Download as PDF, PPTX



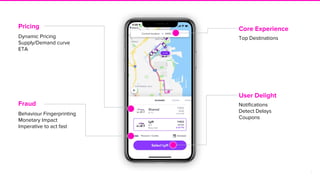




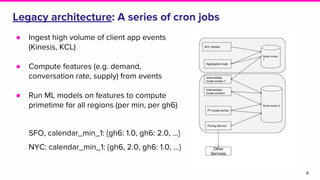


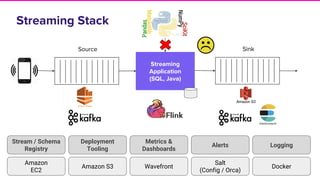

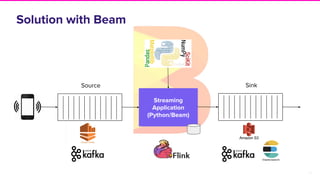

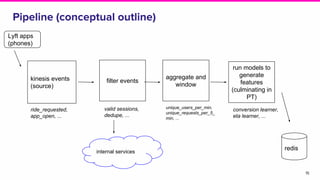



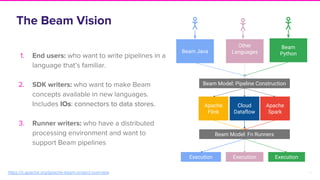


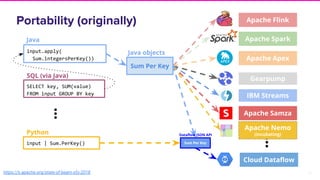
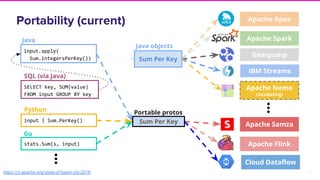

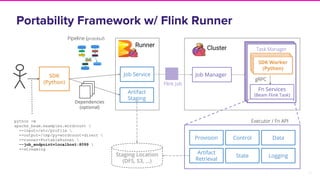

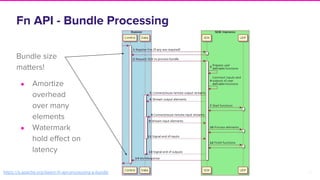

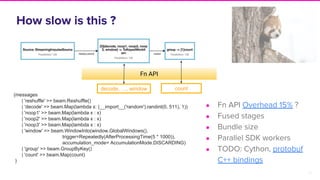







The document discusses Lyft's implementation of dynamic pricing through a streaming data infrastructure leveraging machine learning to enhance pricing efficiency. It details the transition from a legacy pricing system to a streaming-based architecture using technologies such as Apache Flink and Apache Beam, observing significant improvements in latency and code complexity. Key lessons learned highlight the importance of simplicity, monitoring, and efficient managing of dependencies during the upgrade process.


































































