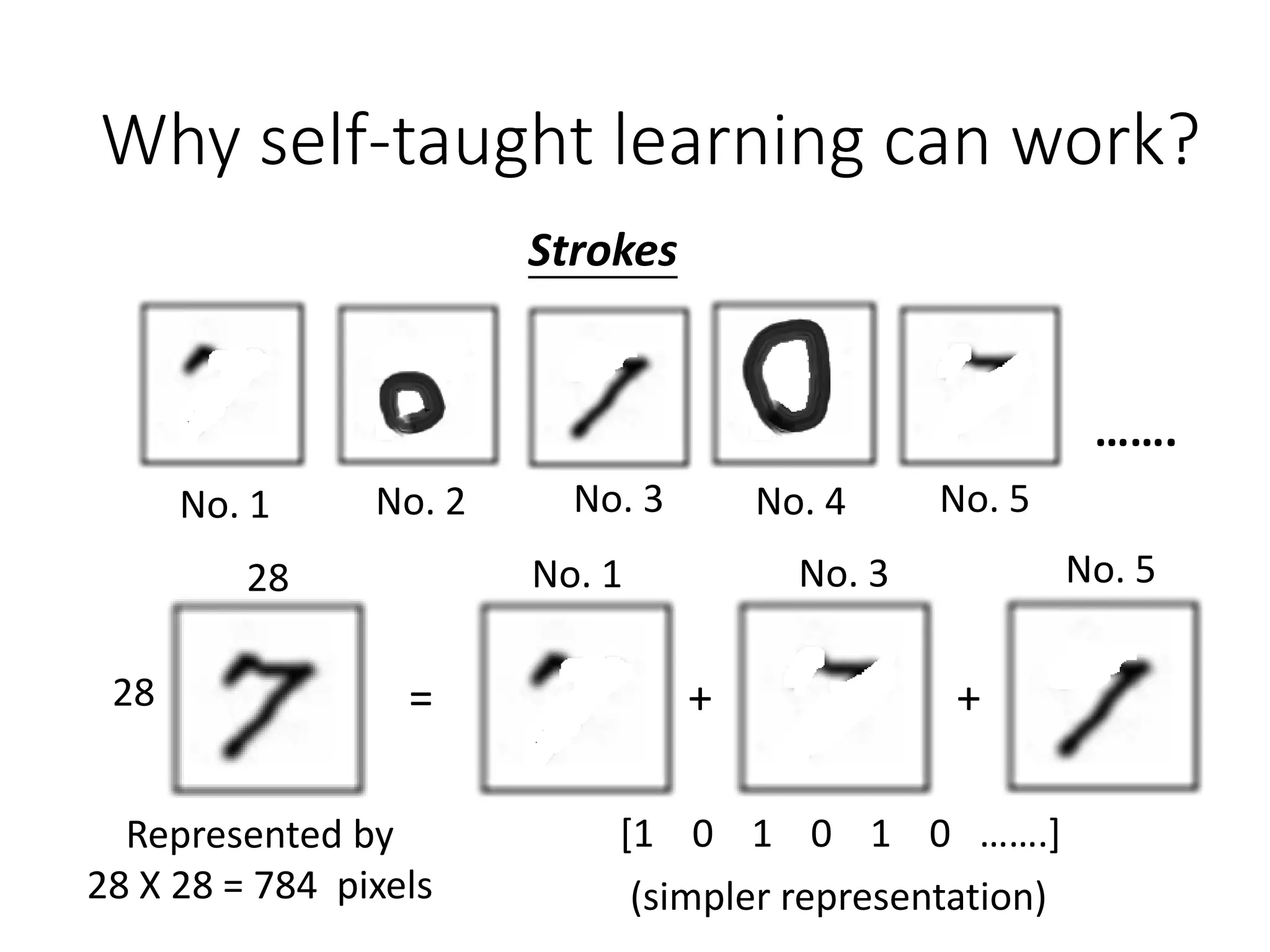
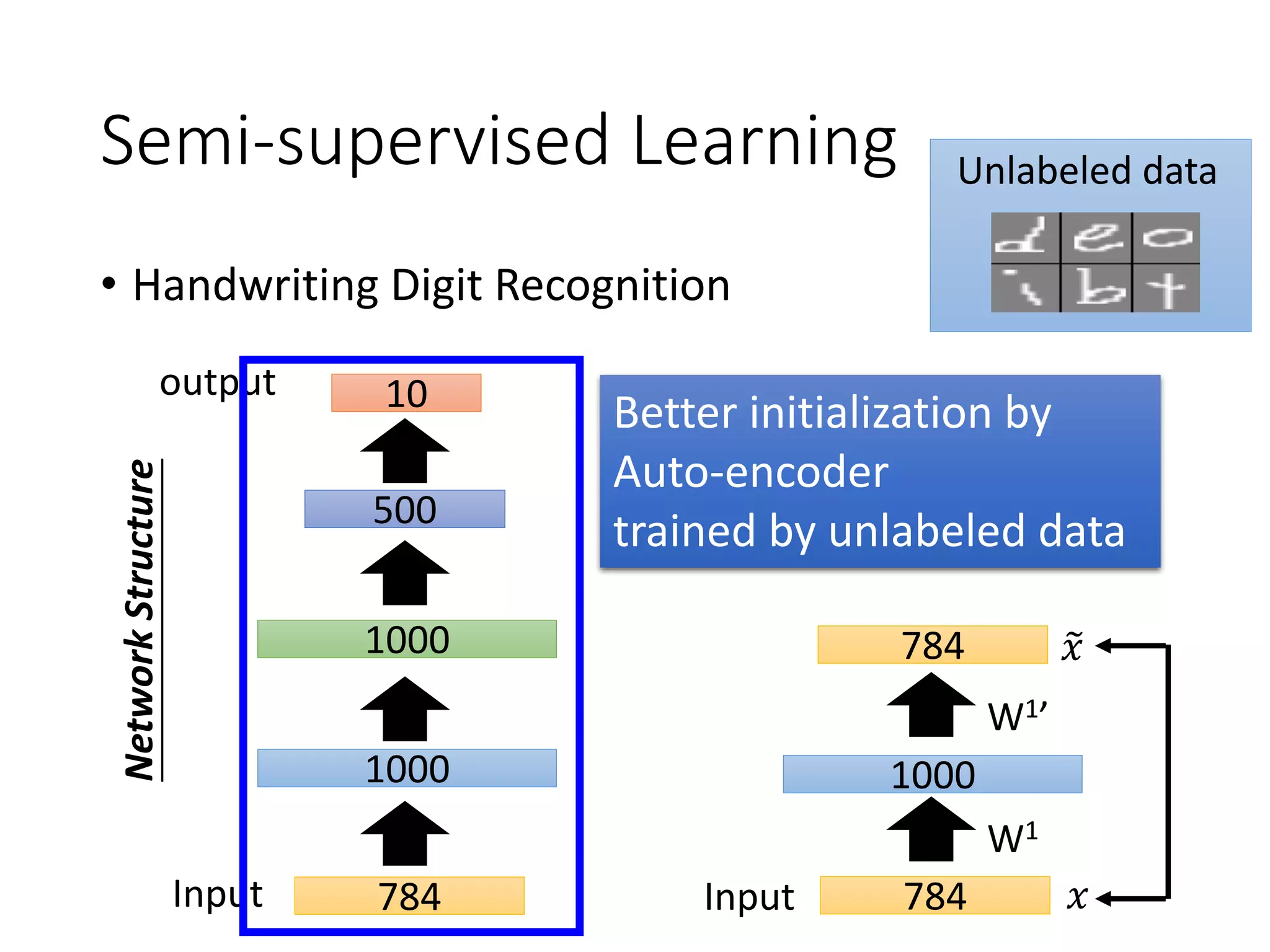
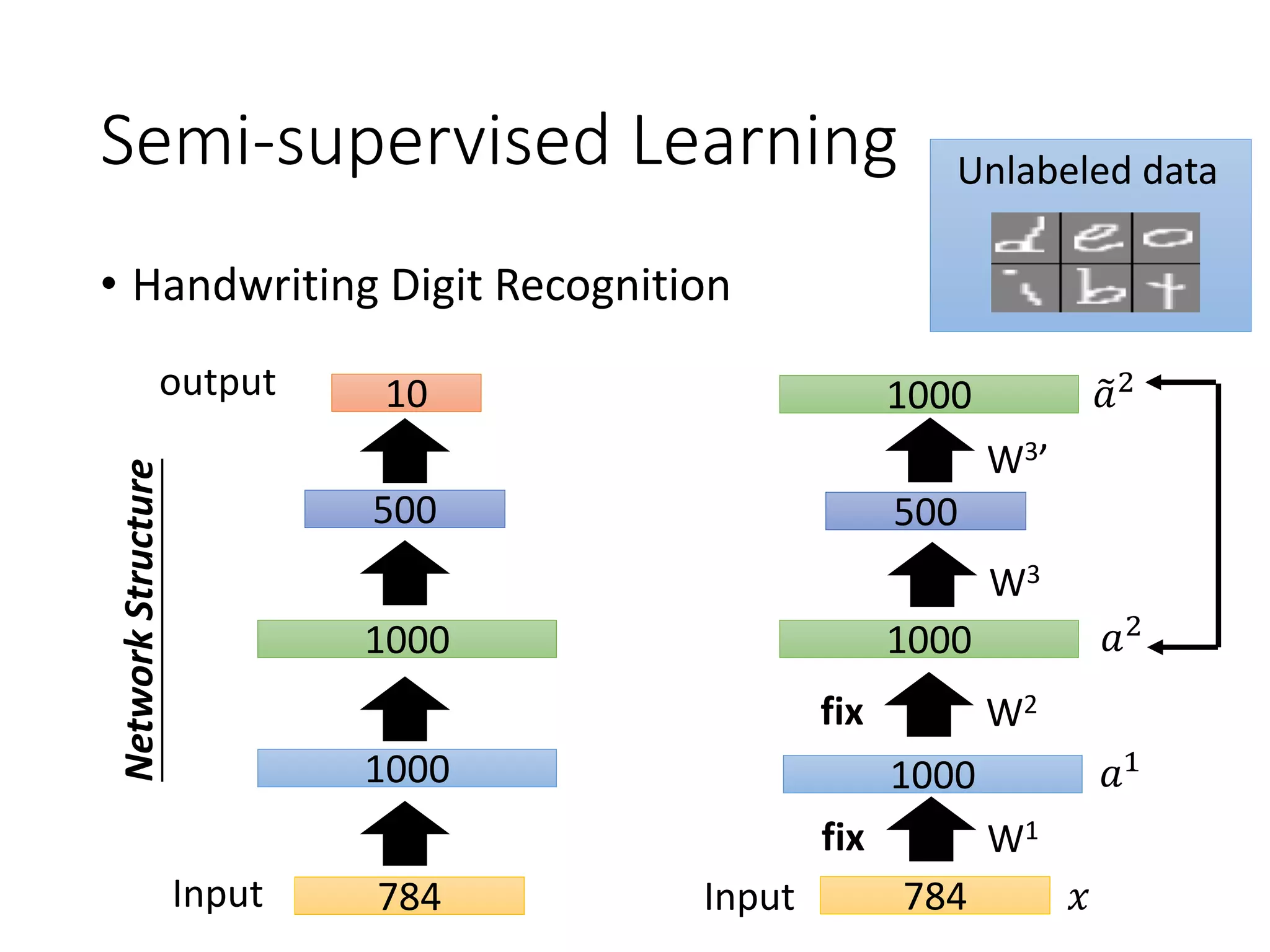
This document outlines a deep learning tutorial led by Li Hongyi, covering fundamental concepts and techniques in deep learning, including the structure and function of neural networks, their training, and applications like handwriting recognition. The tutorial emphasizes the simplicity of deep learning processes through a three-step methodology: defining a set of functions, determining their effectiveness, and selecting the best one. Various aspects like gradient descent, modularization of classifiers, and the advantages of deep over shallow networks are also discussed.











![[系列活動] 一日搞懂生成式對抗網路](https://cdn.slidesharecdn.com/ss_thumbnails/gan-170813004356-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[系列活動] 手把手的深度學習實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidesharestepbystepdl-161213072731-thumbnail.jpg?width=640&height=640&fit=bounds)


![[系列活動] 無所不在的自然語言處理—基礎概念、技術與工具介紹](https://cdn.slidesharecdn.com/ss_thumbnails/nlptutorial-0828-170830062001-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 機器學習速遊](https://cdn.slidesharecdn.com/ss_thumbnails/mltourhandout-170310083857-thumbnail.jpg?width=640&height=640&fit=bounds)



































![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 工業 4.0 與智慧製造的發展趨勢與挑戰](https://cdn.slidesharecdn.com/ss_thumbnails/20190316jyh-horngchou-190315170336-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 深度學習與Kaggle實戰](https://cdn.slidesharecdn.com/ss_thumbnails/20181206003-181210031001-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 從經濟學看人工智慧產業應用](https://cdn.slidesharecdn.com/ss_thumbnails/1-the-application-of-ai-industry-from-economics-190108064940-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 工業4.0潛力新應用! 多模式對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/20181206004-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] Bridging AI to Precision Agriculture through IoT](https://cdn.slidesharecdn.com/ss_thumbnails/hc-2nd-openingai-school-181206104858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 啟動物聯網新關鍵 - 未來由你「喚」醒 / 沈品勳](https://cdn.slidesharecdn.com/ss_thumbnails/20181117shengfn-181130083931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 智慧製造成真! 產線導入AI的致勝關鍵](https://cdn.slidesharecdn.com/ss_thumbnails/thu-hsu-190116063619-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台中分校] 第一期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/sw-ppt-181217031715-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台北總校第三期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/tp3closingsw-190126030359-thumbnail.jpg?width=640&height=640&fit=bounds)

![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiotforaiabytedchangho-190227081005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 2019 台灣數位轉型與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/20181206-001-181210031002-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 2019 台灣數位轉型 與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/to-sheng-190116063620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台中分校第二期開學典禮 - 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/tc2-opening1-compressed-190107034100-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 產業經驗分享: 如何用最少的訓練樣本,得到最好的深度學習影像分析結果,減少一半人力,提升一倍品質 / 李明達](https://cdn.slidesharecdn.com/ss_thumbnails/lee-181130104127-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] AI整合是重點! 竹科的關鍵轉型思維](https://cdn.slidesharecdn.com/ss_thumbnails/20181206002-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/openingsw-190315170512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] AI 引爆新工業革命,智慧機械首都台中轉型論壇](https://cdn.slidesharecdn.com/ss_thumbnails/aia-chen-190116063635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiinhealthcare-20190216victoria-v6-190227081004-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)



