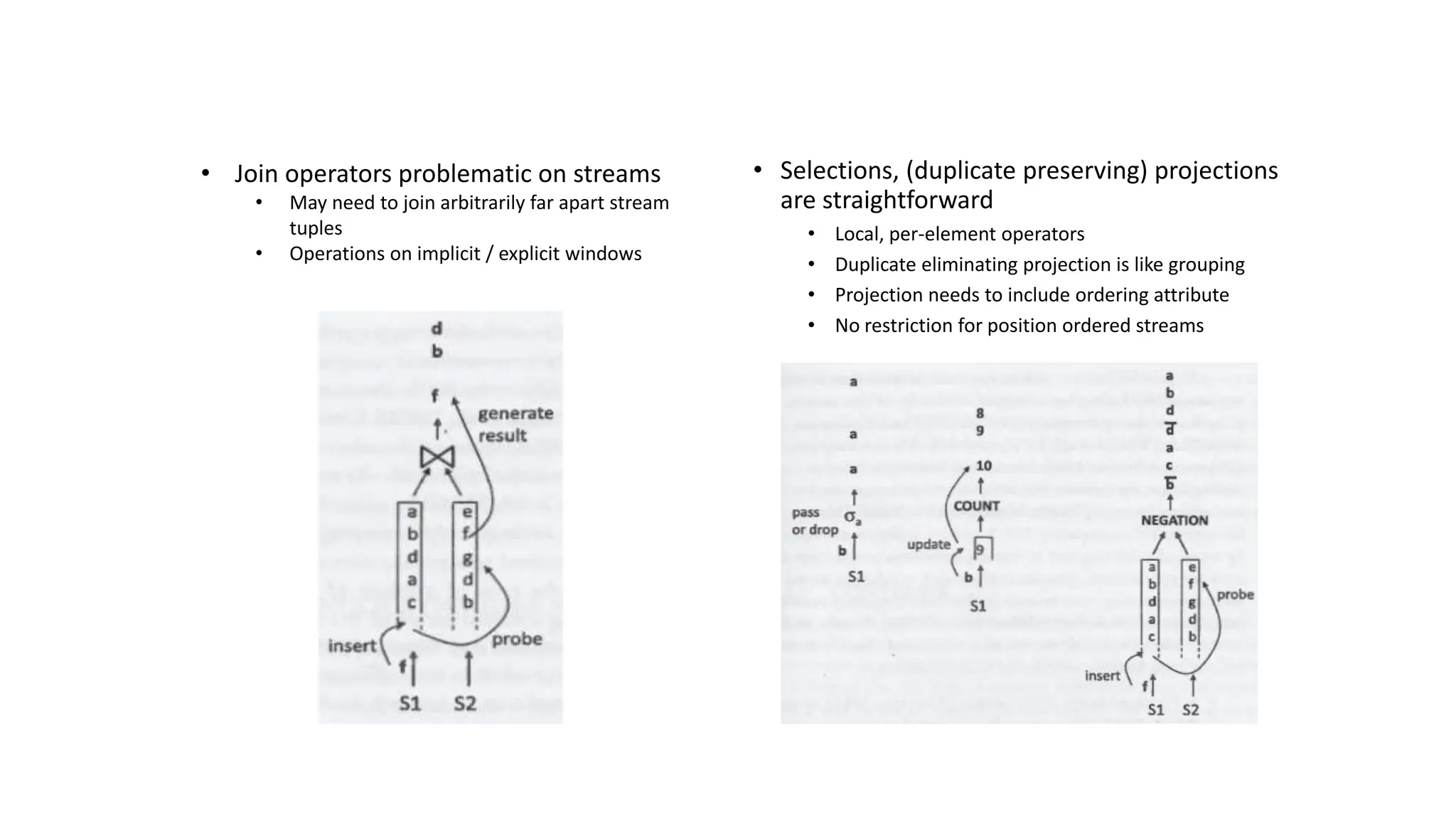
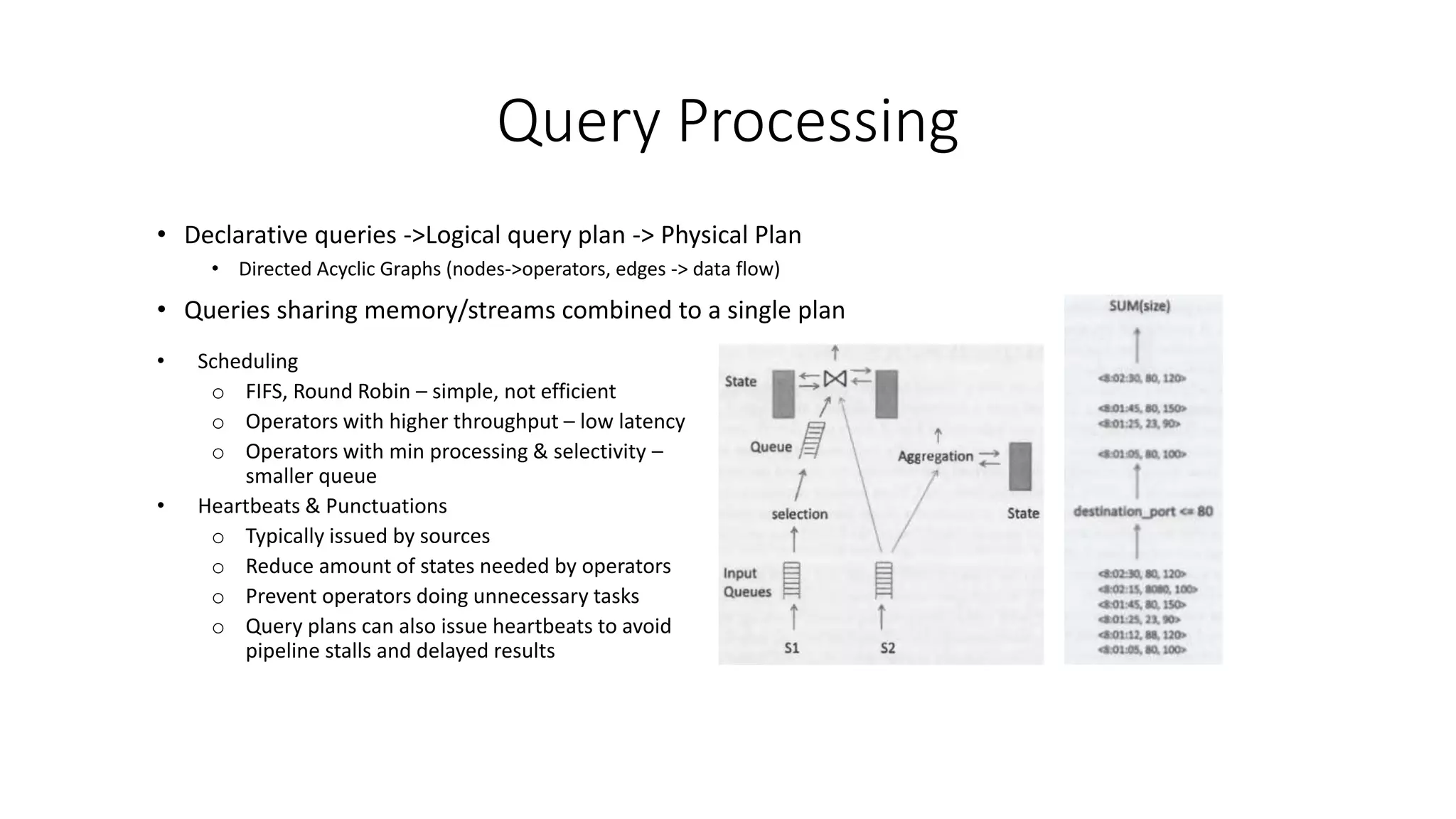
The document outlines concepts related to data stream management systems, including characteristics of streaming data, query processing, and implementing streaming operators. It discusses both blocking and nonblocking query operators and explores load shedding and query approximation methods for handling real-time data processing challenges. The document also references various languages for stream data management and includes techniques for managing query plans and optimizing performance.

























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















