The document discusses cross entropy loss function which is commonly used in classification problems. It derives the theoretical basis for cross entropy by formulating it as minimizing the cross entropy between the predicted probabilities and true labels. For binary classification problems, cross entropy is shown to be equivalent to maximizing the likelihood of the training data which can be written as minimizing the binary cross entropy. This concept is extended to multiclass classification problems by defining the prediction as a probability distribution over classes and label as a one-hot encoding.





![NN
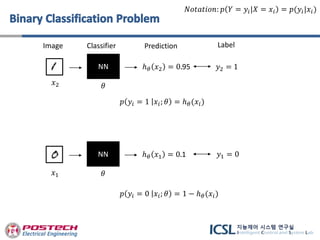
𝑥1 𝜃
ℎ 𝜃 𝑥1 = 0.1 𝑦1 = 0
Image Classifier Prediction Label
NN
𝑥2 𝜃
ℎ 𝜃 𝑥2 = 0.95 𝑦2 = 1
[0, 0, 0, 1, 1, 1]
𝑦1, … , 𝑦 𝑚𝑥1, … , 𝑥 𝑚
: Training Dataset
𝜃](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-6-320.jpg)
![NN
𝑥1 𝜃
ℎ 𝜃 𝑥1 = 0.1 𝑦1 = 0
Image Classifier Prediction Label
NN
𝑥2 𝜃
ℎ 𝜃 𝑥2 = 0.95 𝑦2 = 1
[0, 0, 0, 1, 1, 1]
𝑦1, … , 𝑦 𝑚𝑥1, … , 𝑥 𝑚
𝐿𝑖𝑘𝑒𝑙𝑖ℎ𝑜𝑜𝑑: 𝐿 𝜃 = 𝑝(𝑦1, … , 𝑦 𝑚|𝑥1, … , 𝑥 𝑚; 𝜃)
: Training Dataset
𝜃
: 에 의해 [0, 0, 0, 1, 1, 1]로 Prediction이 나올법한 정도𝜃
𝑁𝑜𝑡𝑎𝑡𝑖𝑜𝑛: 𝑝 𝑌 = 𝑦𝑖|𝑋 = 𝑥𝑖 = 𝑝(𝑦𝑖|𝑥𝑖)
입력 image예측 label](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-7-320.jpg)
![NN
𝑥1 𝜃
ℎ 𝜃 𝑥1 = 0.1 𝑦1 = 0
Image Classifier Prediction Label
NN
𝑥2 𝜃
ℎ 𝜃 𝑥2 = 0.95 𝑦2 = 1
[0, 0, 0, 1, 1, 1]
𝑦1, … , 𝑦 𝑚𝑥1, … , 𝑥 𝑚
𝐿𝑖𝑘𝑒𝑙𝑖ℎ𝑜𝑜𝑑: 𝐿 𝜃 = 𝑝(𝑦1, … , 𝑦 𝑚|𝑥1, … , 𝑥 𝑚; 𝜃)
𝑀𝑎𝑥𝑖𝑚𝑢𝑚 𝐿𝑖𝑘𝑒𝑙𝑖ℎ𝑜𝑜𝑑: 𝜃 = 𝑎𝑟𝑔𝑚𝑎𝑥(𝐿(𝜃))
: [0, 0, 0, 1, 1, 1]로 Prediction이 가장 나올법한 를 선택한다
𝜃
: 에 의해 [0, 0, 0, 1, 1, 1]로 Prediction이 나올법한 정도𝜃
𝜃
: Training Dataset
𝑁𝑜𝑡𝑎𝑡𝑖𝑜𝑛: 𝑝 𝑌 = 𝑦𝑖|𝑋 = 𝑥𝑖 = 𝑝(𝑦𝑖|𝑥𝑖)](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-8-320.jpg)







![𝜃
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛(− 𝑙𝑜𝑔 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛( 𝑖=1
𝑚
[−𝑦𝑖 log ℎ 𝜃 𝑥𝑖 − (1 − 𝑦𝑖) log(1 − ℎ 𝜃 𝑥𝑖 )]) (∵ 𝑙𝑜𝑔 성질)
𝐿 𝜃 =
𝑖=1
𝑚
ℎ 𝜃 𝑥𝑖
𝑦 𝑖 1 − ℎ 𝜃 𝑥𝑖
1−𝑦 𝑖](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-17-320.jpg)
![𝜃
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛(− 𝑙𝑜𝑔 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛( 𝑖=1
𝑚
[−𝑦𝑖 log ℎ 𝜃 𝑥𝑖 − (1 − 𝑦𝑖) log(1 − ℎ 𝜃 𝑥𝑖 )])
= 𝑎𝑟𝑔𝑚𝑖𝑛 𝑖=1
𝑚
𝐻 𝑦𝑖, ℎ 𝜃 𝑥𝑖
𝑤ℎ𝑒𝑟𝑒 𝐻 𝑦𝑖, ℎ 𝜃 𝑥𝑖 = −𝑦𝑖 log ℎ 𝜃 𝑥𝑖 − 1 − 𝑦𝑖 log 1 − ℎ 𝜃 𝑥𝑖
: 𝐵𝑖𝑛𝑎𝑟𝑦 𝐶𝑟𝑜𝑠𝑠 𝐸𝑛𝑡𝑟𝑜𝑝𝑦](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-18-320.jpg)
![𝜃
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛(− 𝑙𝑜𝑔 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛( 𝑖=1
𝑚
[−𝑦𝑖 log ℎ 𝜃 𝑥𝑖 − (1 − 𝑦𝑖) log(1 − ℎ 𝜃 𝑥𝑖 )])
= 𝑎𝑟𝑔𝑚𝑖𝑛 𝑖=1
𝑚
𝐻 𝑦𝑖, ℎ 𝜃 𝑥𝑖
𝑤ℎ𝑒𝑟𝑒 𝐻 𝑦𝑖, ℎ 𝜃 𝑥𝑖 = −𝑦𝑖 log ℎ 𝜃 𝑥𝑖 − 1 − 𝑦𝑖 log 1 − ℎ 𝜃 𝑥𝑖
: 𝐵𝑖𝑛𝑎𝑟𝑦 𝐶𝑟𝑜𝑠𝑠 𝐸𝑛𝑡𝑟𝑜𝑝𝑦
ℎ 𝜃 𝑥𝑖 , 𝑦𝑖 ∈ 0, 1 인 확률값
Maximize Likelihood Minimize Binary Cross Entropy
Binary Classification Problem](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-19-320.jpg)
![NN
𝑥1 𝜃
ℎ 𝜃 𝑥1 = [𝟎. 𝟗, 0.05, 0.05] 𝑦1 = [1, 0, 0]
Image Classifier Prediction Label
NN
𝑥2 𝜃
ℎ 𝜃 𝑥2 = [0.03, 𝟎. 𝟗𝟓, 0.02] 𝑦2 = [0, 1, 0]
NN
𝑥3 𝜃
ℎ 𝜃 𝑥3 = [0.01, 0.01, 𝟎. 𝟗𝟖] 𝑦3 = [0, 0, 1]](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-20-320.jpg)
![NN
𝑥1 𝜃
ℎ 𝜃 𝑥1 = [𝟎. 𝟗, 0.05, 0.05] 𝑦1 = [1, 0, 0]
Image Classifier Prediction Label
𝑝 𝑦𝑖 = [1, 0, 0] 𝑥𝑖; 𝜃
= 𝑝 𝑦𝑖(0) = 1 𝑥𝑖; 𝜃) (𝐴𝑠𝑠𝑢𝑚𝑒 𝑂𝑛𝑒ℎ𝑜𝑡 𝑒𝑛𝑐𝑜𝑑𝑖𝑛𝑔)](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-21-320.jpg)
![NN
𝑥1 𝜃
ℎ 𝜃 𝑥1 = [𝟎. 𝟗, 0.05, 0.05] 𝑦1 = [1, 0, 0]
Image Classifier Prediction Label
𝑝 𝑦𝑖 = [1, 0, 0] 𝑥𝑖; 𝜃
= 𝑝 𝑦𝑖(0) = 1 𝑥𝑖; 𝜃)
= ℎ 𝜃 𝑥𝑖 (0)](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-22-320.jpg)
![NN
𝑥1 𝜃
ℎ 𝜃 𝑥1 = [𝟎. 𝟗, 0.05, 0.05] 𝑦1 = [1, 0, 0]
Image Classifier Prediction Label
𝑝 𝑦𝑖 = [1, 0, 0] 𝑥𝑖; 𝜃
= 𝑝 𝑦𝑖(0) = 1 𝑥𝑖; 𝜃)
= ℎ 𝜃 𝑥𝑖 (0)
같은 방법으로,
𝑝 𝑦𝑖 = [0, 1, 0] 𝑥𝑖; 𝜃 = ℎ 𝜃 𝑥𝑖 1
𝑝 𝑦𝑖 = [0, 0, 1] 𝑥𝑖; 𝜃 = ℎ 𝜃 𝑥𝑖 (2)](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-23-320.jpg)
![𝑝 𝑦𝑖 = [1, 0, 0] 𝑥𝑖; 𝜃 = ℎ 𝜃 𝑥𝑖 (0)
𝑝 𝑦𝑖 = [0, 1, 0] 𝑥𝑖; 𝜃 = ℎ 𝜃 𝑥𝑖 1
𝑝 𝑦𝑖 = [0, 0, 1] 𝑥𝑖; 𝜃 = ℎ 𝜃 𝑥𝑖 (2)
즉, 𝑝 𝑦𝑖 𝑥𝑖; 𝜃 = ℎ 𝜃 𝑥𝑖 0 𝑦 𝑖(0)
ℎ 𝜃 𝑥𝑖 1 𝑦 𝑖(1)
ℎ 𝜃 𝑥𝑖 2 𝑦 𝑖(2)
𝑁𝑜𝑡𝑎𝑡𝑖𝑜𝑛: 𝑝 𝑌 = 𝑦𝑖|𝑋 = 𝑥𝑖 = 𝑝(𝑦𝑖|𝑥𝑖)](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-24-320.jpg)

![𝑁𝑜𝑡𝑎𝑡𝑖𝑜𝑛: 𝑝 𝑌 = 𝑦𝑖|𝑋 = 𝑥𝑖 = 𝑝(𝑦𝑖|𝑥𝑖)
𝜃
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛(− 𝑙𝑜𝑔 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛 𝑖=1
𝑚
[−𝑦𝑖 0 𝑙𝑜𝑔ℎ 𝜃(𝑥𝑖)(0) − 𝑦𝑖 1 𝑙𝑜𝑔ℎ 𝜃(𝑥𝑖)(1) − 𝑦𝑖 2 𝑙𝑜𝑔ℎ 𝜃(𝑥𝑖)(2)]
𝑝 𝑦𝑖 𝑥𝑖; 𝜃 = ℎ 𝜃 𝑥𝑖 0 𝑦 𝑖(0)
ℎ 𝜃 𝑥𝑖 1 𝑦 𝑖(1)
ℎ 𝜃 𝑥𝑖 2 𝑦 𝑖(2)](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-26-320.jpg)
![𝑁𝑜𝑡𝑎𝑡𝑖𝑜𝑛: 𝑝 𝑌 = 𝑦𝑖|𝑋 = 𝑥𝑖 = 𝑝(𝑦𝑖|𝑥𝑖)
𝜃
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛(− 𝑙𝑜𝑔 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛 𝑖=1
𝑚
[−𝑦𝑖 0 𝑙𝑜𝑔ℎ 𝜃(𝑥𝑖)(0) − 𝑦𝑖 1 𝑙𝑜𝑔ℎ 𝜃(𝑥𝑖)(1) − 𝑦𝑖 2 𝑙𝑜𝑔ℎ 𝜃(𝑥𝑖)(2)]
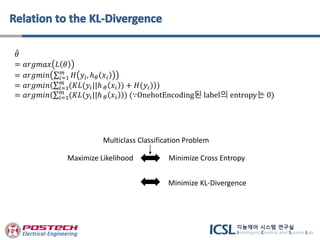
= 𝑎𝑟𝑔𝑚𝑖𝑛 𝑖=1
𝑚
𝐻 𝑦𝑖, ℎ 𝜃 𝑥𝑖
𝑤ℎ𝑒𝑟𝑒 𝐻 𝑃, 𝑄 = −
𝑖=1
𝑐
𝑝𝑖 𝑙𝑜𝑔(𝑞𝑖)
: 𝐶𝑟𝑜𝑠𝑠 𝐸𝑛𝑡𝑟𝑜𝑝𝑦](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-27-320.jpg)
![𝑁𝑜𝑡𝑎𝑡𝑖𝑜𝑛: 𝑝 𝑌 = 𝑦𝑖|𝑋 = 𝑥𝑖 = 𝑝(𝑦𝑖|𝑥𝑖)
𝜃
= 𝑎𝑟𝑔𝑚𝑎𝑥 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛(− 𝑙𝑜𝑔 𝐿 𝜃
= 𝑎𝑟𝑔𝑚𝑖𝑛 𝑖=1
𝑚
[−𝑦𝑖 0 𝑙𝑜𝑔ℎ 𝜃(𝑥𝑖)(0) − 𝑦𝑖 1 𝑙𝑜𝑔ℎ 𝜃(𝑥𝑖)(1) − 𝑦𝑖 2 𝑙𝑜𝑔ℎ 𝜃(𝑥𝑖)(2)]
= 𝑎𝑟𝑔𝑚𝑖𝑛 𝑖=1
𝑚
𝐻 𝑦𝑖, ℎ 𝜃 𝑥𝑖
ℎ 𝜃 𝑥𝑖 , 𝑦𝑖는 Probability Distribution
Maximize Likelihood Minimize Cross Entropy
Multiclass Classification Problem
𝑤ℎ𝑒𝑟𝑒 𝐻 𝑃, 𝑄 = −
𝑖=1
𝑐
𝑝𝑖 𝑙𝑜𝑔(𝑞𝑖)
: 𝐶𝑟𝑜𝑠𝑠 𝐸𝑛𝑡𝑟𝑜𝑝𝑦](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-28-320.jpg)







![ 정보 이론의 관점에서는 KL-divergence를 직관적으로 “놀라움의 정도”로 이해 가능
(예) 준결승 진출팀 : LG 트윈스, 한화 이글스, NC 다이노스, 삼성 라이온즈
- 예측 모델 1) :
- 예측 모델 2) :
- 경기 결과 :
- 예측 모델 2)에서 더 큰 놀라움을 확인
- 놀라움의 정도를 최소화 Q가 P로 근사됨 두 확률 분포가 닮음 정확한 예측
𝑦 = 𝑃 = [1, 0, 0, 0]
𝑦 = 𝑄 = [𝟎. 𝟗, 0.03, 0.03, 0.04]
𝑦 = 𝑄 = [0.3, 𝟎. 𝟔 0.05, 0.05]
𝐾𝐿(𝑃| 𝑄 =
𝑖=1
𝑐
(𝑝𝑖 𝑙𝑜𝑔
𝑝𝑖
𝑞𝑖
)](https://image.slidesharecdn.com/bjcrossentropyslideshare-190103050258/85/Detailed-Description-on-Cross-Entropy-Loss-Function-37-320.jpg)







































![Decision Tree Intro [의사결정나무]](https://cdn.slidesharecdn.com/ss_thumbnails/thetreeslideshare-170922160319-thumbnail.jpg?width=640&height=640&fit=bounds)
























