Download to read offline








![10
What do you mean ?
MongoDBExpressive
Queries
• Find anyone with phone # “1-212…”
• Check if the person with number “555…” is on the
“do not call” list
Geospatial
• Find the best offer for the customer at geo
coordinates of 42nd St. and 6th Ave
Text Search
• Find all tweets that mention the firm within the last
2 days
Aggregation
• Count and sort number of customers by city,
compute min, max, and average spend
Native Binary
JSON support
• Add a phone number to Mark Smith’s
• Update just 2 phone numbers out of 10
• Sort on the modified date
{ customer_id : 1,
first_name : "Mark",
last_name : "Smith",
city : "San Francisco",
phones: [{
number : “1-212-777-
1212”,
type : “work”
},
{
number : “1-212-777-
1213”,
type : “cell”
}]
...
JOIN ($lookup)
• Query for all San Francisco residences, lookup
their transactions, and sum the amount by person
Graph queries
($graphLookup)
• Query for all people within 3 degrees of
separation from Mark](https://image.slidesharecdn.com/04odm11-session4-which-questions-we-should-have-oracle-meetup-version-190520150045/85/Which-Questions-We-Should-Have-10-320.jpg)





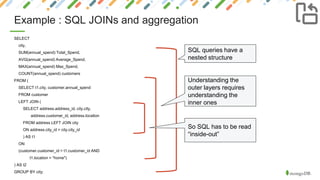
![Example : Complex queries fast to create, optimize, & maintain
MongoDB’s aggregation framework has the flexibility you need to get value from your data,
but without the complexity and fragility of SQL
db.customers.aggregate([
{
$unwind: "$address",
},
{
$match: {"address.location": "home"}
},
{
$group: {
_id: "$address.city",
totalSpend: {$sum: "$annualSpend"},
averageSpend: {$avg: "$annualSpend"},
maximumSpend: {$max: "$annualSpend"},
customers: {$sum: 1}
}
}
])
These “phases” are distinct
and easy to understand
They can be thought about
in order… no nesting.](https://image.slidesharecdn.com/04odm11-session4-which-questions-we-should-have-oracle-meetup-version-190520150045/85/Which-Questions-We-Should-Have-19-320.jpg)












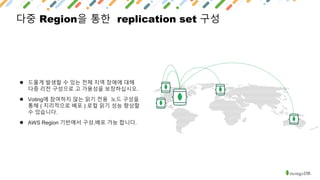
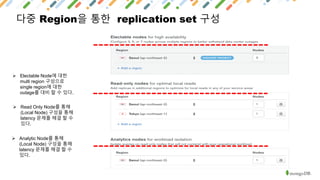
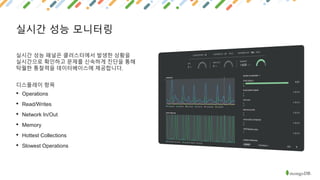
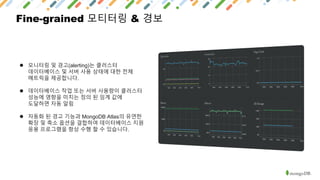

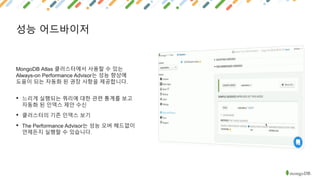
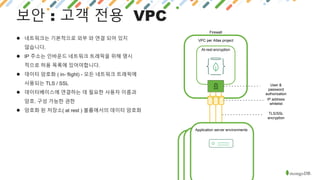


MongoDB is a document-oriented NoSQL database that provides polyglot persistence and multi-model capabilities. It supports document, graph, relational, and key-value data models through a single backend. MongoDB also provides tunable consistency levels, secondary indexing, aggregation capabilities, and multi-document ACID transactions. Mature drivers simplify application development, while MongoDB Atlas provides a fully managed cloud database service with high availability, security, and monitoring.































































![[Main Session] 카프카, 데이터 플랫폼의 최강자](https://cdn.slidesharecdn.com/ss_thumbnails/180519-kafka-oraclefin-180521125323-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Demo session] 관리형 Kafka 서비스 - Oracle Event Hub Service](https://cdn.slidesharecdn.com/ss_thumbnails/oraclouddevmeetupeventhubpublic-180521084803-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Hands-on] CQRS(Command Query Responsibility Segregation) 와 Event Sourcing 패턴 실습](https://cdn.slidesharecdn.com/ss_thumbnails/cqrsesv201804221730publish-180422082848-180423040836-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Main Session] 보안을 고려한 애플리케이션 개발 공정 및 실무적 수행 방법 소개](https://cdn.slidesharecdn.com/ss_thumbnails/s-sdlcsecurecoding2018-04-21-180423031934-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Main Session] 미래의 Java 미리보기 - 앰버와 발할라 프로젝트를 중심으로](https://cdn.slidesharecdn.com/ss_thumbnails/java-180320135253-thumbnail.jpg?width=640&height=640&fit=bounds)



















