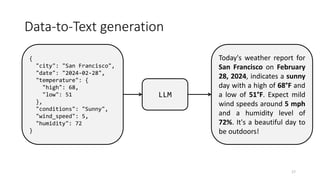
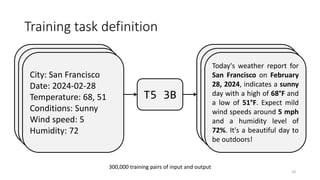
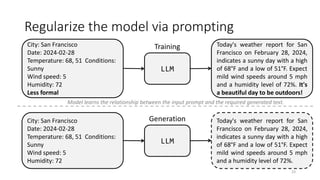
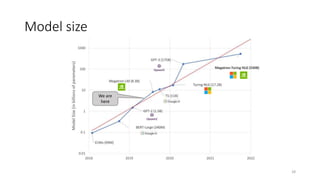
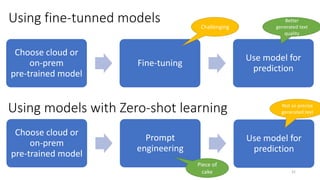
The document discusses the fine-tuning of large language models (LLMs) for data-to-text generation, focusing on various methods, pre-training versus fine-tuning, and considerations for model selection and training environments. It emphasizes the importance of high-quality data, effective prompting, and the distinctions between different model sizes and their capabilities. The document also covers specific examples of data-to-text generation, challenges faced, and potential solutions for improving output quality.








![Supervised fine-tuning in clouds
13
Cloud LLM Model
Azure GPT, Llama
AWS Bedrock Amazon Titan, Anthropic Cloude, Cohere Command, Meta Llama [link]
GCP Vertex AI* PaLM 🌴, Gemma, T5, Gemini**, Llama
OpenAI Platform GPT
Anthropic Claude
Cohere Command
MosaicML MPT
* - supports RLHF
** - coming soon](https://image.slidesharecdn.com/fine-tuninglargelanguagemodelpublic-240327160859-0b7d3658/85/Fine-tuning-Large-Language-Models-by-Dmitry-Balabka-13-320.jpg)





























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





