Download as PDF, PPTX





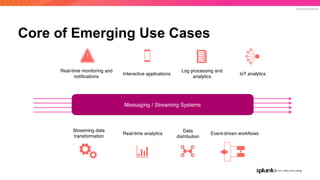
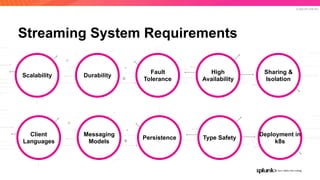
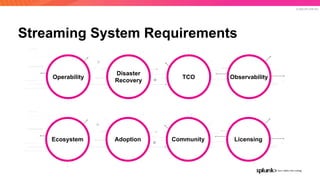

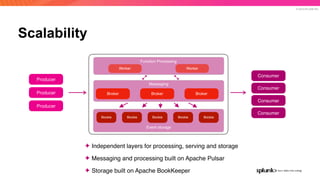

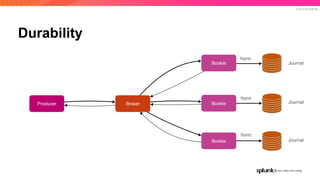





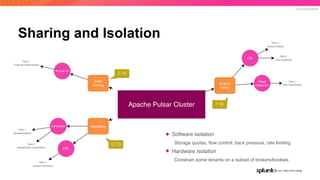

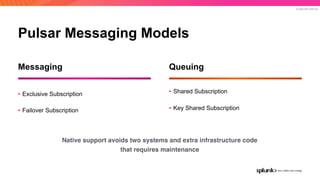
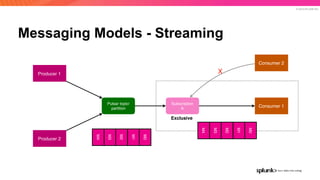
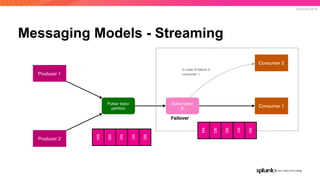
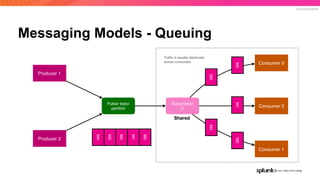
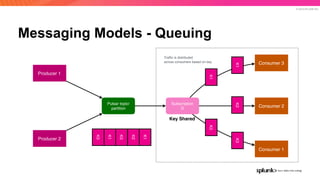
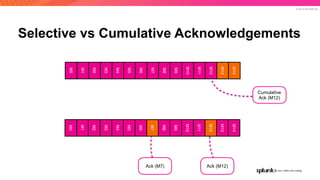
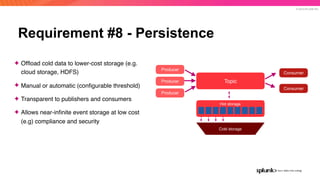



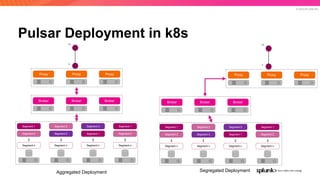


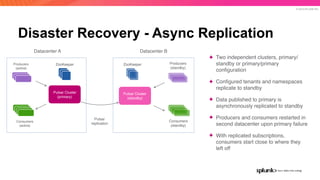






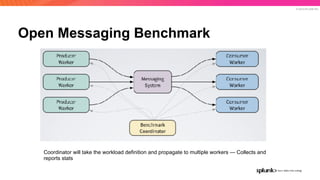
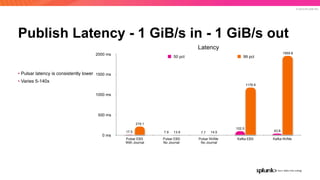
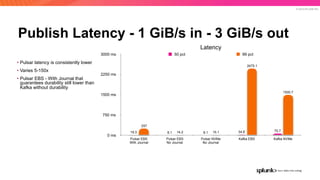
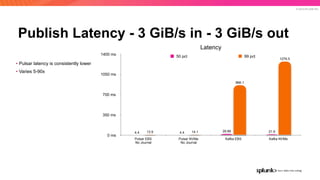

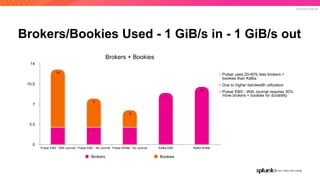
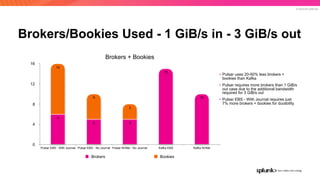
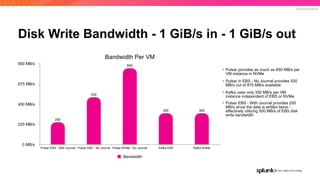
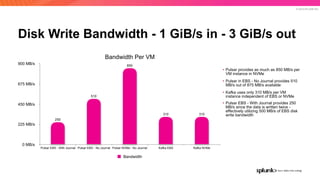

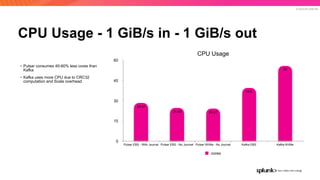
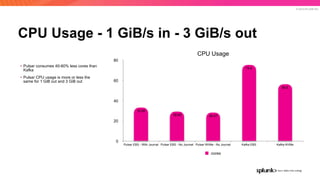
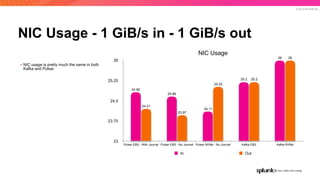
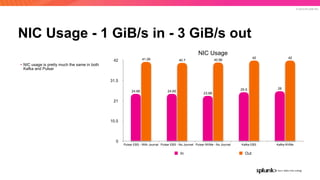

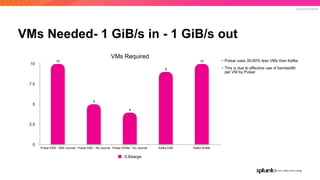
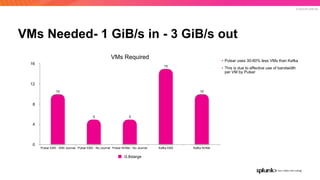
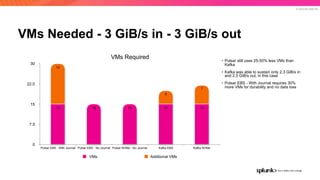

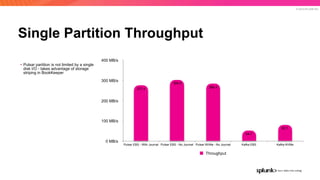
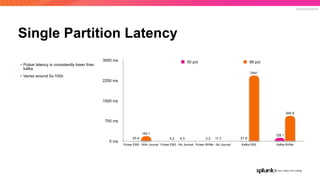






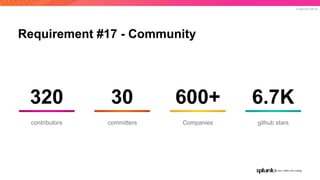



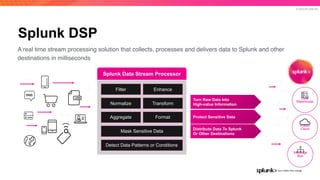
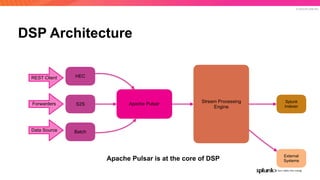



The document discusses the benefits and requirements of Apache Pulsar, a streaming platform utilized by Splunk, highlighting its scalability, durability, fault tolerance, and high availability. It outlines the various messaging models supported by Pulsar, as well as its deployment in Kubernetes and disaster recovery capabilities. Additionally, performance comparisons with Kafka illustrate Pulsar's lower latency and efficient resource utilization.


































![[AerospikeRoadshow] Apache Pulsar Unifies Streaming and Messaging for Real-Ti...](https://cdn.slidesharecdn.com/ss_thumbnails/aerospikeroadshowapachepulsarunifiesstreamingandmessagingforreal-timedata2-221103174214-18ce3fa2-thumbnail.jpg?width=640&height=640&fit=bounds)












































