Downloaded 13 times




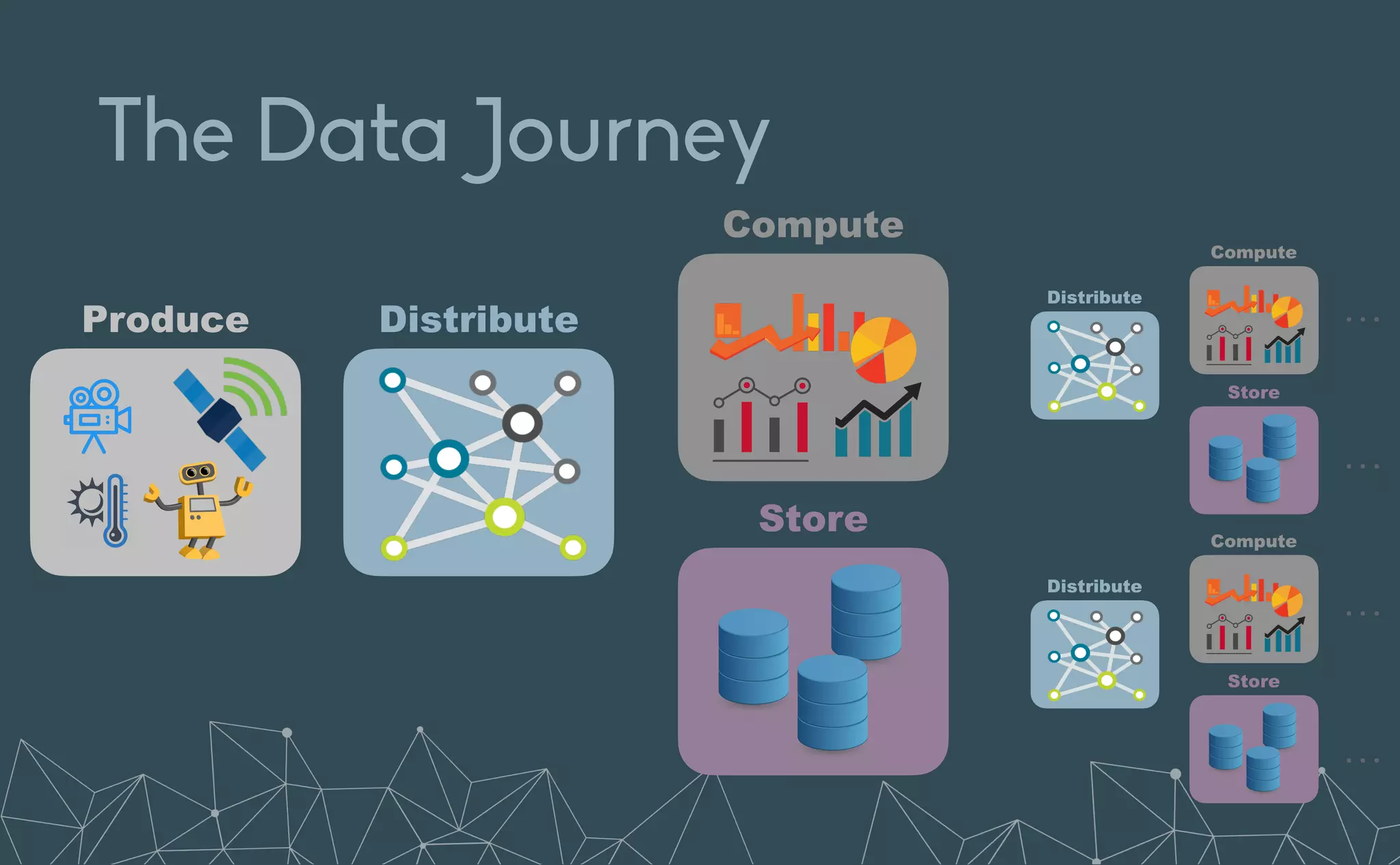
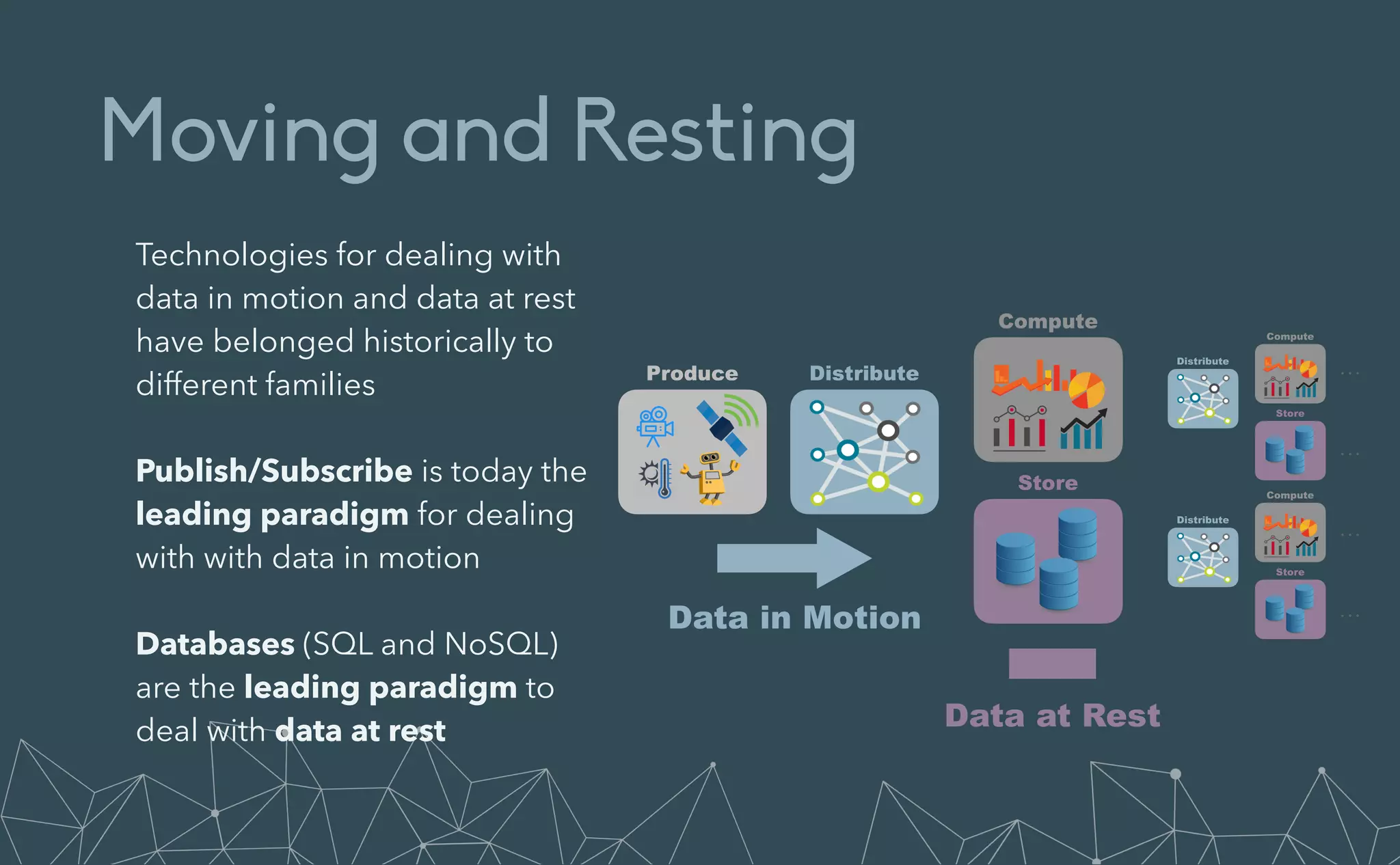
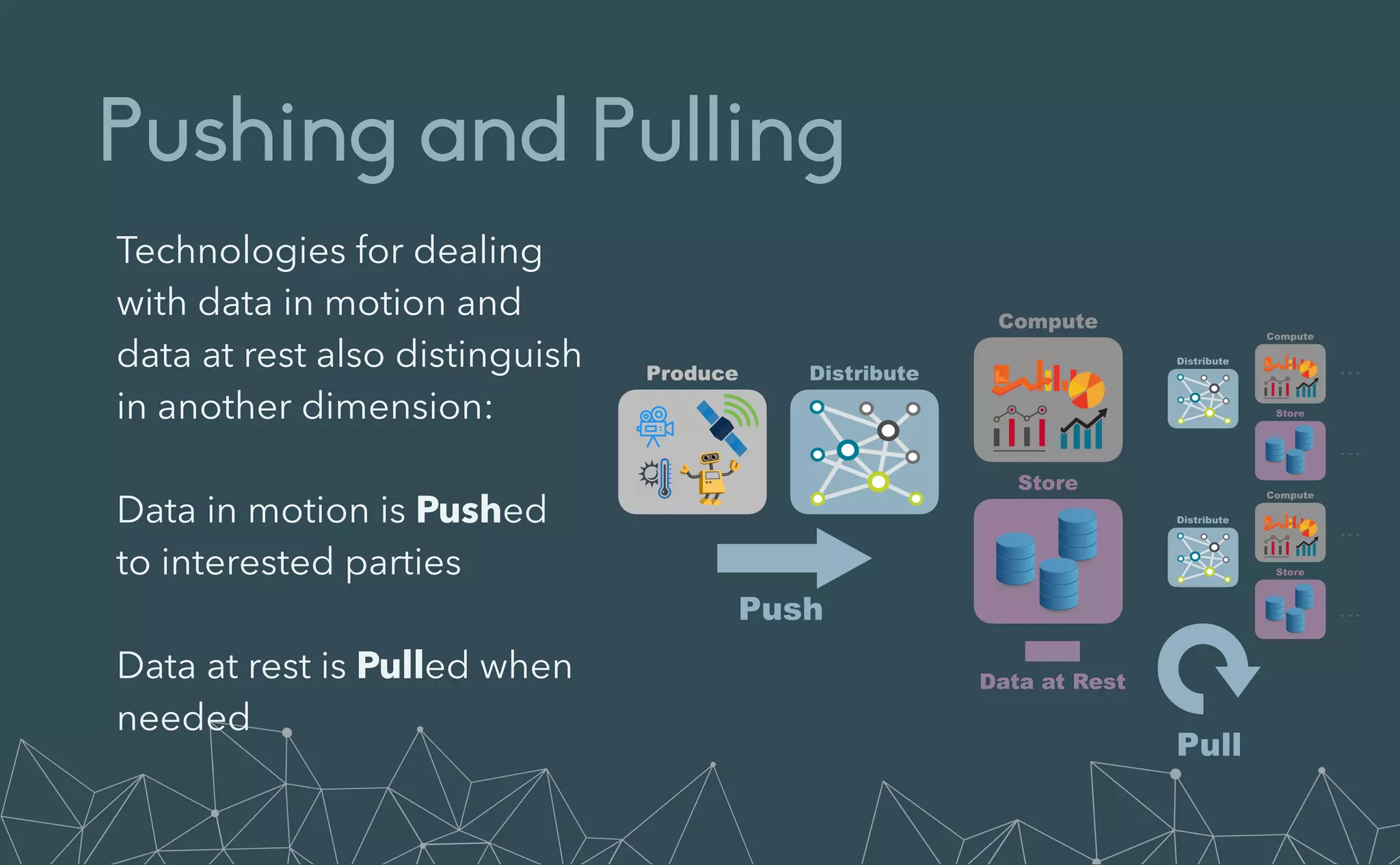
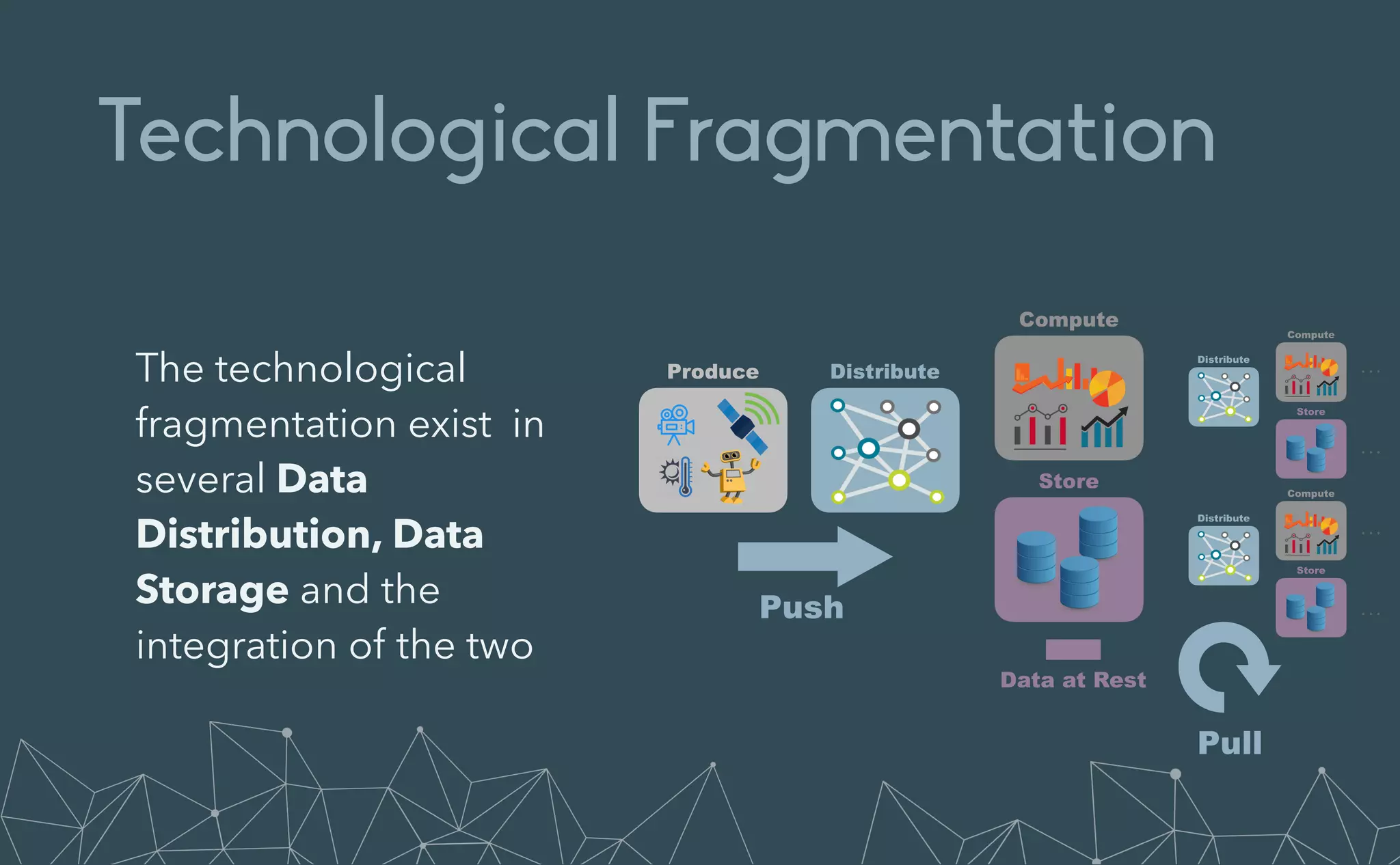
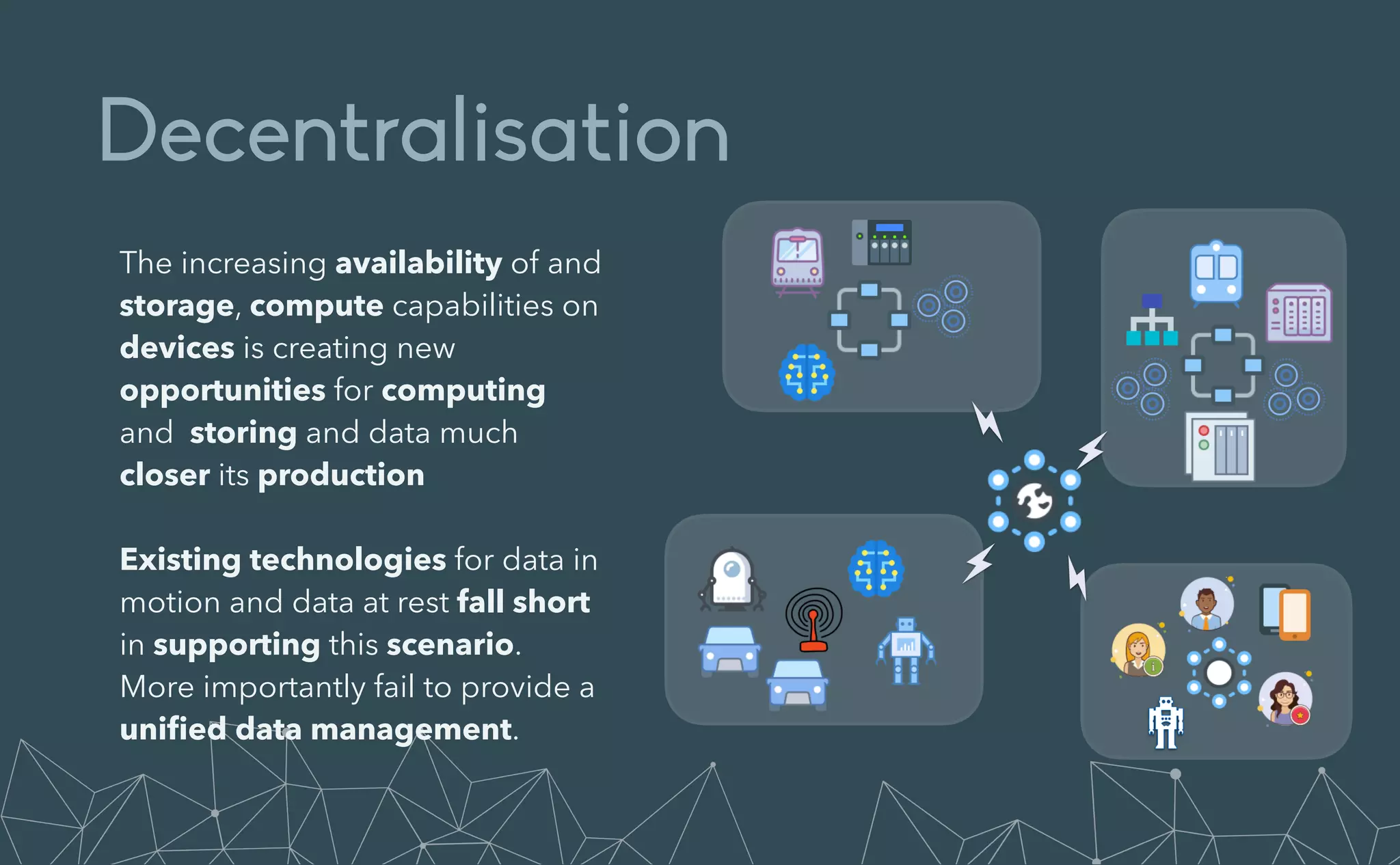



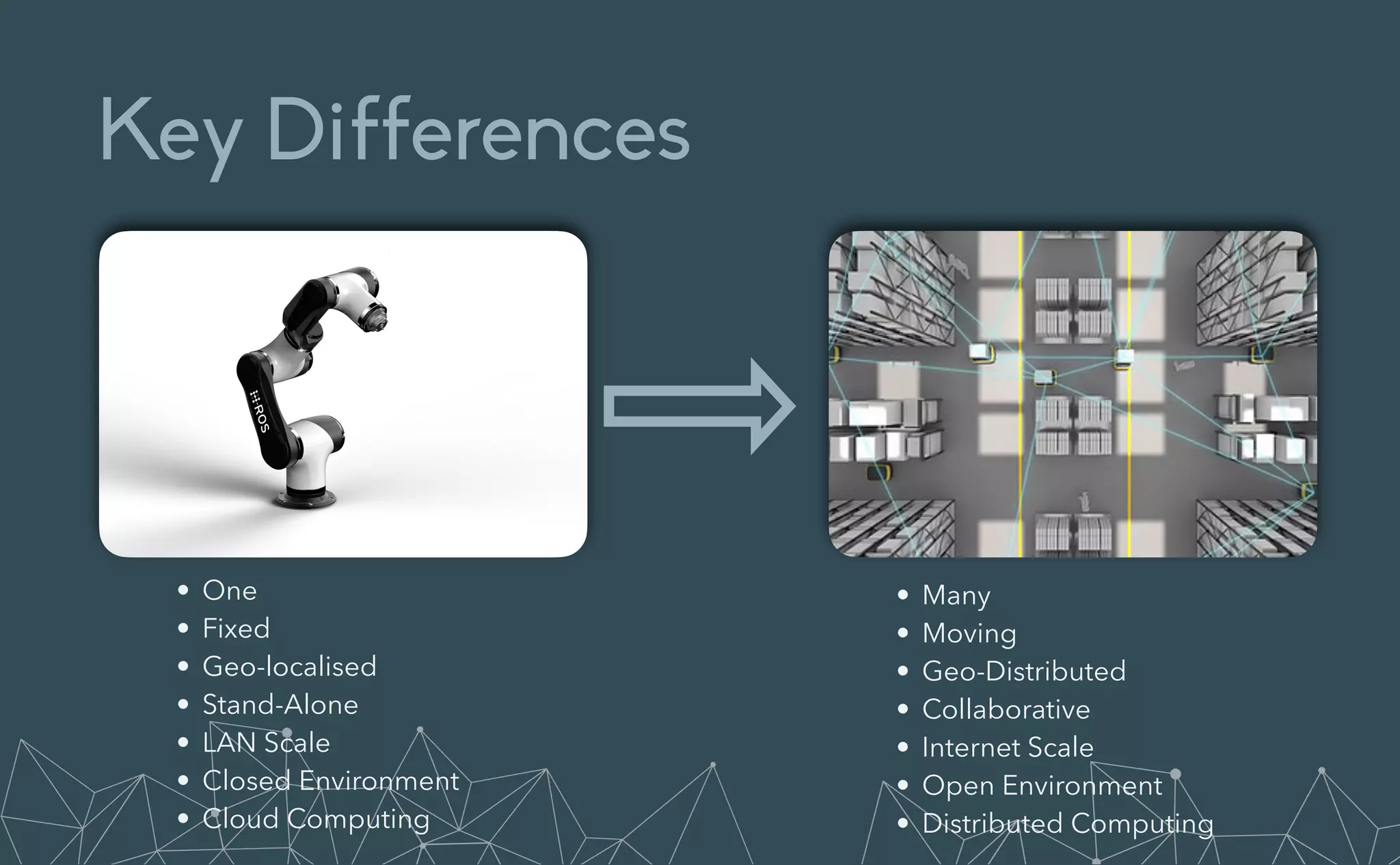

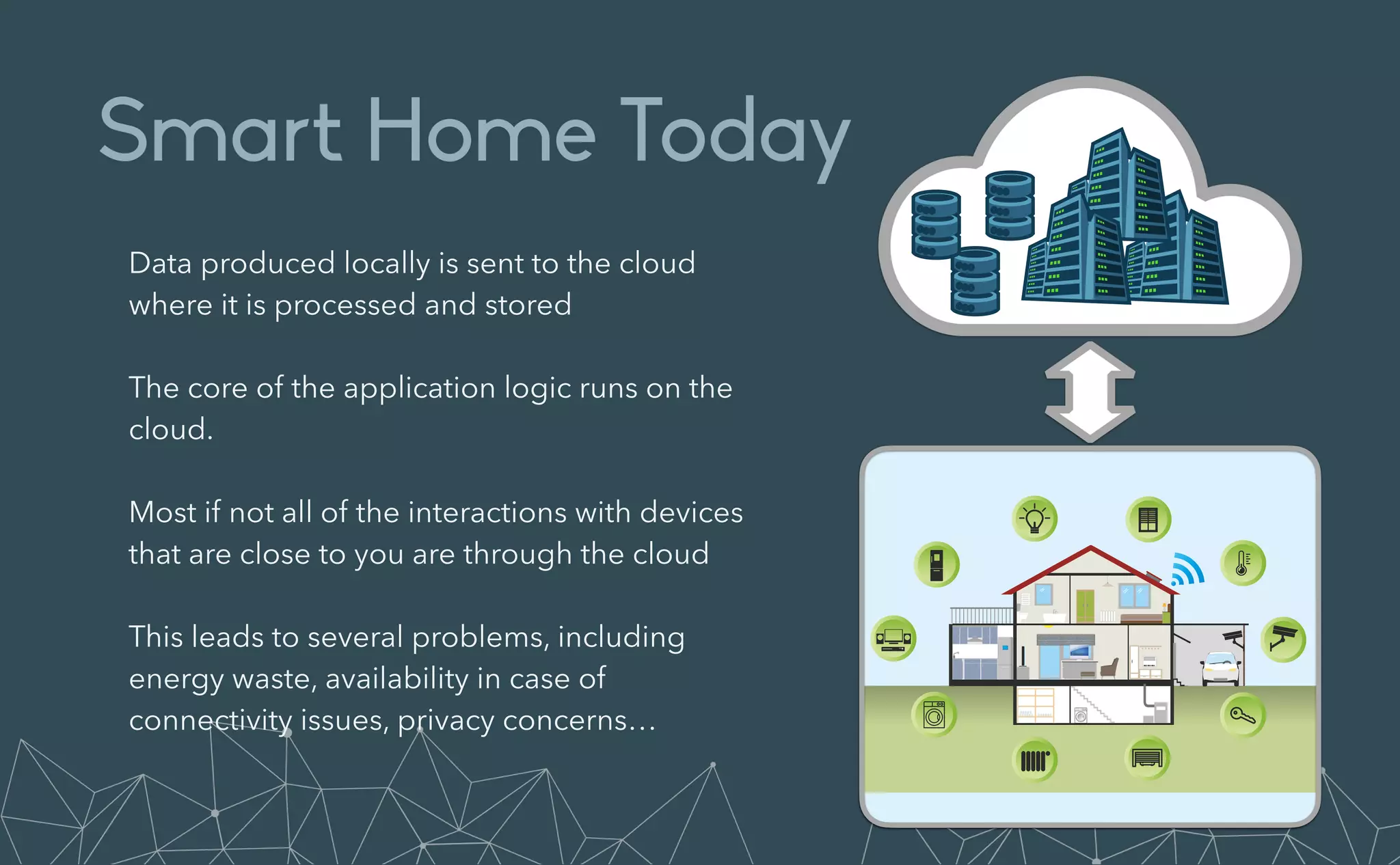
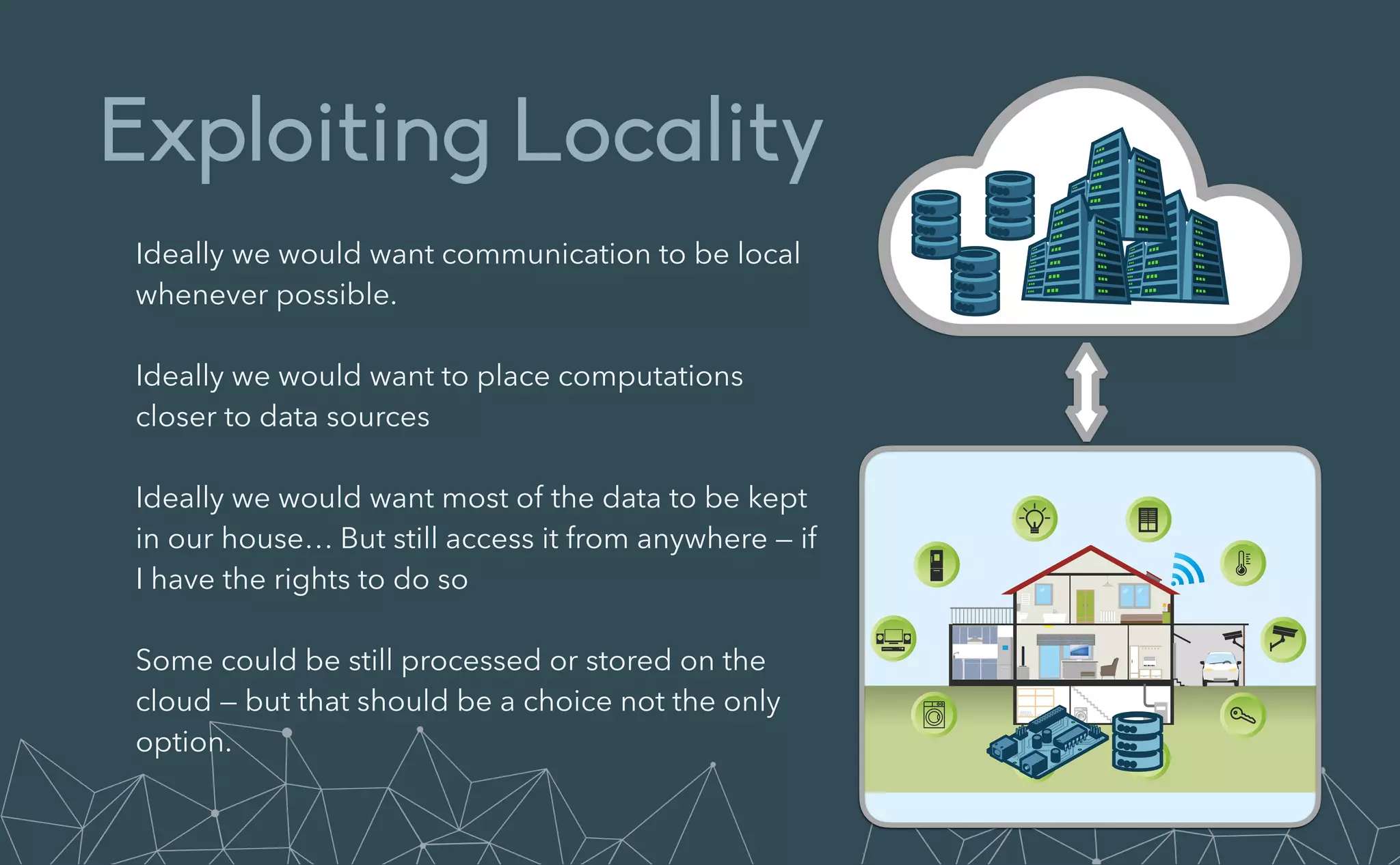
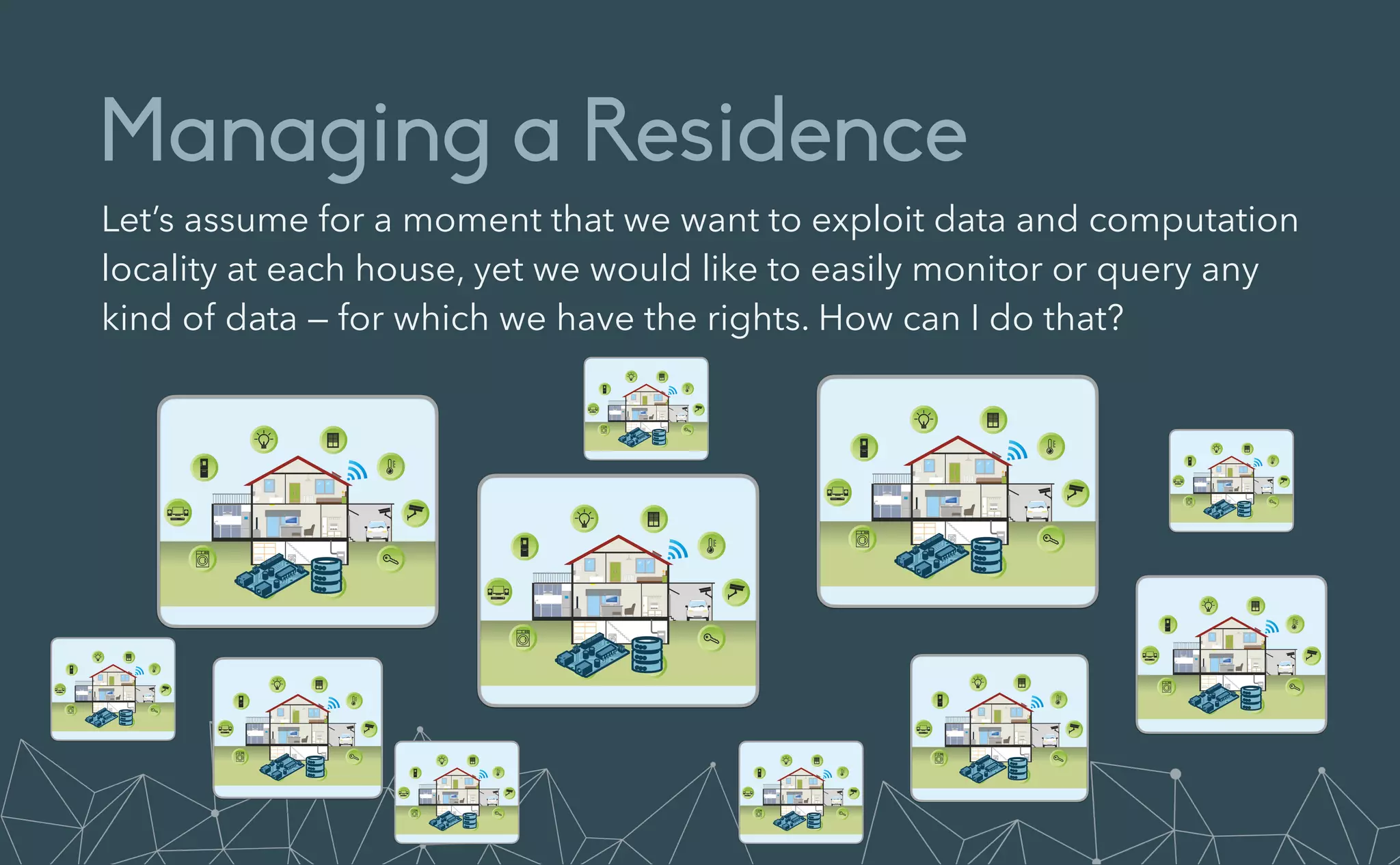
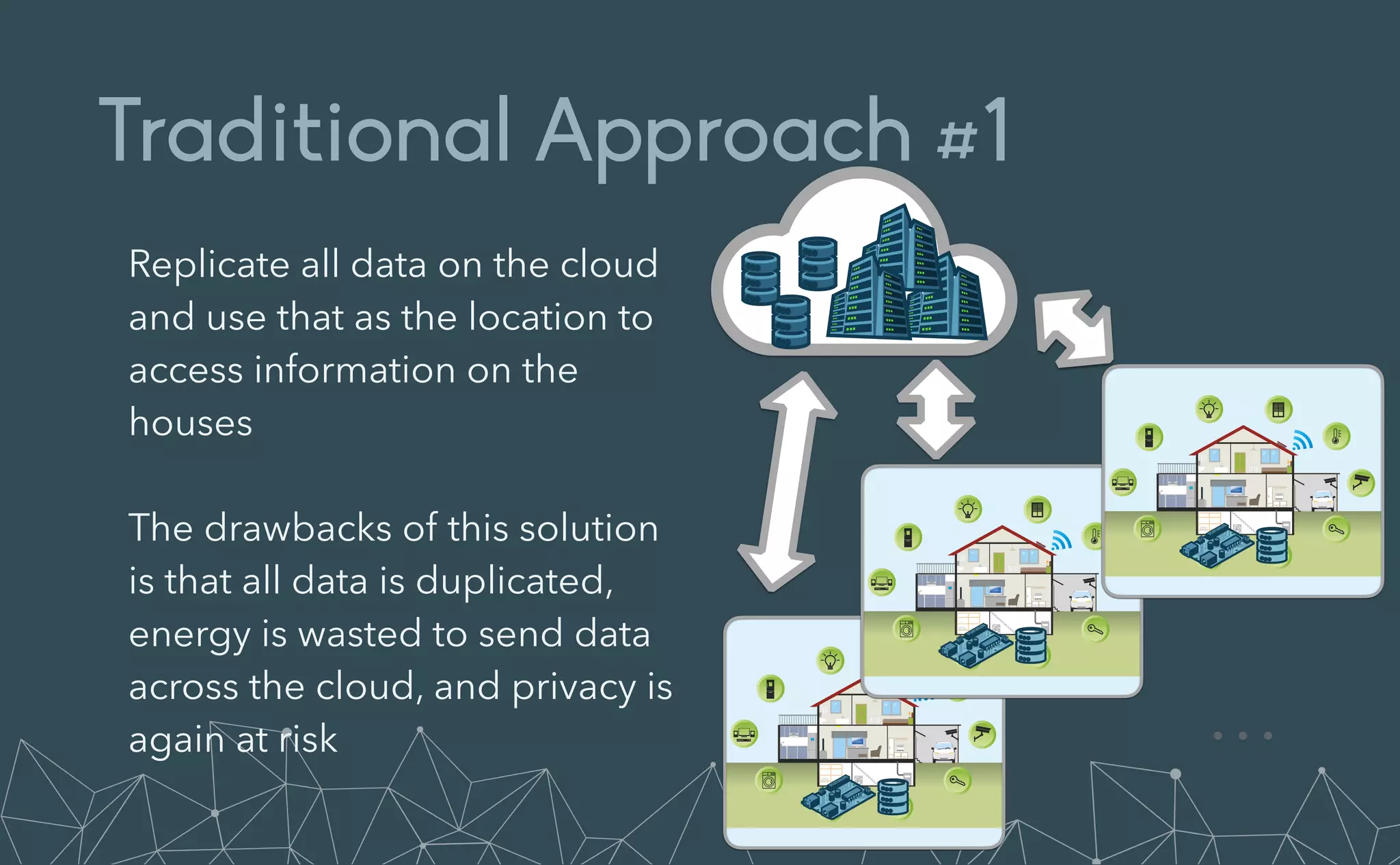
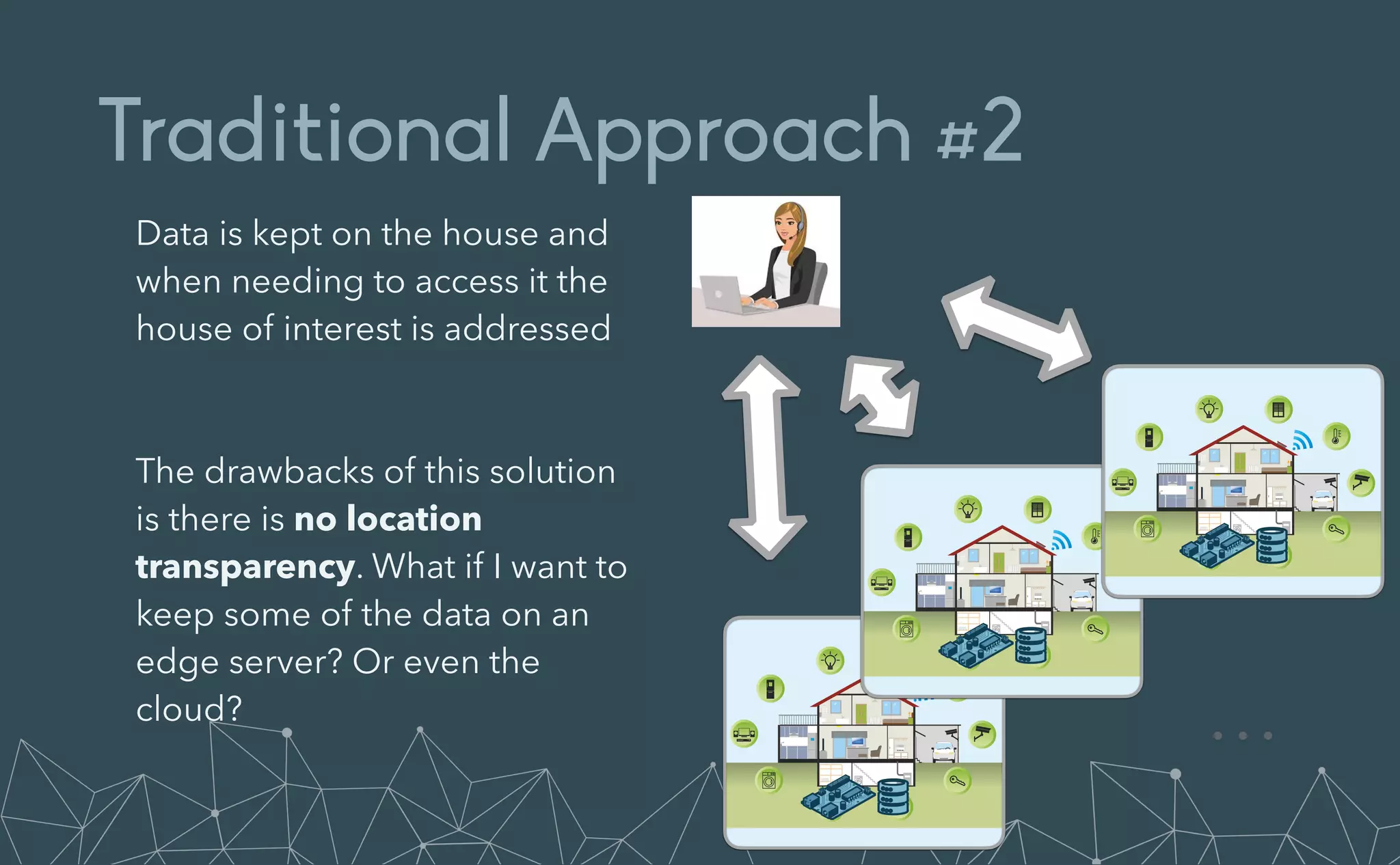














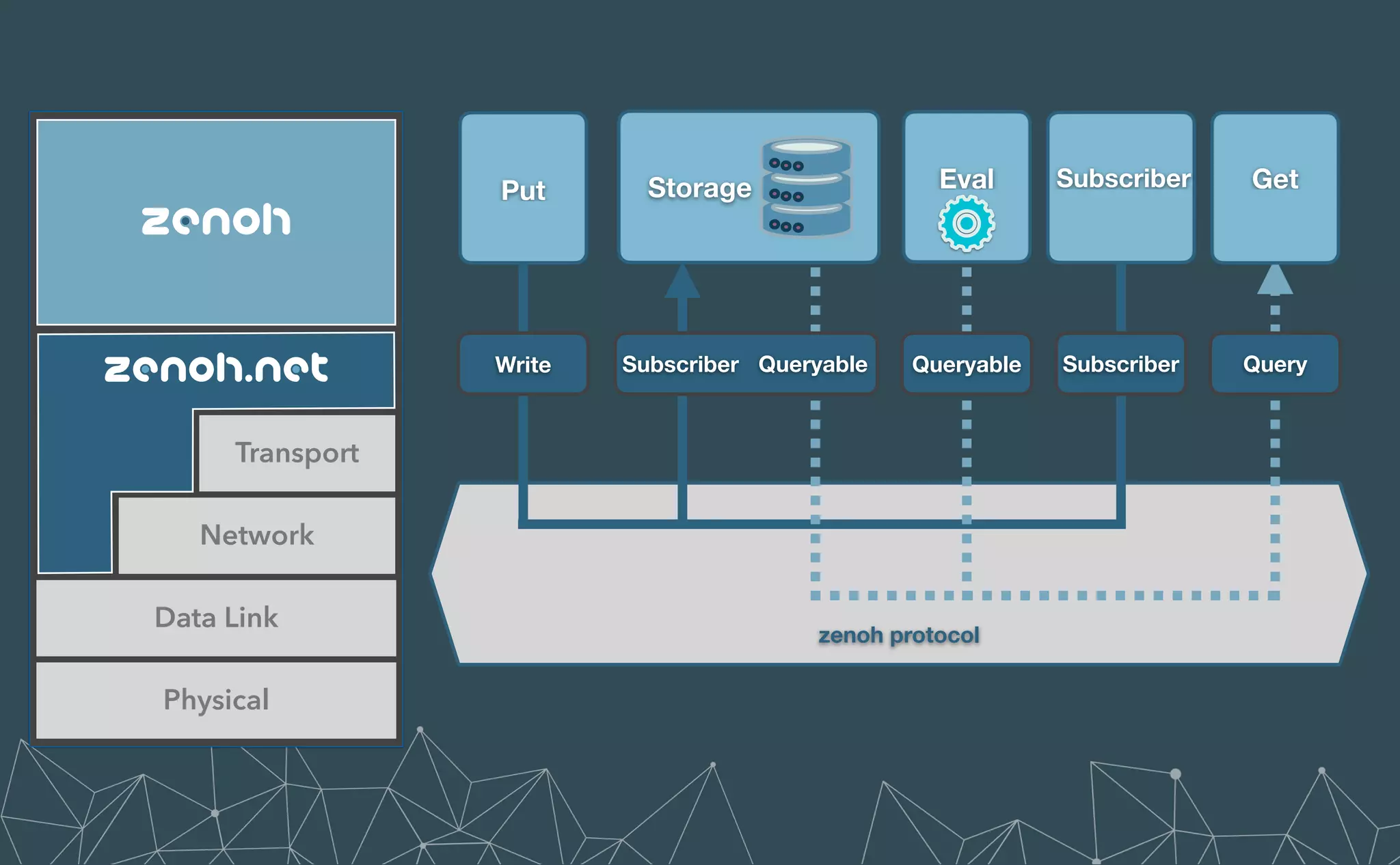
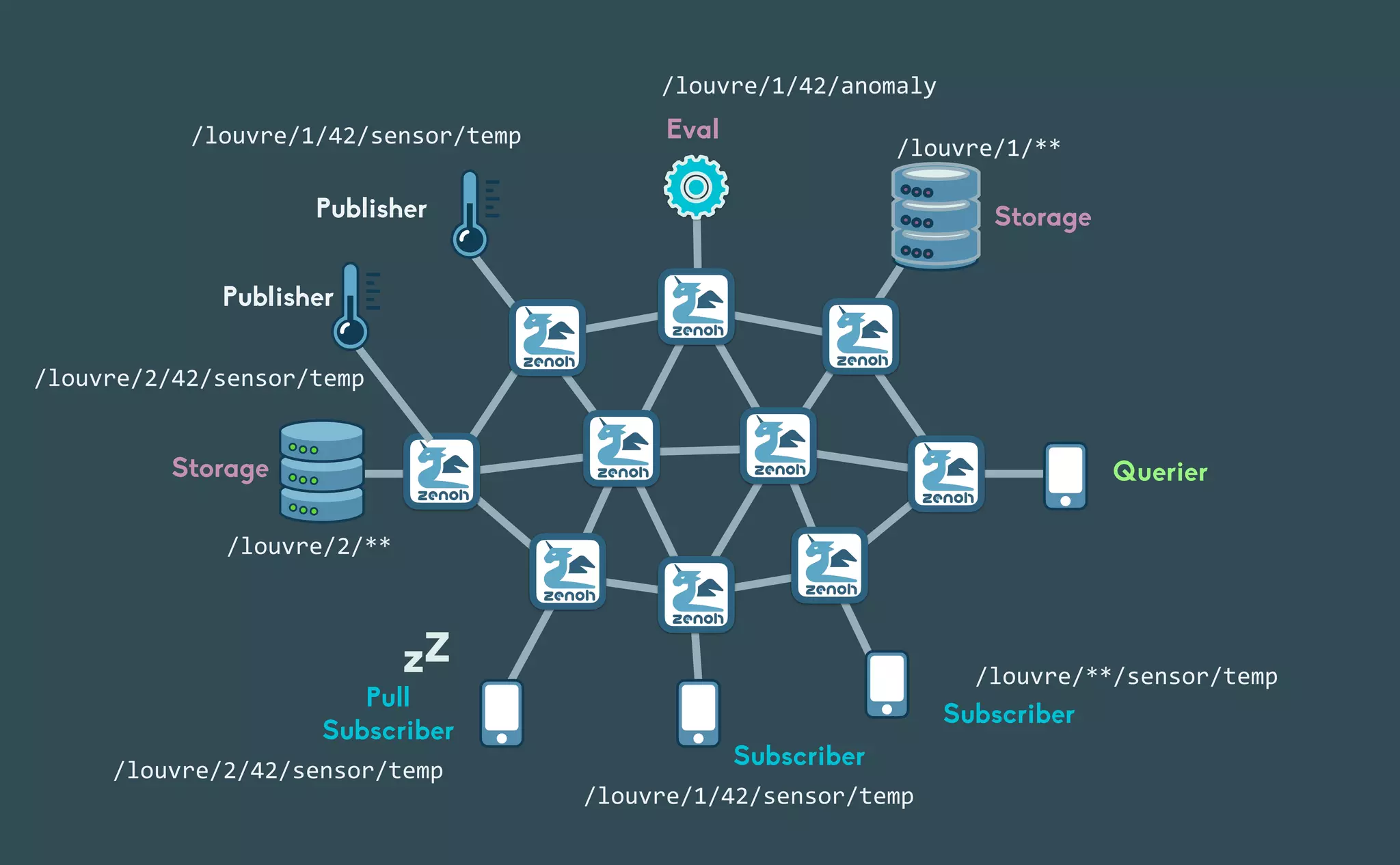
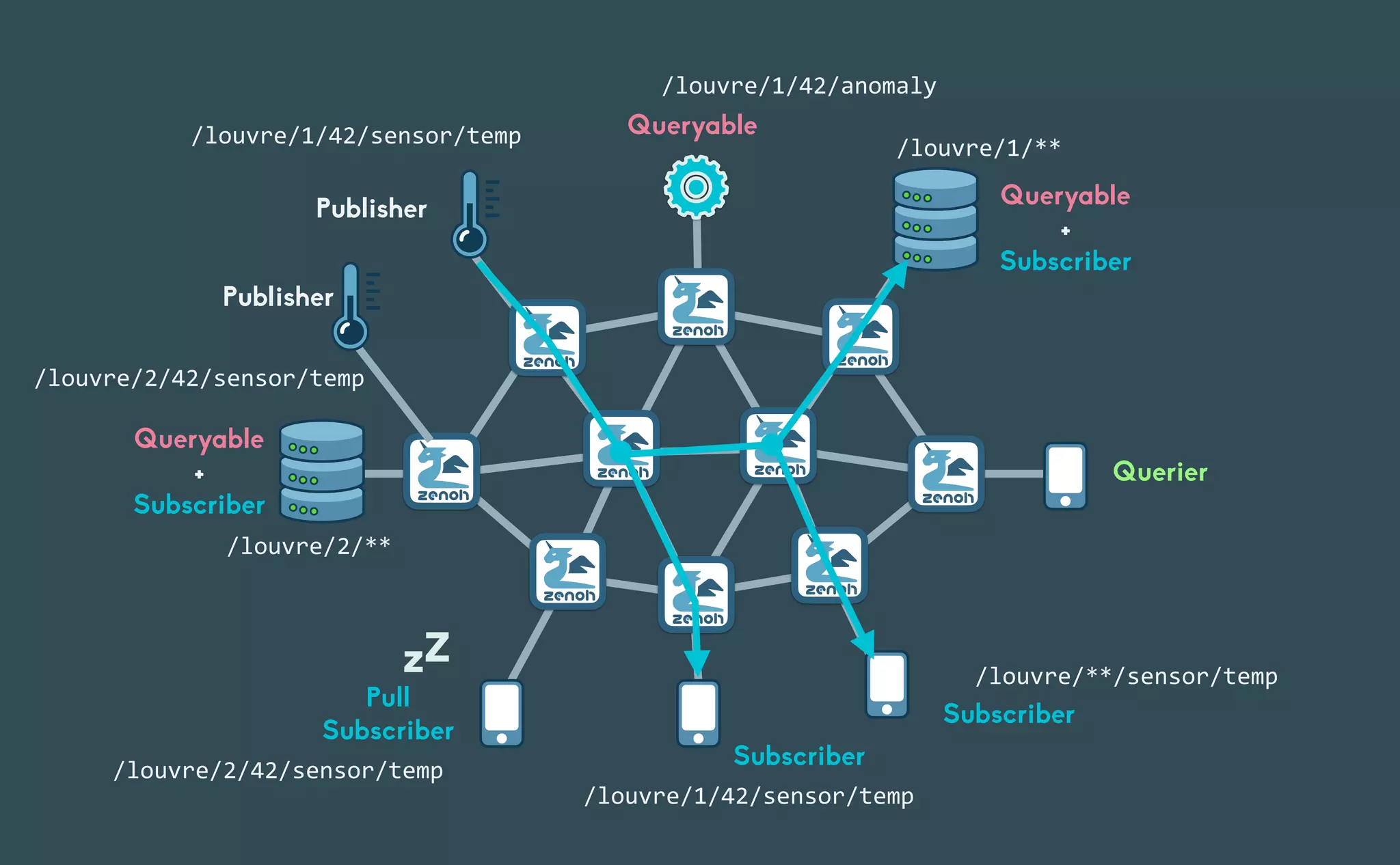
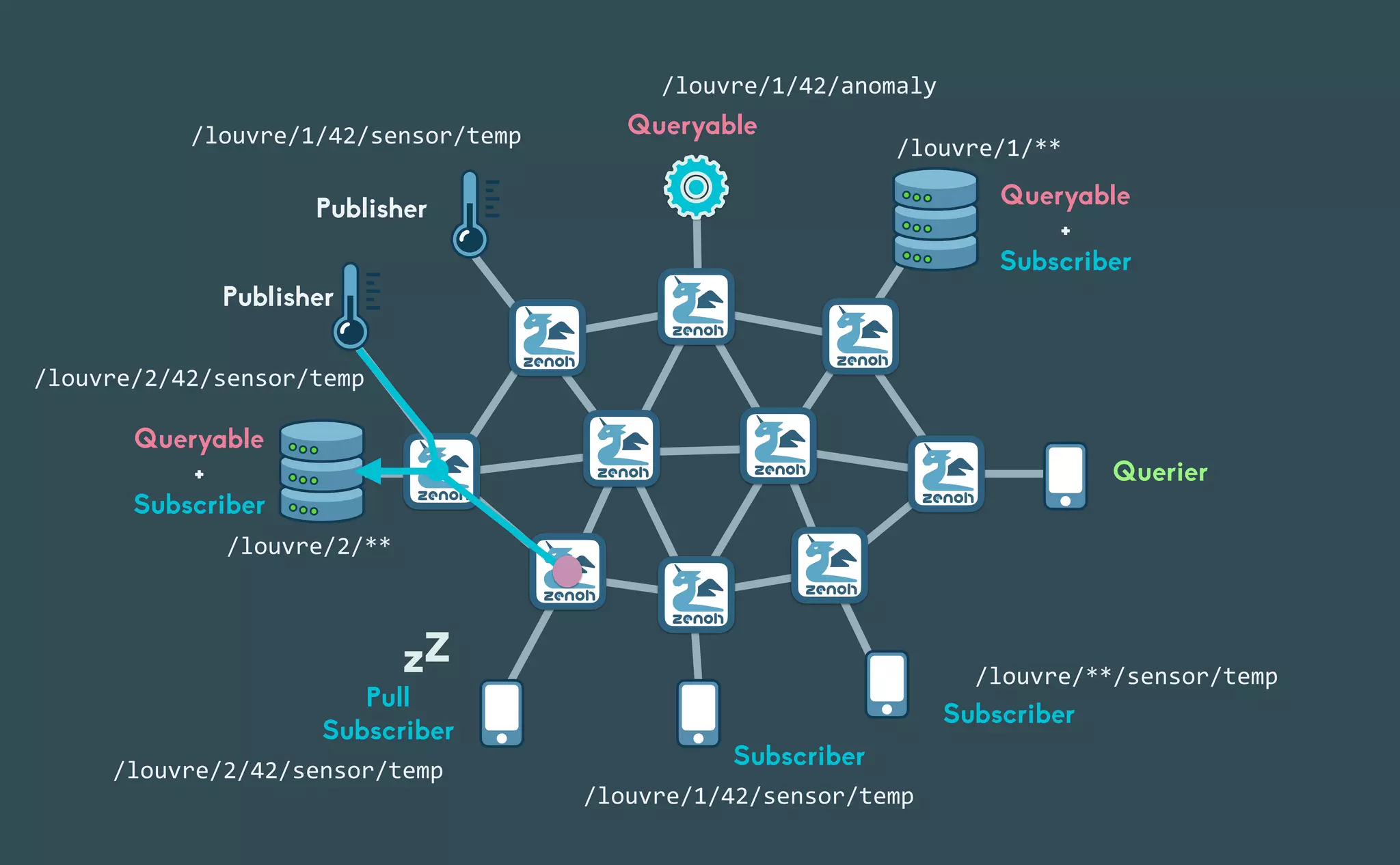
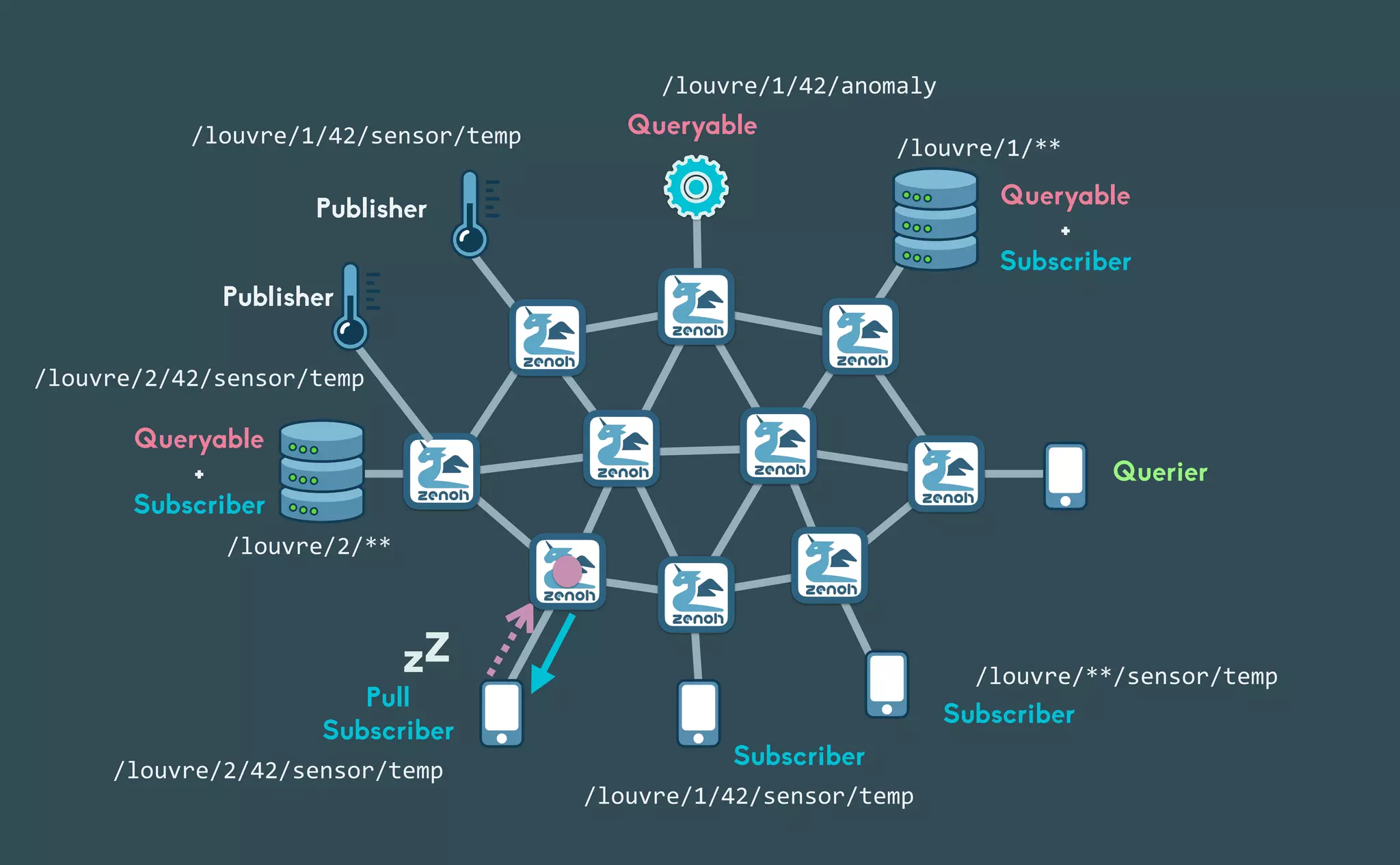
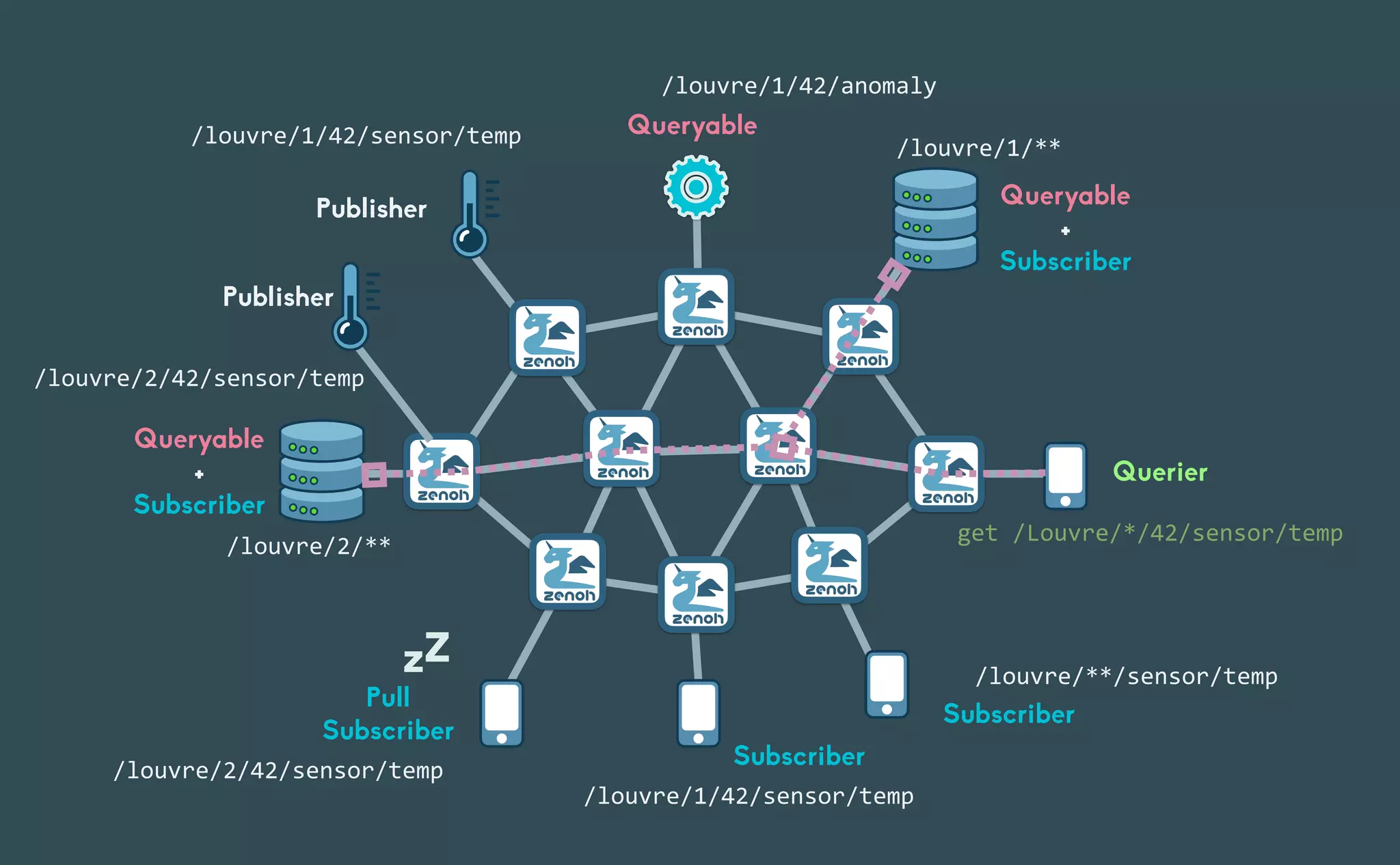



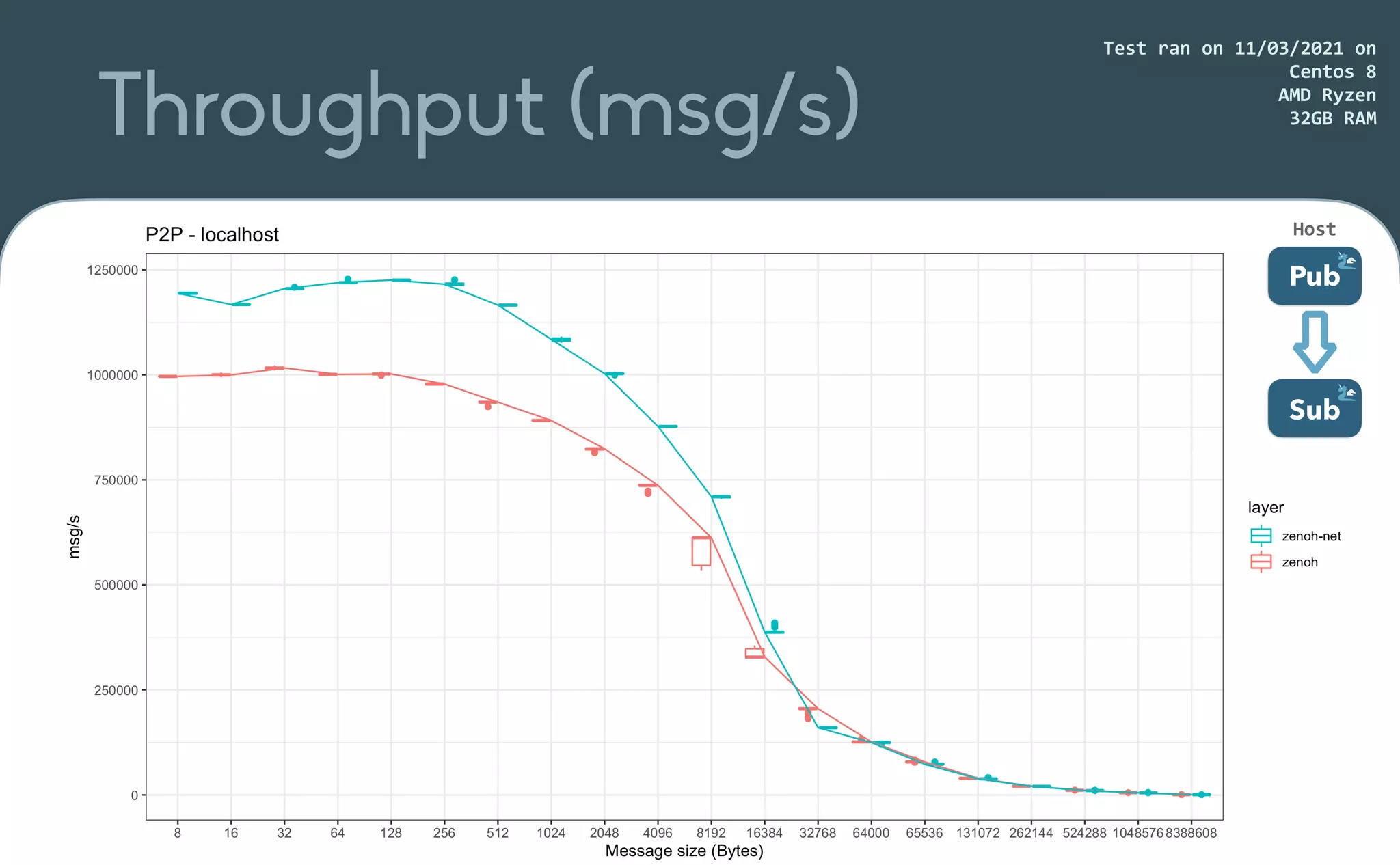
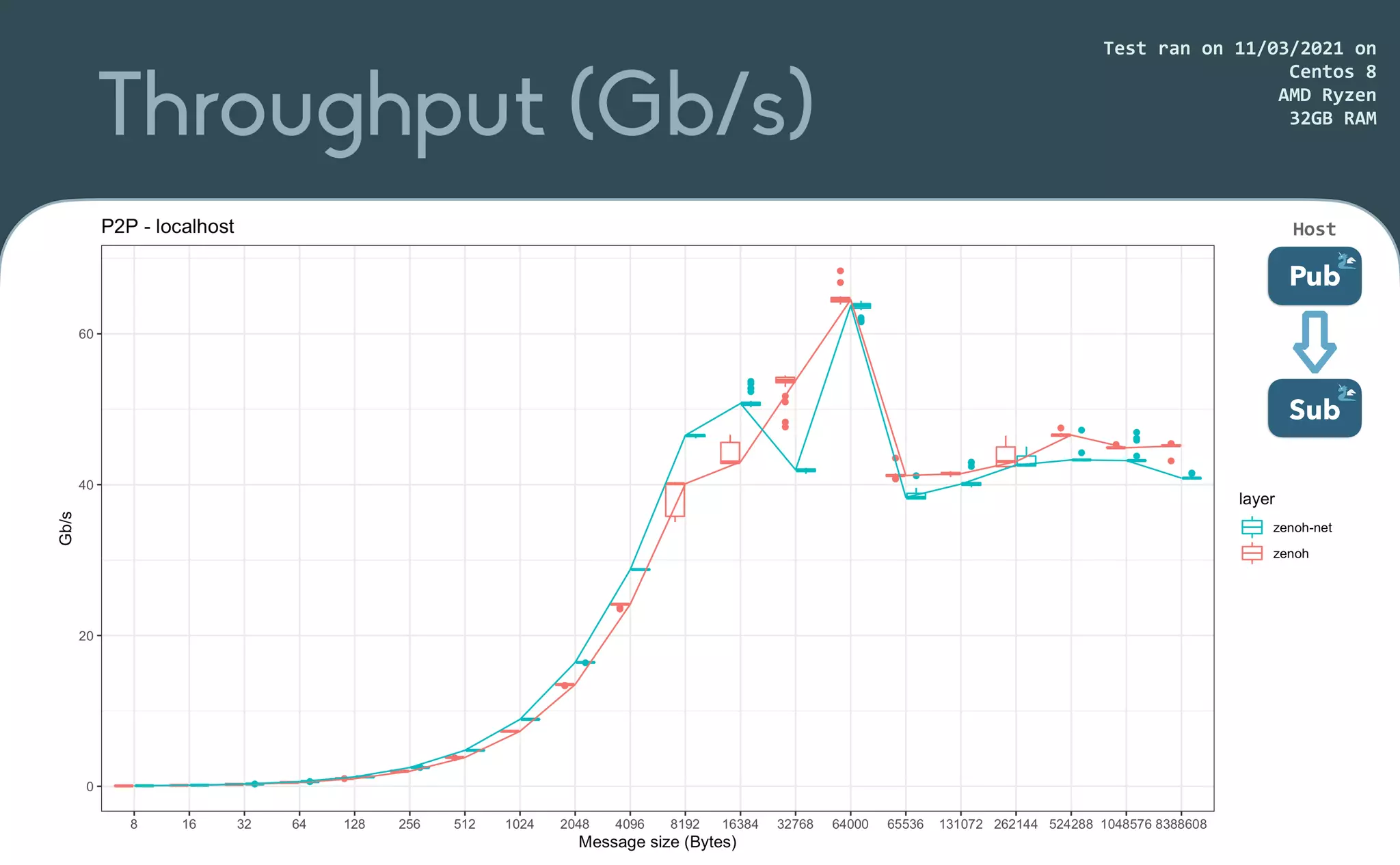

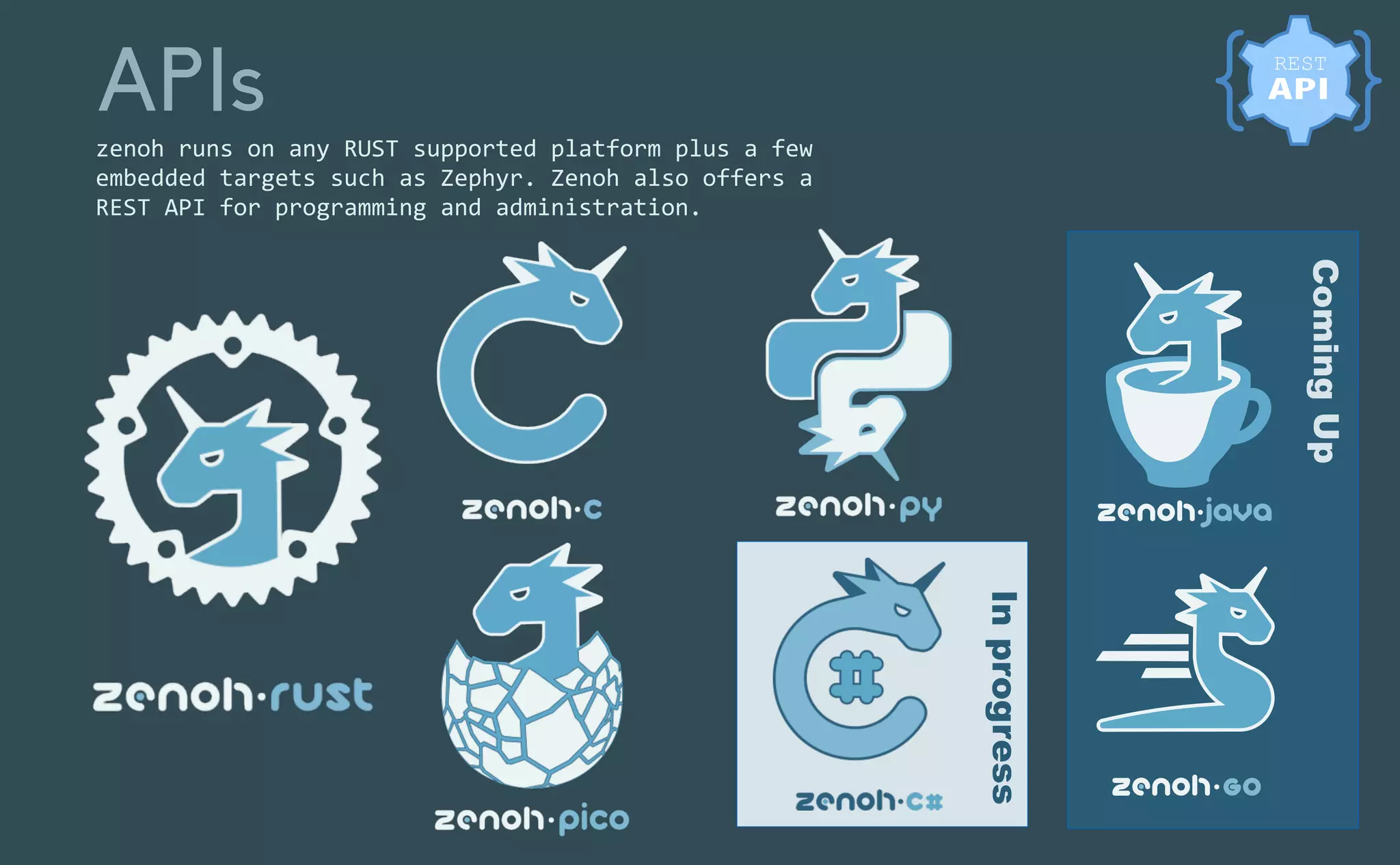
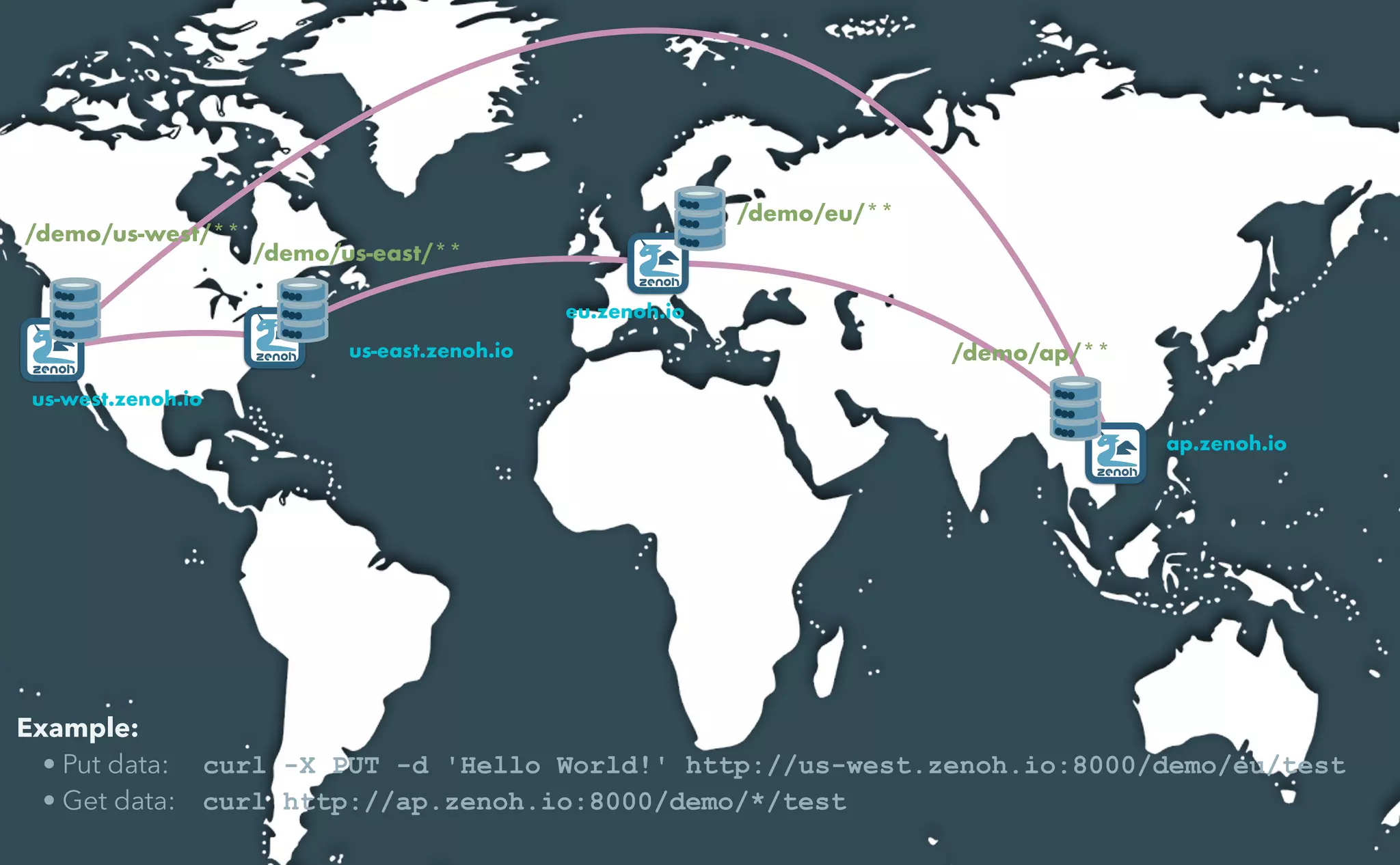

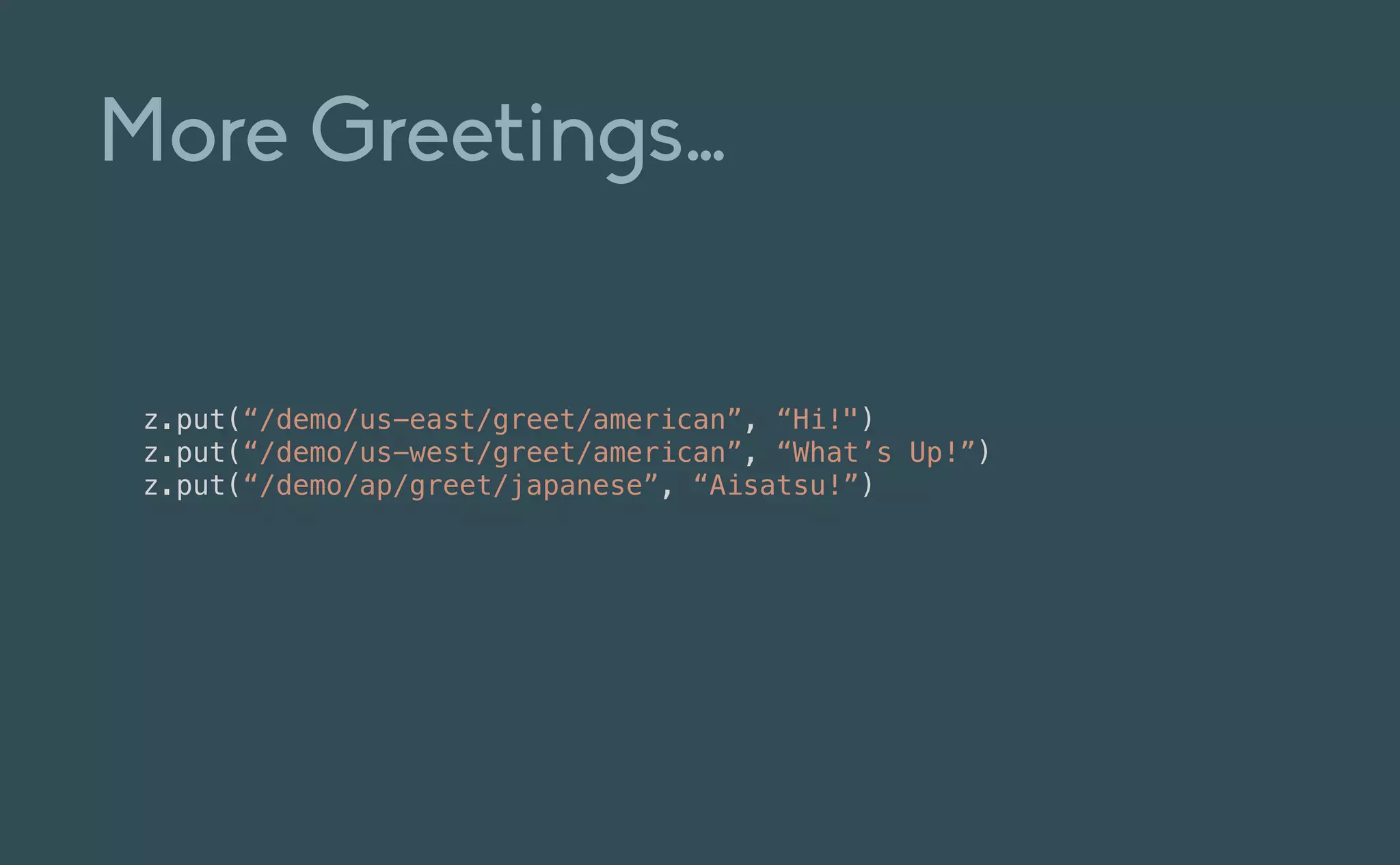
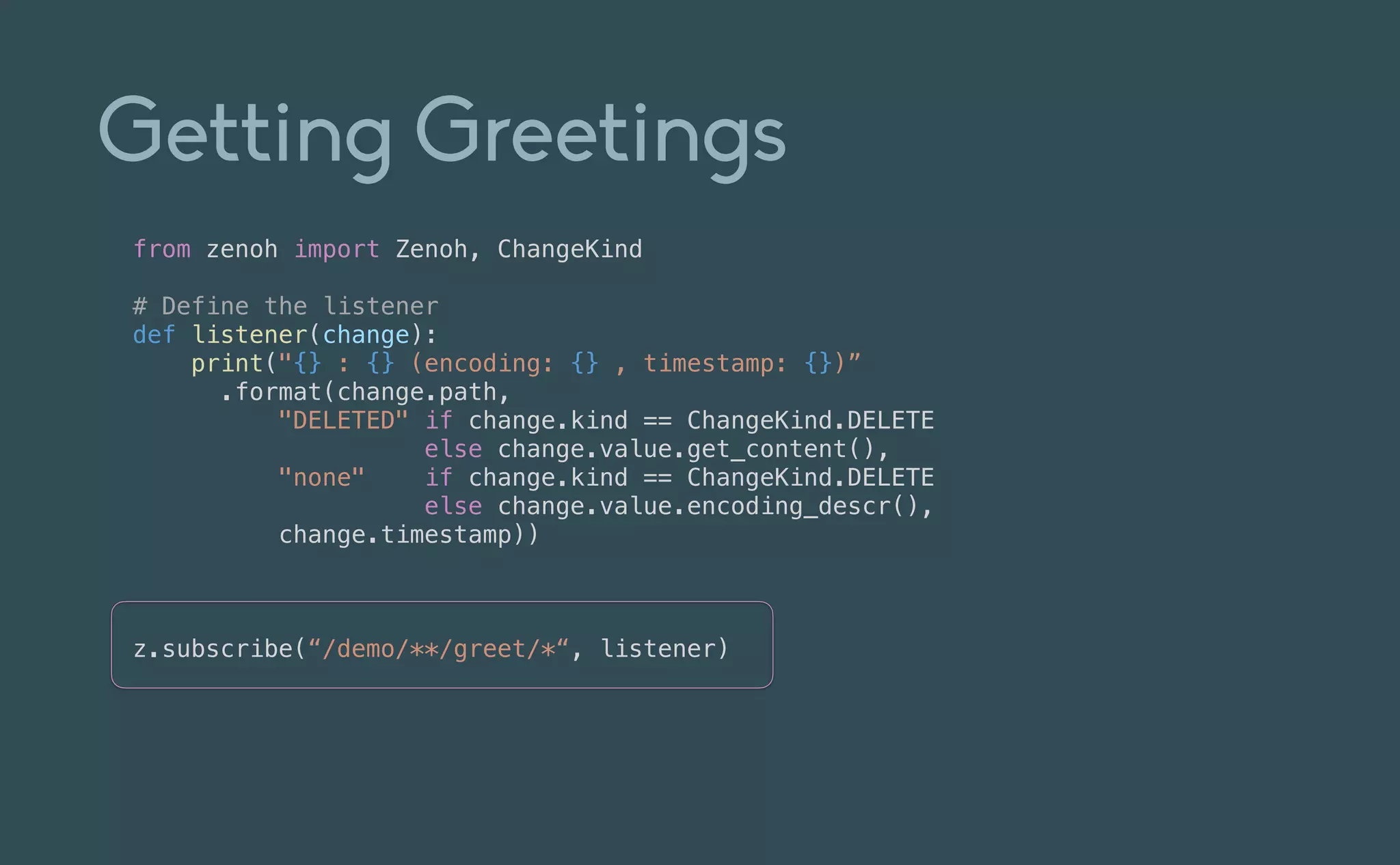

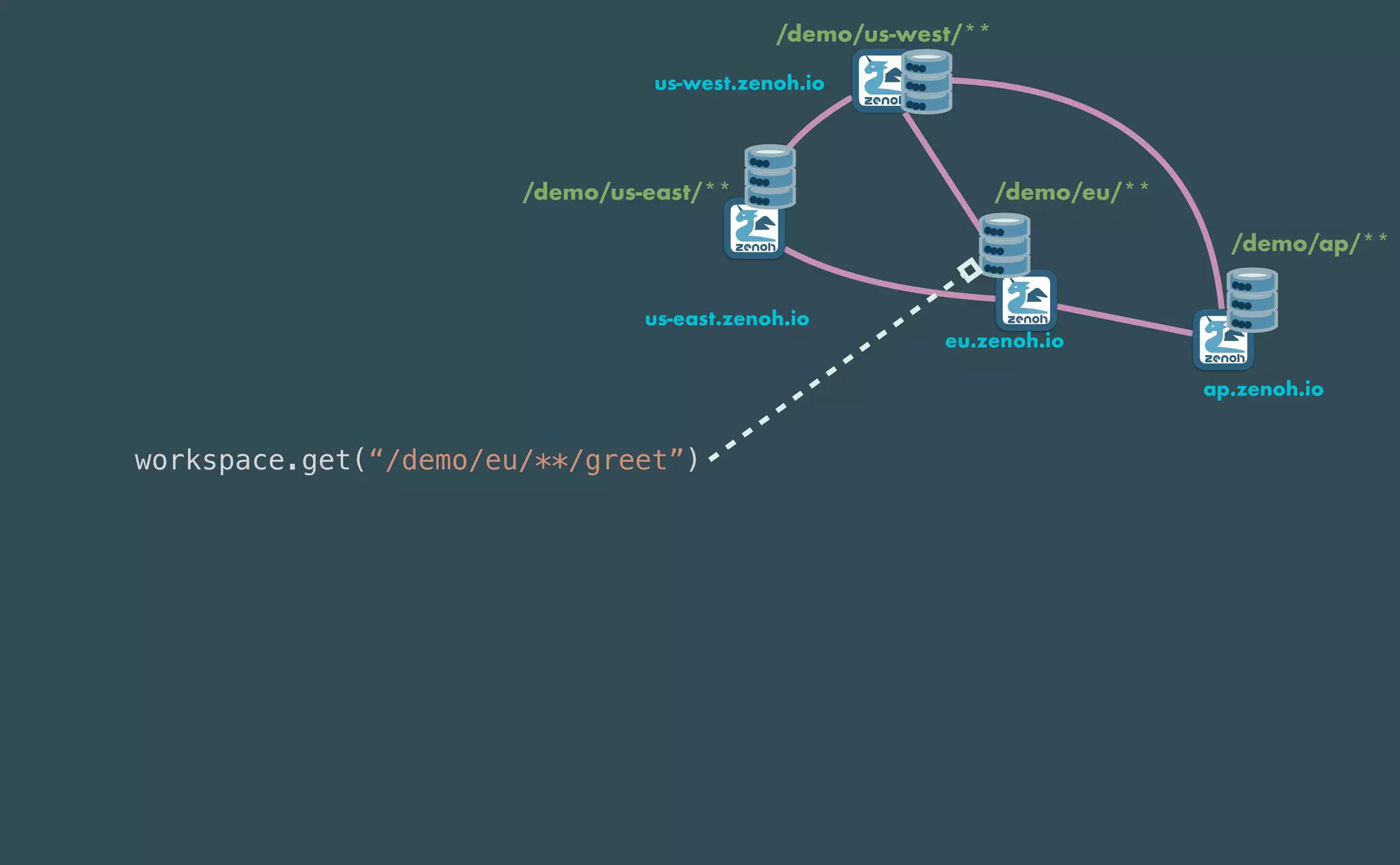
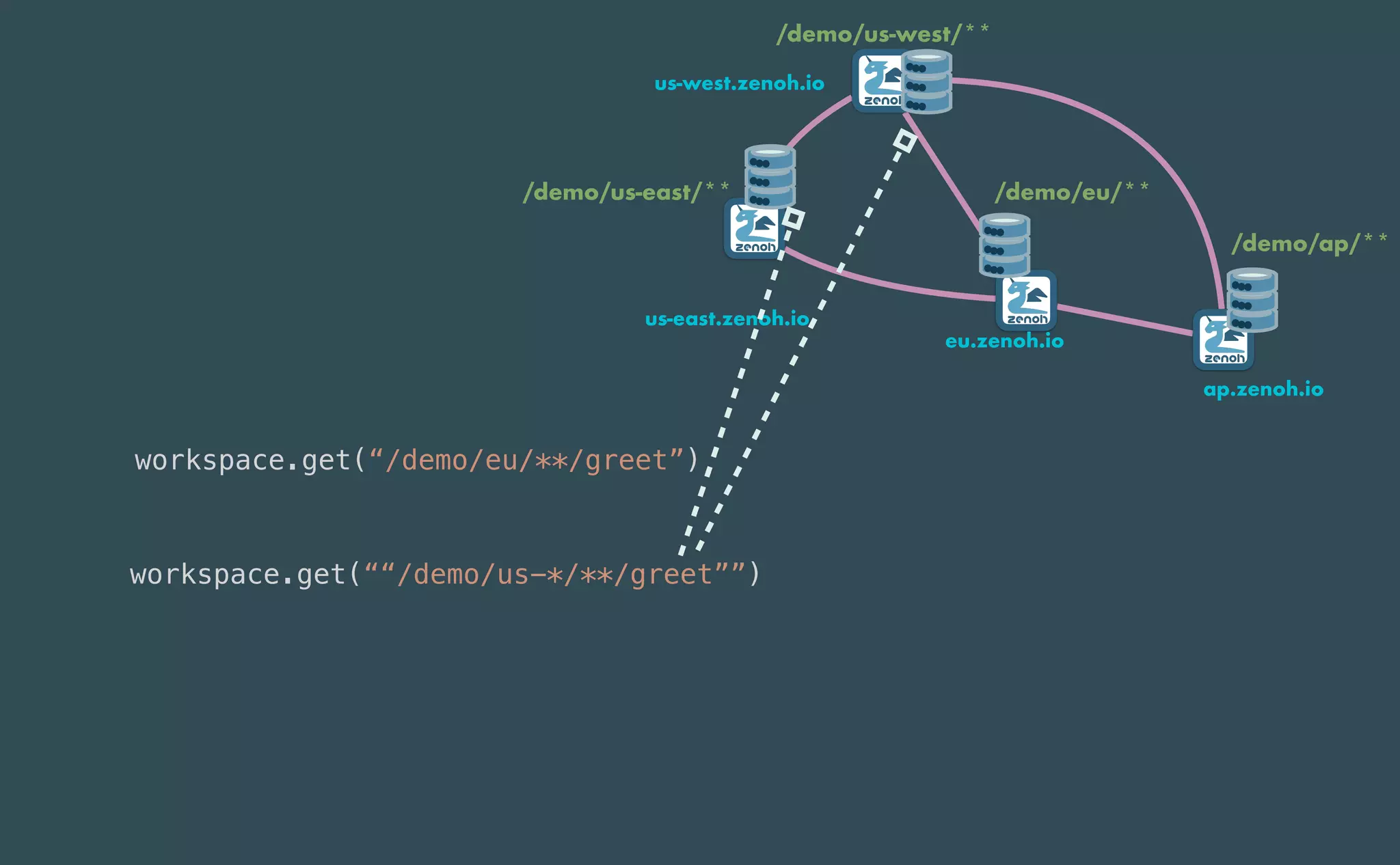
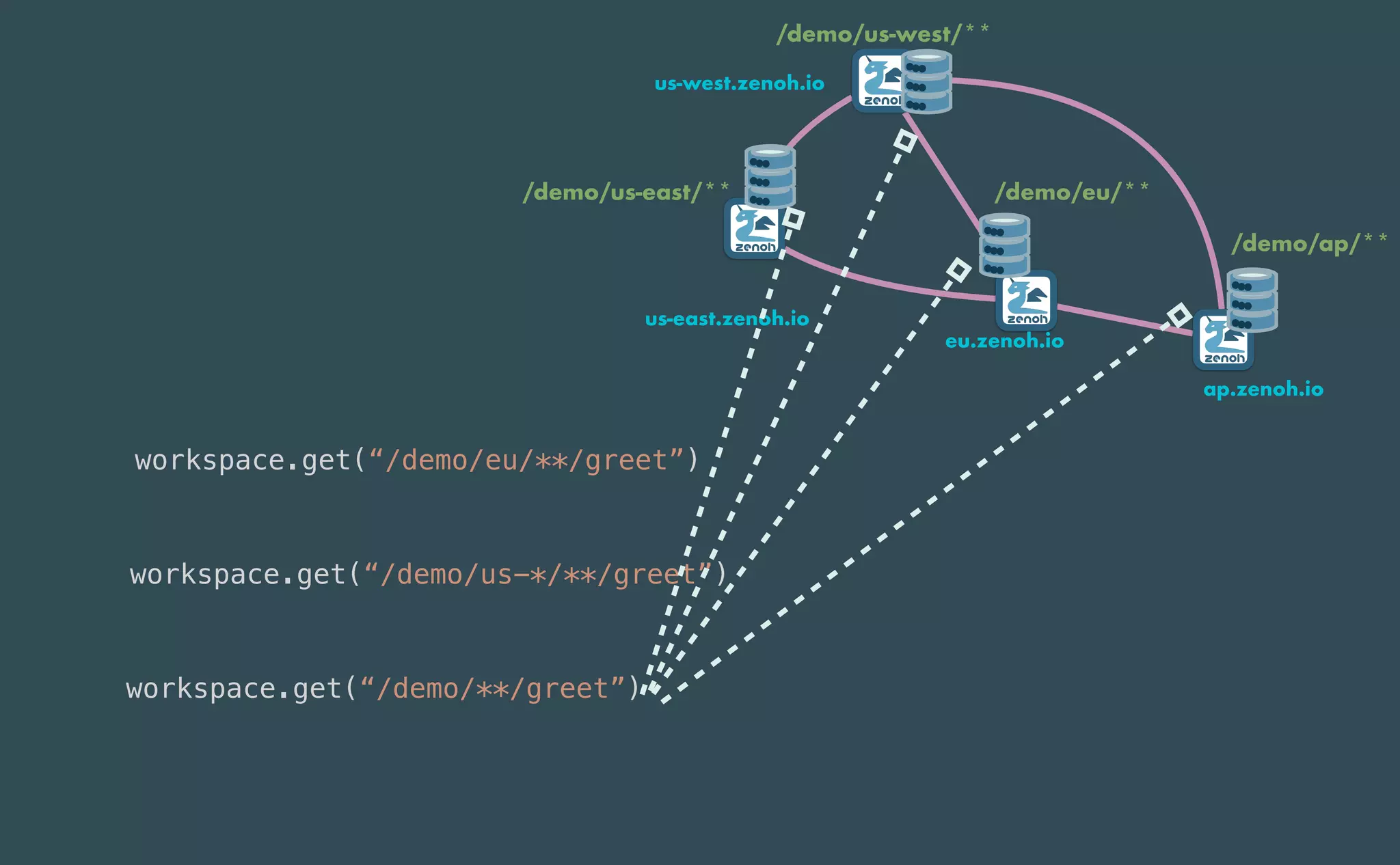

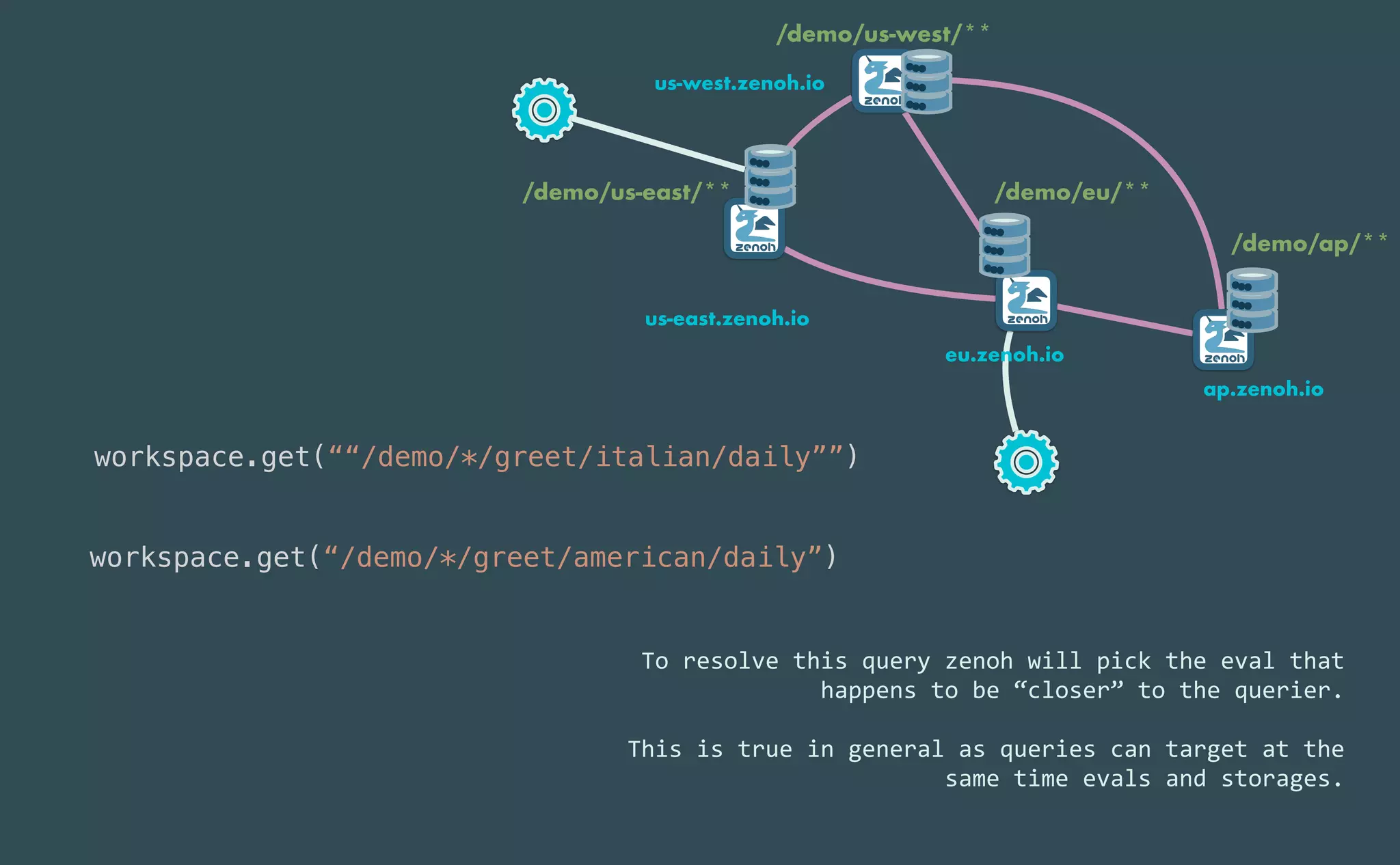












This document provides an introduction to Eclipse Zenoh, an open source project that unifies data in motion, data at rest, and computations in a distributed system. Zenoh elegantly blends traditional publish-subscribe with geo-distributed storage, queries, and computations. The presentation will demonstrate Zenoh's advantages for enabling typical edge computing scenarios and simplifying large-scale distributed applications through real-world use cases. It will also provide an overview of Zenoh's architecture, performance, and APIs.