Download as PDF, PPTX










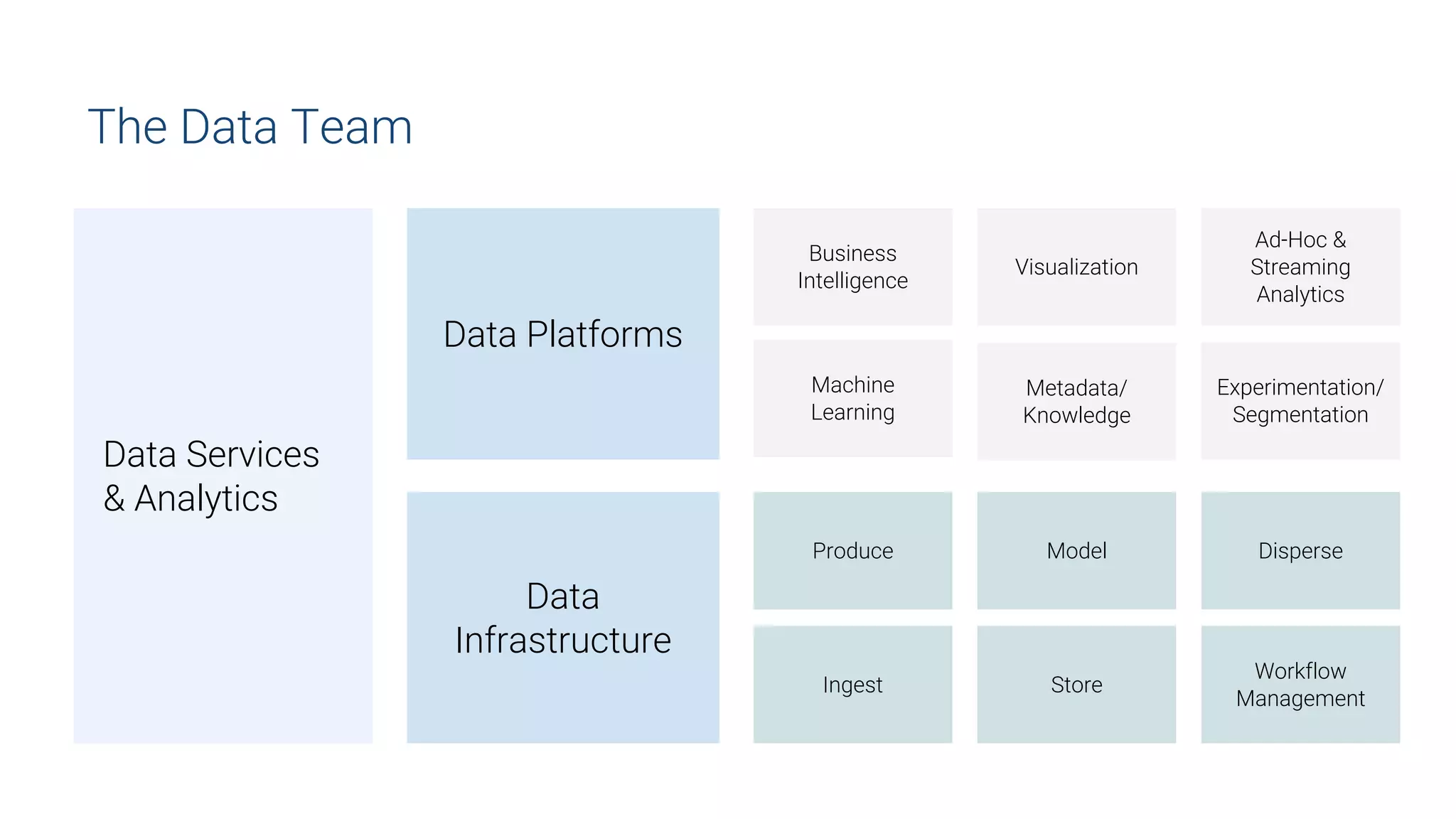
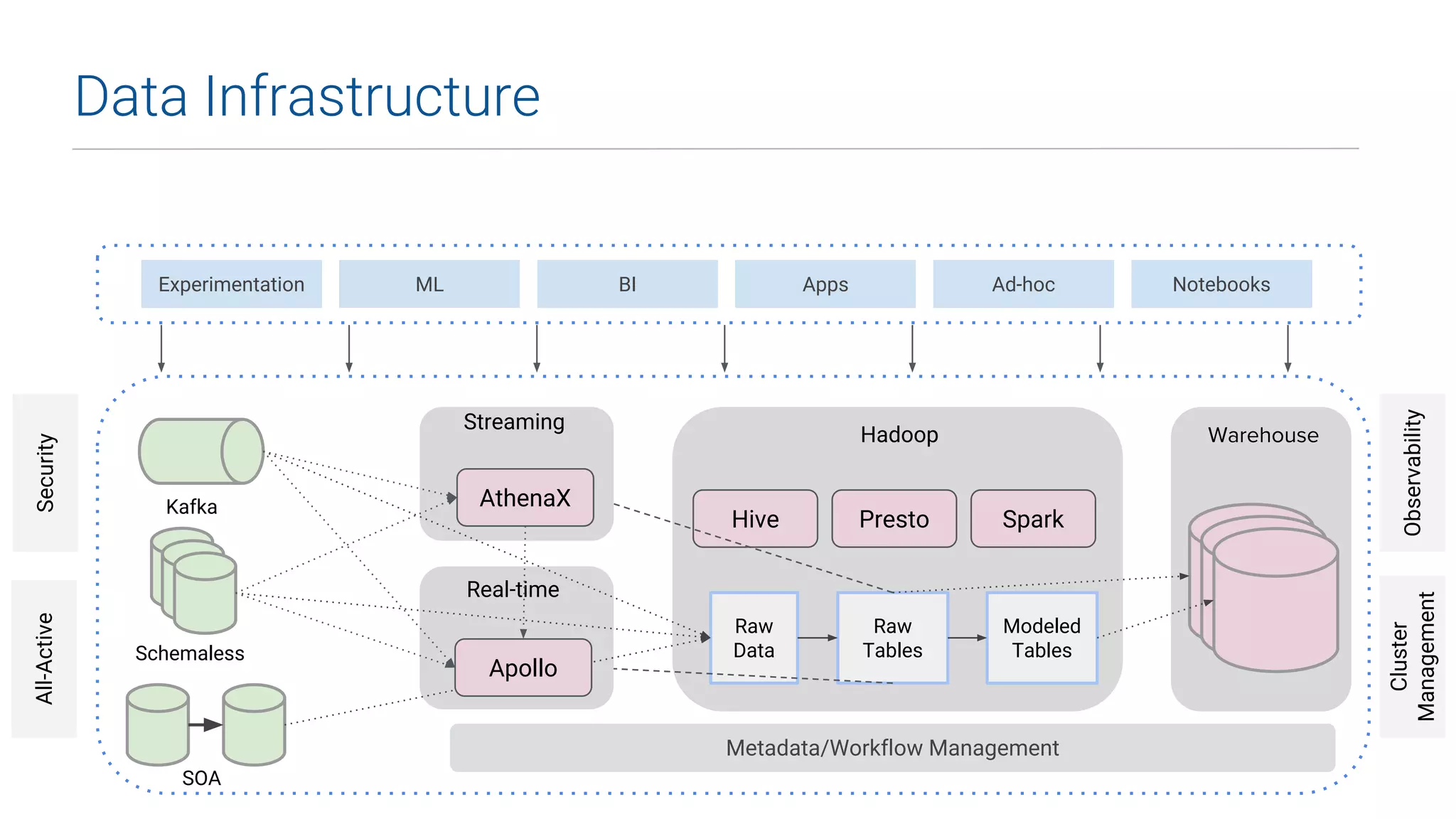






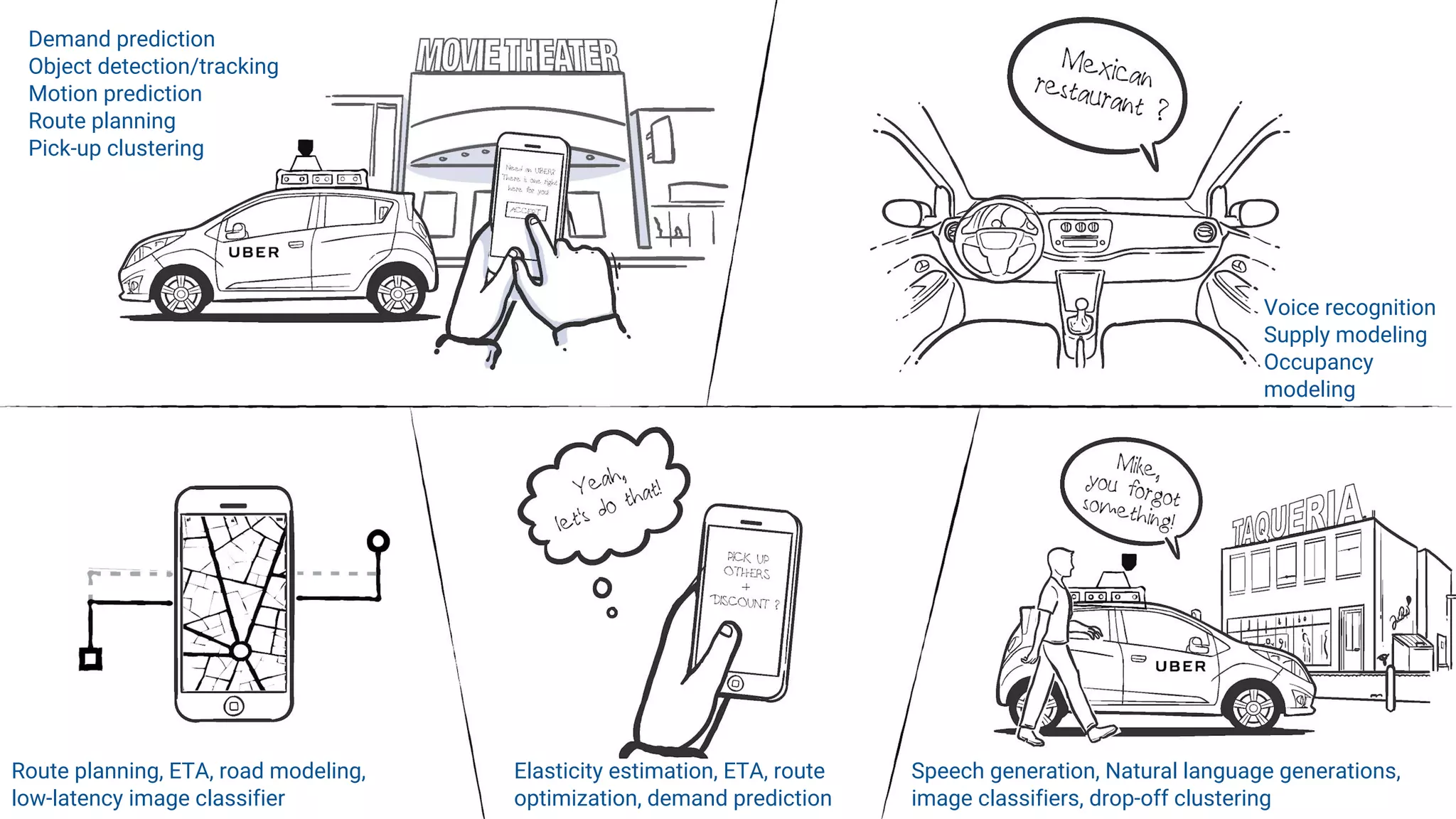
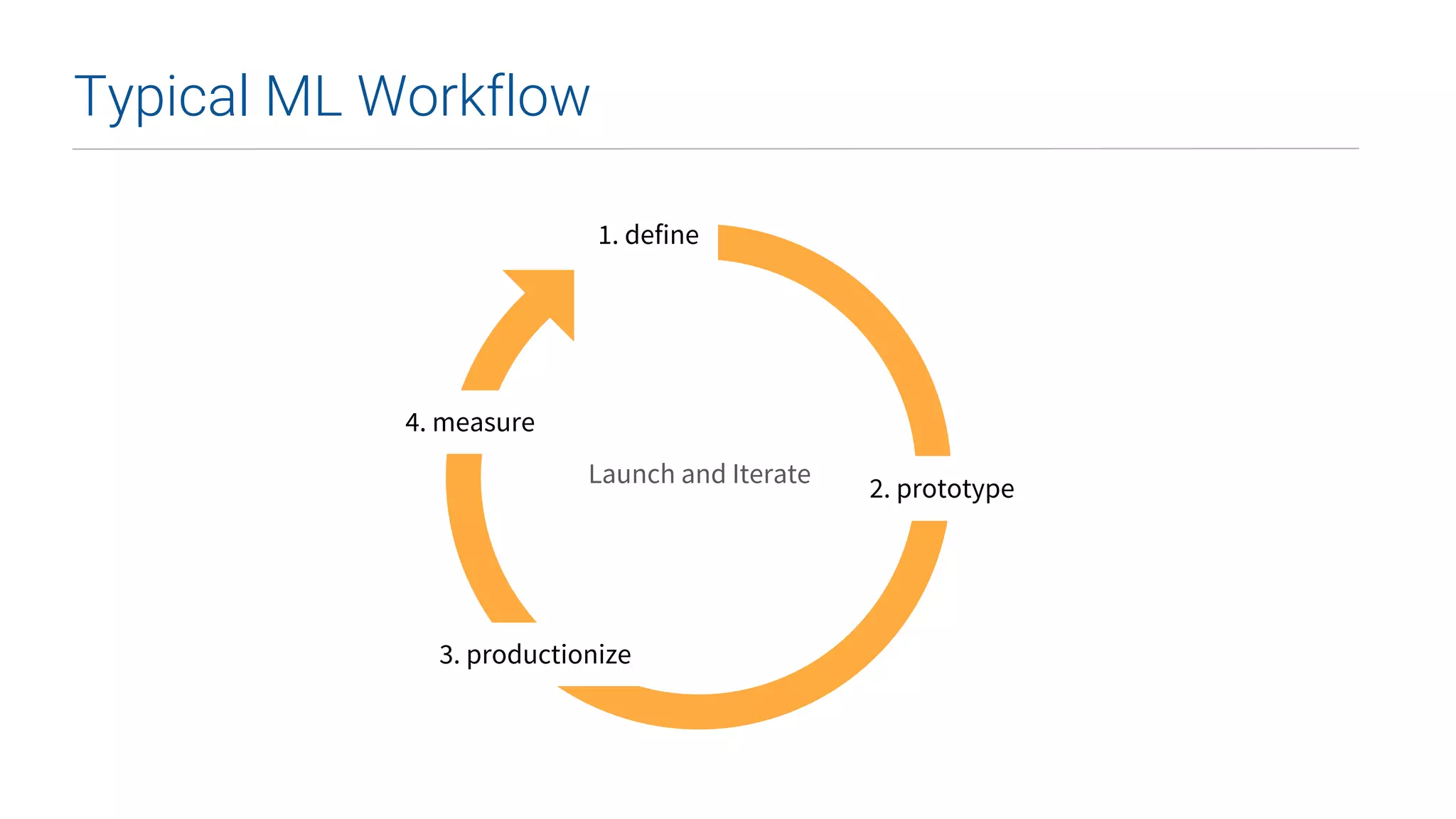
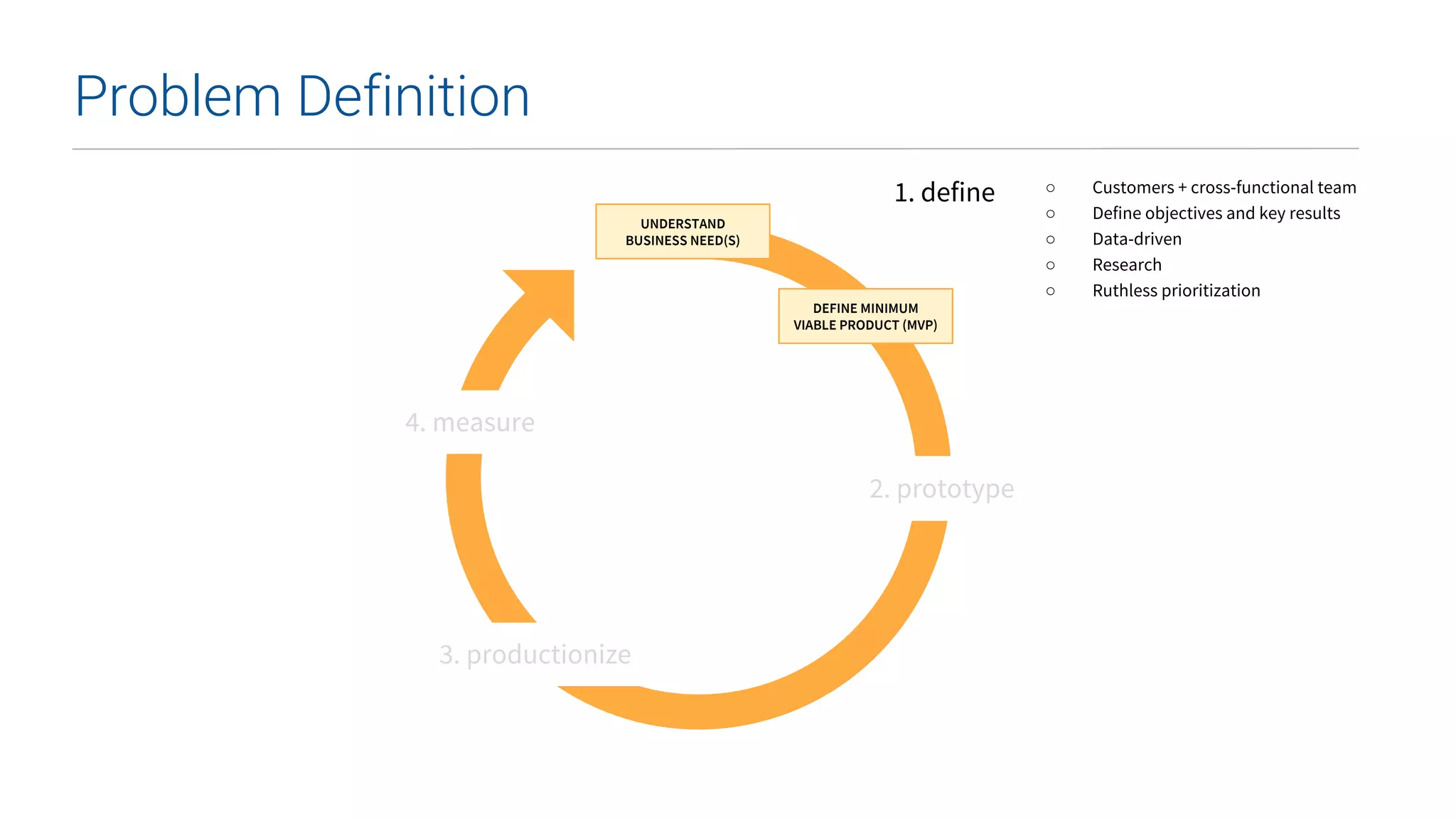
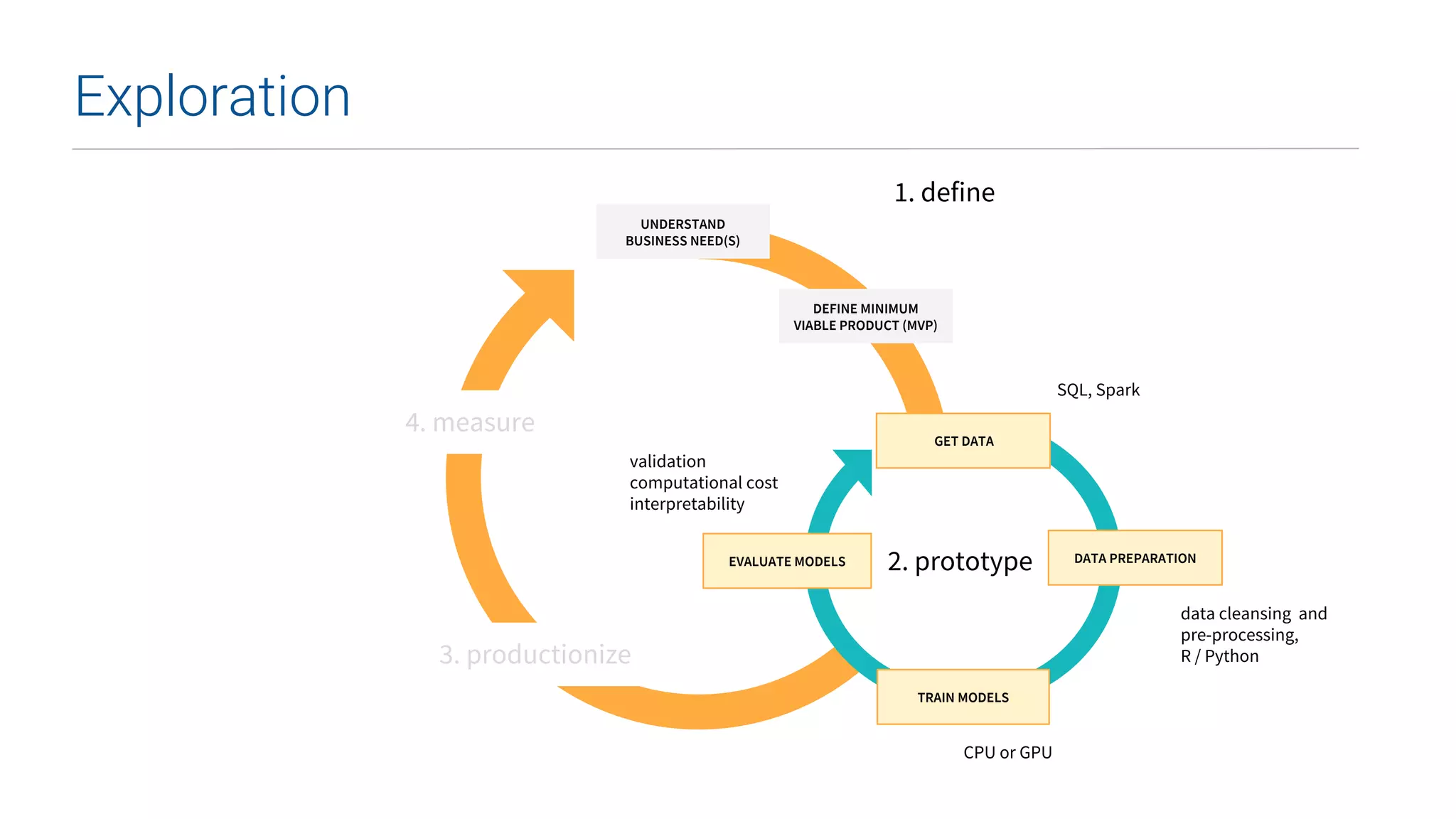
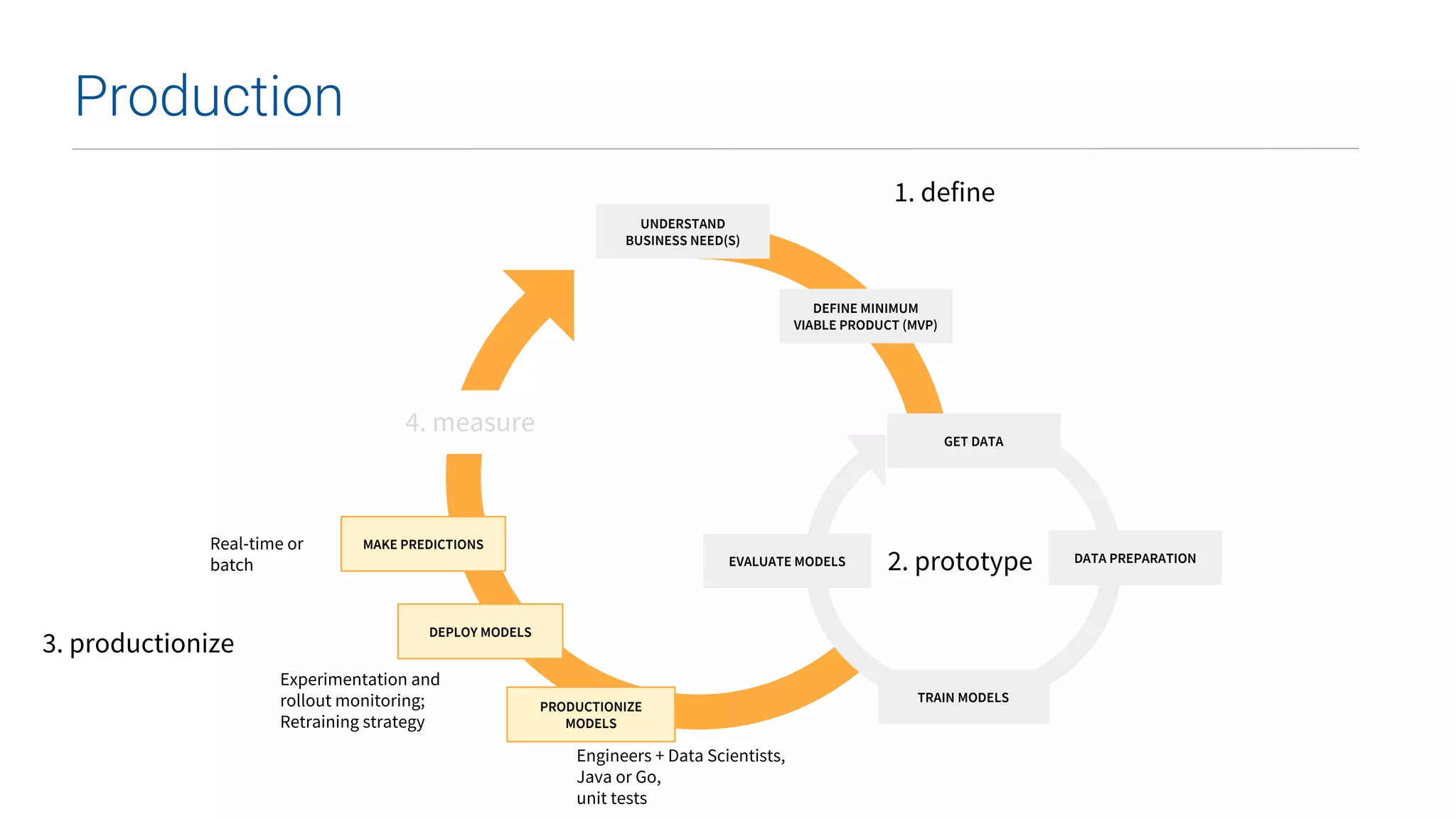
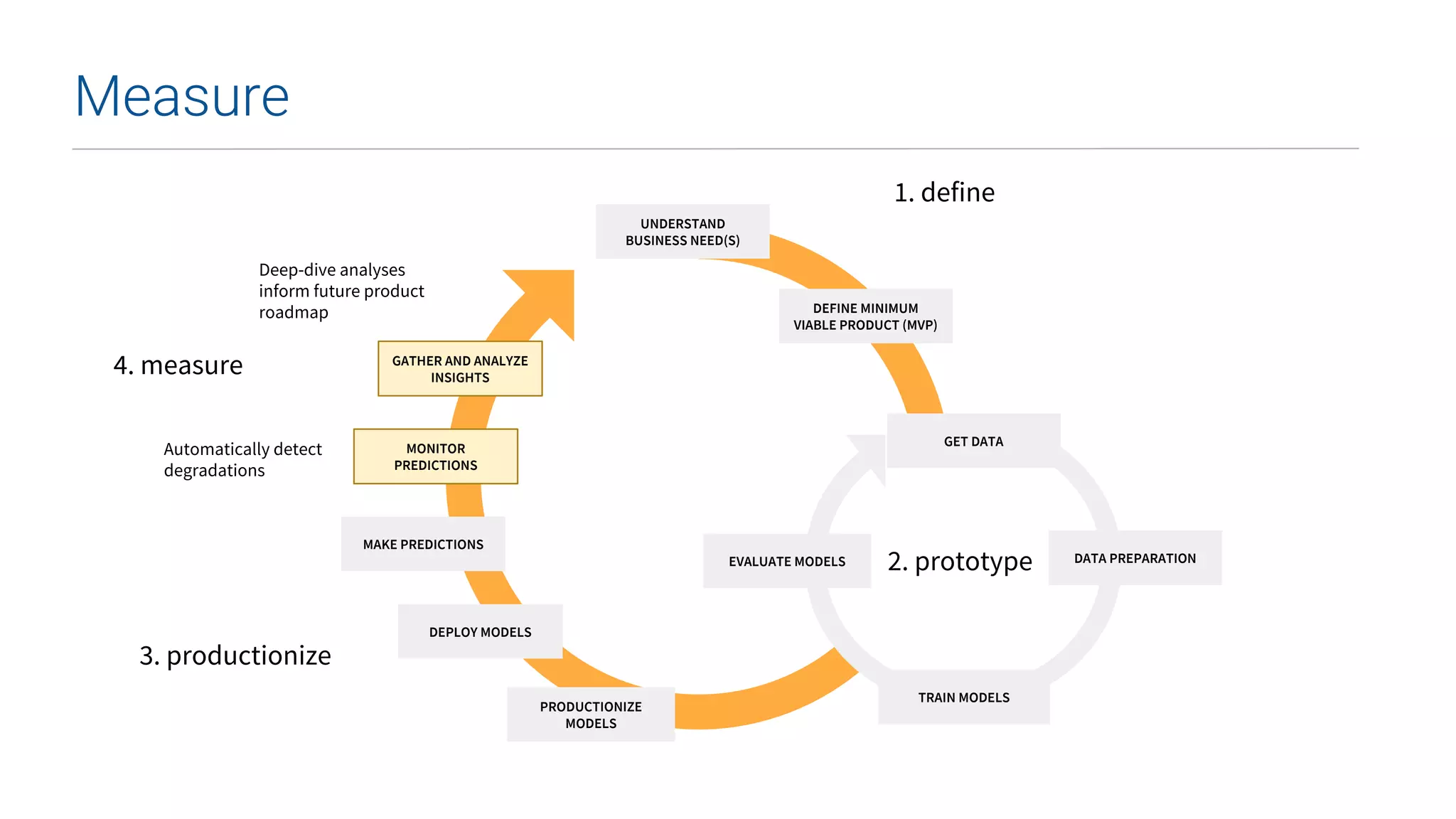


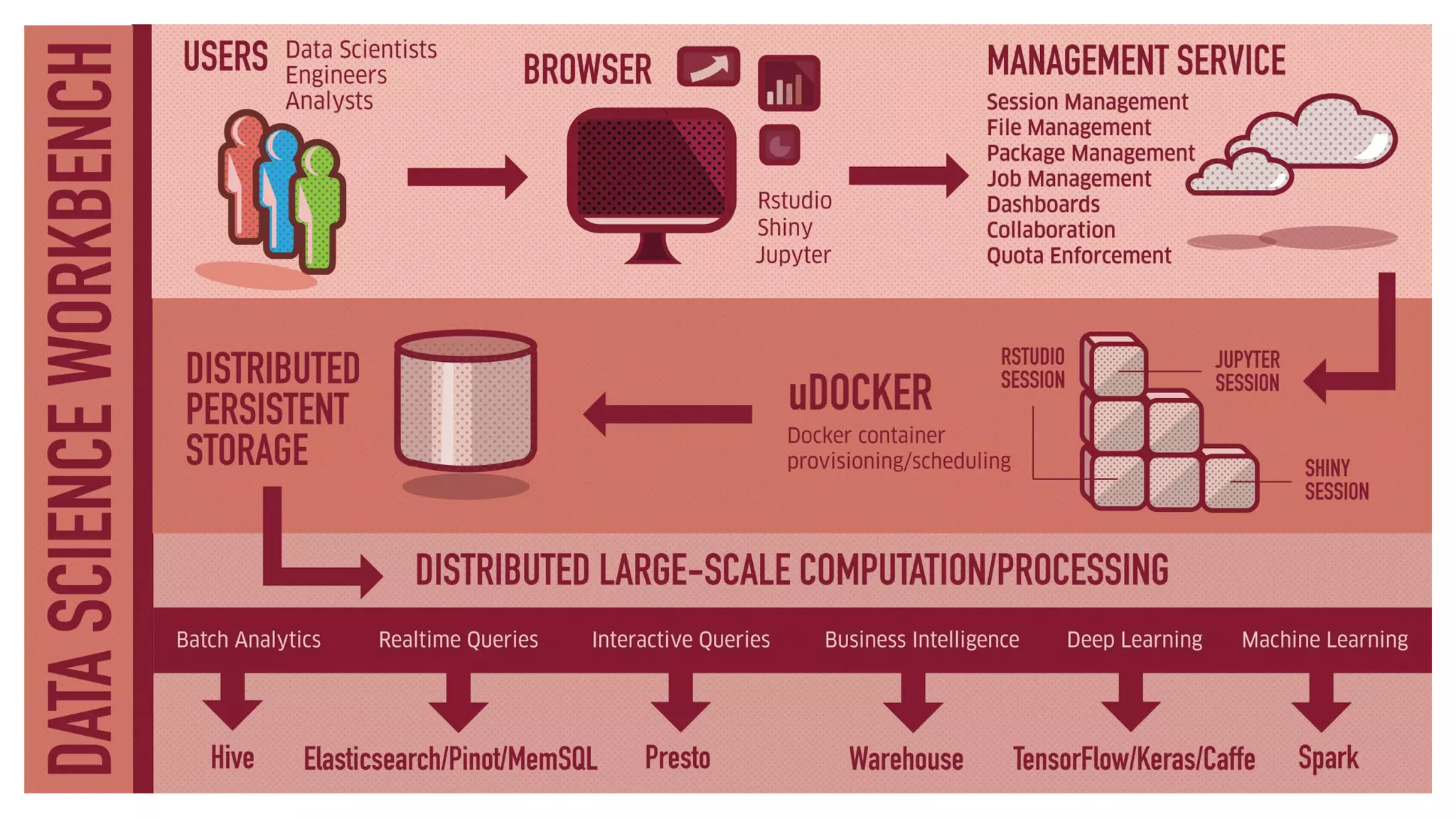


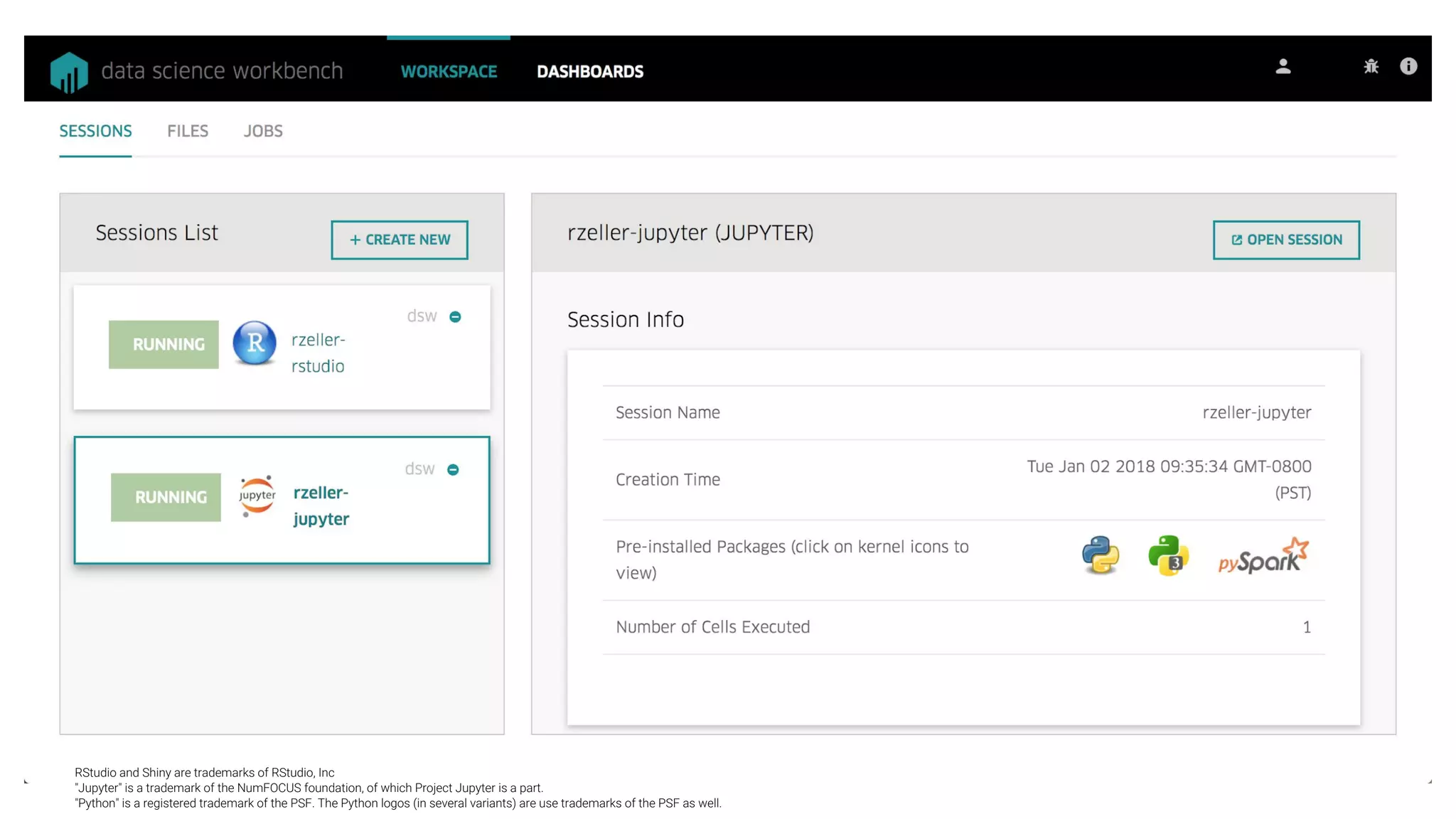
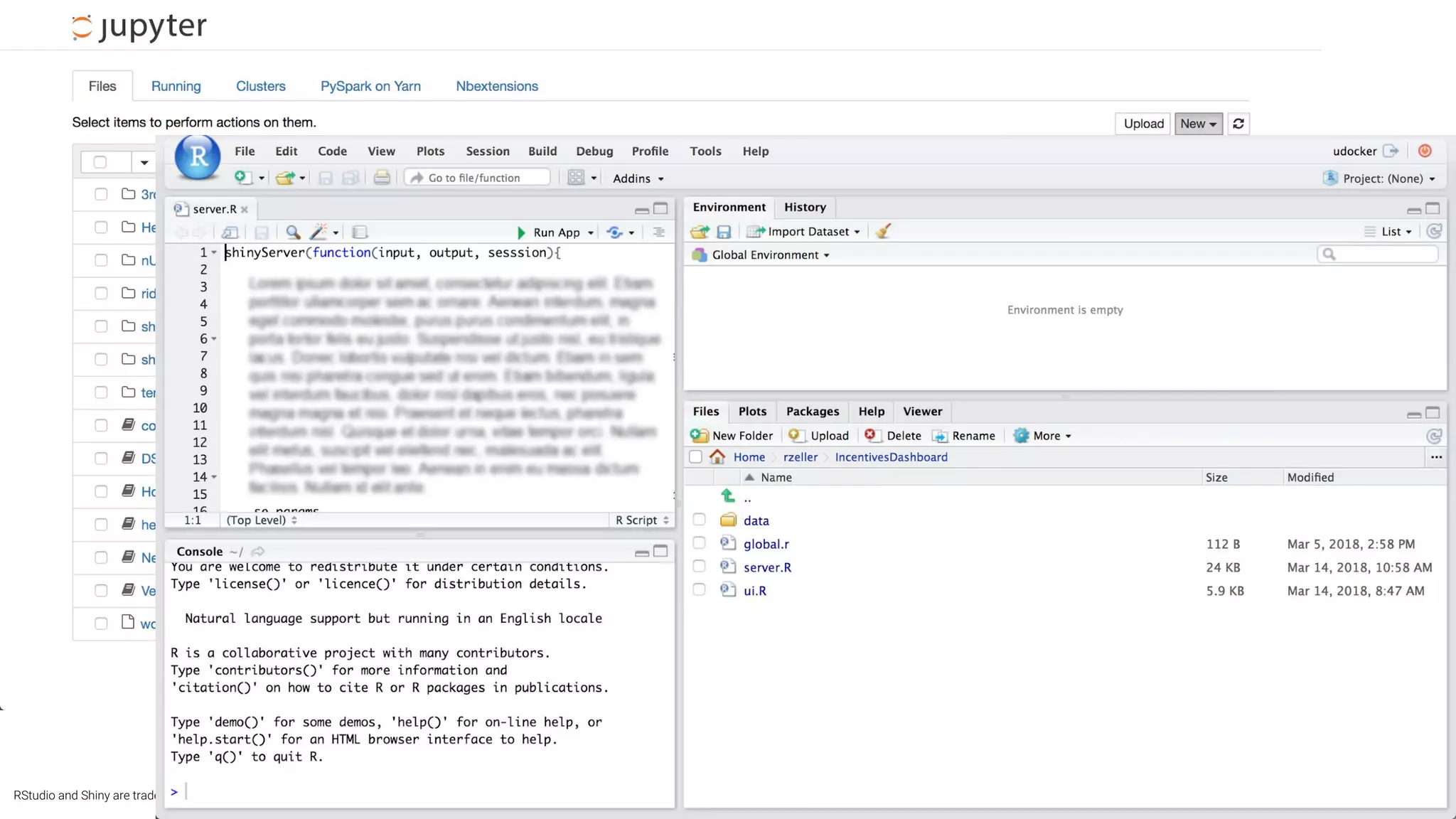
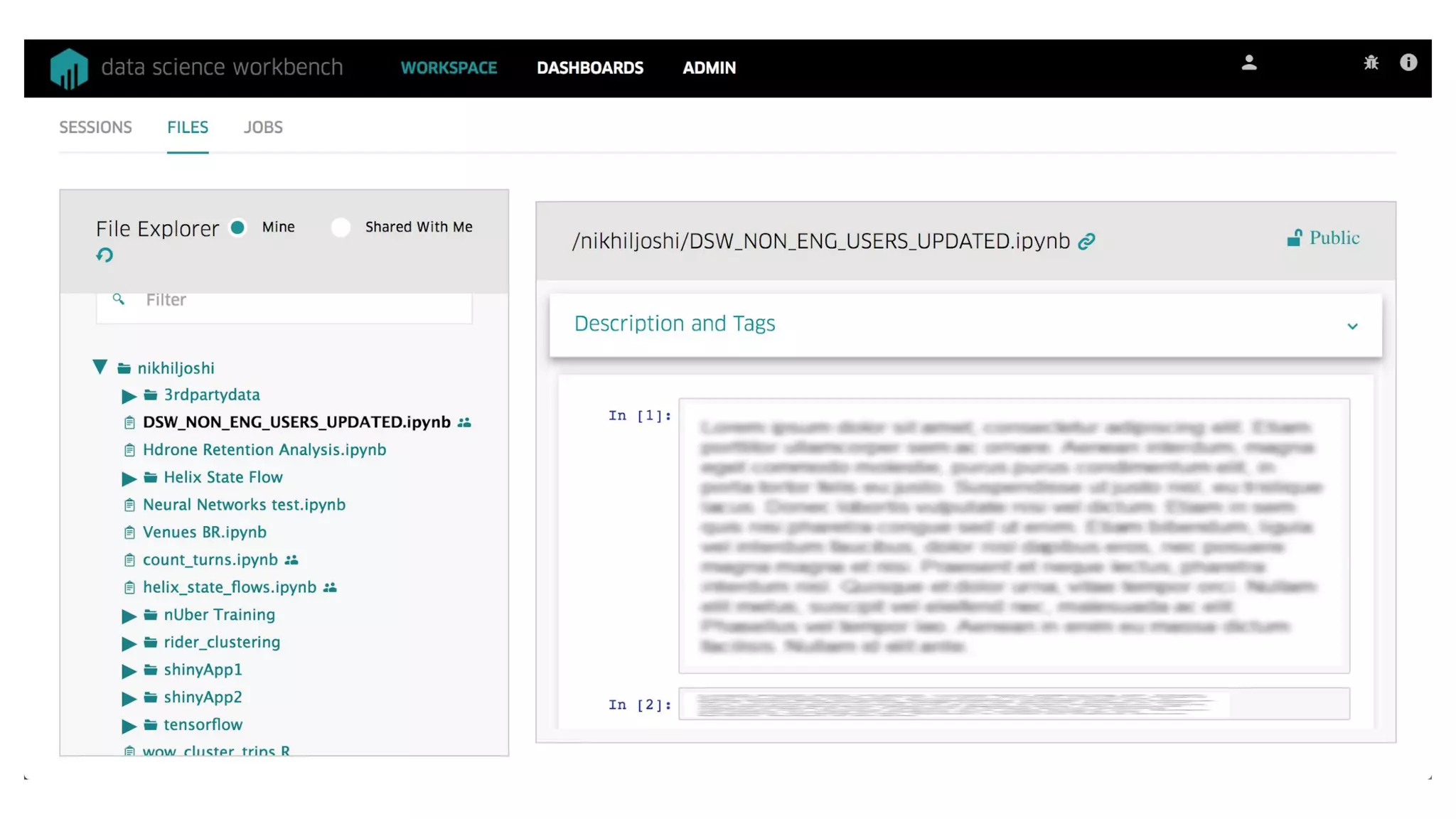
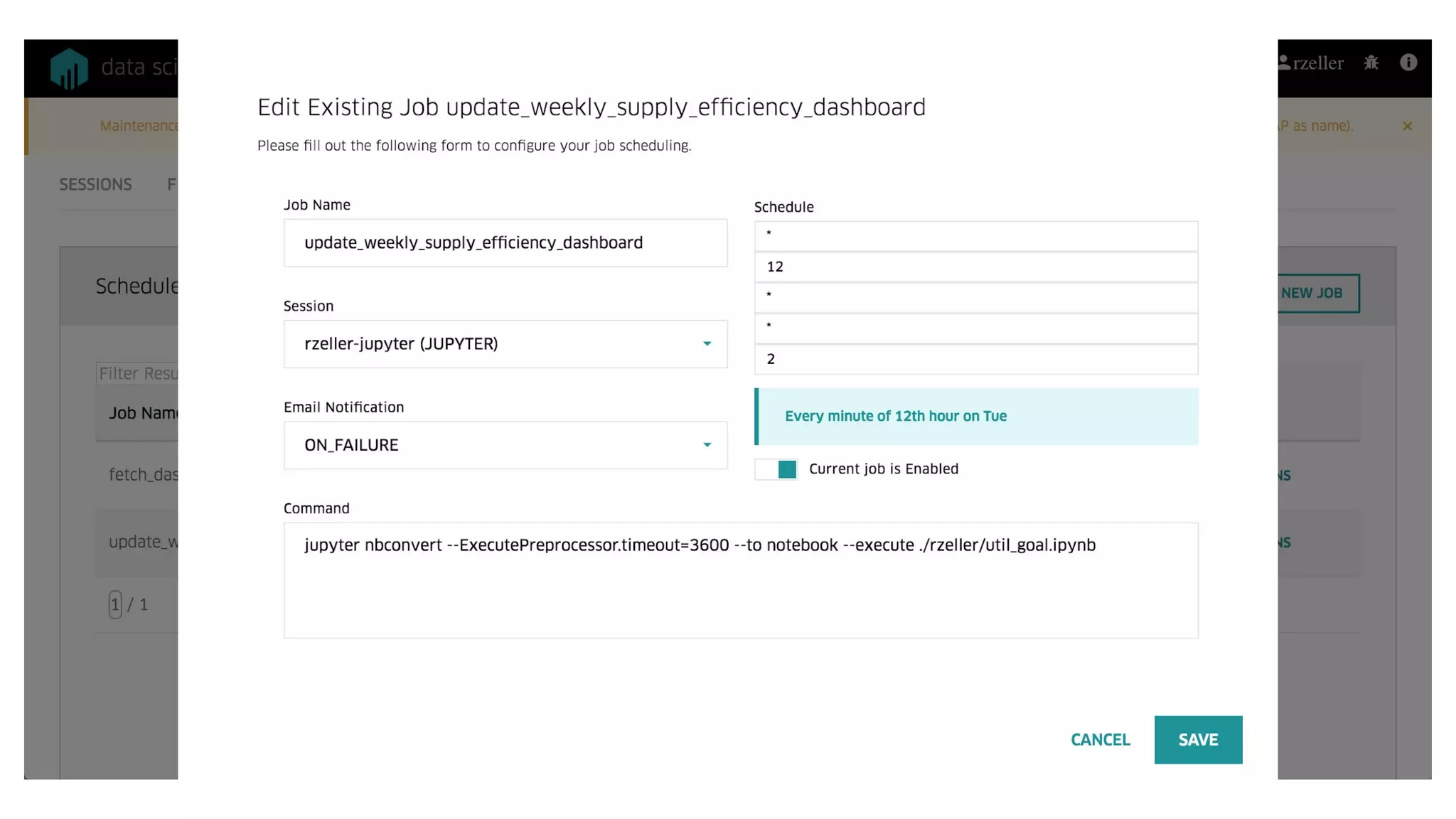
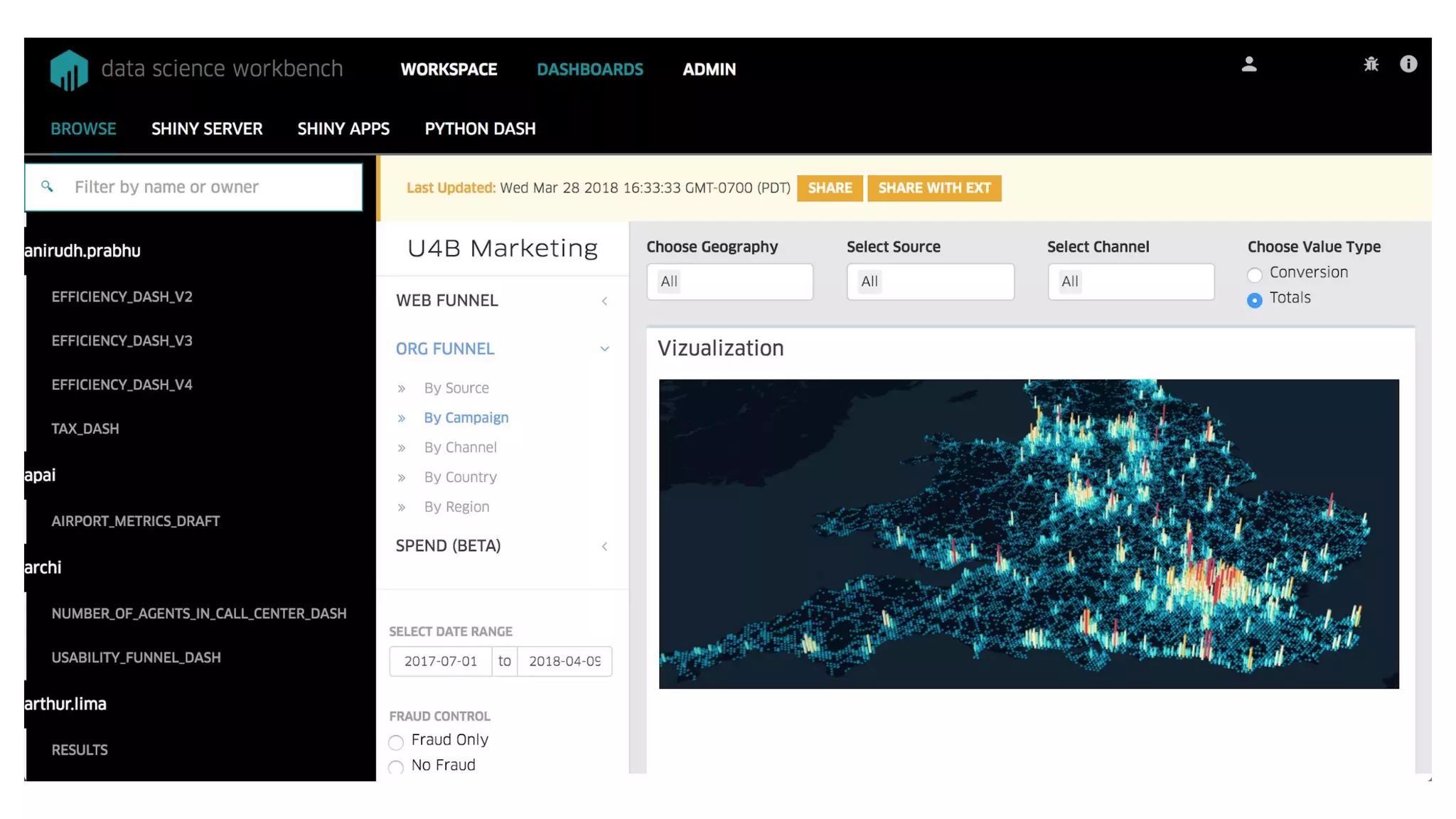

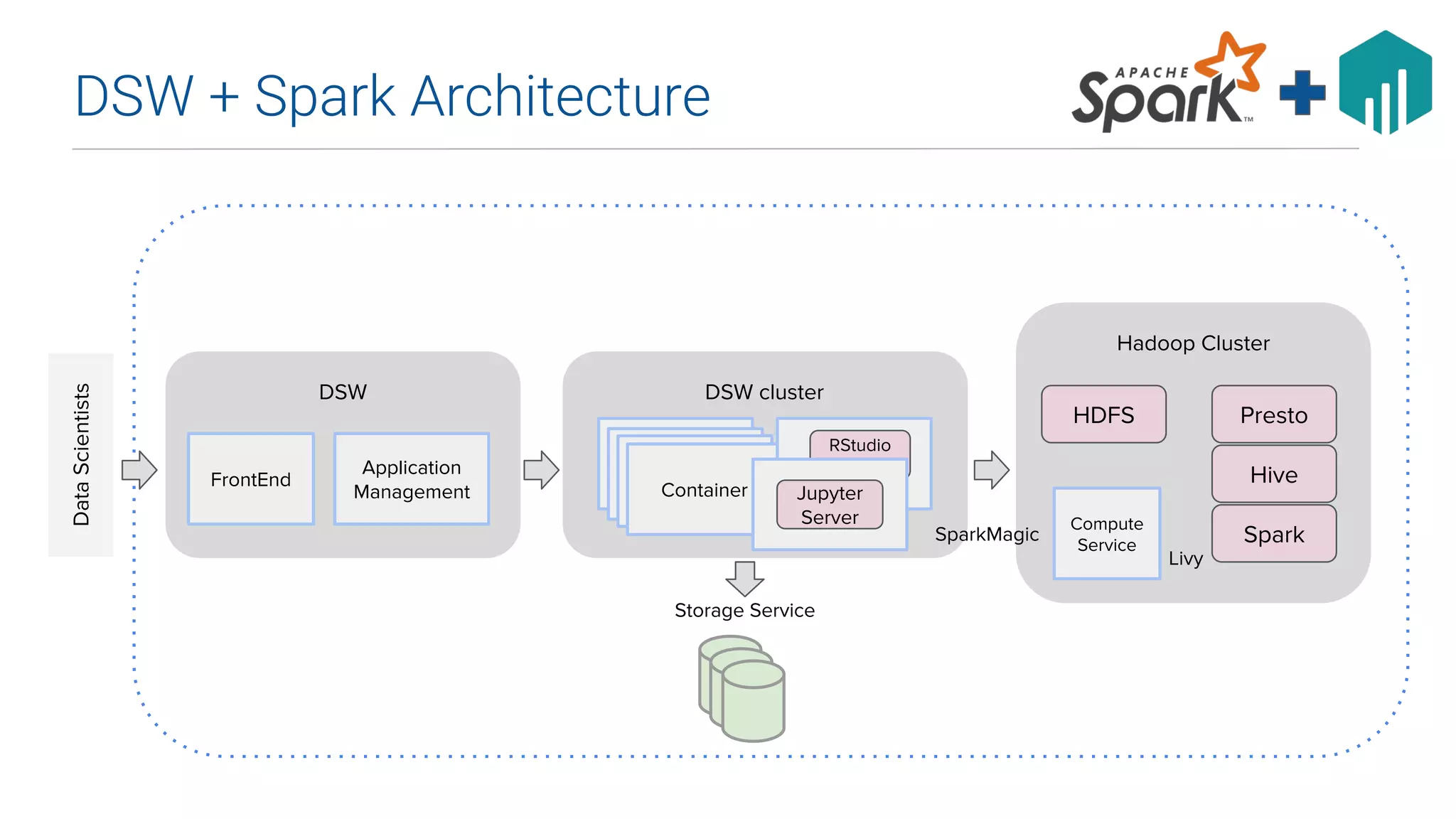

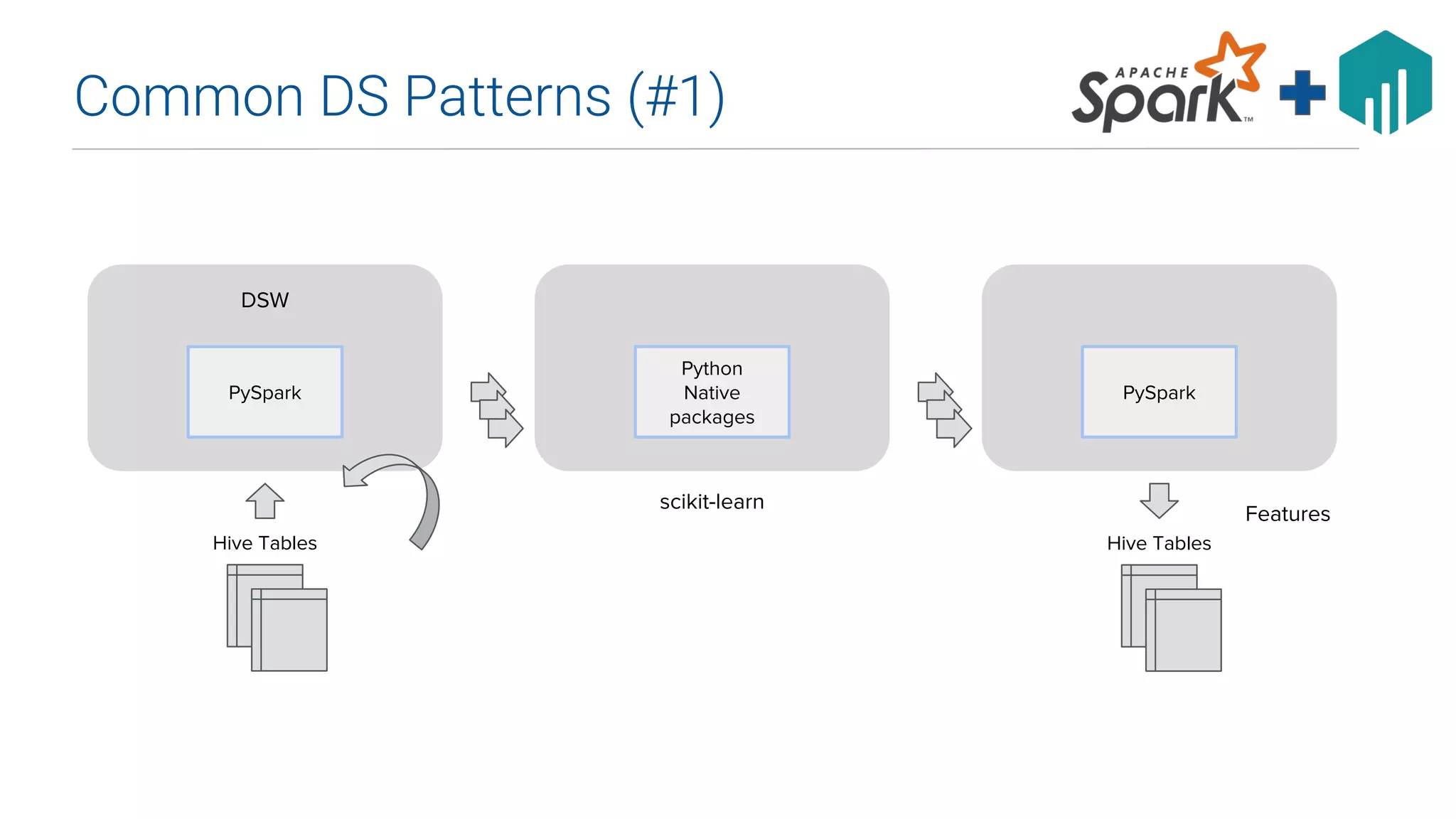






This document summarizes Uber's data science workbench (DSW), which provides scalable infrastructure, tools, customization, and support for Uber's large data science community. The DSW allows data scientists to access internal data sources and compute engines through Jupyter notebooks or RStudio IDEs in a secure, hosted environment. It helps standardize workflows and facilitates collaboration, publishing of results, and model deployment to production. The DSW integrates with Uber's Spark and machine learning systems to enable large-scale data exploration, parallelized model training, and evaluation at Uber's massive scale. It has supported a wide range of use cases across safety, risk, recommendations, and operations.























































































