Downloaded 69 times

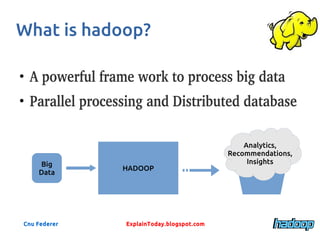














Hadoop is a powerful framework for processing big data through parallel processing and distributed databases, originally evolved from Google’s MapReduce and GFS. It manages data using a distributed file system (HDFS) and employs key components such as NameNode, DataNode, and Resource Manager for efficient data handling and task execution. Its significance lies in addressing the rapid growth of data and the need for effective analytics, offering a solution where traditional methods fall short.



















































































