Downloaded 66 times






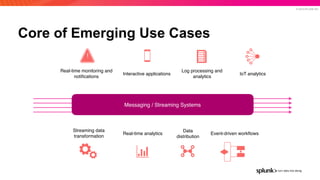
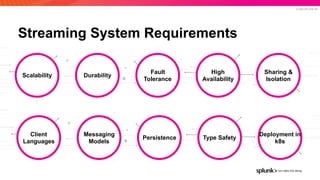
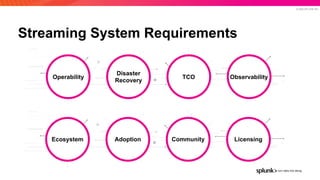

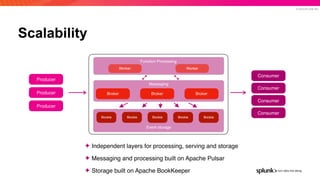

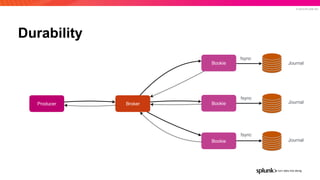





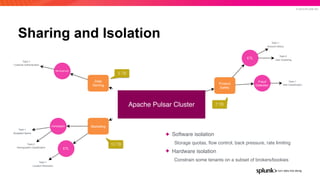
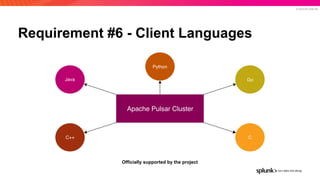

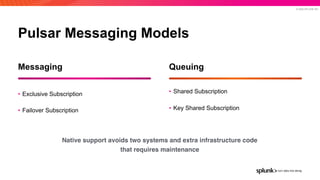
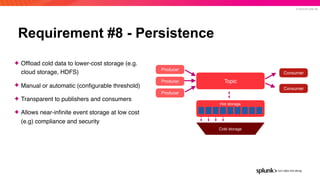



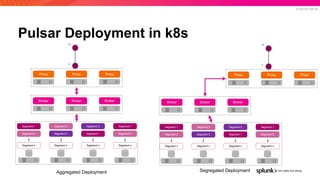


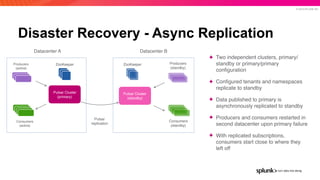










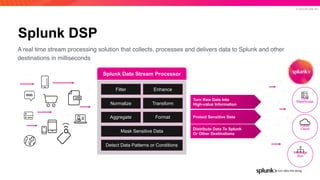

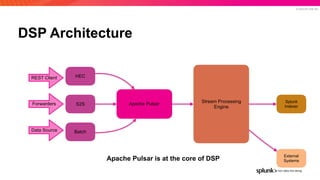



The document presents an overview of why Splunk chose Apache Pulsar as their streaming system, detailing its requirements such as scalability, durability, fault tolerance, and high availability. It highlights Pulsar's capabilities in handling real-time data processing efficiently, with lower latency and costs compared to other systems. Additionally, it discusses Splunk's successful integration of Pulsar within its data stream processing solutions, aimed at enhancing data-driven decision-making.


































![[AerospikeRoadshow] Apache Pulsar Unifies Streaming and Messaging for Real-Ti...](https://cdn.slidesharecdn.com/ss_thumbnails/aerospikeroadshowapachepulsarunifiesstreamingandmessagingforreal-timedata2-221103174214-18ce3fa2-thumbnail.jpg?width=640&height=640&fit=bounds)





































![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)









