Download as PDF, PPTX











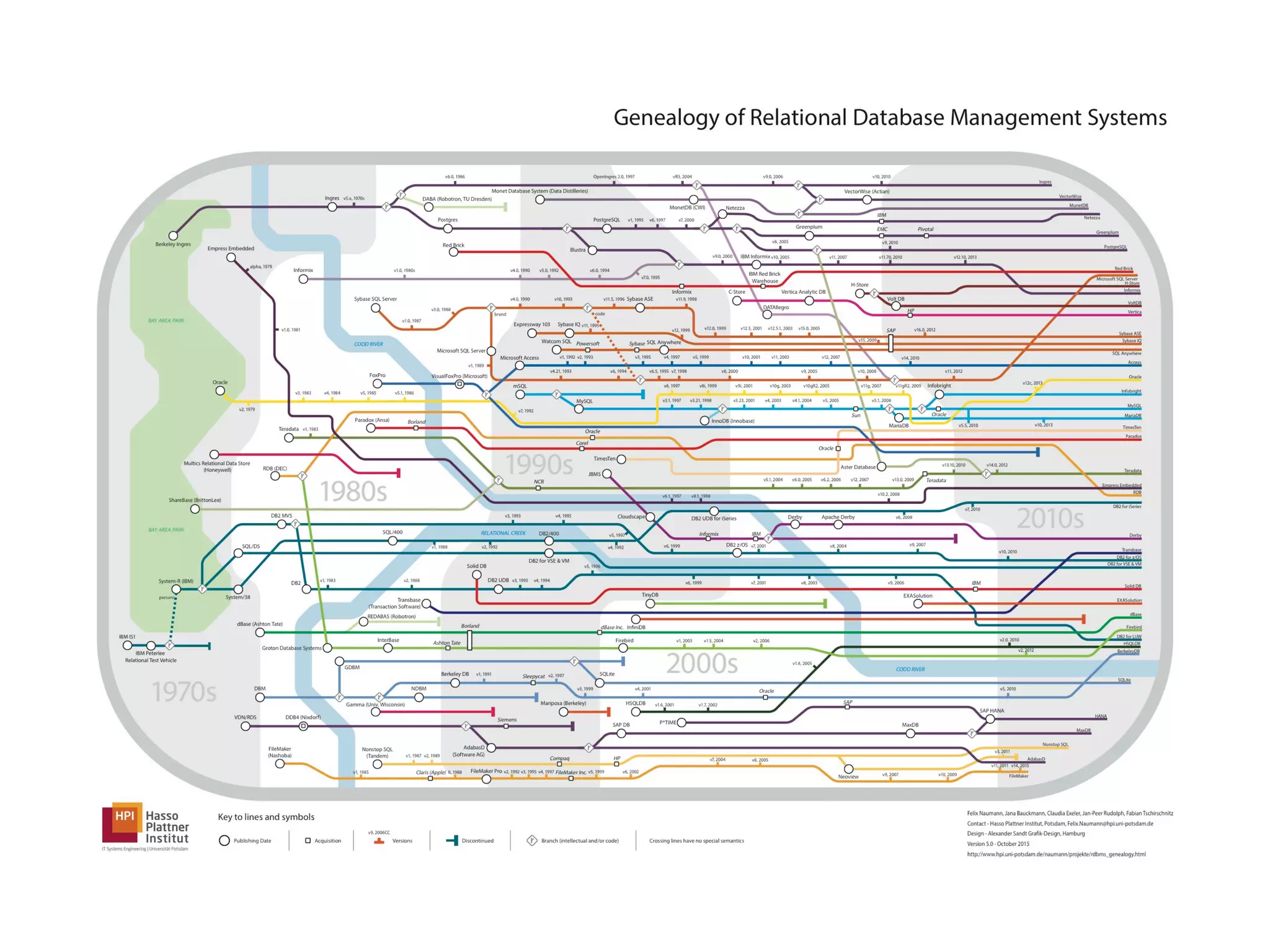
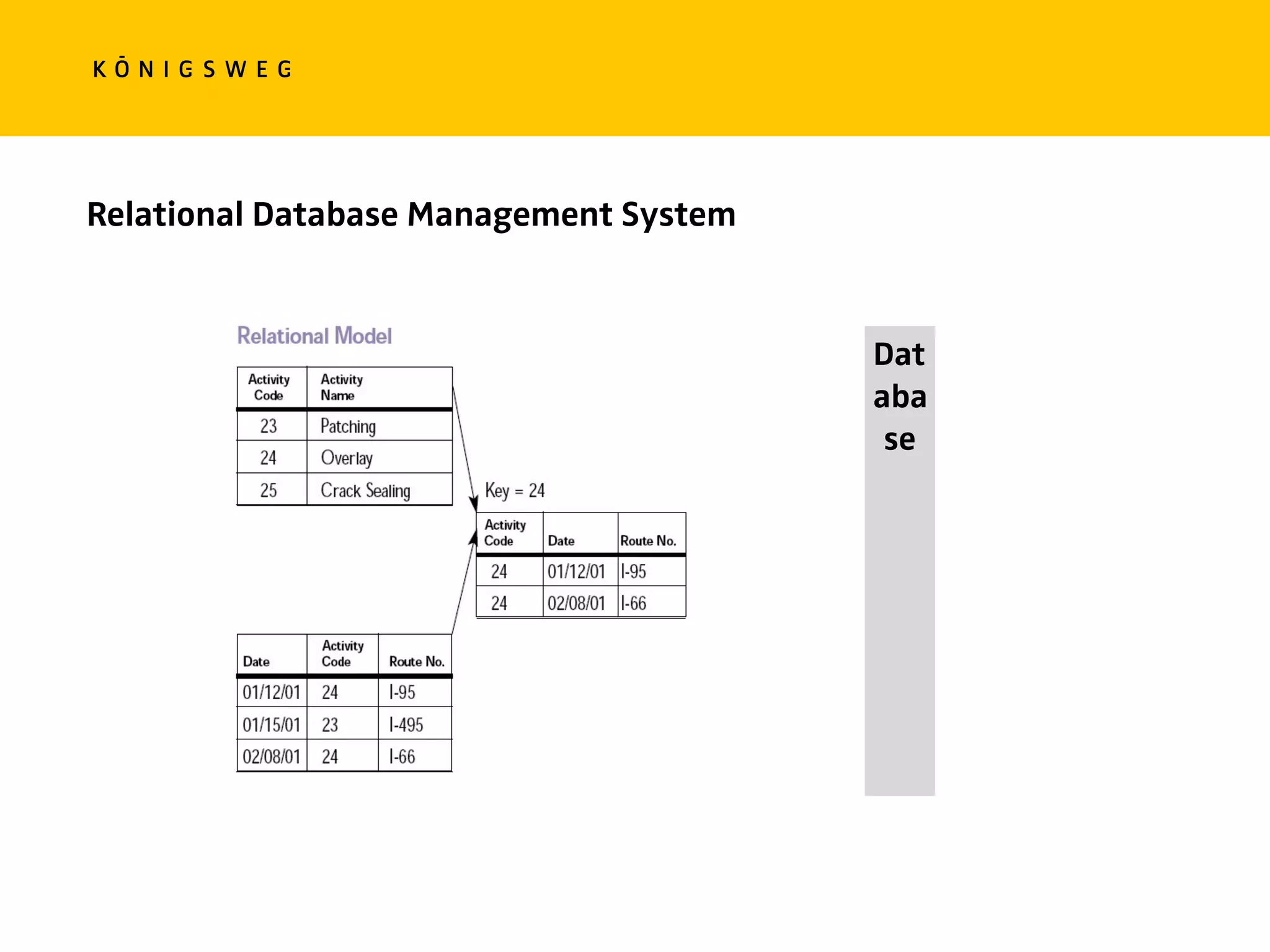
![Relational Databases
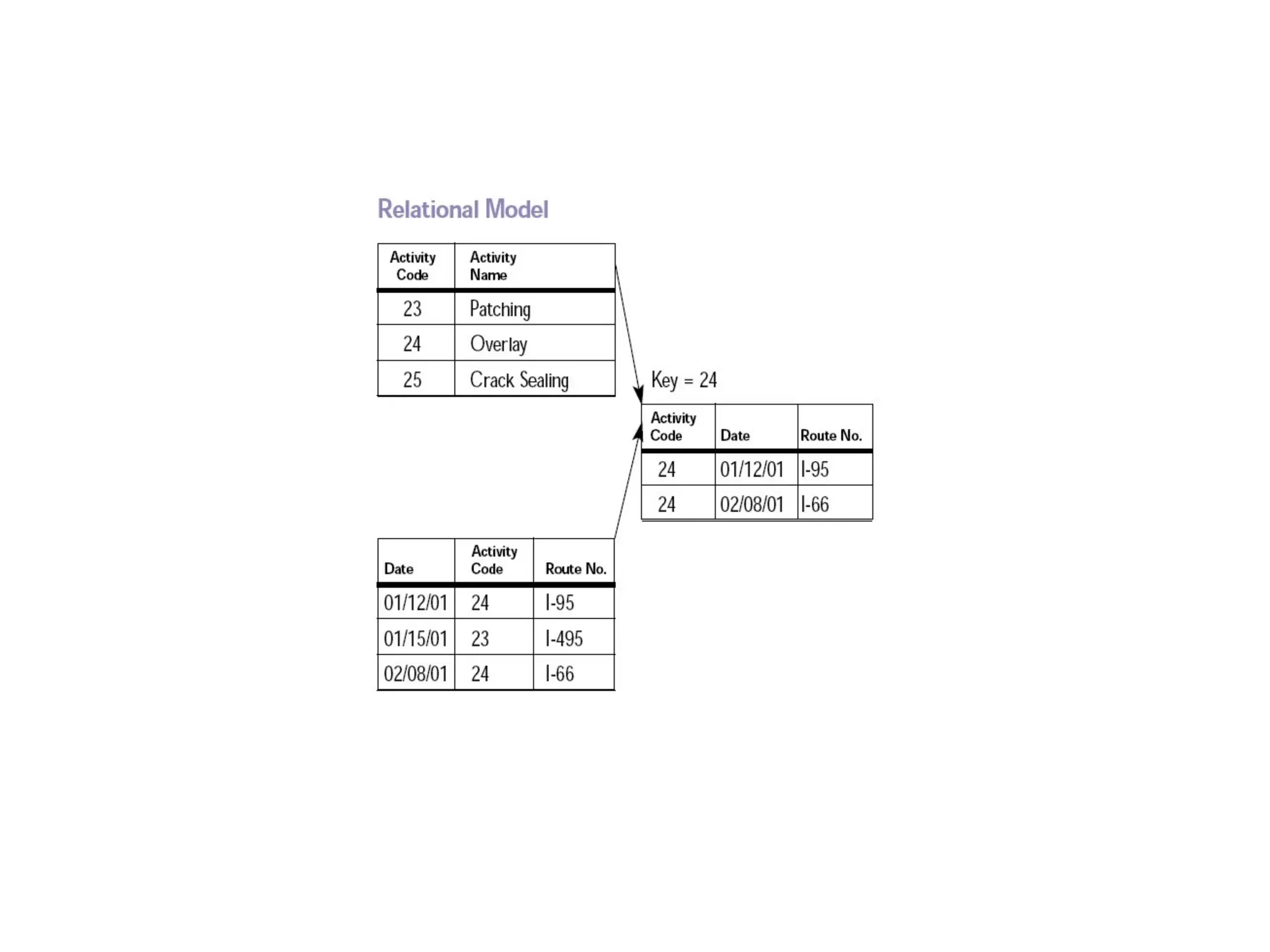
− Records are organised into tables
− Rows of these table are identified by unique keys
− Data spans multiple tables, linked via ids
− Data is ideally normalised
− Data can be denormalized for performance
− Transactions are ACID [Atomic, Consistent , Isolated, Durable]](https://image.slidesharecdn.com/pycon-nove-databases-for-data-science-180421160121/75/Databases-for-Data-Science-16-2048.jpg)









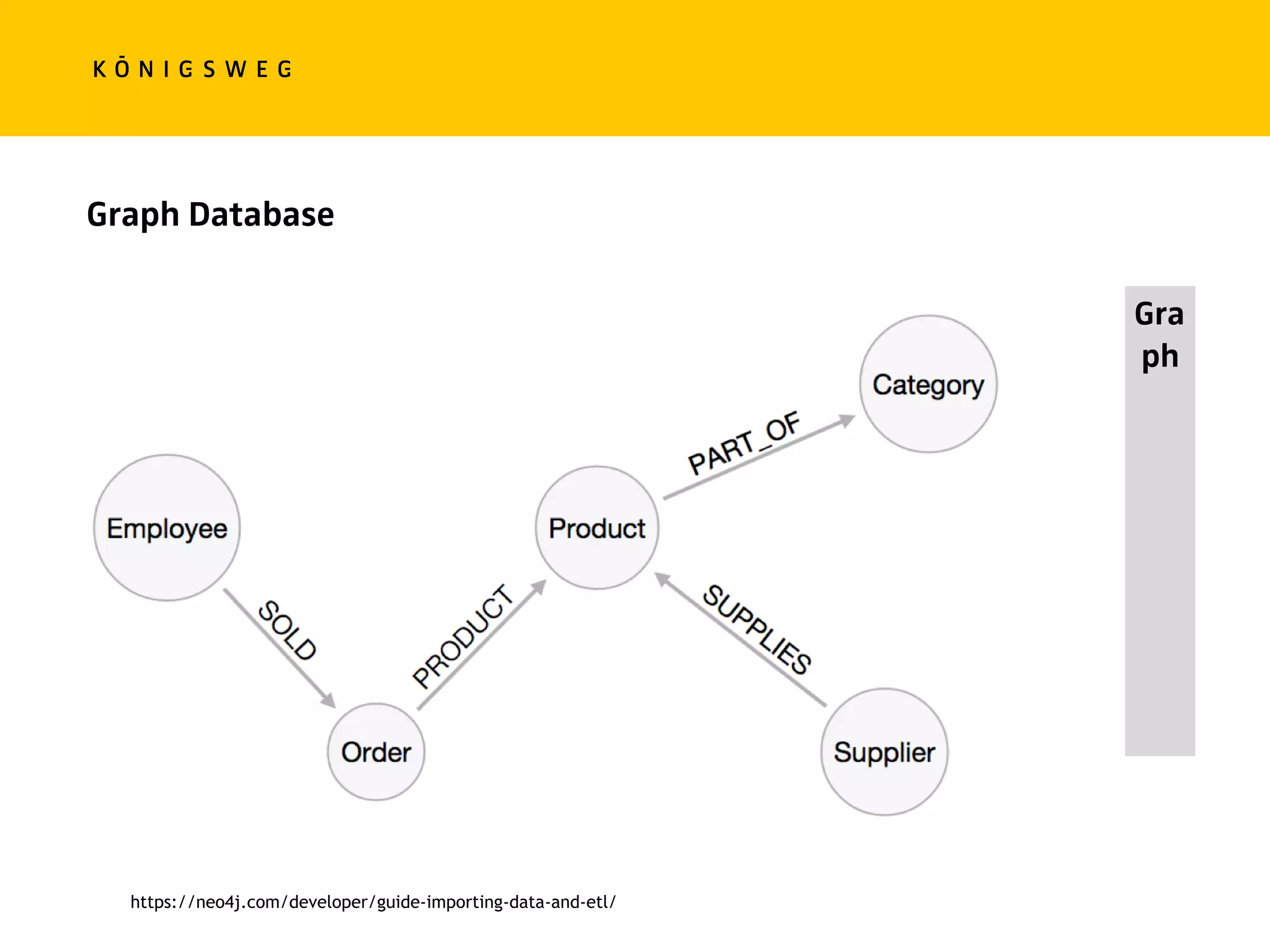




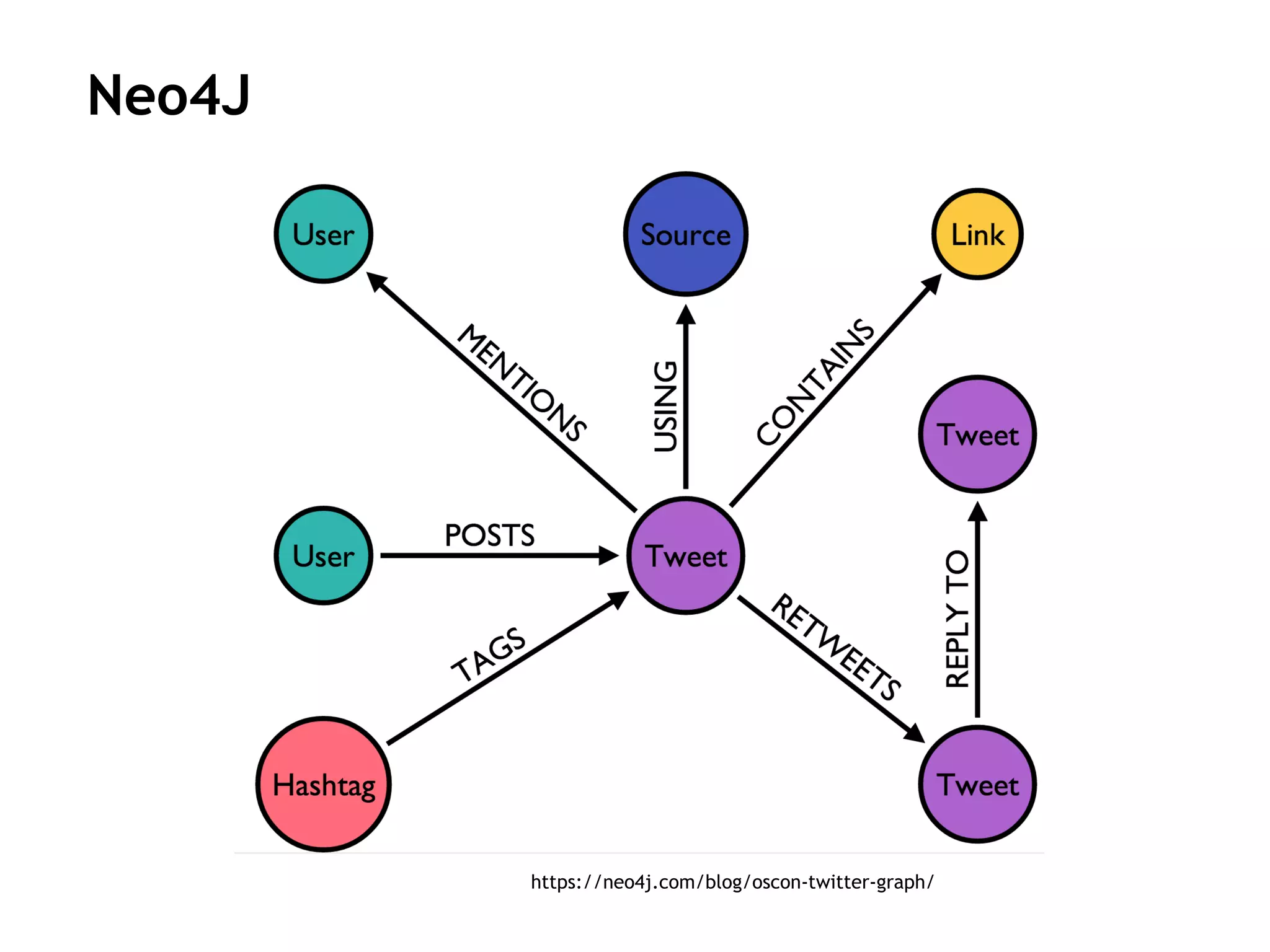
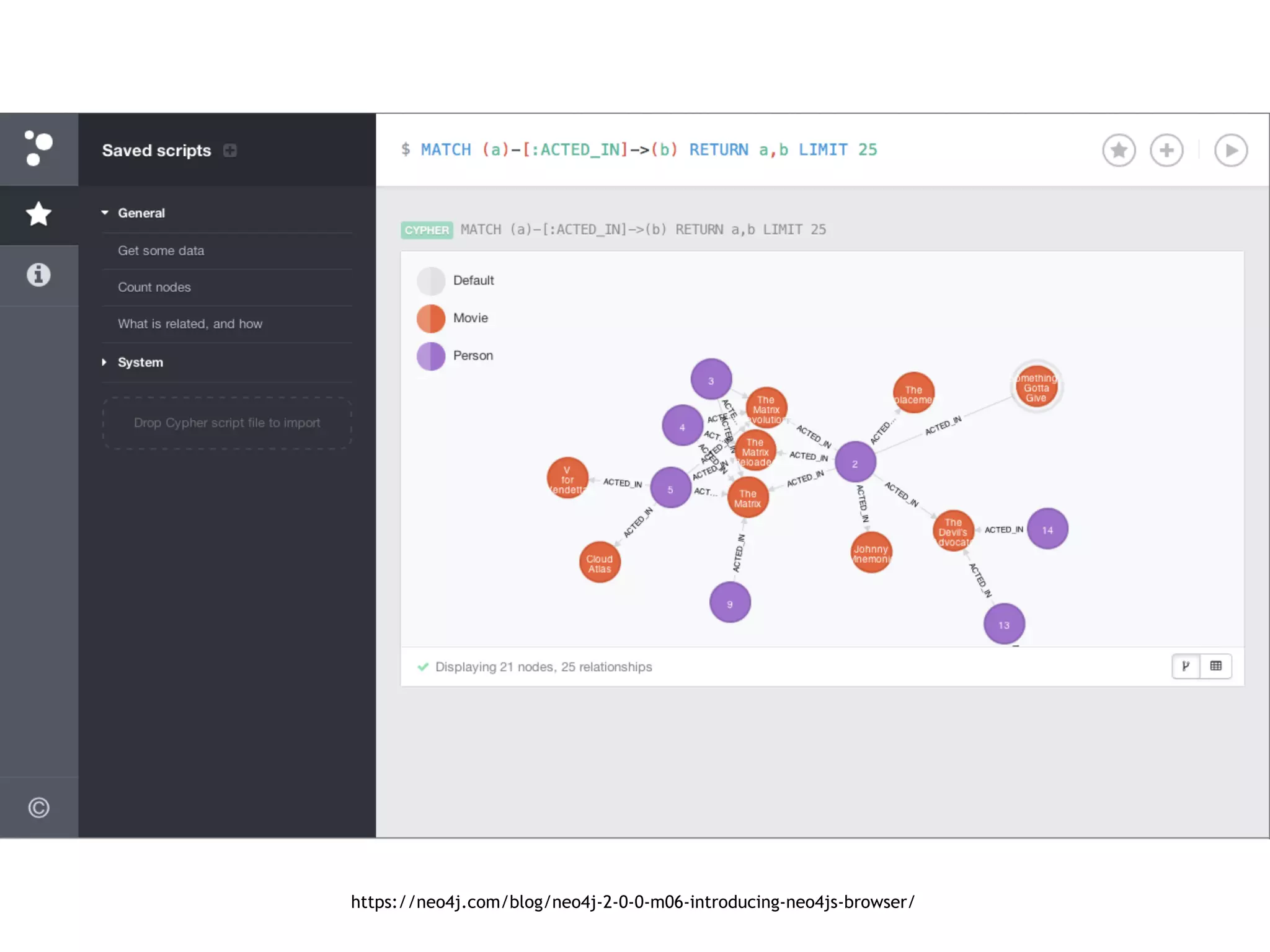
![MATCH (c:Customer {companyName:"Drachenblut Delikatessen"})
OPTIONAL MATCH (p:Product)<-[pu:PRODUCT]-(:Order)<-[:PURCHASED]-(c)
RETURN p.productName, toInt(sum(pu.unitPrice * pu.quantity)) AS volume
ORDER BY volume DESC;
Neo4J](https://image.slidesharecdn.com/pycon-nove-databases-for-data-science-180421160121/75/Databases-for-Data-Science-47-2048.jpg)
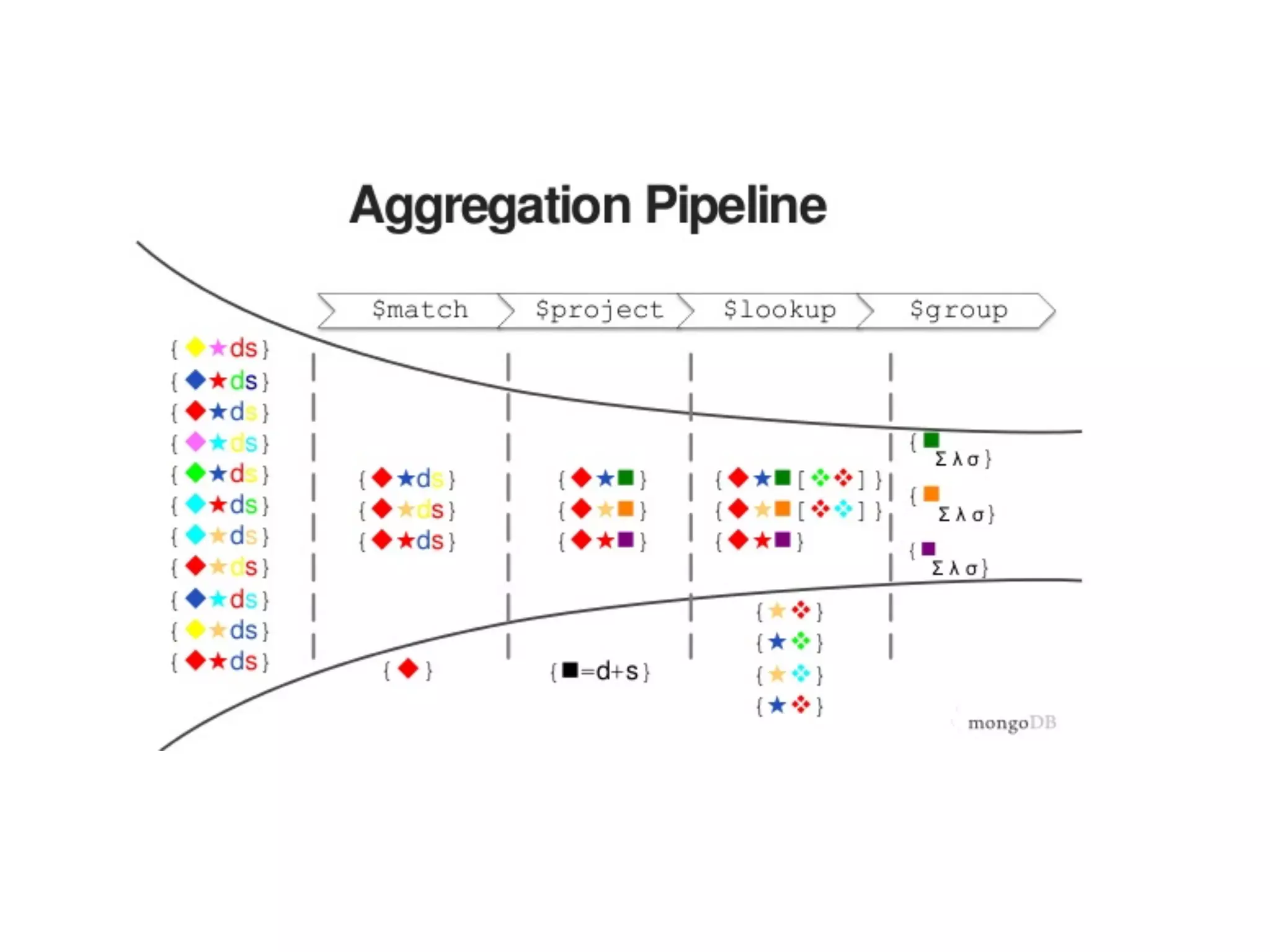
![pipeline = [
{"$match": {"artistName": “Suppenstar"}},
{"$sort": {„info.releaseDate: 1)])},
{"$group": {
"_id": {"$year": "$info.releaseDateEpoch"},
"count": {"$sum": "1}}},
{"$project": {"year": "$_id.year", "count": 1}}},
]
MongoDB Aggregation Pipeline](https://image.slidesharecdn.com/pycon-nove-databases-for-data-science-180421160121/75/Databases-for-Data-Science-48-2048.jpg)

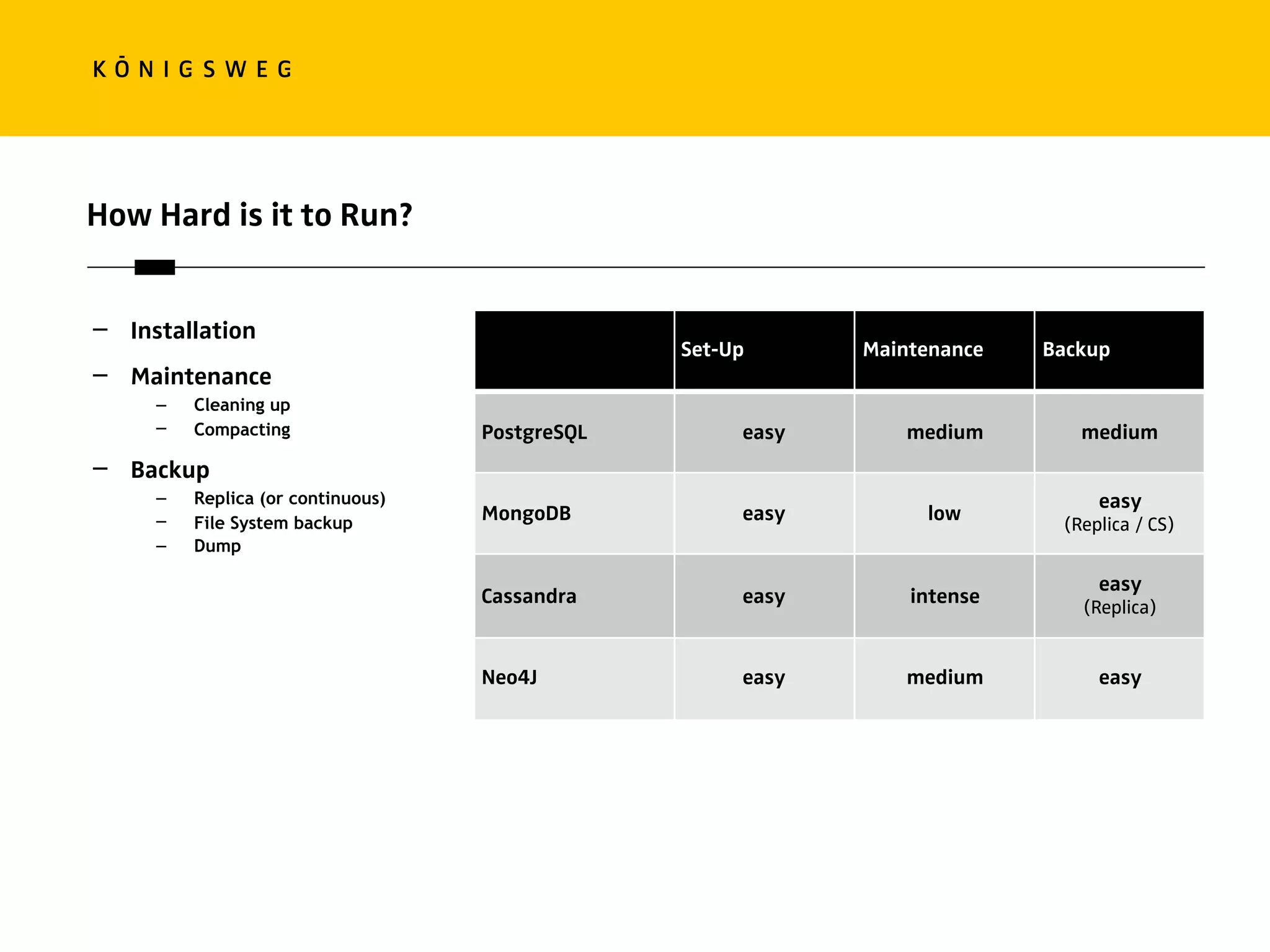
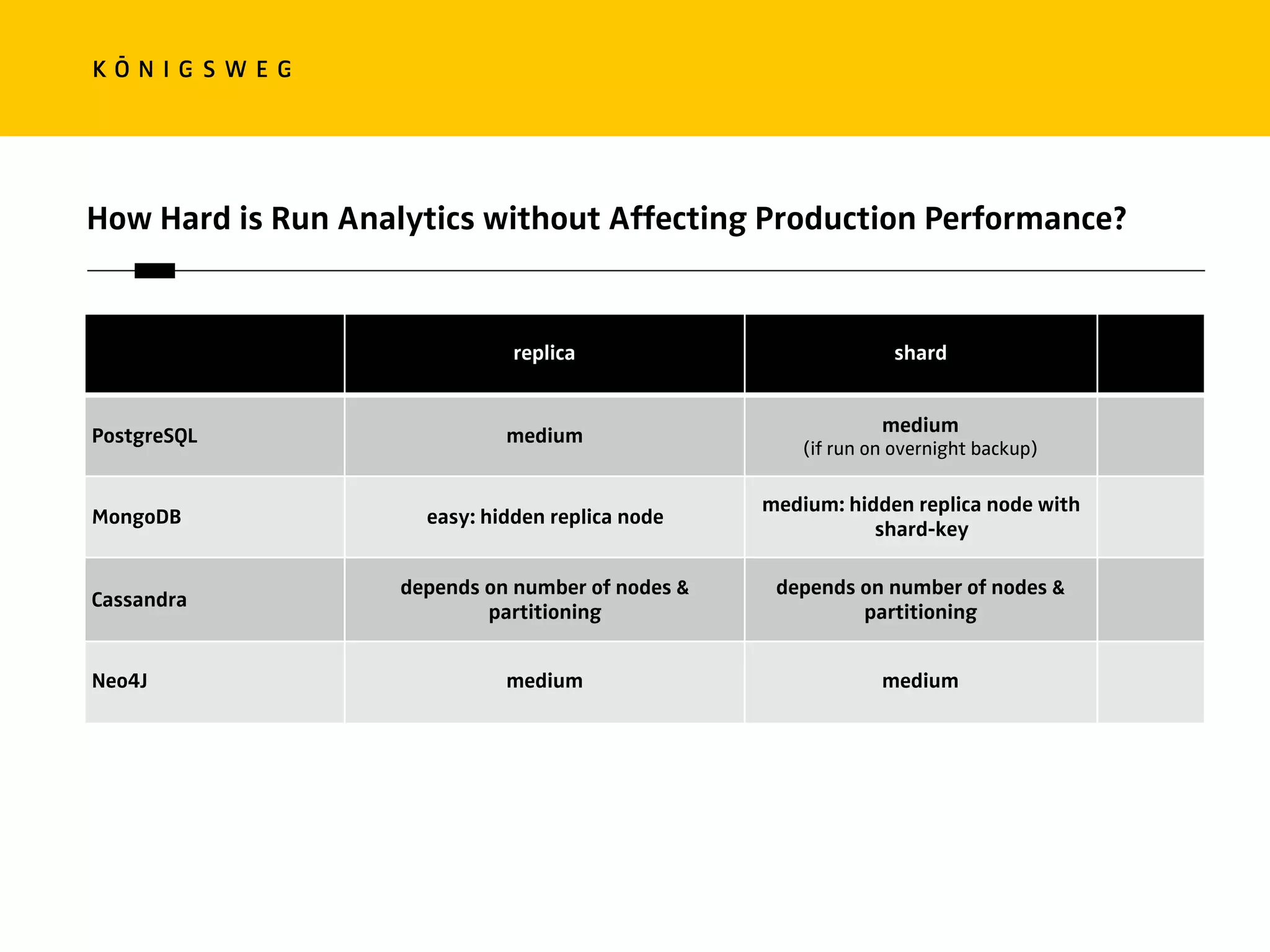
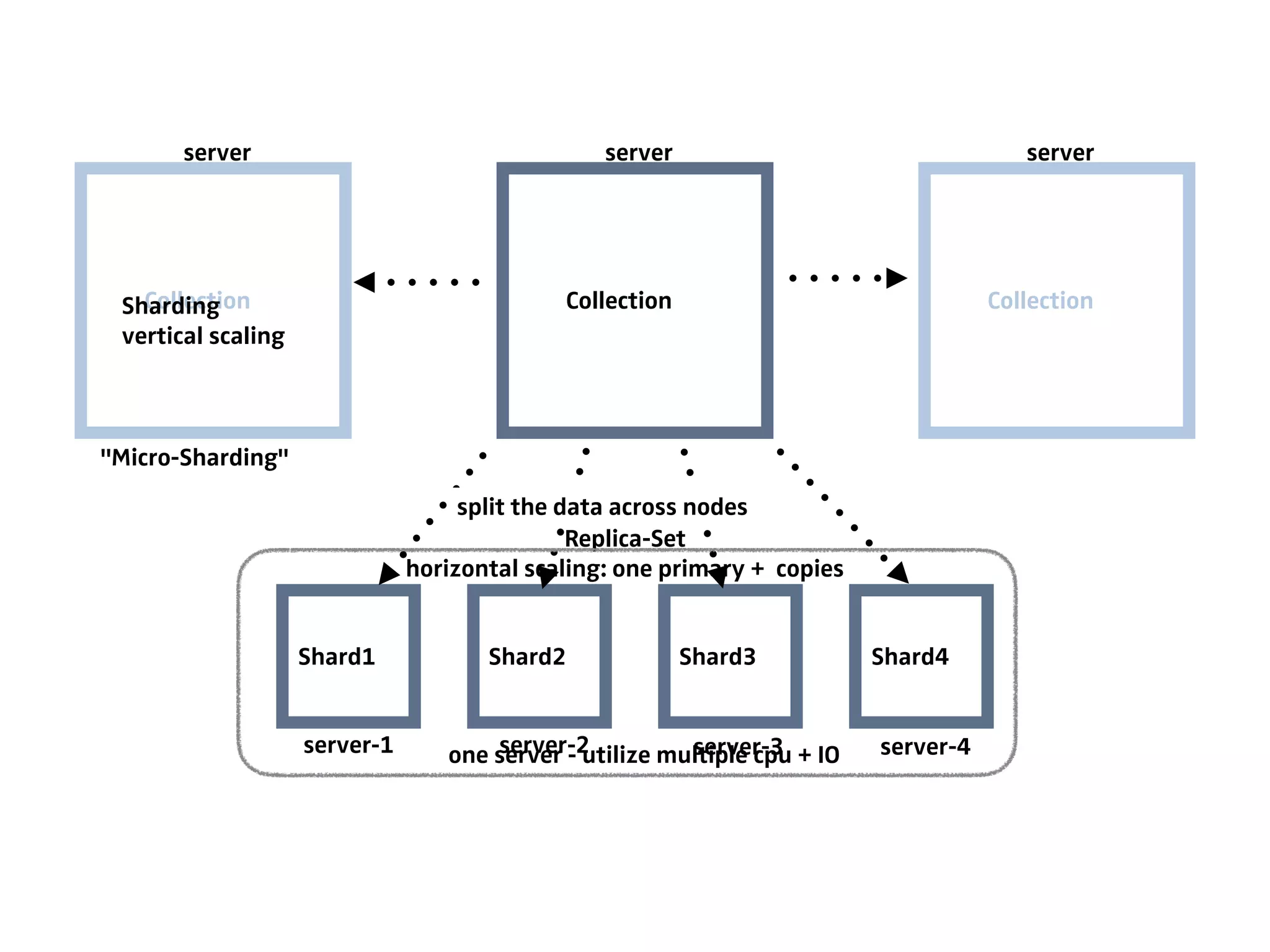
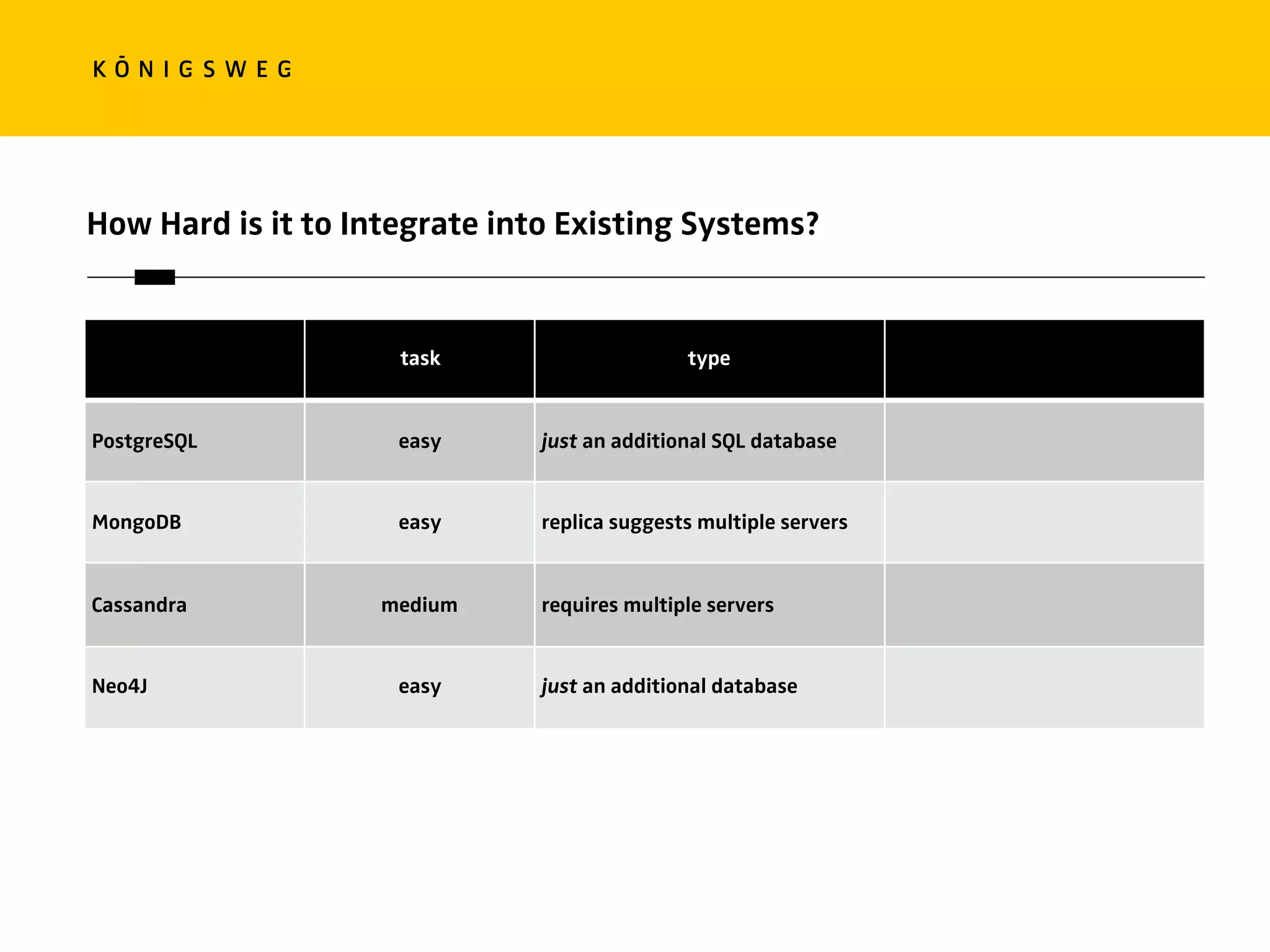

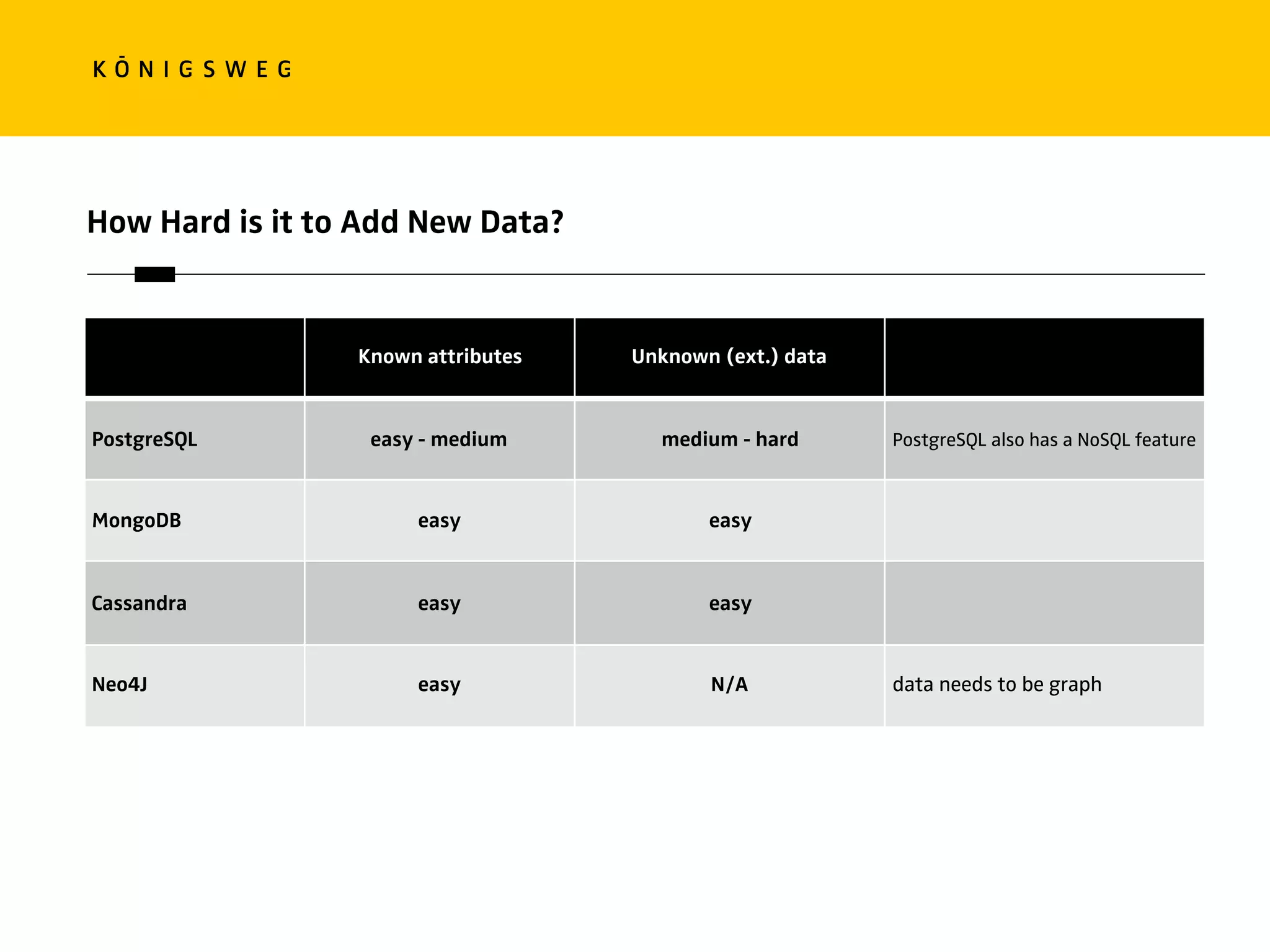
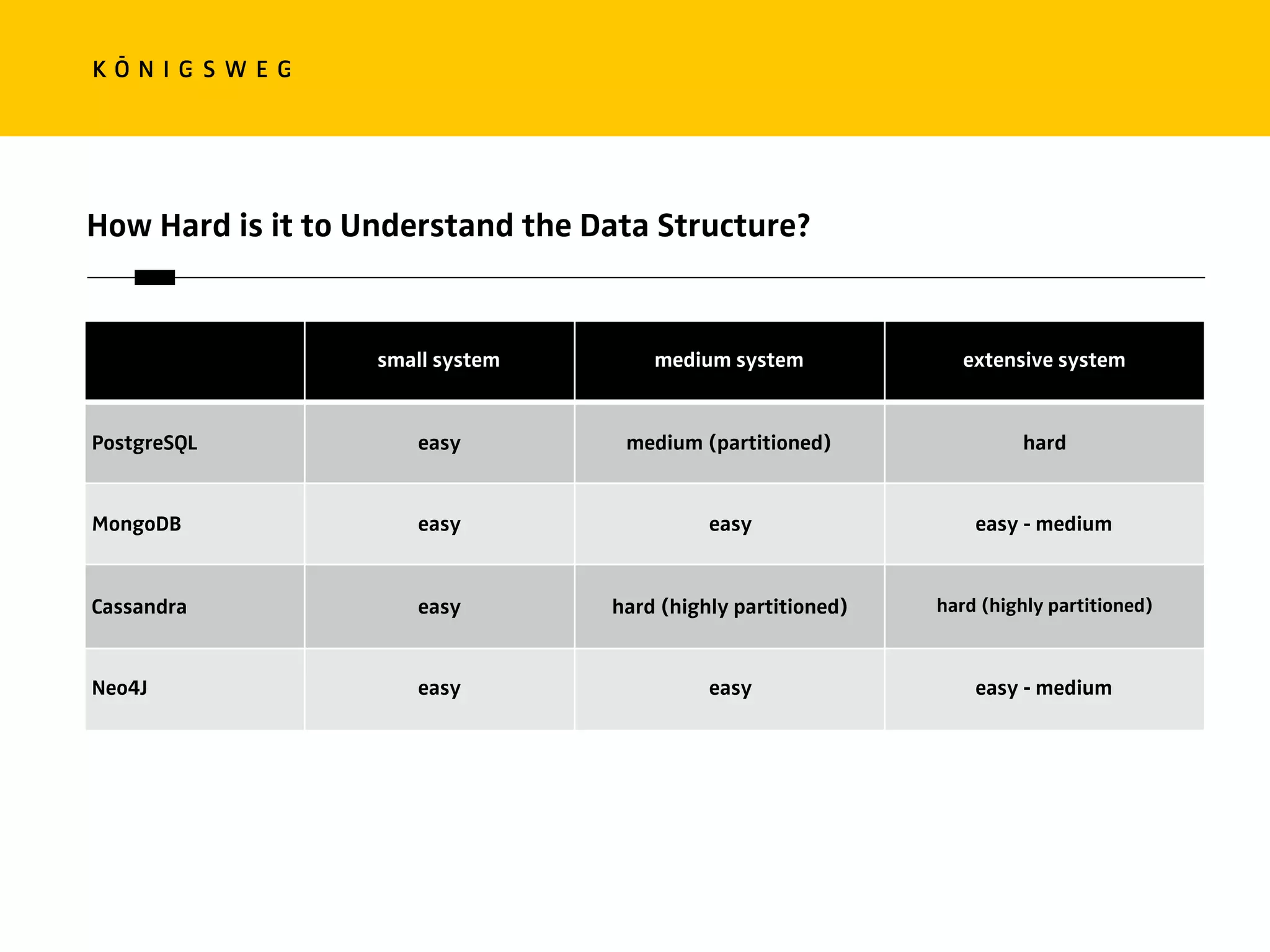








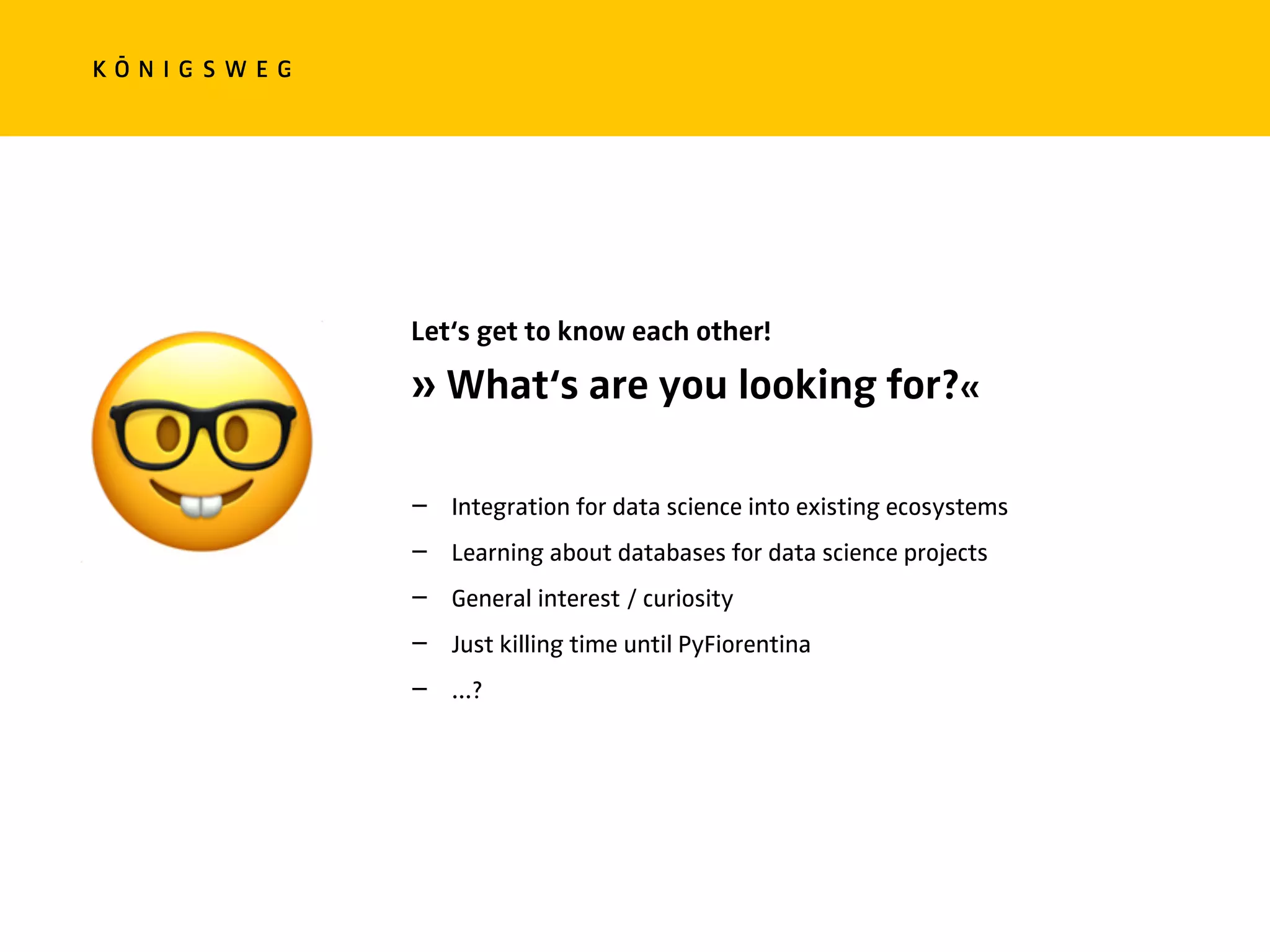
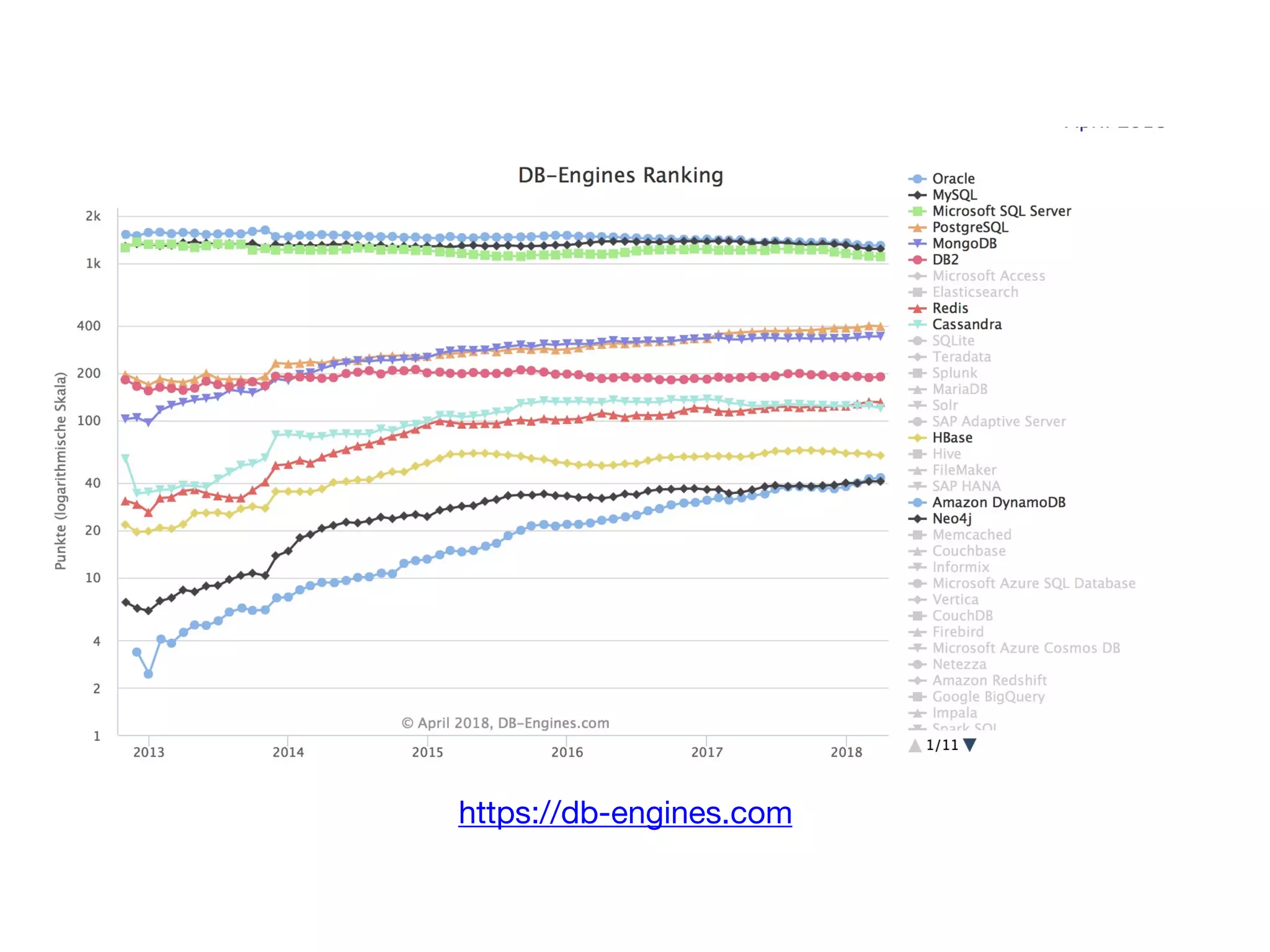
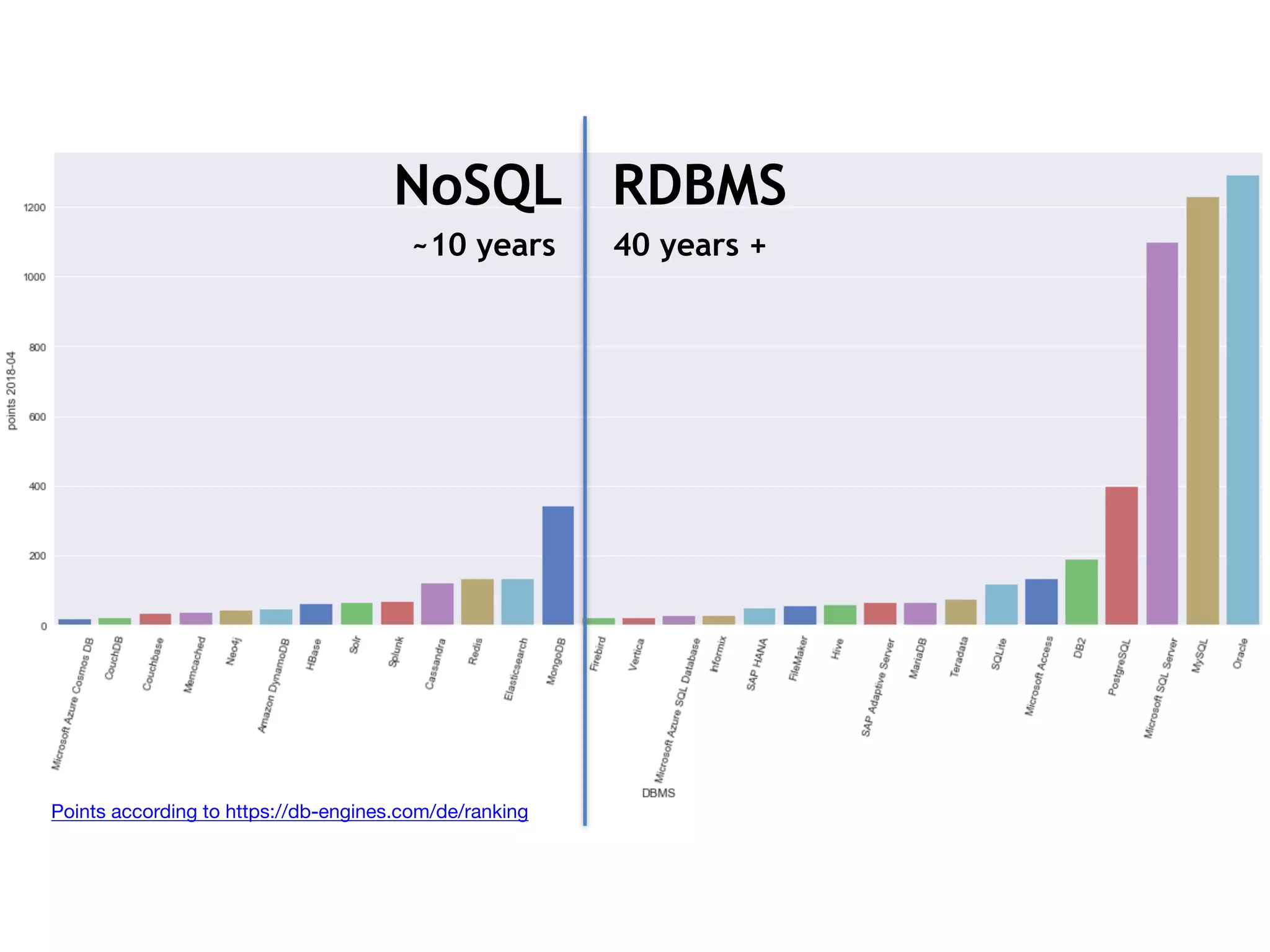
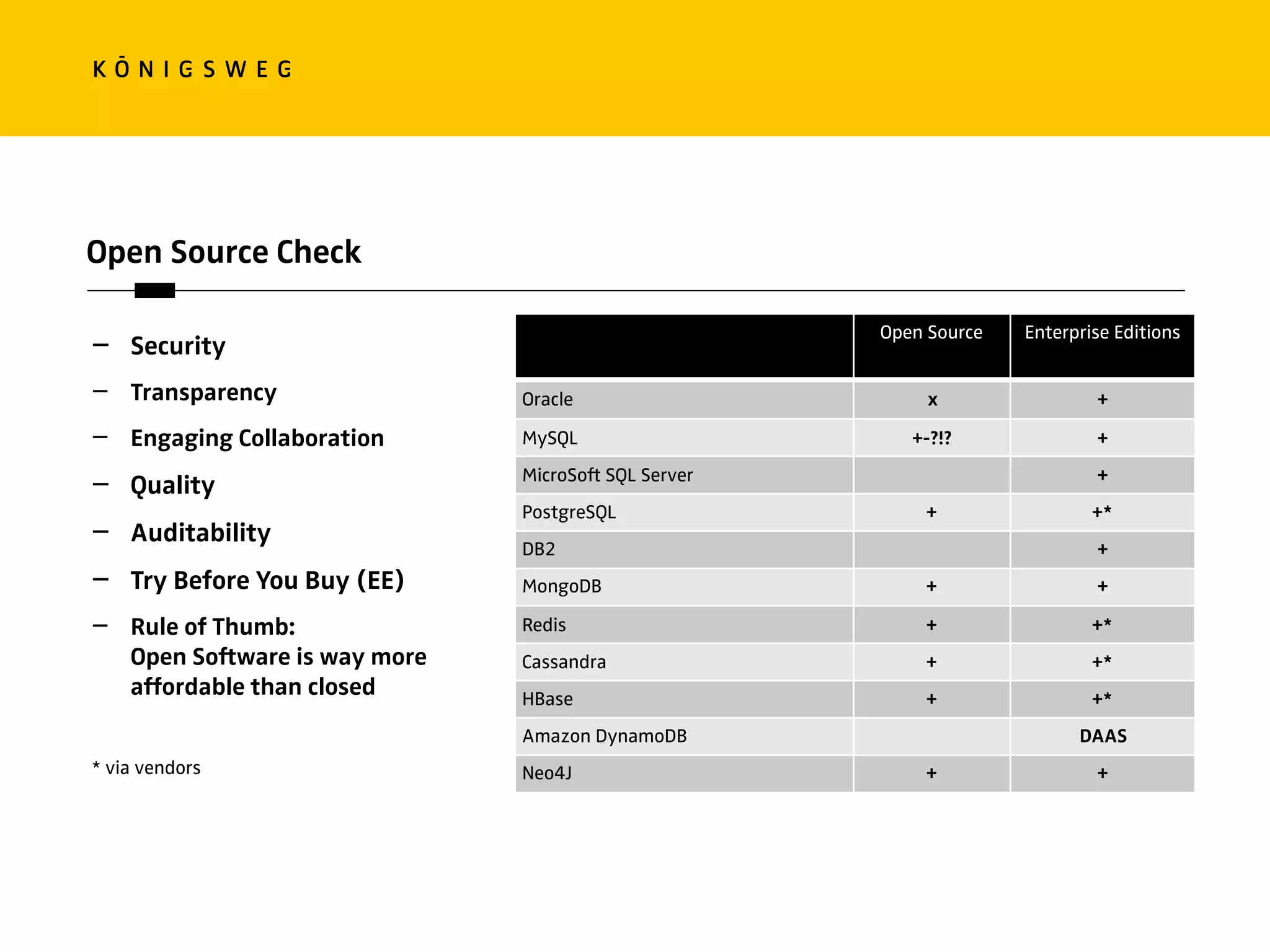
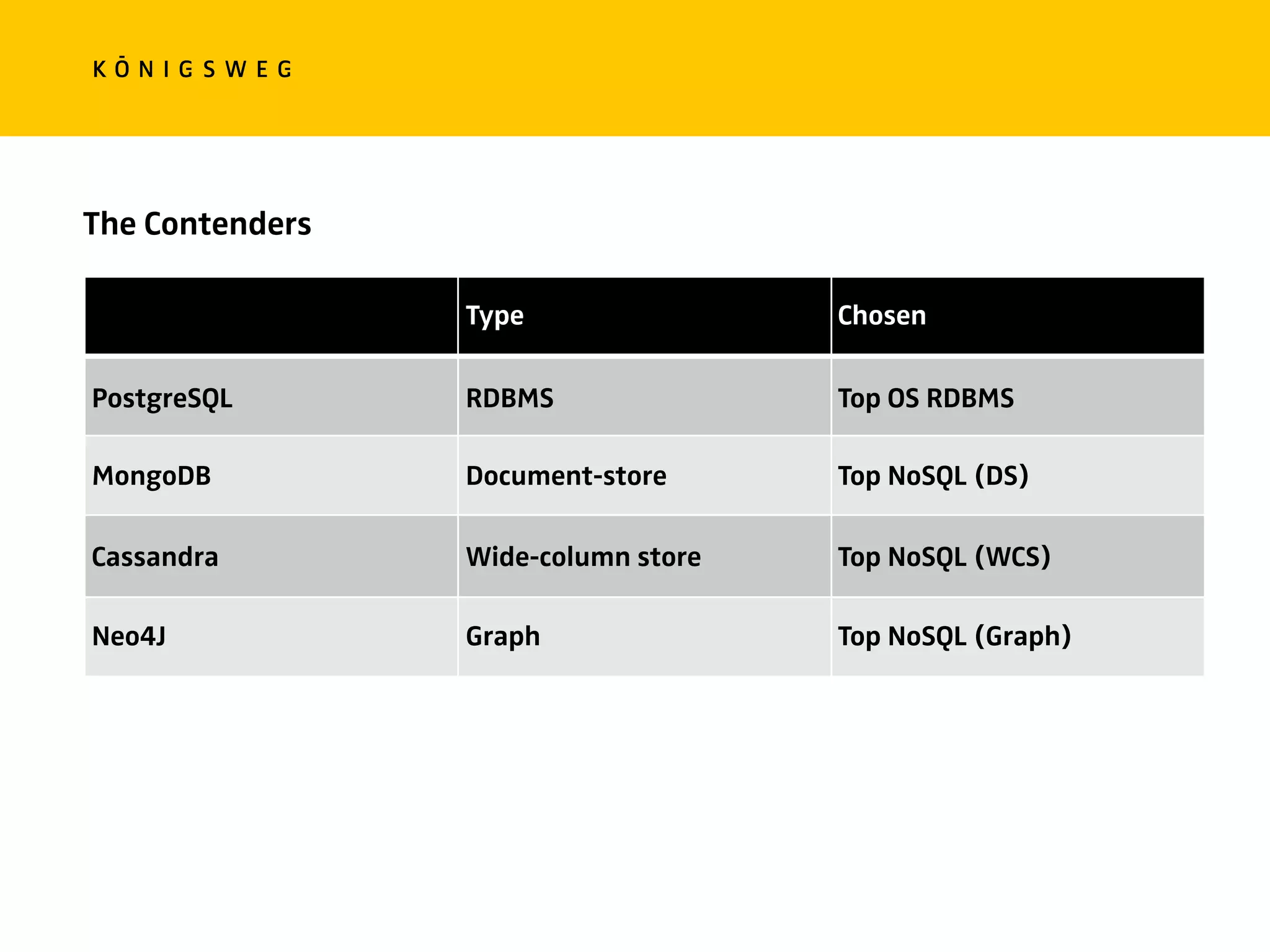
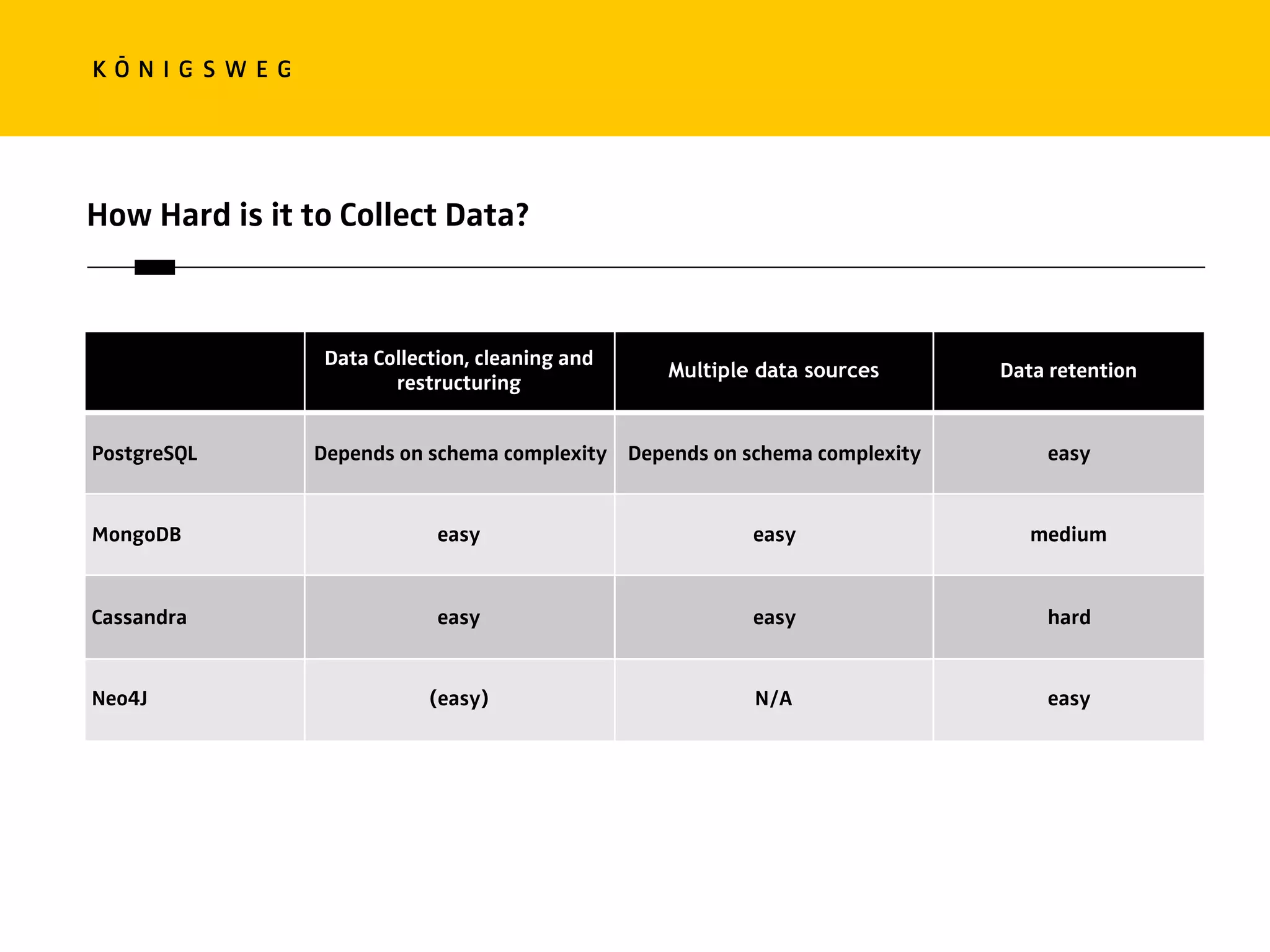
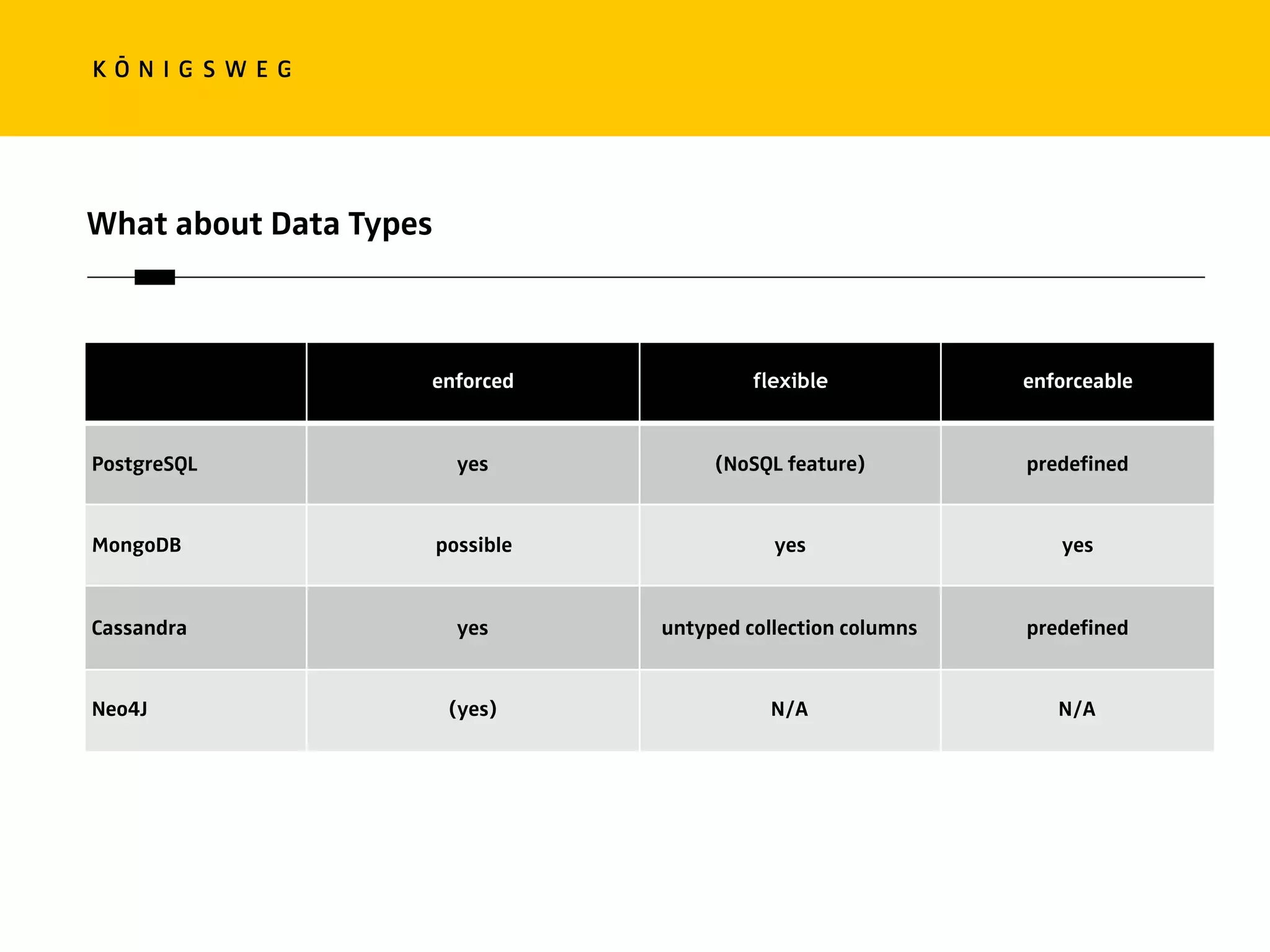
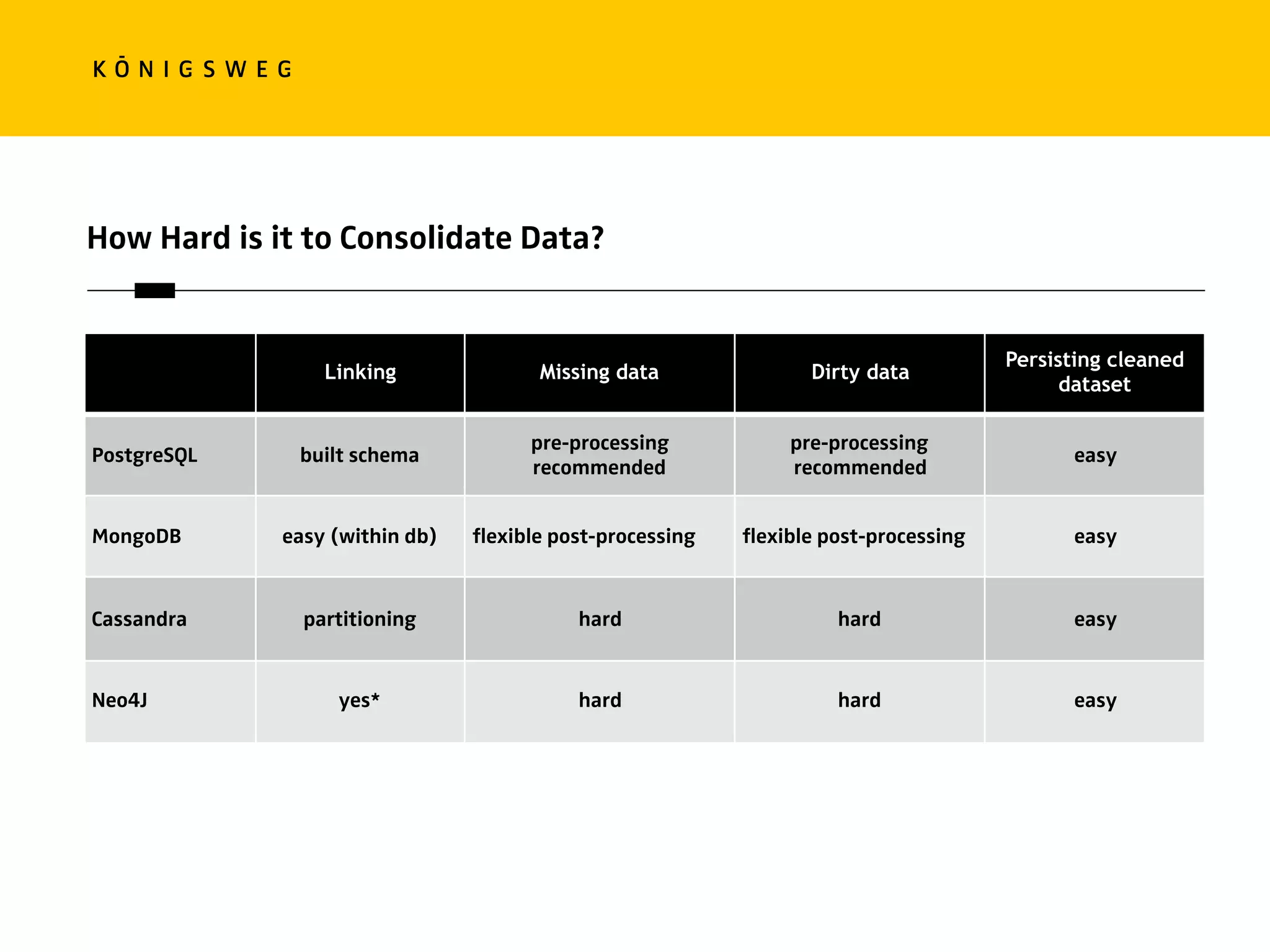
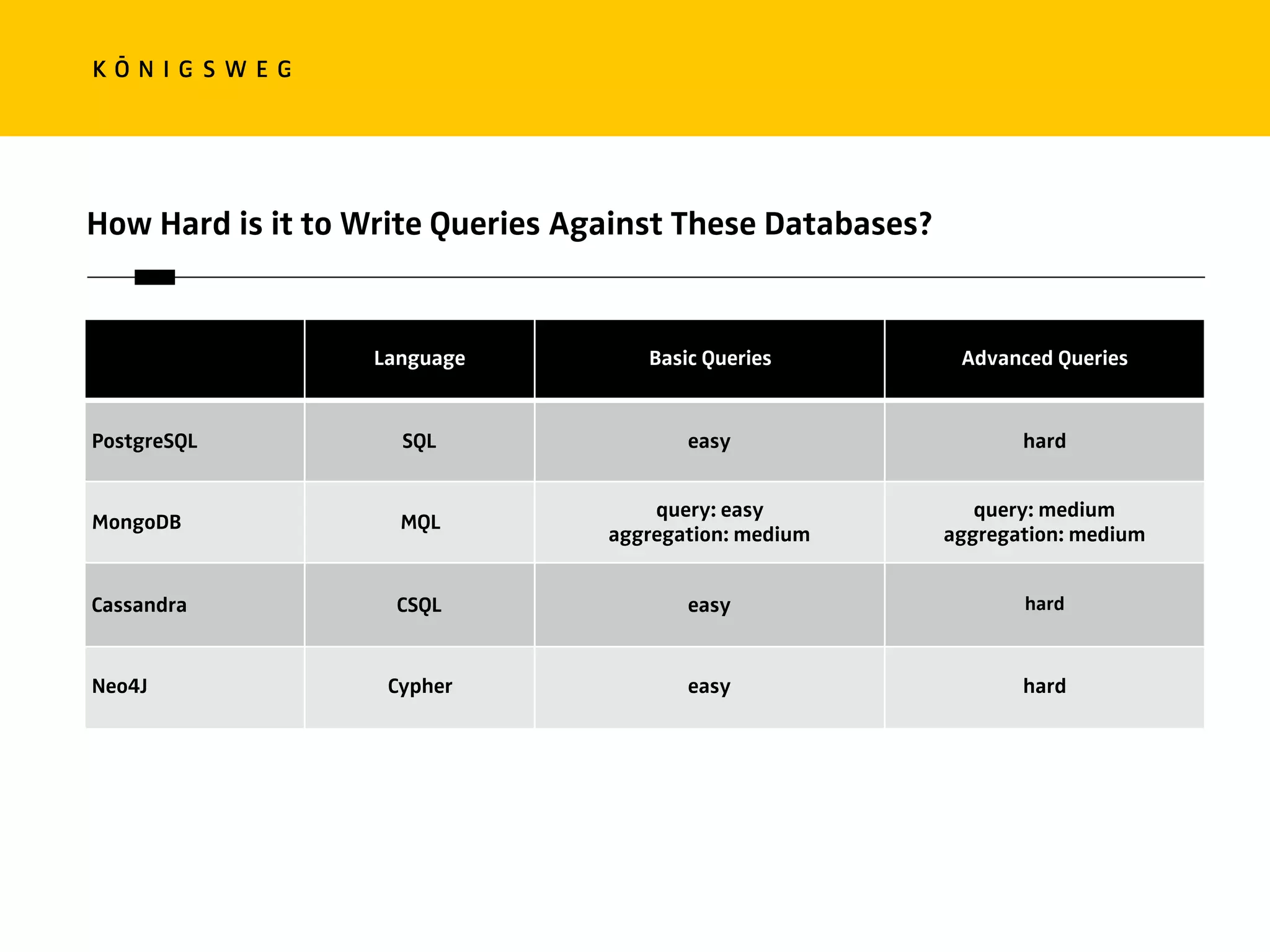
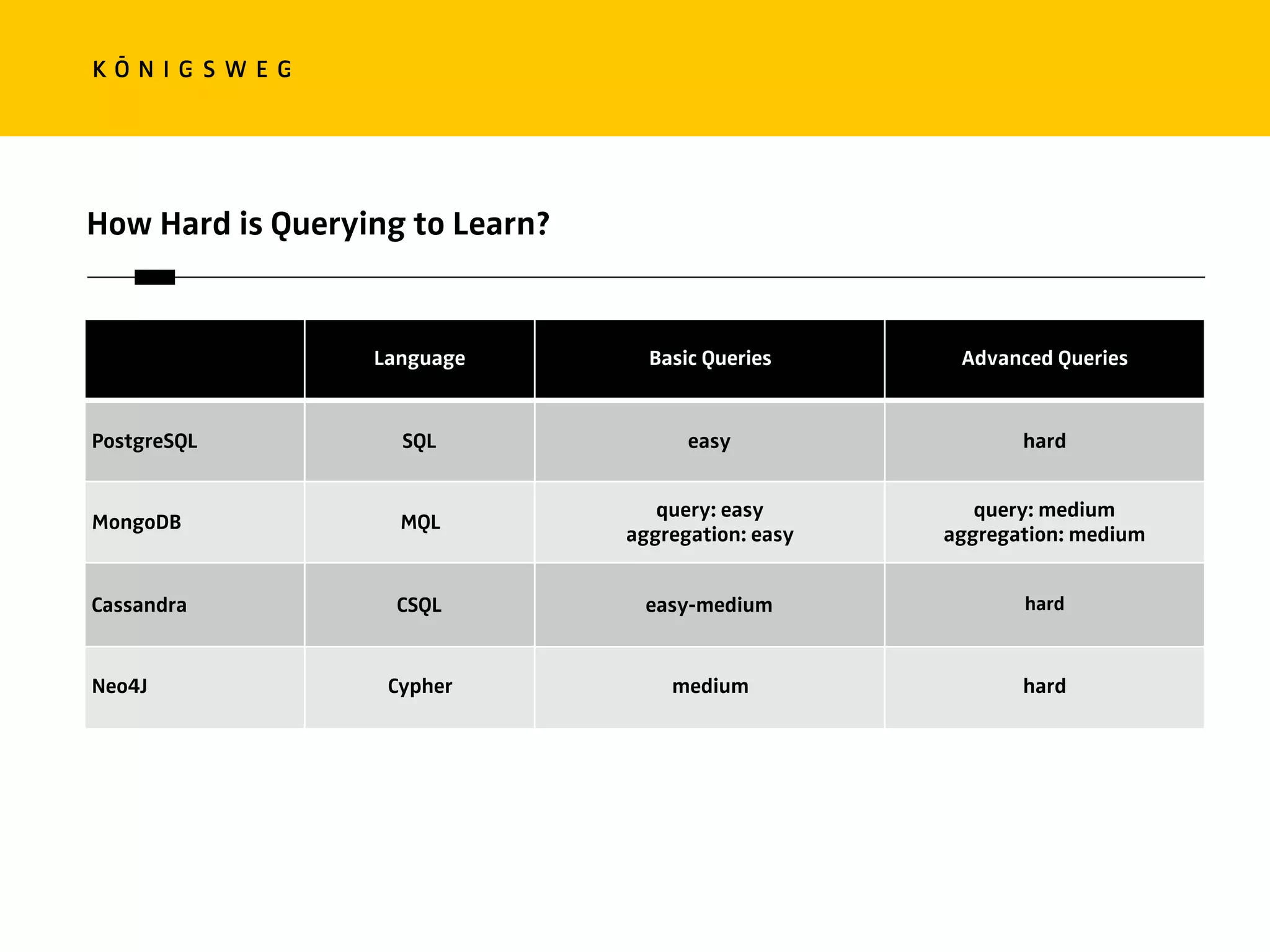
The document discusses the role of databases in data science, covering types of databases (RDBMS, NoSQL), their benefits, and challenges. It emphasizes the importance of choosing the right database based on project needs and highlights the evolution of database technologies. It concludes with advice for selecting databases for specific use cases and encourages exploration of various database solutions.
















































![Introduction to Pandas and Time Series Analysis [PyCon DE]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontopandasandtimeseriesanalysispyconde-170617163724-thumbnail.jpg?width=640&height=640&fit=bounds)
![Data analysis and visualization with mongo db [mongodb world 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/dataanalysisandvisualizationwithmongodbmongodbworld2016-160713161849-thumbnail.jpg?width=640&height=640&fit=bounds)
![Introduction to Data Analtics with Pandas [PyCon Cz]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontodataanalticswithpandaspyconcz-170617163446-thumbnail.jpg?width=640&height=640&fit=bounds)
![Introduction to Pandas and Time Series Analysis [Budapest BI Forum]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontopandasandtimeseriesanalysis-170617163829-thumbnail.jpg?width=640&height=640&fit=bounds)
![Einführung Datenanalyse mit Pandas [data2day]](https://cdn.slidesharecdn.com/ss_thumbnails/einfuhrungdatenanalysemitpandas-170617164037-thumbnail.jpg?width=640&height=640&fit=bounds)
![Neat Analytics with Pandas 4 3 [PyParis]](https://cdn.slidesharecdn.com/ss_thumbnails/neatanalyticswithpandas43pyparis-170617163008-thumbnail.jpg?width=640&height=640&fit=bounds)

![Data mangling with mongo db the right way [pyconit 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/datamanglingwithmongodbtherightwaypyconit2016-160420171121-thumbnail.jpg?width=640&height=640&fit=bounds)


![Data Mangling with mongoDB the Right Way [PyData London] 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/datamanglingwithmongodbtherightwaypydatalondon2016-170617163600-thumbnail.jpg?width=640&height=640&fit=bounds)
![Deep Learning for Fun and Profit [PyConDE 2018]](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearningforfunandprofitpyconde2018-181105221856-thumbnail.jpg?width=640&height=640&fit=bounds)



















