Download to read offline







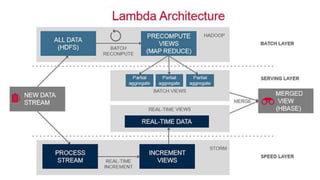

![[Distributed Cache]
Metrics &
Analytics
Complex
Alerts
Scheduled
Feeds
Adhoc
Queries
Detail
Data
Logical Unified
Data Model
Subject Area
Logical Data
Models
Enterprise Data Fabric Cluster
Unified queries
Business &
Exceptions Rules
Normalisation and
Standardisation Rules
Top Down Data
Quality (and profiling)
Connectors (JDBC,
APIs, ODBC, etc)
Schedulers and
Refresh Jobs Rules
Query Planners &
Optimiser(s)
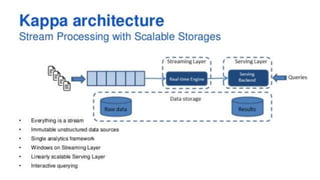
Data Fabric Architecture
• Schema Store
• Distributed Cache
• Query Federation
• Query Optimisation
• Semantic Normalisation](https://image.slidesharecdn.com/pgdu-190322133532/85/HTAP-Queries-13-320.jpg)


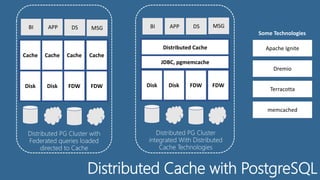




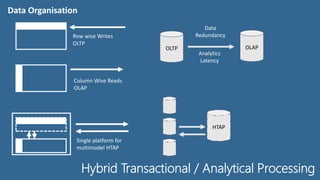
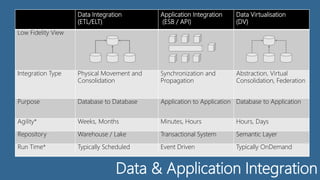
The document discusses HTAP (Hybrid Transactional/Analytical Processing), data fabrics, and key PostgreSQL features that enable data fabrics. It describes HTAP as addressing resource contention by allowing mixed workloads on the same system and analytics on inflight transactional data. Data fabrics are defined as providing a logical unified data model, distributed cache, query federation, and semantic normalization across an enterprise data fabric cluster. Key PostgreSQL features that support data fabrics include its schema store, distributed cache, query federation, optimization, and normalization capabilities as well as foreign data wrappers.













































































