More Related Content

PPT

PPTX

PDF

PDF

PDF

PDF

PPTX

PDF
What's hot

PDF

PDF

PDF

PDF

PDF
Rにおける大規模データ解析(第10回TokyoWebMining) 
PPTX

KEY

PPTX
機械学習 / Deep Learning 大全 (1) 機械学習基礎編 
PDF

PDF

PPTX

PDF

PDF

PDF
Granger因果による�時系列データの因果推定(因果フェス2015) 
PDF

PDF
MLOps Yearning ~ 実運用システムを構築する前にデータサイエンティストが考えておきたいこと 
PDF

PDF
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大) 
PDF

PDF
Viewers also liked

PDF
マーケティングリサーチってなに?今さら聞けないリサーチの基礎知識と実践講座【基本編】 
PDF

PDF
基礎からのベイズ統計学 輪読会資料 第1章 確率に関するベイズの定理 
PDF

PPTX

PDF

PDF

PPTX
さくっとはじめるテキストマイニング(R言語) スタートアップ編 
PDF
Google Prediction APIを使う前に知っておきたい統計のはなし 
PDF

ODP

PDF
Similar to 推定と標本抽出

PPT

PPT

PPT

PPTX
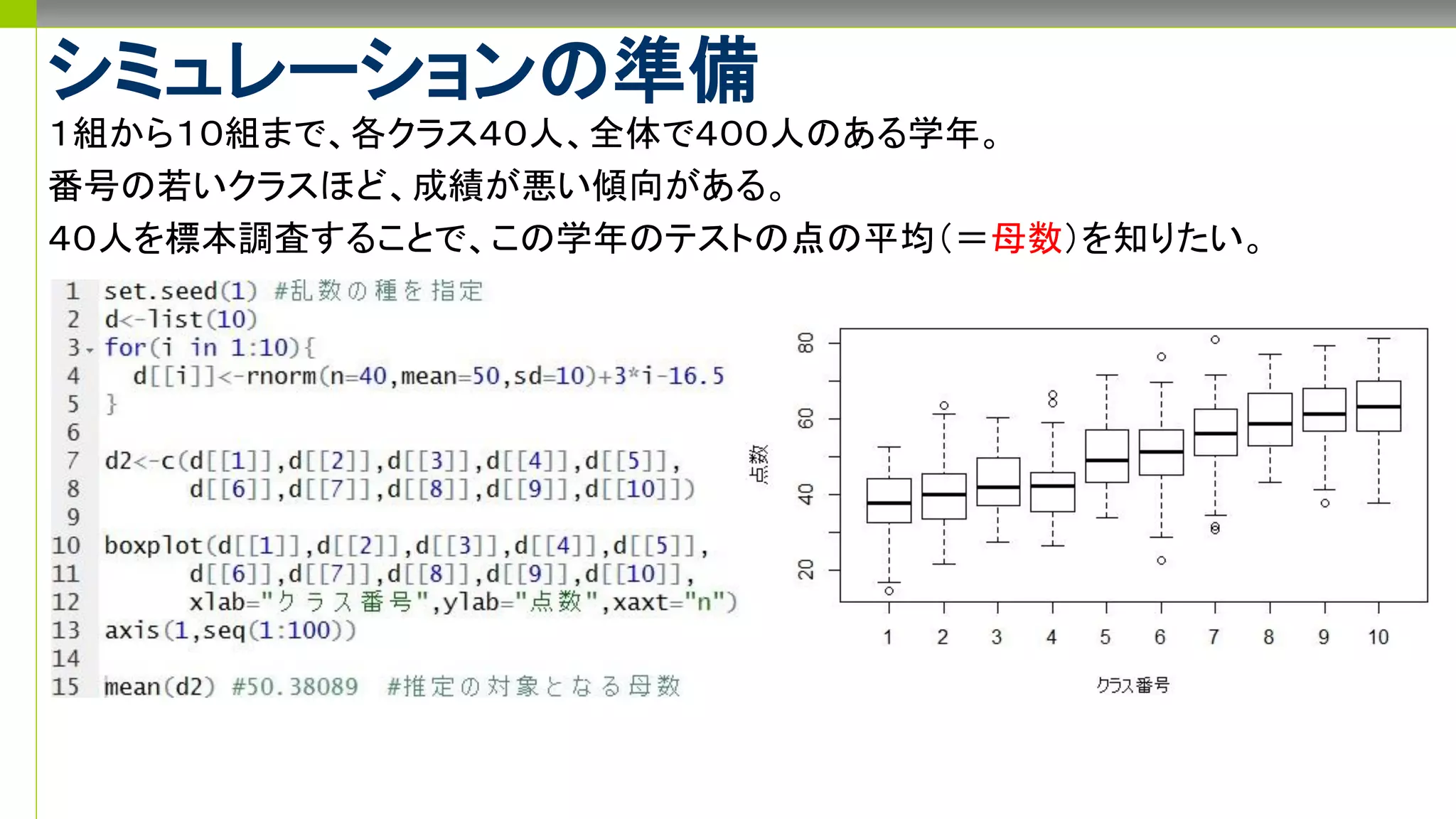
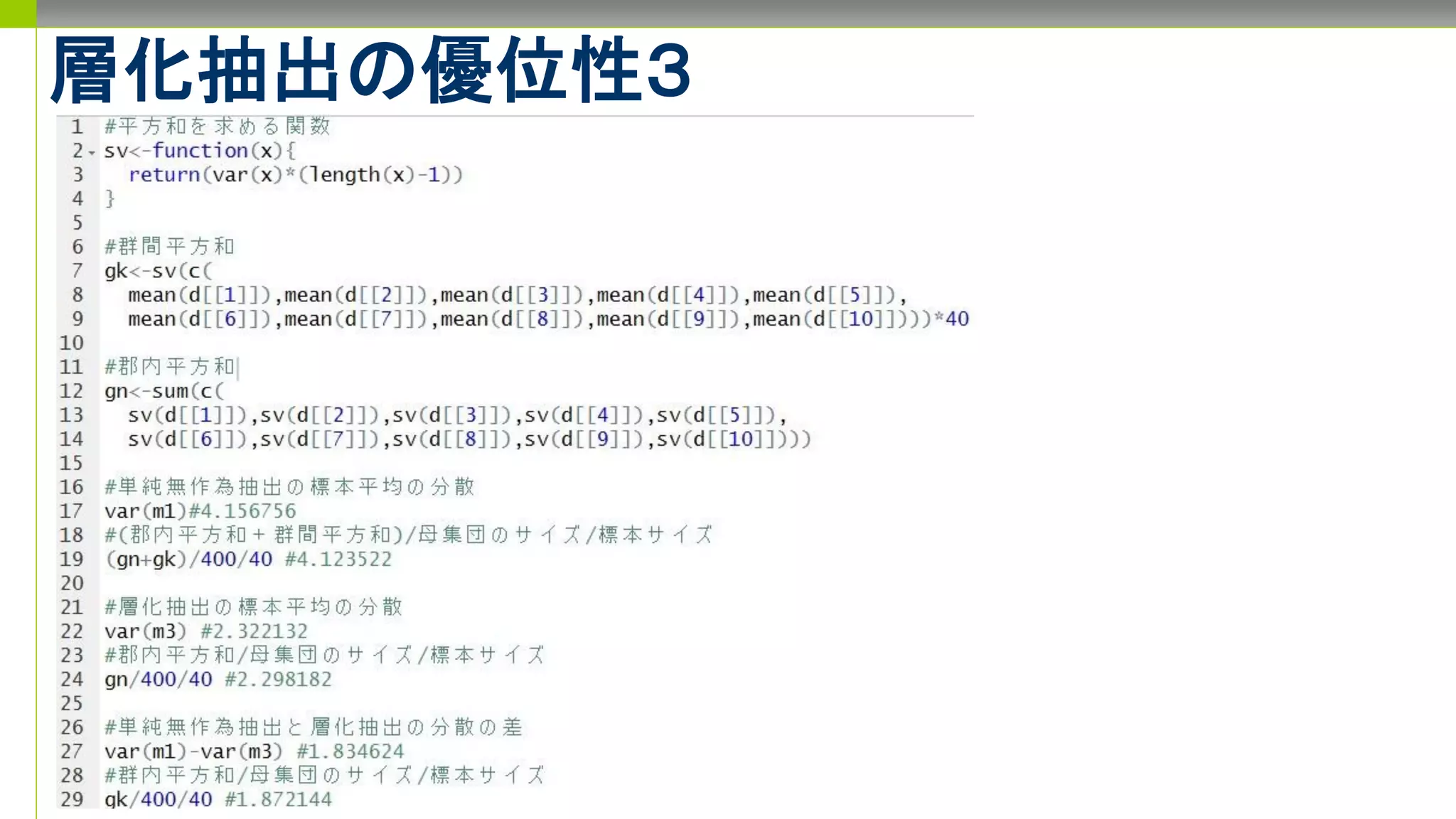
標本抽出で�なぜn=40なのか�についてのある考察 
PDF

PDF
2014年度秋学期 統計学 第10回 分布の推測とは - 標本調査,度数分布と確率分布 (2014. 12. 3) 
PDF

PDF

PDF
2014年度秋学期 統計学 第12回 分布の平均を推測する - 区間推定 (2014. 12. 17) 
PDF

PDF
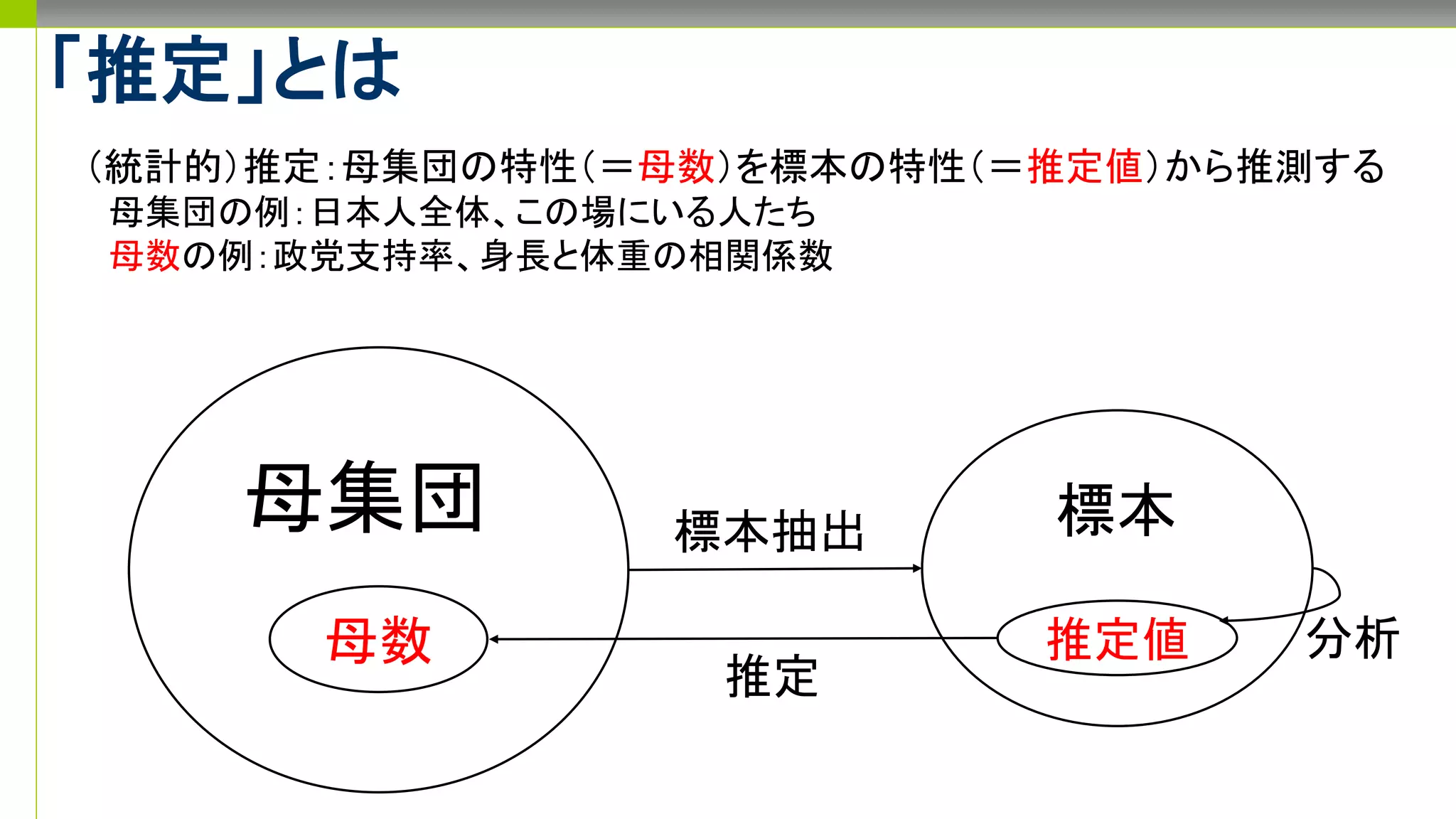
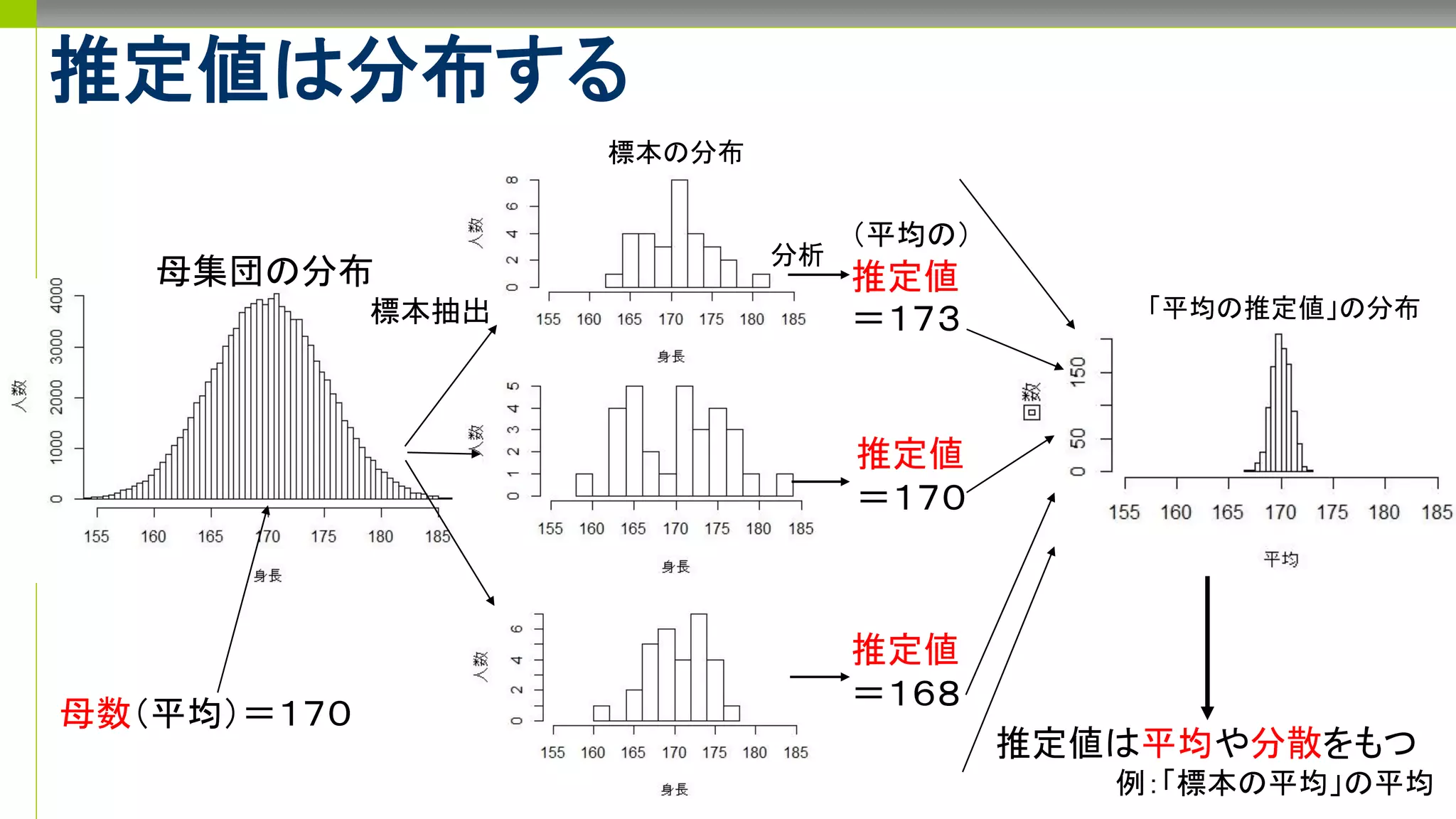
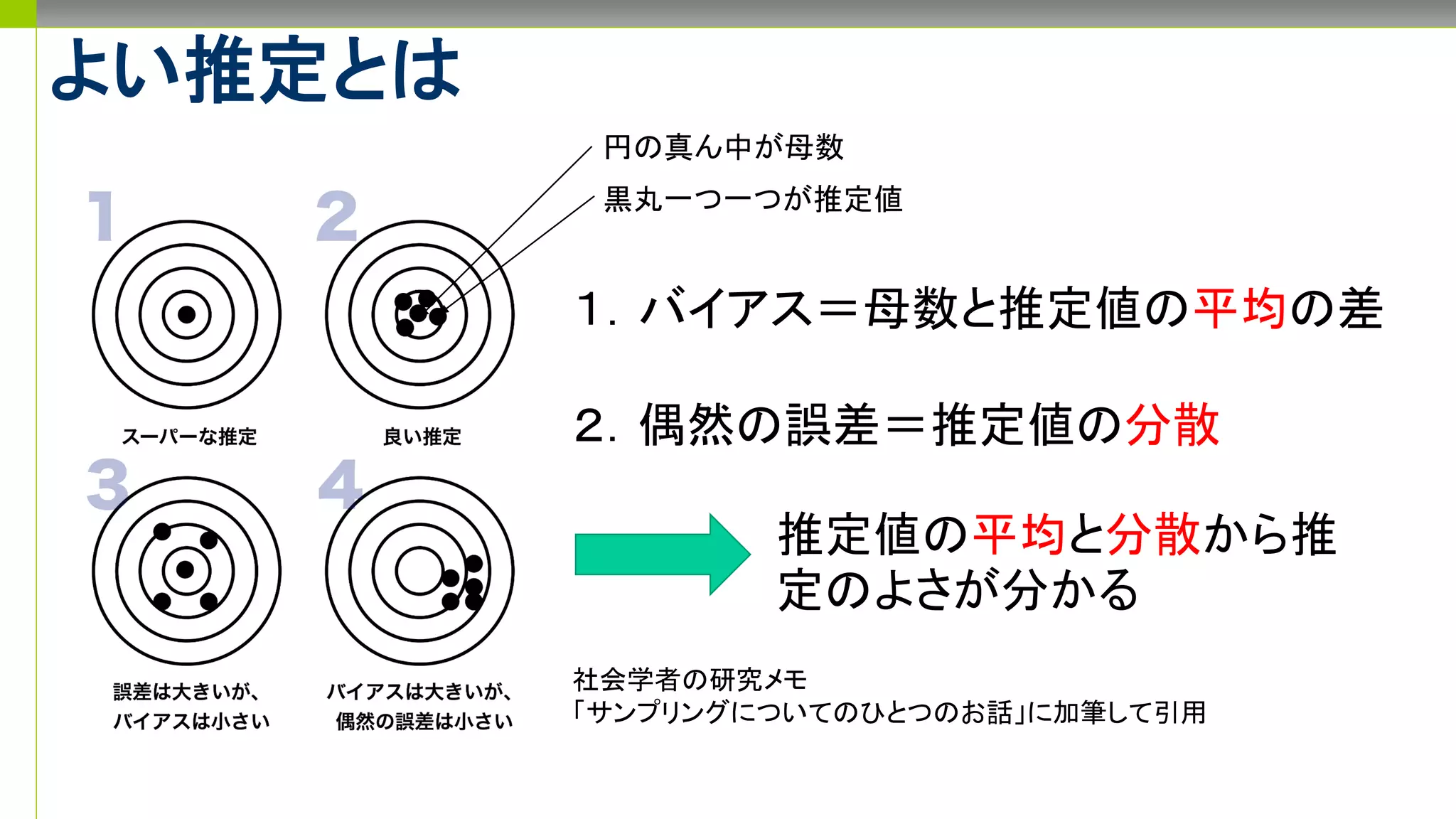
推定と標本抽出
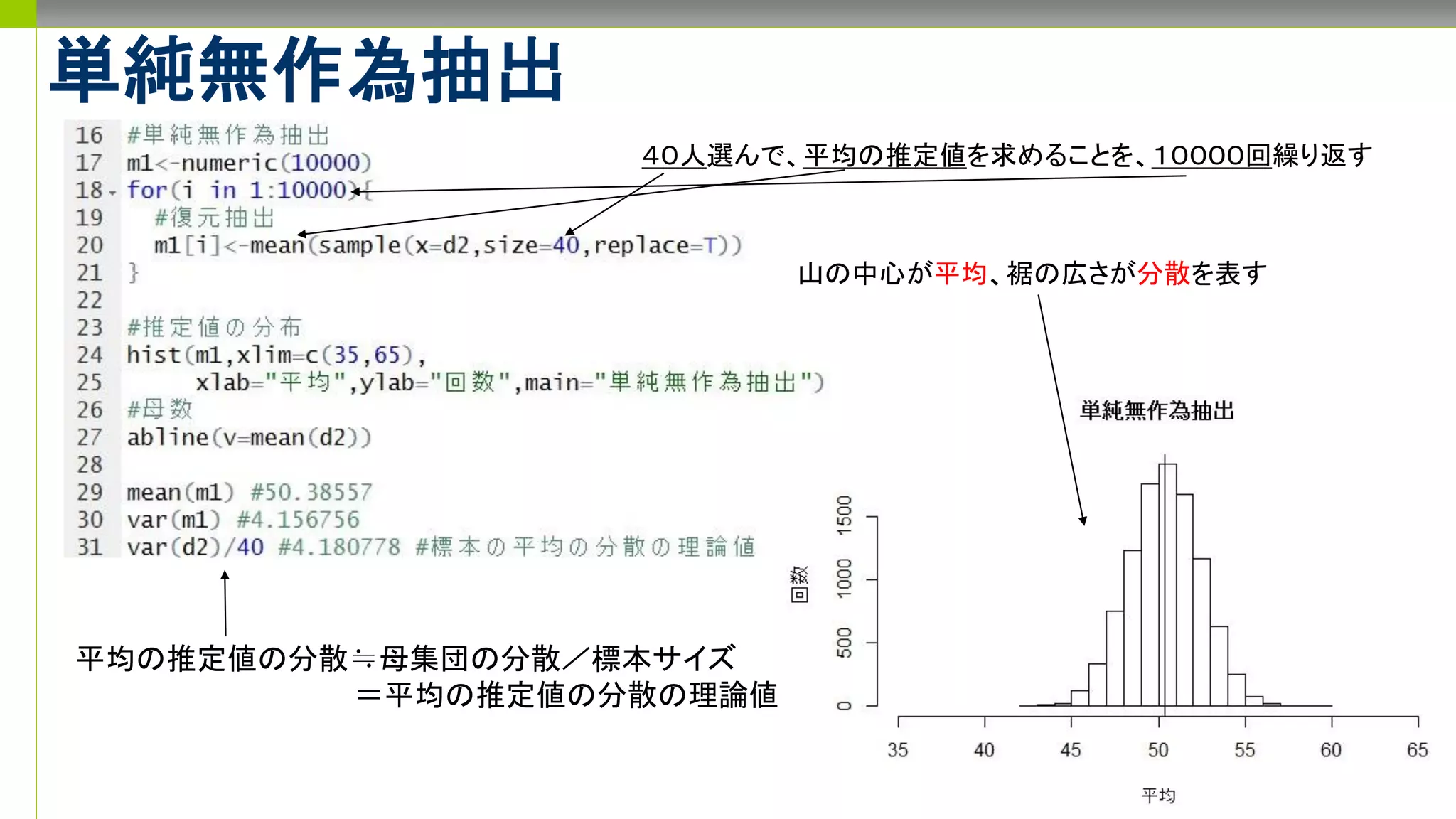
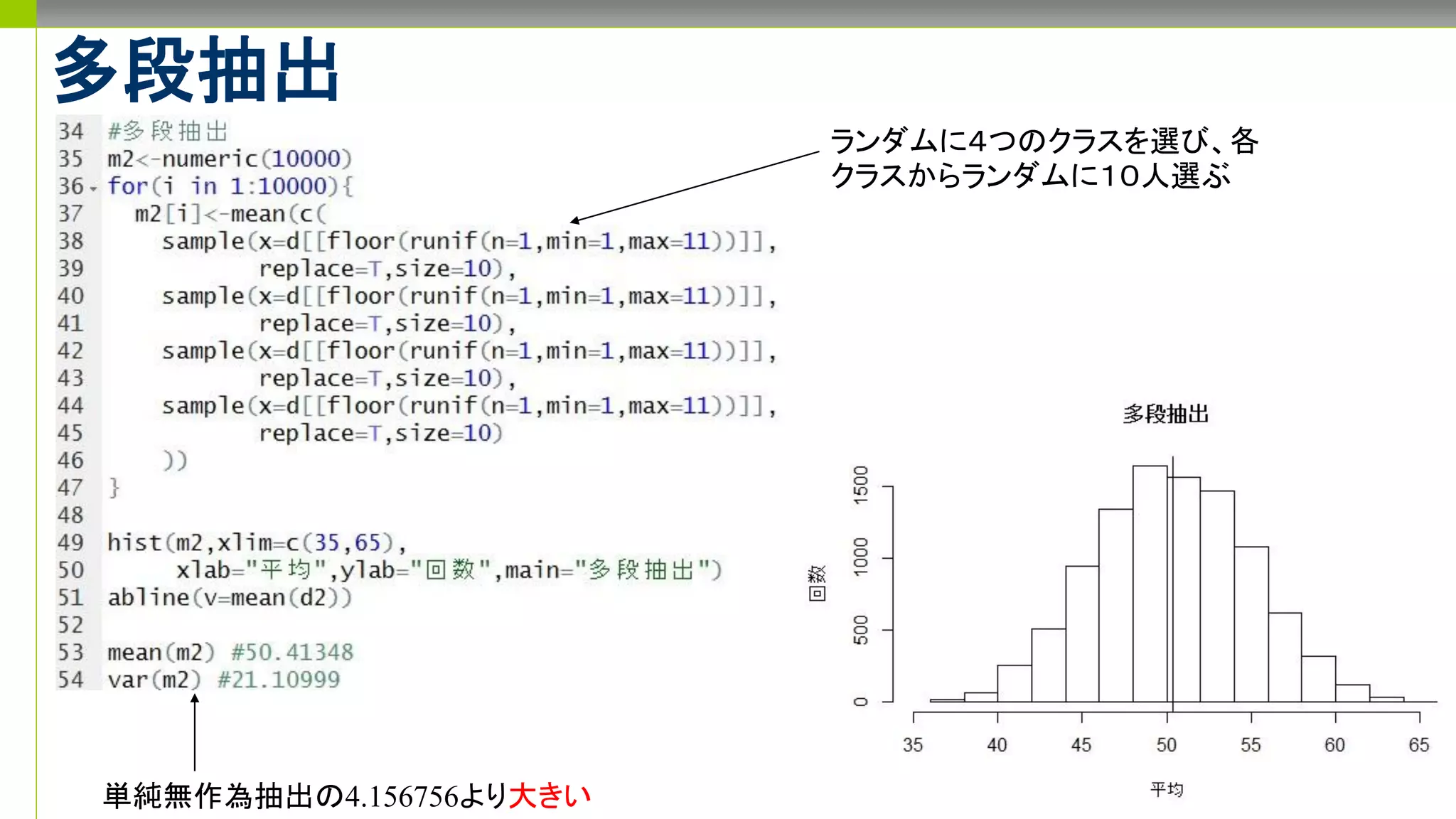
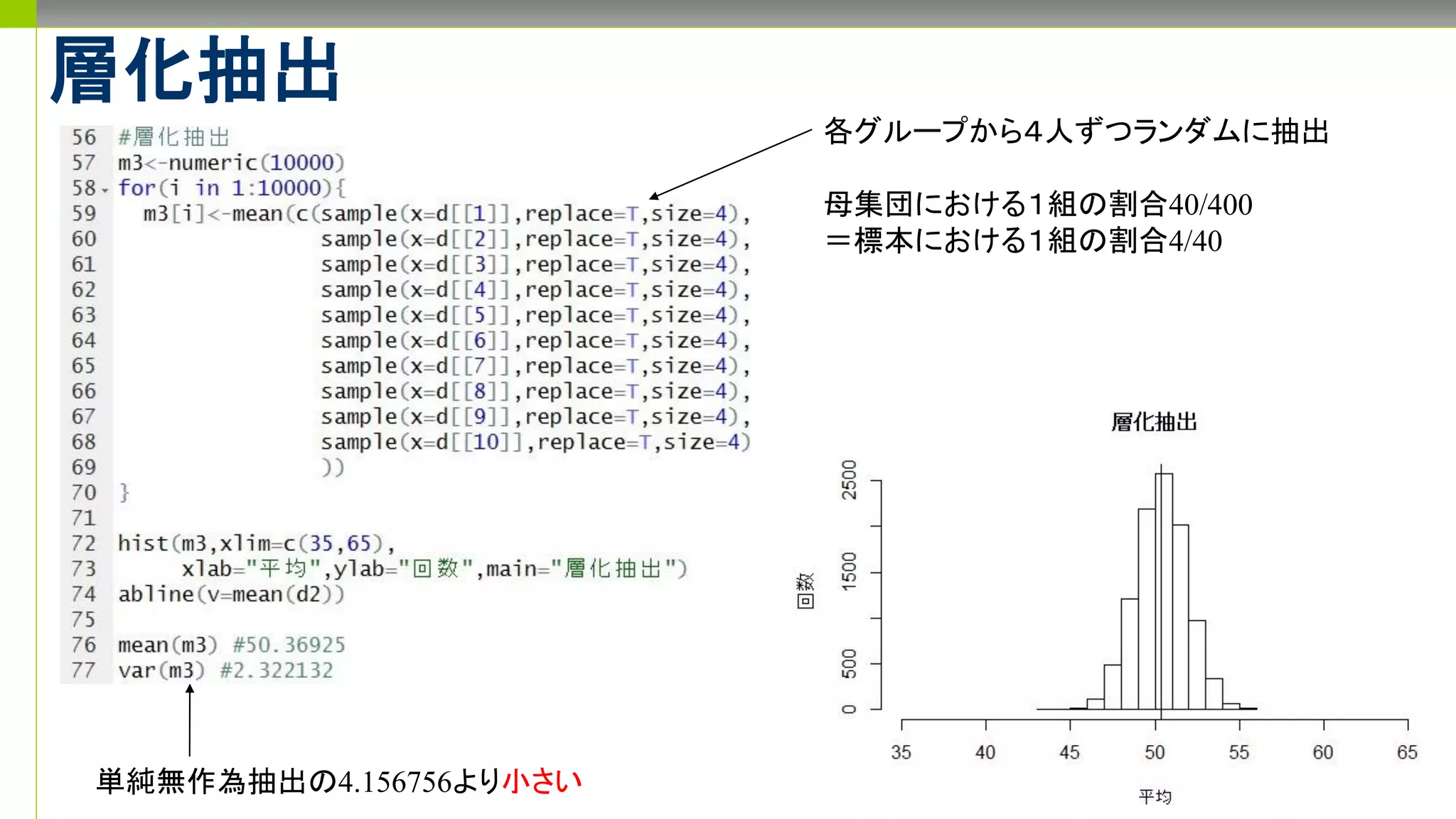
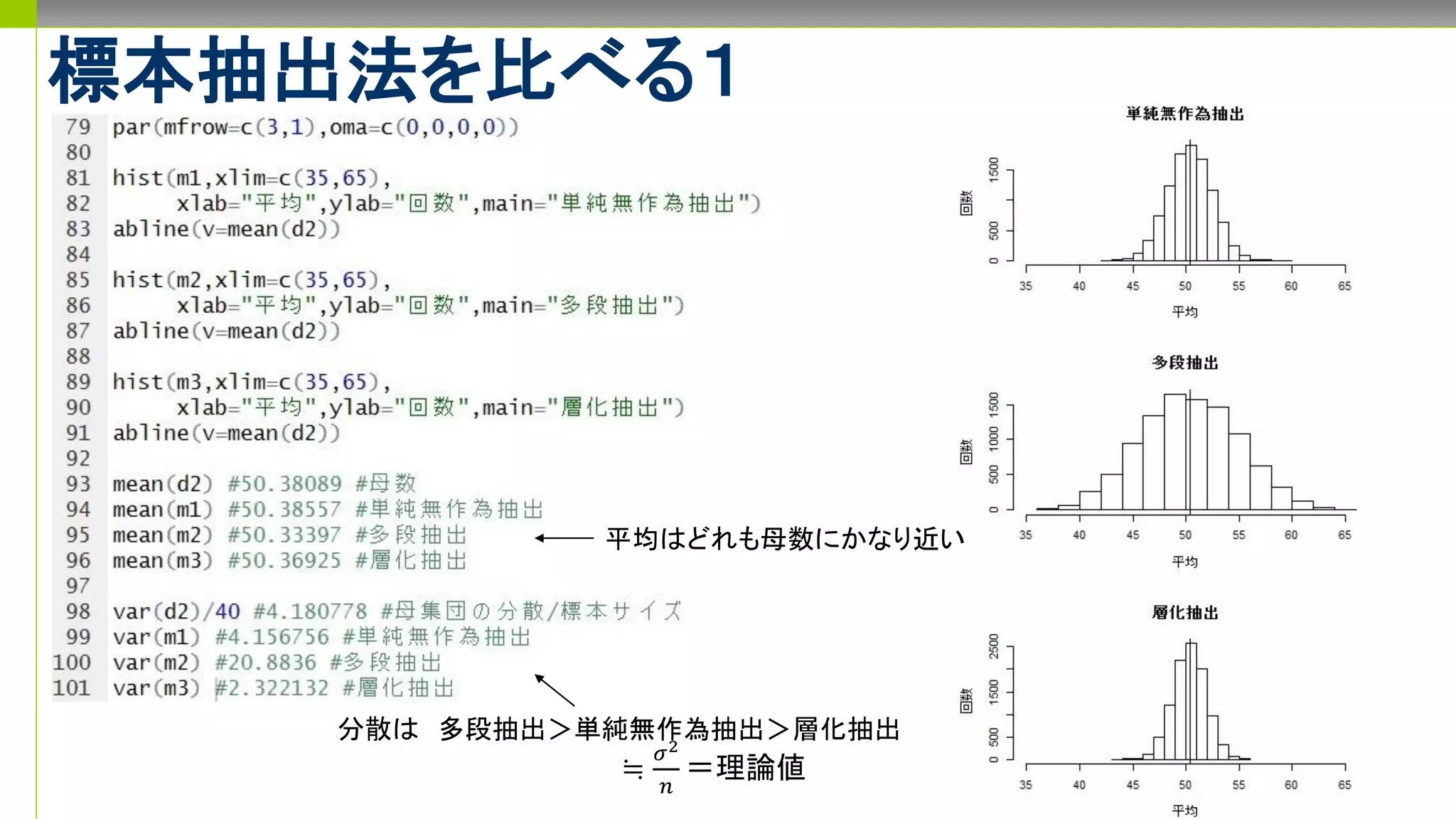
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
標本抽出法を比べる3
標本抽出法 推定値の平均 推定値の分散調査コスト
単純無作為抽出 ◯
母数と同じ
△
普通
計算しやすい
△
調査対象が散らばる
多段抽出 △
(割当てをうまくやれば)
母数と同じ
×
層ごとに母数が異なる
ほど大きくなりやすい
計算しづらい
◯
グループごとに調査対
象がまとまる
層化抽出 △
(割当てをうまくやれば)
母数と同じ
◯
層ごとに母数が異なる
ほど小さくなりやすい
計算しづらい
×
調査対象が散らばる
層の割り当てにコストが
かかる
- 17.
- 18.
- 19.