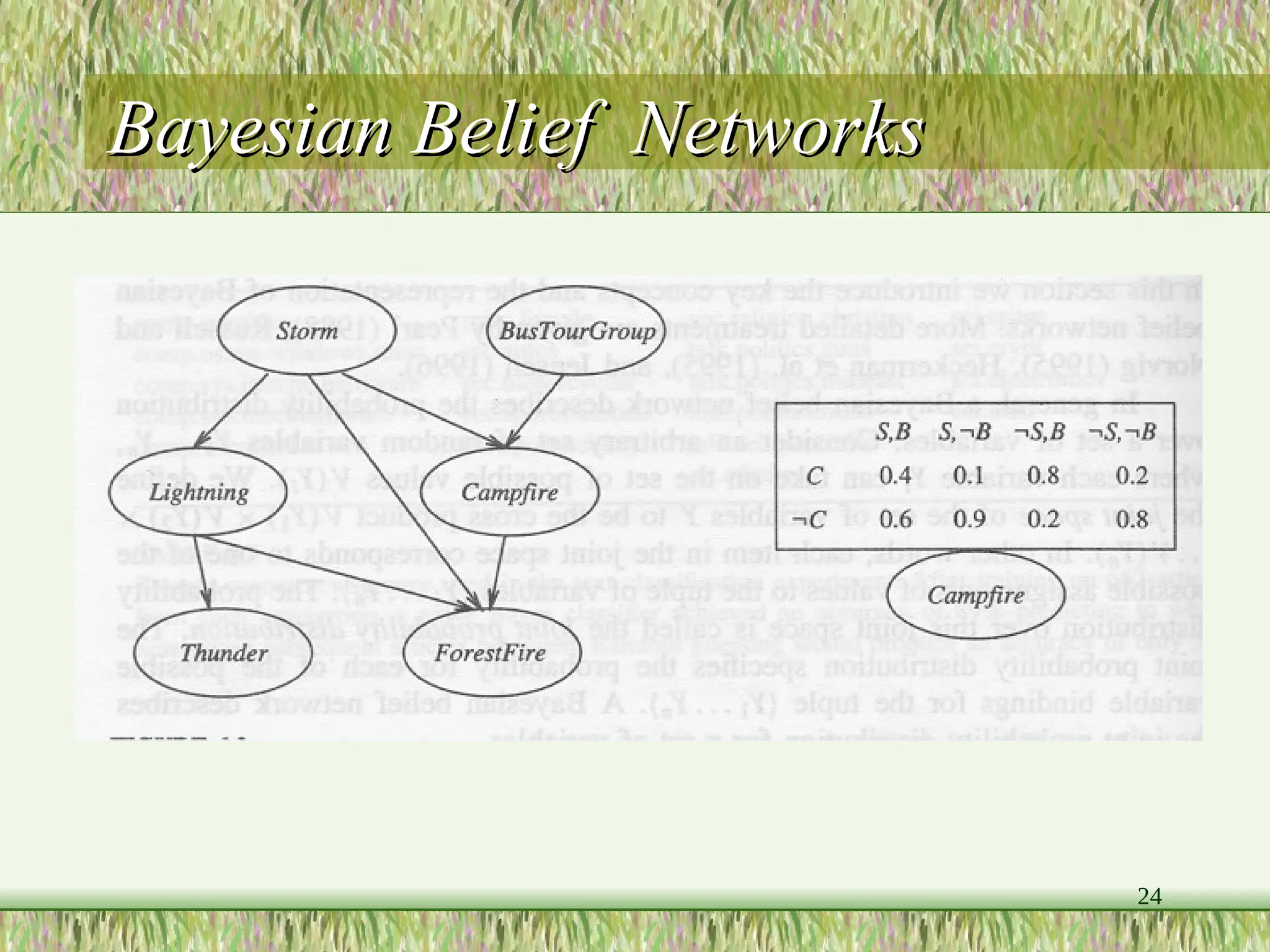
The document provides an overview of Bayesian learning and reasoning in machine learning, highlighting the significance of Bayesian algorithms in handling probability distributions and decision making. It discusses key concepts such as Bayes' theorem, maximum likelihood hypothesis, and naive Bayes classifier, along with their features, limitations, and practical applications, including medical diagnosis examples. Additionally, it covers advanced topics like Gibbs sampling and Bayesian belief networks to infer dependencies among variables.













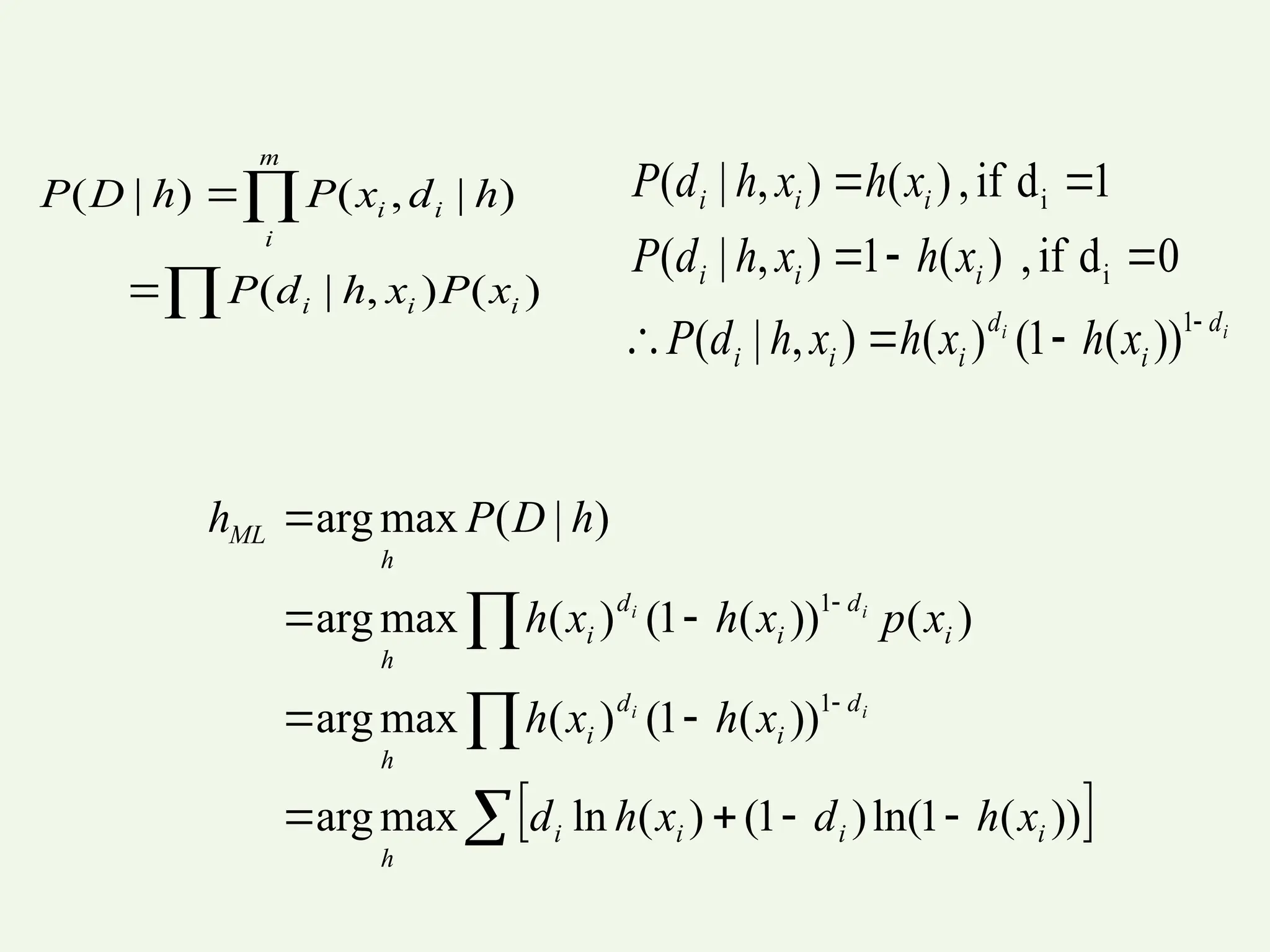












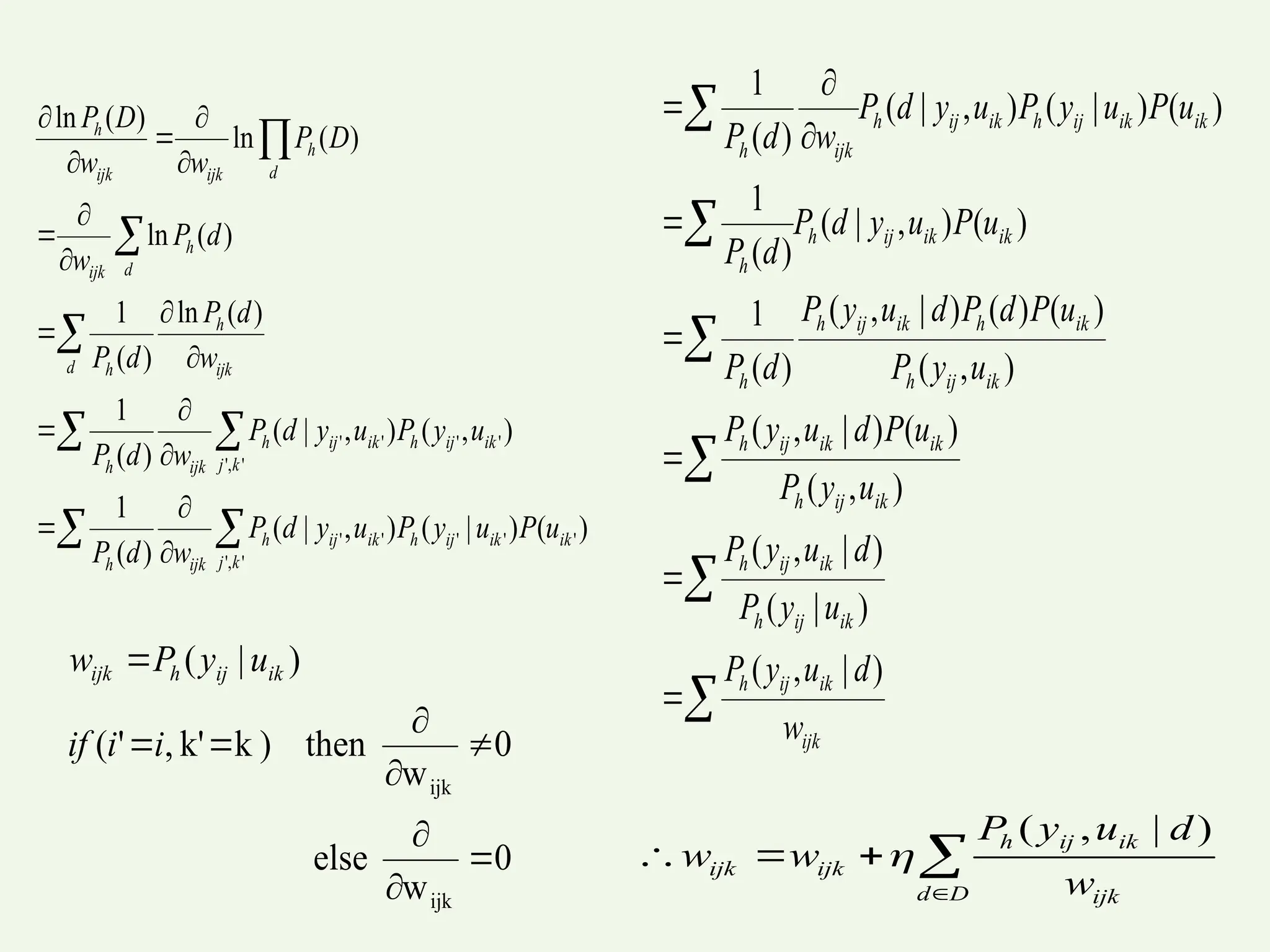


![31
K-means algorithm
K-means algorithm
• Initialize
• calculate E[z]
• calculate a new ML hypothesis
2
2
2
2
)
(
2
1
)
(
2
1
)
|
(
)
|
(
]
[
k
i
j
i
x
x
k
k
i
j
i
ij
e
e
x
P
x
P
z
E
m
i
i
ij
j x
z
E
m 1
]
[
1
==> converge to a local ML hypothesis](https://image.slidesharecdn.com/ml06-241128172808-45697364/75/Machine-learning-31-2048.jpg)

![33
guideline
guideline
• Search h’
• if h = : calculate function Q
)]
|
(
[ln
max
arg h
Y
P
E
h
h
]
,
|
)
|
(
[ln
)
|
( X
h
h
Y
P
E
h
h
Q
](https://image.slidesharecdn.com/ml06-241128172808-45697364/75/Machine-learning-33-2048.jpg)
![34
EM algorithm
EM algorithm
• Estimation step
• maximization step
• converge to a local maxima
]
,
|
)
|
(
[ln
)
|
( X
h
h
Y
P
E
h
h
Q
)
|
(
max
arg h
h
Q
h
h
](https://image.slidesharecdn.com/ml06-241128172808-45697364/75/Machine-learning-34-2048.jpg)

)
(
2
1
2
1
(ln
[
)]
'
|
(
[ln
'
2
'
2
2
2
'
2
2
h
h
Q
x
Z
E
x
Z
E
h
Y
P
E
m
i
j
i
ij
j
i
ij
2
2
2
2
)
(
2
1
)
(
2
1
)
|
(
)
|
(
]
[
k
i
j
i
x
x
k
k
i
j
i
ij
e
e
x
P
x
P
z
E
m
i
i
ij
j x
z
E
m 1
]
[
1
](https://image.slidesharecdn.com/ml06-241128172808-45697364/75/Machine-learning-35-2048.jpg)


























![Decision Tree Intro [의사결정나무]](https://cdn.slidesharecdn.com/ss_thumbnails/thetreeslideshare-170922160319-thumbnail.jpg?width=640&height=640&fit=bounds)




















