Downloaded 13 times






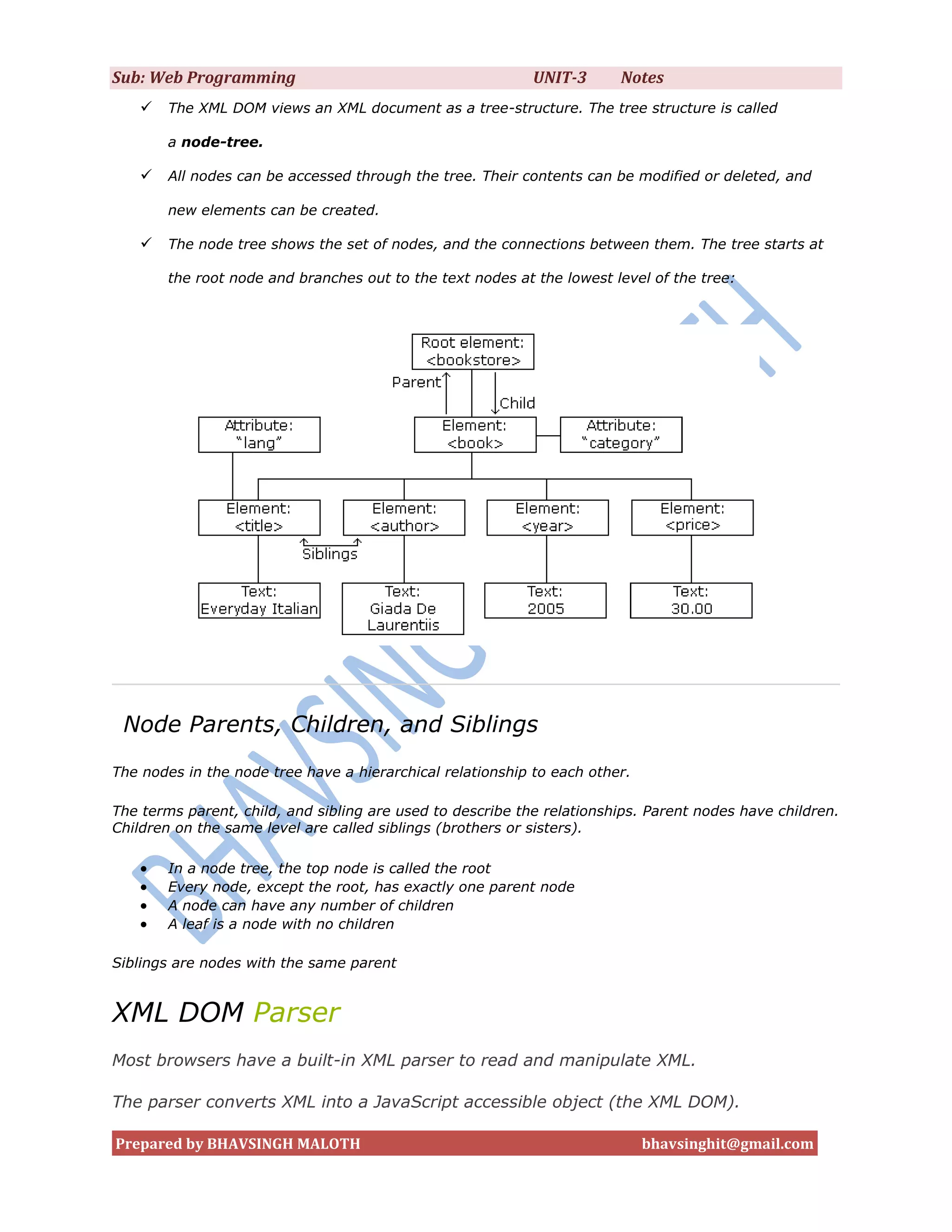
![Sub: Web Programming UNIT-3 Notes
]>
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
The DTD is interpreted like this:
!ELEMENT note (in line 2) defines the element "note" as having four elements:
"to,from,heading,body".
!ELEMENT to (in line 3) defines the "to" element to be of the type "CDATA".
!ELEMENT from (in line 4) defines the "from" element to be of the type "CDATA"
and so on.....
External DTD
This is the same XML document with an external DTD:
<?xml version="1.0"?>
<!DOCTYPE note SYSTEM "note.dtd">
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
This is a copy of the file "note.dtd" containing the Document Type Definition:
<?xml version="1.0"?>
<!ELEMENT note (to,from,heading,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
DTD - XML building blocks
The building blocks of XML documents
XML documents (and HTML documents) are made up by the following building blocks:
Elements, Tags, Attributes, Entities, PCDATA, and CDATA
This is a brief explanation of each of the building blocks:
Elements
Prepared by BHAVSINGH MALOTH bhavsinghit@gmail.com](https://image.slidesharecdn.com/wpunit-iii-121201002139-phpapp01/75/Wp-unit-III-7-2048.jpg)

















![Sub: Web Programming UNIT-3 Notes
Note: In this case the type "carType" can be used by other elements because it is not a part of the
"car" element.
Restrictions on a Series of Values
To limit the content of an XML element to define a series of numbers or letters that can be used, we
would use the pattern constraint.
The example below defines an element called "letter" with a restriction. The only acceptable value is
ONE of the LOWERCASE letters from a to z:
<xs:element name="letter">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:pattern value="[a-z]"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
Restrictions on Length
To limit the length of a value in an element, we would use the length, maxLength, and minLength
constraints.
This example defines an element called "password" with a restriction. The value must be exactly eight
characters:
<xs:element name="password">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:length value="8"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
This example defines another element called "password" with a restriction. The value must be
minimum five characters and maximum eight characters:
<xs:element name="password">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:minLength value="5"/>
<xs:maxLength value="8"/>
</xs:restriction>
Prepared by BHAVSINGH MALOTH bhavsinghit@gmail.com](https://image.slidesharecdn.com/wpunit-iii-121201002139-phpapp01/75/Wp-unit-III-25-2048.jpg)















![Sub: Web Programming UNIT-3 Notes
txt=xmlDoc.getElementsByTagName("title")[0].childNodes[0].nodeValue
After the execution of the statement, txt will hold the value "Everyday Italian"
Explained:
xmlDoc - the XML DOM object created by the parser.
getElementsByTagName("title")[0] - the first <title> element
childNodes[0] - the first child of the <title> element (the text node)
nodeValue - the value of the node (the text itself)
XML DOM - Accessing Nodes
With the DOM, you can access every node in an XML document.
Accessing Nodes
You can access a node in three ways:
1. By using the getElementsByTagName() method
2. By looping through (traversing) the nodes tree.
3. By navigating the node tree, using the node relationships.
The getElementsByTagName() Method
getElementsByTagName() returns all elements with a specified tag name.
Syntax
node.getElementsByTagName("tagname");
Example
The following example returns all <title> elements under the x element:
x.getElementsByTagName("title");
Note that the example above only returns <title> elements under the x node. To return all <title>
elements in the XML document use:
xmlDoc.getElementsByTagName("title");
where xmlDoc is the document itself (document node).
Prepared by BHAVSINGH MALOTH bhavsinghit@gmail.com](https://image.slidesharecdn.com/wpunit-iii-121201002139-phpapp01/75/Wp-unit-III-42-2048.jpg)
![Sub: Web Programming UNIT-3 Notes
DOM Node List
The getElementsByTagName() method returns a node list. A node list is an array of nodes.
The following code loads "books.xml" into xmlDoc using loadXMLDoc() and stores a list of <title>
nodes (a node list) in the variable x:
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("title");
The <title> elements in x can be accessed by index number. To access the third <title> you can
write::
y=x[2];
Note: The index starts at 0.
Node Types
The documentElement property of the XML document is the root node.
The nodeName property of a node is the name of the node.
The nodeType property of a node is the type of the node.
Node Properties
In the XML DOM, each node is an object.
Objects have methods and properties, that can be accessed and manipulated by JavaScript.
Three important node properties are:
nodeName
nodeValue
nodeType
The nodeName Property
The nodeName property specifies the name of a node.
nodeName is read-only
nodeName of an element node is the same as the tag name
nodeName of an attribute node is the attribute name
nodeName of a text node is always #text
nodeName of the document node is always #document
Prepared by BHAVSINGH MALOTH bhavsinghit@gmail.com](https://image.slidesharecdn.com/wpunit-iii-121201002139-phpapp01/75/Wp-unit-III-43-2048.jpg)






The document provides comprehensive notes on XML, detailing its purpose, syntax, and comparison with HTML. It explains key concepts such as Document Type Definition (DTD), well-formed and valid XML documents, and the use of attributes within XML. The notes also emphasize the structure and rules for creating XML elements and DTDs, along with practical examples.




















































































