Download as PDF, PPTX






















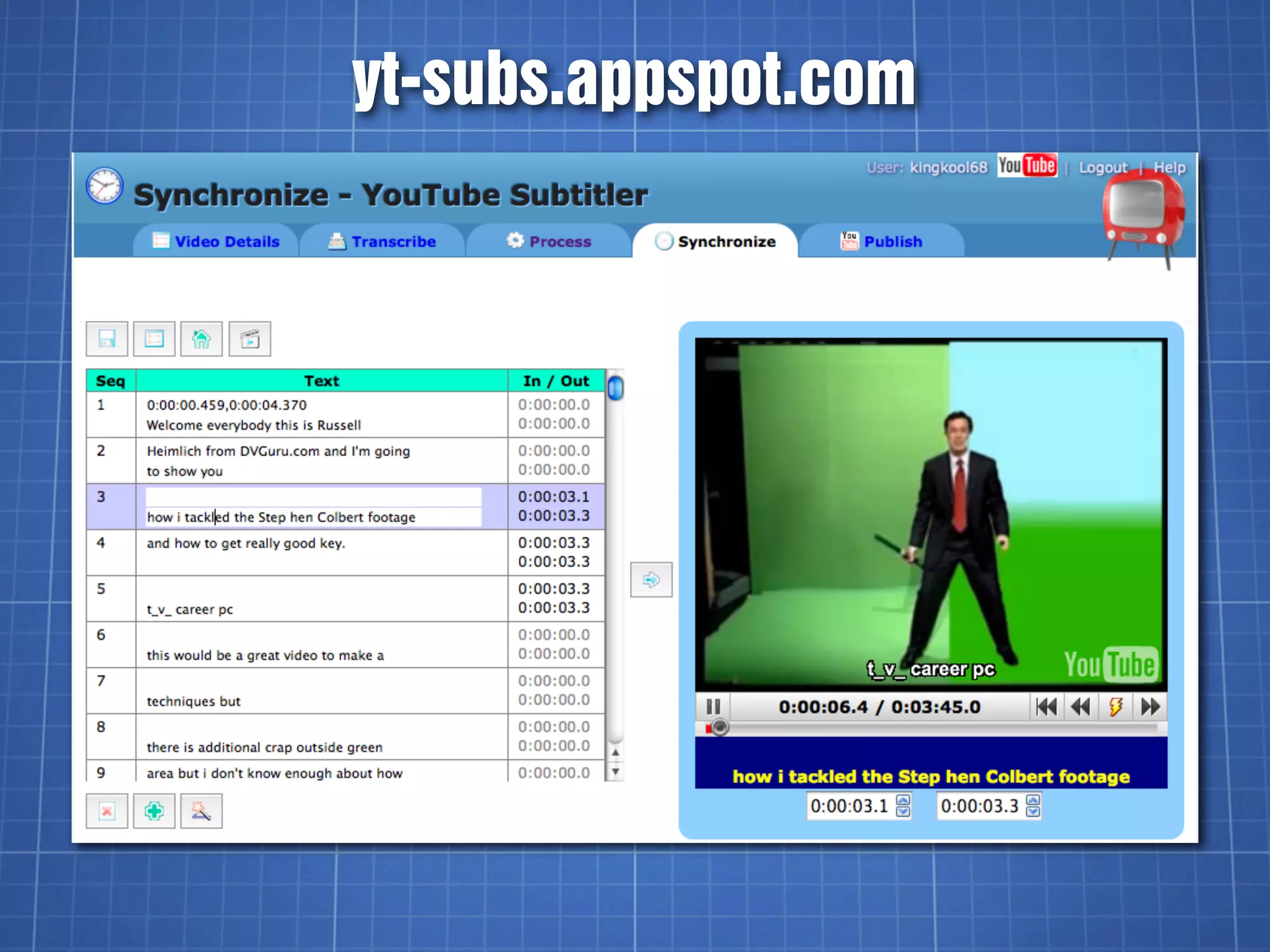
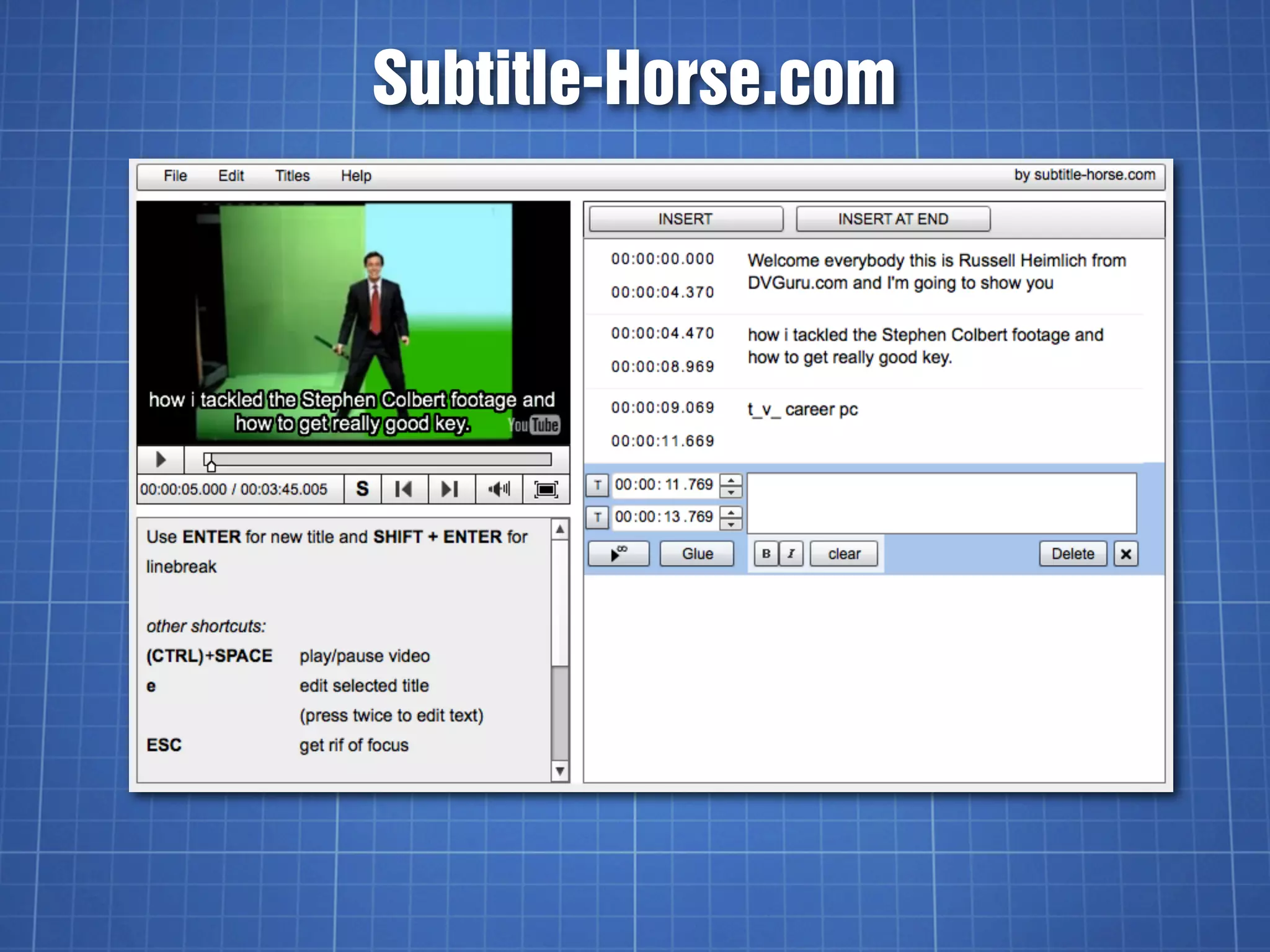
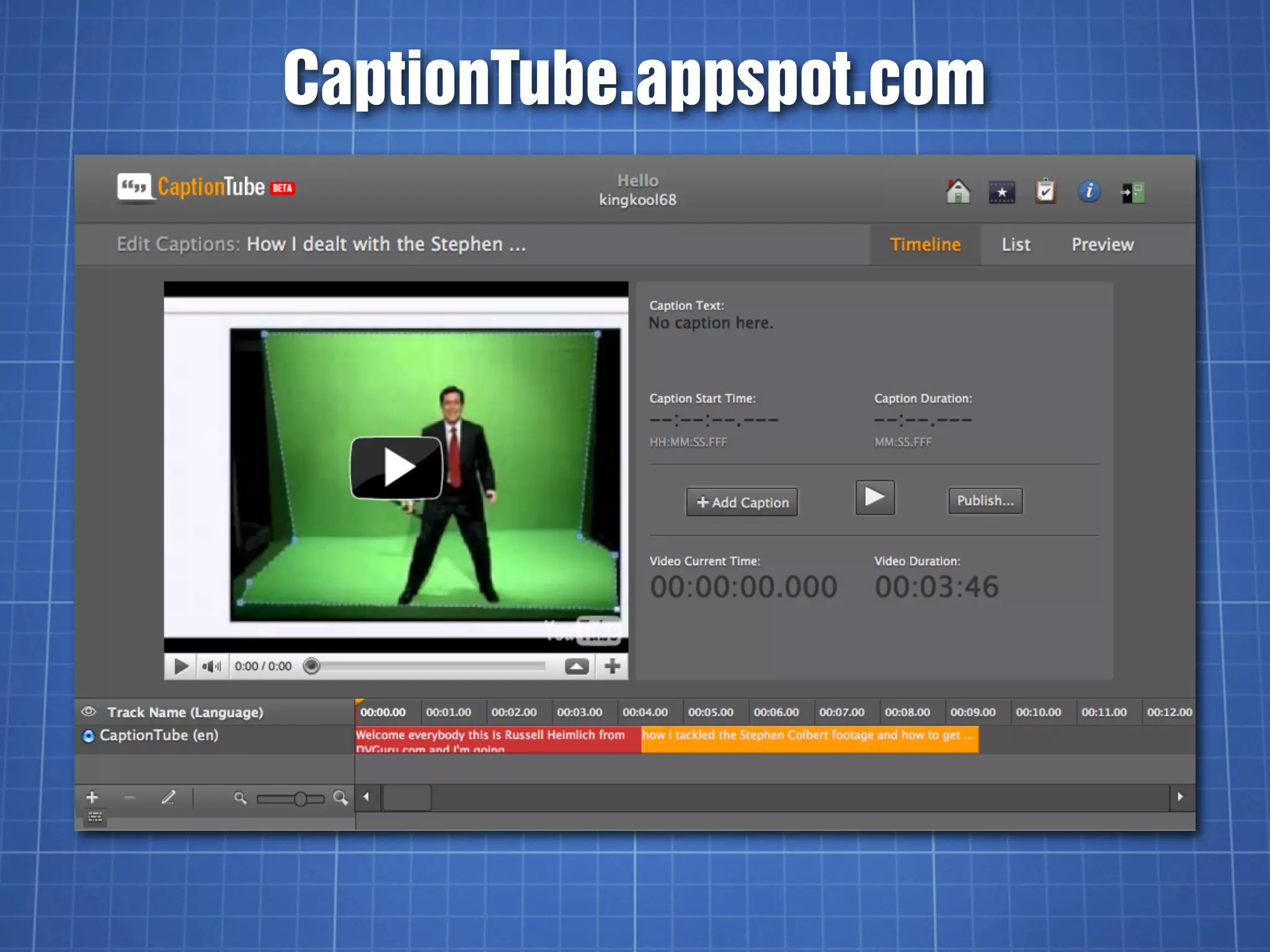
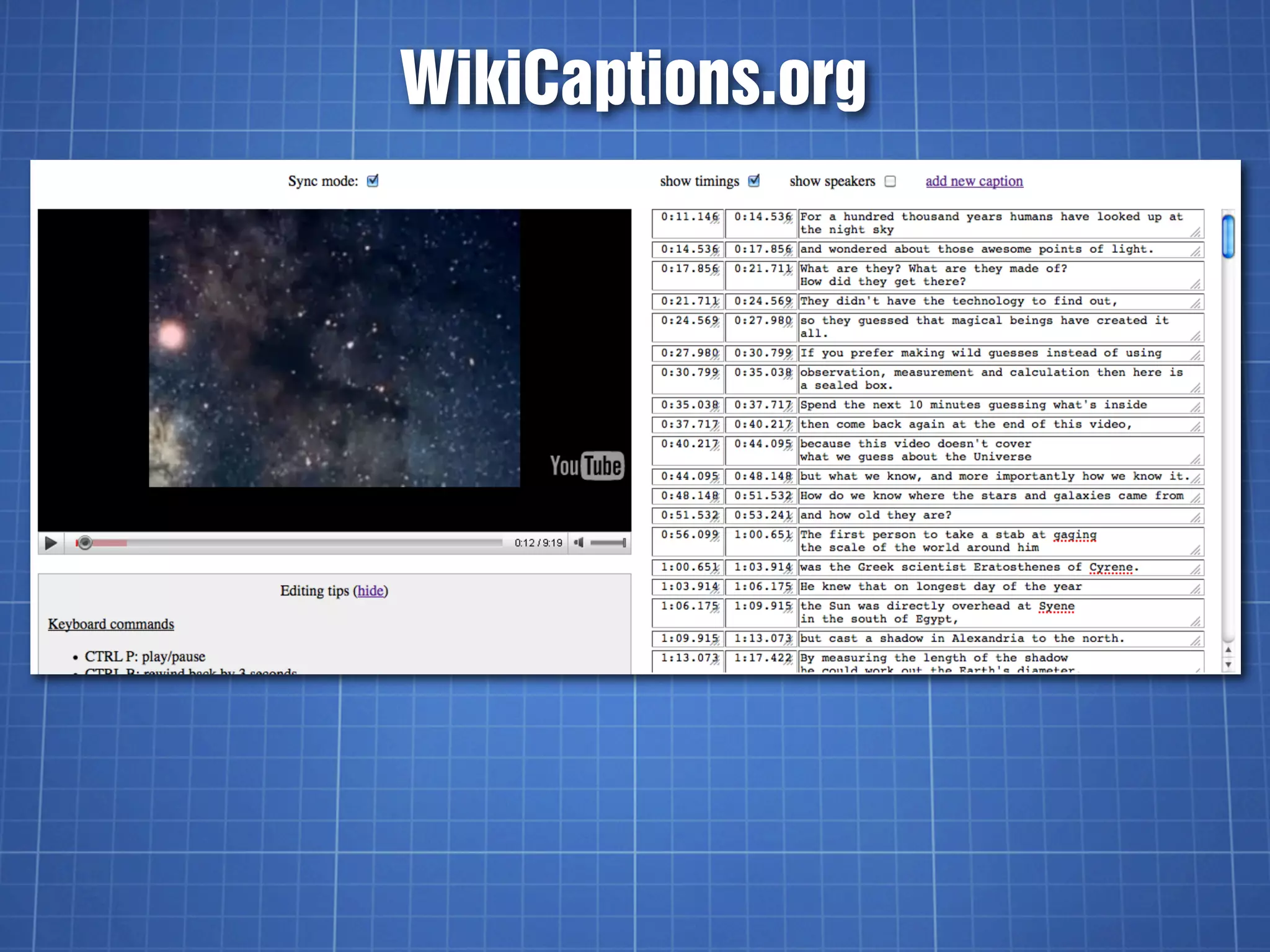




![YouTube’s SBV Format
Start time, End time (H:MM:SS.milliseconds)
Text (one or more lines)
0:00:03.490,0:00:07.430
>> FISHER: All right. So, let's begin.
This session is: Going Social
0:00:07.430,0:00:11.600
with the YouTube APIs. I am
Jeff Fisher,
0:00:14.009,0:00:15.889
[pause]](https://image.slidesharecdn.com/videocaptioningontheweb-110618085458-phpapp02/75/Video-Captioning-on-the-Web-37-2048.jpg)


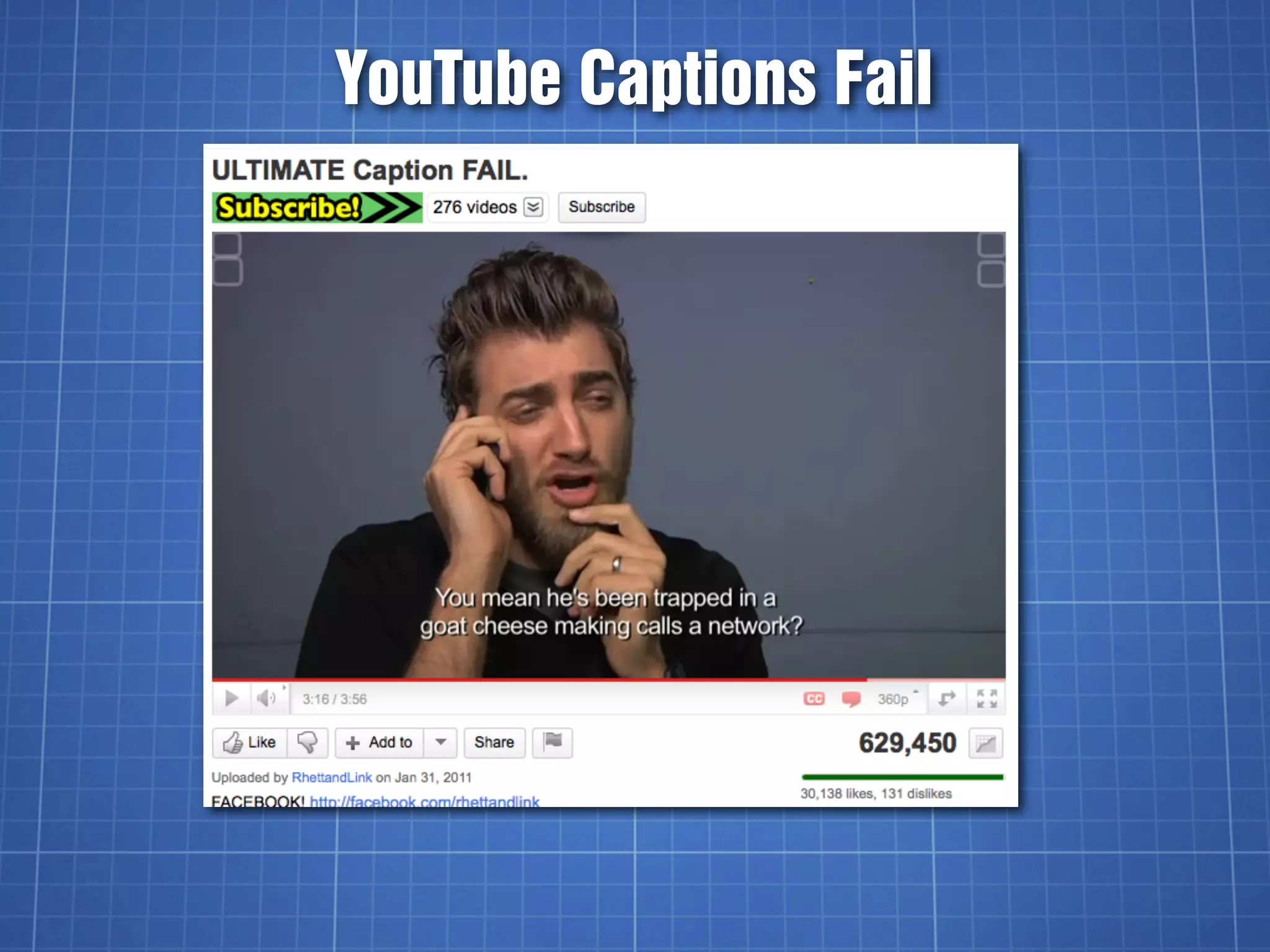
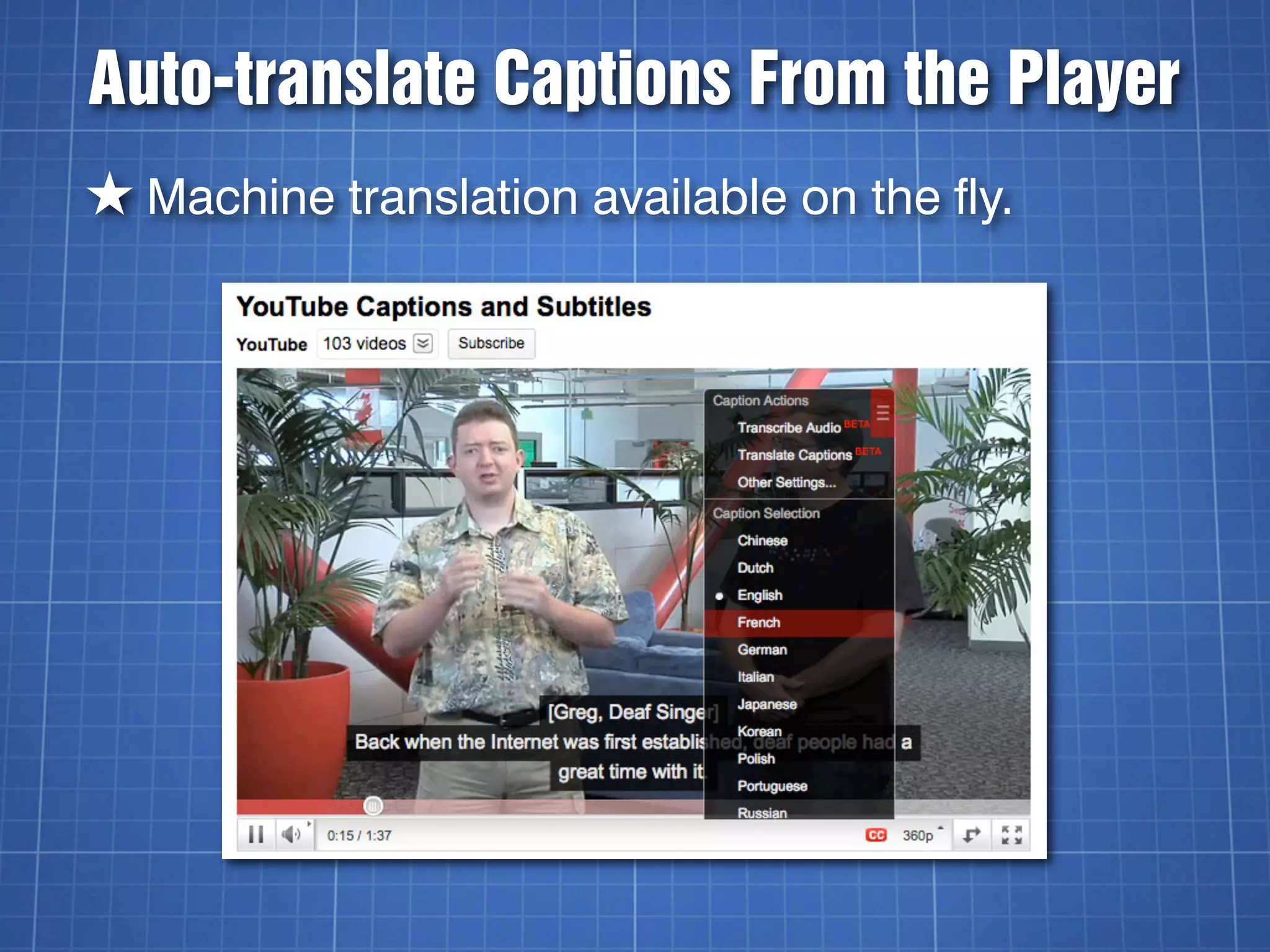








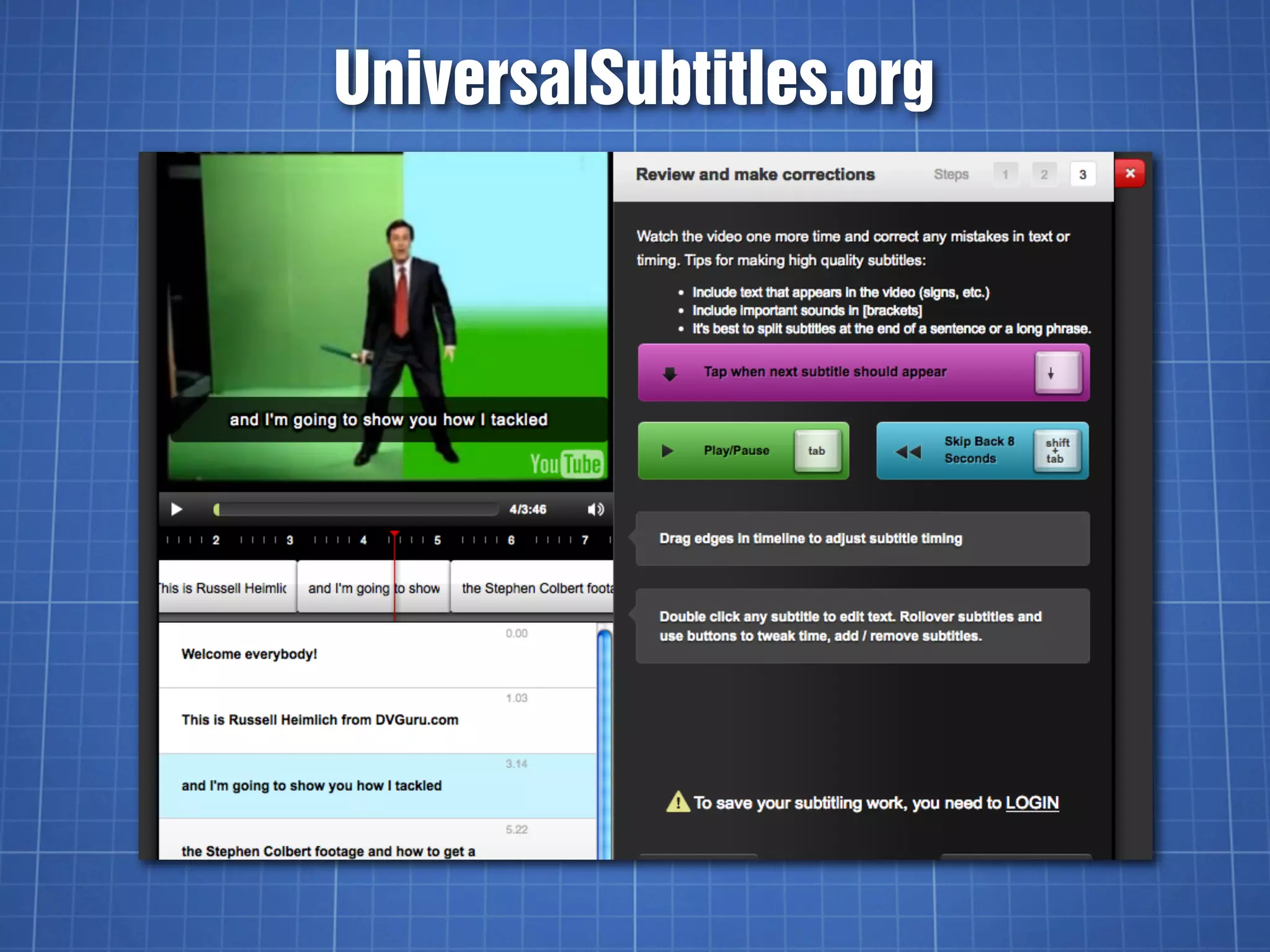
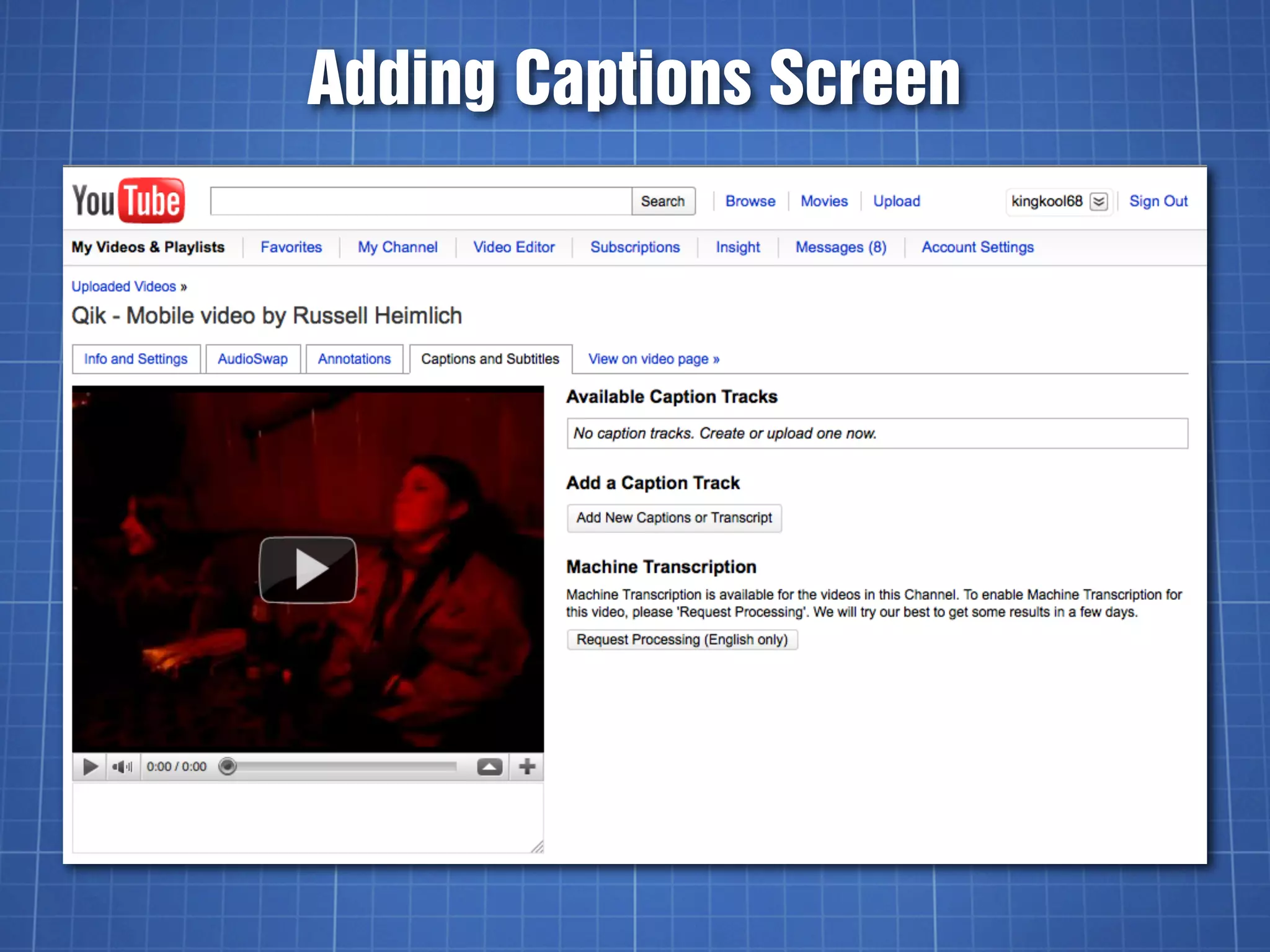
The document discusses video captioning, differentiating between captions and subtitles, and explains the history and importance of captions for accessibility. It covers various methods for adding captions to videos, particularly on YouTube, and highlights both paid and DIY options for creating captions. The text emphasizes the significance of captions for diverse audiences, including the deaf and hard of hearing, second language learners, and those in noisy environments.
























![[DL輪読会]Object-Centric Learning with Slot Attention](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0717-200717023021-thumbnail.jpg?width=640&height=640&fit=bounds)
















































