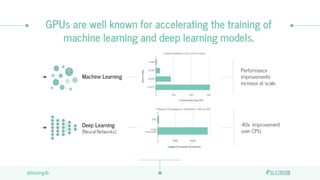
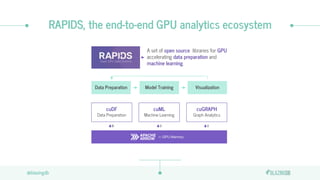
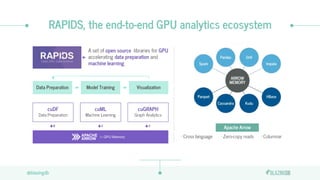
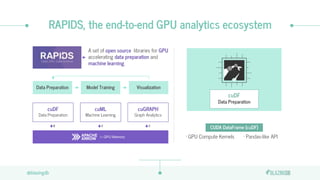
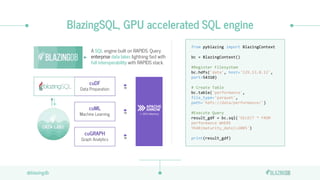
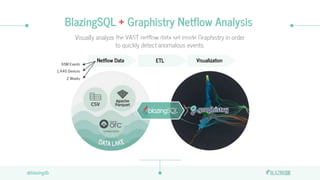
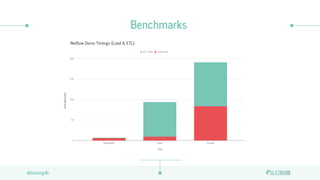
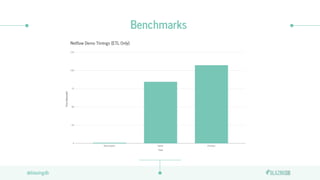
The document discusses the limitations of CPUs for data science workloads and highlights the advantages of using GPUs for training machine learning models, offering a 40x performance improvement. It introduces RAPIDS, a GPU analytics ecosystem consisting of open-source libraries for data preparation, machine learning, and graph analytics. Additionally, it describes BlazeSQL, a GPU-accelerated SQL engine that allows for fast queries on data lakes and integration with Python for efficient data handling.