7/20/2013 32th Tokyo.R6
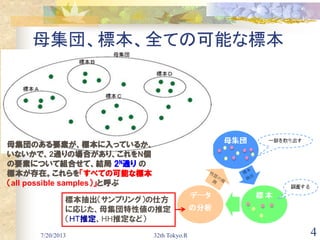
基本サンプリング
色々あるけど、今回はSIのみ!
SIの手順: 母集団の大きさ N 、標本の大きさ n と仮定
以下の作業をn回繰り返す
I. 1からNの整数iを1つ決める: ex. uを[0,1)の一様乱数として、
i=floor(u×N)+1
II. i が既に抽出された母集団の要素番号ならⅠに戻る
III. さもなければ、i を抽出する母集団の要素番号として記録する
⇒ [1,N]上の一様乱数を重複する事なくn個生成し、母集団から対応
する要素を抽出
非復元 復元
等確率(単純ランダム) SI SIR
不等確率(確率比例) PP PPR
系統サンプリング SY
7/20/2013 32th Tokyo.R9
HT推定量の定義~準備
包含確率
一次の包含確率
母集団の要素 i が、実現する
標本に含まれる確率
母集団の要素 i を含む標本 s について p(s) を足し挙げて得る
二次の包含確率
母集団の要素 i と j が、同時
に実現する標本に含まれる確率
標本帰属指標
母集団の要素 i が標本 s に
含まれているかどうかを表す確率変数
is
i sp
ji
ji
sp
jis
i
ij
&
サンプリングデザイン
si
si
sIi
0
1
sIsI ii 2
i を含むsに関する和
i と j を両方含むsに関する和
10.
7/20/2013 32th Tokyo.R10
HT推定量の定義
HT推定量(the Horvitz-Thompson estimator)は、
母集団総計 の不偏推定量を与える
標本の各y値を包含確率で割って足しこむ
包含確率がわかればすぐに算出できる
si i
i
HT
y
ˆ
※ どの母集団の要素も標本に含まれる可能性があると仮定!
11.
7/20/2013 32th Tokyo.R11
HT推定量の期待値
HT推定量の期待値
母集団平均 μ の不偏推定量も直ちに作れる
Ui Ui
i
Ui
i
i
i
i
i
i
Ui
i
i
i
si i
i
HT
y
y
IE
y
I
y
E
y
EE
ˆ
確かに不偏推定量
NN
EE
N
HT
HT
HT
HT
ˆ
ˆ
ˆ
ˆ
i
isisSs
ii spspspsIIE
01
i を含む標本 i を含まない標本
12.
7/20/2013 32th Tokyo.R12
HT推定量の分散・分散の推定量
HT推定量の分散
HT推定量の分散の推定量
ここで、
ji
Ui ji ji
jiij
Ui Ui
i
i
i
Uj ji
ji
ijHT yyy
yy
Var
21
ˆ
ji
Ui ji ijjisi Ui
i
i
i
sj ji
ji
ij
ij
HT yyy
yy
111
ˆ 2
2
ji
ji
jiij
ii
ij
1
め、一般に算出不能母集団の要素であるた:iy
、値を算出可能標本の要素であるため:iy
※ 母集団のどの2つの要素も
標本に同時に含まれる
可能性があると仮定!
13.
7/20/2013 32th Tokyo.R13
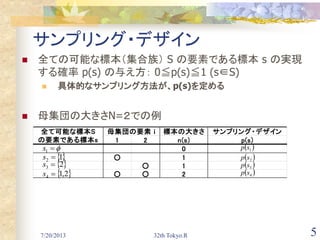
SIにおけるHT推定量 [1/3]
一次と二次の包含確率が解ればHT推定量を算出可能
一次の包含確率
標本の大きさが n の可能な標本数:
従って、サンプリング・デザイン
母集団のある要素 i を含む標本の数:
nsn
nsn
n
N
sp
0
1
通り
n
N
通り
1
1
n
N
N
n
n
Nn
N
sp
is
i
1
1
1
14.
7/20/2013 32th Tokyo.R14
SIにおけるHT推定量 [2/3]
二次の包含確率
母集団のある要素 i と j を含む標本の数:
通り
2
2
n
N
1
11
2
2
&
NN
nn
n
Nn
N
sp
jis
ij
15.
7/20/2013 32th Tokyo.R15
SIにおけるHT推定量 [3/3]
HT推定量は母集団総計 の不偏推定量を与える
SIによるものである事を強調して、 と書く
統計量である標本平均 が、SIの場合に、母集団平均
のHT推定量 (不偏推定量)!
y
N
yN
N
SI
SI
ˆ
ˆ
si
i
si
i
si i
i
SI yNy
n
N
N
n
yy
ˆ
SIˆ
y
SIˆ
16.
7/20/2013 32th Tokyo.R16
SIにおけるHT推定量の分散
抽出率
有限母集団修正項
SIにおけるHT推定量の分散
ここで、 は母集団分散であり一般に不明。従って、その
推定量の算出が必要となる。
n
fN
n
nNNVar SI
2
2
2
1ˆ
N
n
f
N
nN
f
1
n
f
nN
nN
Var SI
22
1ˆ
2
17.
7/20/2013 32th Tokyo.R17
SIにおけるHT推定量の分散の推定量
標本分散
SIにおけるHT推定量の分散の推定量
n
i
i yy
n
s
1
22
1
1
n
s
fN
n
s
nNNSI
2
2
2
1ˆ
n
s
f
n
s
N
nN
SI
22
1ˆ
18.
7/20/2013 32th Tokyo.R18
SIにおける標本分散の期待値
HT推定量の分散の不偏推定量 について
が成り立っている。
だから、両者を等しいとおいて下記を得る
統計量である標本分散の が、SIの場合に、母集団分散
の不偏推定量!
n
fNVar SI
2
2
1ˆ
n
sE
fN
n
s
fNEE SI
2
2
2
2
11ˆ
SI ˆ
SISI VarE ˆˆ
(不偏)22
sE
2
s
2





![7/20/2013 32th Tokyo.R 6
基本サンプリング
色々あるけど、今回はSIのみ!
SIの手順: 母集団の大きさ N 、標本の大きさ n と仮定
以下の作業をn回繰り返す
I. 1からNの整数iを1つ決める: ex. uを[0,1)の一様乱数として、
i=floor(u×N)+1
II. i が既に抽出された母集団の要素番号ならⅠに戻る
III. さもなければ、i を抽出する母集団の要素番号として記録する
⇒ [1,N]上の一様乱数を重複する事なくn個生成し、母集団から対応
する要素を抽出
非復元 復元
等確率(単純ランダム) SI SIR
不等確率(確率比例) PP PPR
系統サンプリング SY](https://image.slidesharecdn.com/siht-130720031939-phpapp01/85/Si-ht-6-320.jpg)





![7/20/2013 32th Tokyo.R 13
SIにおけるHT推定量 [1/3]
一次と二次の包含確率が解ればHT推定量を算出可能
一次の包含確率
標本の大きさが n の可能な標本数:
従って、サンプリング・デザイン
母集団のある要素 i を含む標本の数:
nsn
nsn
n
N
sp
0
1
通り
n
N
通り
1
1
n
N
N
n
n
Nn
N
sp
is
i
1
1
1
](https://image.slidesharecdn.com/siht-130720031939-phpapp01/85/Si-ht-13-320.jpg)
![7/20/2013 32th Tokyo.R 14
SIにおけるHT推定量 [2/3]
二次の包含確率
母集団のある要素 i と j を含む標本の数:
通り
2
2
n
N
1
11
2
2
&
NN
nn
n
Nn
N
sp
jis
ij
](https://image.slidesharecdn.com/siht-130720031939-phpapp01/85/Si-ht-14-320.jpg)
![7/20/2013 32th Tokyo.R 15
SIにおけるHT推定量 [3/3]
HT推定量は母集団総計 の不偏推定量を与える
SIによるものである事を強調して、 と書く
統計量である標本平均 が、SIの場合に、母集団平均
のHT推定量 (不偏推定量)!
y
N
yN
N
SI
SI
ˆ
ˆ
si
i
si
i
si i
i
SI yNy
n
N
N
n
yy
ˆ
SIˆ
y
SIˆ](https://image.slidesharecdn.com/siht-130720031939-phpapp01/85/Si-ht-15-320.jpg)

























![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)





















































