参考文献 I
[1] VolodymyrMnih et al. “Human-level control through deep reinforcement
learning”. In: Nature 518.7540 (2015), pp. 529–533.
[2] Volodymyr Mnih et al. “Playing Atari with Deep Reinforcement Learning”. In:
NIPS 2014 Deep Learning Workshop. 2013, pp. 1–9. arXiv:
arXiv:1312.5602v1.
[3] David Silver et al. “Deterministic Policy Gradient Algorithms”. In: ICML 2014.
2014, pp. 387–395.
[4] Richard S. Sutton et al. “Policy Gradient Methods for Reinforcement Learning
with Function Approximation”. In: In Advances in Neural Information
Processing Systems 12. 1999, pp. 1057–1063.
[5] Pawel Wawrzynski. “Real-time reinforcement learning by sequential
Actor-Critics and experience replay”. In: Neural Networks 22.10 (2009),
pp. 1484–1497.
[6] RJ Williams. “Simple statistical gradient-following algorithms for connectionist
reinforcement learning”. In: Reinforcement Learning 8.3-4 (1992), pp. 229–256.





![問題設定
▶ Markov Decision Process
▶ 状態 st ∈ RNS
▶ 行動 at ∈ RNA
▶ 初期状態分布 s0 ∼ p0(·)
▶ 遷移分布 st+1 ∼ p(·|st, at)
▶ st
at
確率的 st+1
決
▶ 報酬関数 rt = r(st, at, t)(時間依存)
▶ 求
▶ (確率的 )policy at ∼ p(·|st; θ)
▶ st
確率的 at
決
▶ 最大化
▶ 報酬 和 期待値 J(θ) = E[
∑T
t=0 γtrt|θ]
▶ γ ∈ [0, 1] 割引率](https://image.slidesharecdn.com/slides-160120050539/85/Learning-Continuous-Control-Policies-by-Stochastic-Value-Gradients-5-320.jpg)
![価値関数
▶ 状態行動価値関数
Qt
(s, a) = E[
∑
τ=t γτ−t
rτ
|st
= s, at
= a, θ]
▶ 状態価値関数 V t
(s) = E[
∑
τ=t γτ−t
rτ
|st
= s, θ]
▶ (確率的)Bellman 方程式
V (s) = Ea∼p(·|s)[r(s, a) + γEs′∼p(·|s,a)[V ′
(s′
)]]
= Ea∼p(·|s)[Q(s, a)]
▶ ′ 次 時間 表 使](https://image.slidesharecdn.com/slides-160120050539/85/Learning-Continuous-Control-Policies-by-Stochastic-Value-Gradients-6-320.jpg)
![表記 関 注意
▶ 下付 文字 偏微分 表
▶ πθ = ∂π
∂θ
▶ 「 θ 表 π」
▶ ( 1 箇所 πθ 後者 意味 使 場所 …)
▶ 上付 文字 時間 指数
▶ 報酬 和 期待値(再掲) J(θ) = E[
∑T
t=0 γtrt|θ]
▶ rt
時間 t 報酬
▶ γt
γ t 乗
▶ 時間依存 判断 …](https://image.slidesharecdn.com/slides-160120050539/85/Learning-Continuous-Control-Policies-by-Stochastic-Value-Gradients-7-320.jpg)
![行動 連続値
▶ 「DQN 駄目 ?」
▶ DQN [Mnih et al. 2013; Mnih et al. 2015] 状態行動価
値 Q(s, a; θ) 学習 ,行動 arg maxa Q(s, a; θ) 選択
▶ a 連続値 arg max 求 !
▶ policy 直接 (NN )表
▶ at ∼ p(·|st; θ)
▶ 行動 選 際
▶ θ 更新 方法 , 論文 policy
gradient methods 種類 方法 扱](https://image.slidesharecdn.com/slides-160120050539/85/Learning-Continuous-Control-Policies-by-Stochastic-Value-Gradients-8-320.jpg)
![Policy Gradient Methods
▶ 目標:J(θ) = E[
∑T
t=0 γt
rt
|θ] 最大化 policy
θ 求
▶ ∇θJ(θ)(policy gradient) 求
▶ 求 勾配法 policy 最適化 (policy
gradient methods)
▶ 求 ?
▶ likelihood ratio methods
▶ value gradient methods](https://image.slidesharecdn.com/slides-160120050539/85/Learning-Continuous-Control-Policies-by-Stochastic-Value-Gradients-9-320.jpg)
![Likelihood Ratio Methods (1)
▶ 分布 p(y|x) 上 , 関数 g(y) 期待値 勾配
∇x Ep(y|x)g(y) 求
▶ 関数 ∇x log p(y|x) 使
∇x Ep(y|x)g(y) = Ep(y|x)[g(y)∇x log p(y|x)]
≈
1
M
M∑
i=0
g(yi
)∇x log p(yi
|x), yi
∼ p(yi
|x)
▶ ∇θEp(y;θ)g(y) 同様 求
▶ likelihood ratio methods, score function estimators,
REINFORCE 様々 呼](https://image.slidesharecdn.com/slides-160120050539/85/Learning-Continuous-Control-Policies-by-Stochastic-Value-Gradients-10-320.jpg)
![Likelihood Ratio Methods (2)
▶ 使 ∇θJ(θ) 推定
[Williams 1992; Sutton et al. 1999]
∇θJ(θ) = Es∼ρπ,a∼p(·|s;θ)[Q(s, a)∇θ log p(a|s; θ)]
▶ policy gradient 求 方法 広 使
▶ 欠点
▶ Q(s, a) 勾配情報 使
▶ variance 大](https://image.slidesharecdn.com/slides-160120050539/85/Learning-Continuous-Control-Policies-by-Stochastic-Value-Gradients-11-320.jpg)

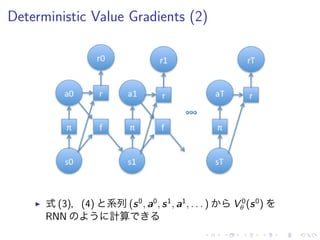


![Stochastic Value Gradients
▶ 遷移分布 s′
= f (s, a, ξ),policy a = π(s, η; θ)
reparameterize
Vs = Eρ(η)[rs + raπs + γEρ(ξ)V ′
s′ (fs + faπs)] (7)
Vθ = Eρ(η)[raπθ + γEρ(ξ)[V ′
s′ faπθ + γV ′
θ]] (8)
= Eρ(η)[Qaπθ + γV ′
θ]
▶ MDP 確率的 ,policy 確率的 ,value
gradient 求 !(stochastic value gradient)](https://image.slidesharecdn.com/slides-160120050539/85/Learning-Continuous-Control-Policies-by-Stochastic-Value-Gradients-16-320.jpg)





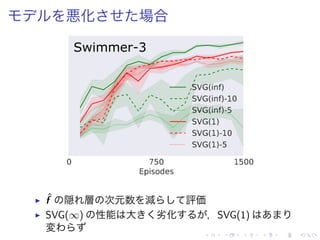
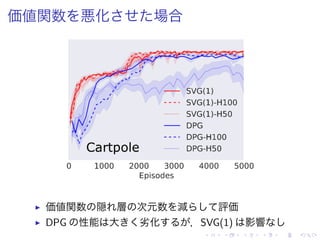
![評価
▶ AC [Wawrzynski 2009],DPG [Silver et al. 2014] 既存
手法( policy value function 学習 )
▶ SVG(1)-ER 総 良](https://image.slidesharecdn.com/slides-160120050539/85/Learning-Continuous-Control-Policies-by-Stochastic-Value-Gradients-22-320.jpg)


![参考文献 I
[1] Volodymyr Mnih et al. “Human-level control through deep reinforcement
learning”. In: Nature 518.7540 (2015), pp. 529–533.
[2] Volodymyr Mnih et al. “Playing Atari with Deep Reinforcement Learning”. In:
NIPS 2014 Deep Learning Workshop. 2013, pp. 1–9. arXiv:
arXiv:1312.5602v1.
[3] David Silver et al. “Deterministic Policy Gradient Algorithms”. In: ICML 2014.
2014, pp. 387–395.
[4] Richard S. Sutton et al. “Policy Gradient Methods for Reinforcement Learning
with Function Approximation”. In: In Advances in Neural Information
Processing Systems 12. 1999, pp. 1057–1063.
[5] Pawel Wawrzynski. “Real-time reinforcement learning by sequential
Actor-Critics and experience replay”. In: Neural Networks 22.10 (2009),
pp. 1484–1497.
[6] RJ Williams. “Simple statistical gradient-following algorithms for connectionist
reinforcement learning”. In: Reinforcement Learning 8.3-4 (1992), pp. 229–256.](https://image.slidesharecdn.com/slides-160120050539/85/Learning-Continuous-Control-Policies-by-Stochastic-Value-Gradients-27-320.jpg)
![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]What Matters In On-Policy Reinforcement Learning? A Large-Scale Empiri...](https://cdn.slidesharecdn.com/ss_thumbnails/20200619misono-200630053718-thumbnail.jpg?width=640&height=640&fit=bounds)

















