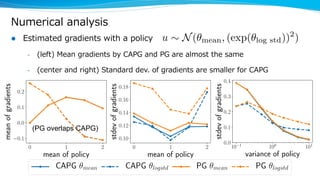
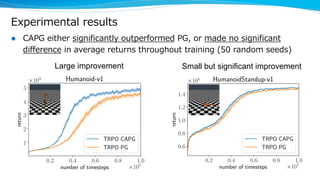
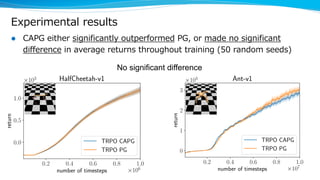
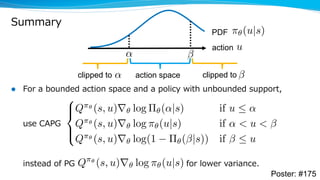
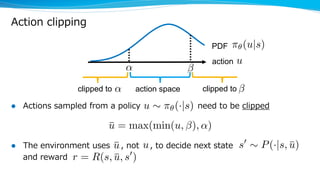
The document discusses a variance reduction technique called clipped action policy gradient for policy gradient methods with bounded action spaces. Policy gradient methods typically use policies with unbounded support even when the action space is bounded, which can lead to a mismatch. This technique clips actions to the bounds of the action space in order to reduce the variance of policy gradient estimates.


![Mismatch between action space and policy
l Policy gradient with continuous actions
– the action space is bounded (ex. ,)
– but, a policy to optimize has unbounded support (ex. Gaussian)
action space
⇡✓(u|s)<latexit sha1_base64="hNsGvK+TMjKv1OqYlg5W0s5xIXU=">AAAHinicjZXbbtQwEIbDcctyKnDJTURViYP2kApEAVUqBSS4QaWlBalZVY4zu4nWsVPb6UEmT8ItPBRvwzgbaDdxBZYiTcb/Z4/H9jjKWar0cPjrwsVLl69c7Sxc616/cfPW7cU7d3eVKCSFHSqYkF8jooClHHZ0qhl8zSWQLGLwJZq+sf1fDkGqVPDP+iSHUUYmPB2nlGh07S/eDvN0P9QJaPKw+KYe7S8uDfvDqvltI6iNJa9um/t3rtIwFrTIgGvKiFJ7wTDXI0OkTimDshsWCnJCp2QCe2hykoEamSry0l9GT+yPhcSPa7/yniUMyZQ6ySJUZkQnqtlnna6+vUKPV0cm5XmhgdPZROOC+Vr4Ng1+nEqgmp2gQahMMVafJkQSqjFZc7PEyoaGI/gYO6ZV+aGdLoqyORlN+CRHY27Bxiq1EEzNuyMhpppE6O2GfyUKtFGJOBKcnUgYqzUtC7AKDkdUZBnh8WMTMnFUmhC4KiRY1ISE5Qkpy4YuSSdJQxjhJrd07xqi2drMu7Kl3CXSrd11aP9b+UYcOrQyM7ajpd7WRINyAJQws416H/dJWZGvMNnQwF9Te+rP43dqnlQq5wBb7nVt1STePNYgPrqJjzXBiS5kCyJykpFjd17qvlZqKEtzN1H1tPR5Wt36ecScloM2sSEksHNyt9GWwwGeS65F1kBqrzHlmikdcbFC/Qt84gI/OEKLlQnqTKc8tlXPlpqCVzvcTCDJJ7lKm5eGSJwZ3c6E5xDnbuJ8YNMJbDqAGMZw0BAfUltosU7yNdR3l/2MTMEPD4Ga0o8Ei7shA23/Z0dt3J05ZueuTorlcISJb+dGO9E6Vy8HAw3Hfbw9dArHWA35BPoYzOCgAFXdm8HKSjAcDvB49JDrYZA9gY+LfXt6ddRYOyWcLqJaXLkXjHA7piA5viDPsiL8Q9XeXuVdCs7+lWeBEp+loPkItY3dlX4w7Aefni6tr9YP1IJ333vgPfQC77m37r33Nr0dj3qF99374f3s3OisdF50Xs2kFy/UzD1vrnXe/gbgSMFJ</latexit><latexit sha1_base64="hNsGvK+TMjKv1OqYlg5W0s5xIXU=">AAAHinicjZXbbtQwEIbDcctyKnDJTURViYP2kApEAVUqBSS4QaWlBalZVY4zu4nWsVPb6UEmT8ItPBRvwzgbaDdxBZYiTcb/Z4/H9jjKWar0cPjrwsVLl69c7Sxc616/cfPW7cU7d3eVKCSFHSqYkF8jooClHHZ0qhl8zSWQLGLwJZq+sf1fDkGqVPDP+iSHUUYmPB2nlGh07S/eDvN0P9QJaPKw+KYe7S8uDfvDqvltI6iNJa9um/t3rtIwFrTIgGvKiFJ7wTDXI0OkTimDshsWCnJCp2QCe2hykoEamSry0l9GT+yPhcSPa7/yniUMyZQ6ySJUZkQnqtlnna6+vUKPV0cm5XmhgdPZROOC+Vr4Ng1+nEqgmp2gQahMMVafJkQSqjFZc7PEyoaGI/gYO6ZV+aGdLoqyORlN+CRHY27Bxiq1EEzNuyMhpppE6O2GfyUKtFGJOBKcnUgYqzUtC7AKDkdUZBnh8WMTMnFUmhC4KiRY1ISE5Qkpy4YuSSdJQxjhJrd07xqi2drMu7Kl3CXSrd11aP9b+UYcOrQyM7ajpd7WRINyAJQws416H/dJWZGvMNnQwF9Te+rP43dqnlQq5wBb7nVt1STePNYgPrqJjzXBiS5kCyJykpFjd17qvlZqKEtzN1H1tPR5Wt36ecScloM2sSEksHNyt9GWwwGeS65F1kBqrzHlmikdcbFC/Qt84gI/OEKLlQnqTKc8tlXPlpqCVzvcTCDJJ7lKm5eGSJwZ3c6E5xDnbuJ8YNMJbDqAGMZw0BAfUltosU7yNdR3l/2MTMEPD4Ga0o8Ei7shA23/Z0dt3J05ZueuTorlcISJb+dGO9E6Vy8HAw3Hfbw9dArHWA35BPoYzOCgAFXdm8HKSjAcDvB49JDrYZA9gY+LfXt6ddRYOyWcLqJaXLkXjHA7piA5viDPsiL8Q9XeXuVdCs7+lWeBEp+loPkItY3dlX4w7Aefni6tr9YP1IJ333vgPfQC77m37r33Nr0dj3qF99374f3s3OisdF50Xs2kFy/UzD1vrnXe/gbgSMFJ</latexit><latexit sha1_base64="hNsGvK+TMjKv1OqYlg5W0s5xIXU=">AAAHinicjZXbbtQwEIbDcctyKnDJTURViYP2kApEAVUqBSS4QaWlBalZVY4zu4nWsVPb6UEmT8ItPBRvwzgbaDdxBZYiTcb/Z4/H9jjKWar0cPjrwsVLl69c7Sxc616/cfPW7cU7d3eVKCSFHSqYkF8jooClHHZ0qhl8zSWQLGLwJZq+sf1fDkGqVPDP+iSHUUYmPB2nlGh07S/eDvN0P9QJaPKw+KYe7S8uDfvDqvltI6iNJa9um/t3rtIwFrTIgGvKiFJ7wTDXI0OkTimDshsWCnJCp2QCe2hykoEamSry0l9GT+yPhcSPa7/yniUMyZQ6ySJUZkQnqtlnna6+vUKPV0cm5XmhgdPZROOC+Vr4Ng1+nEqgmp2gQahMMVafJkQSqjFZc7PEyoaGI/gYO6ZV+aGdLoqyORlN+CRHY27Bxiq1EEzNuyMhpppE6O2GfyUKtFGJOBKcnUgYqzUtC7AKDkdUZBnh8WMTMnFUmhC4KiRY1ISE5Qkpy4YuSSdJQxjhJrd07xqi2drMu7Kl3CXSrd11aP9b+UYcOrQyM7ajpd7WRINyAJQws416H/dJWZGvMNnQwF9Te+rP43dqnlQq5wBb7nVt1STePNYgPrqJjzXBiS5kCyJykpFjd17qvlZqKEtzN1H1tPR5Wt36ecScloM2sSEksHNyt9GWwwGeS65F1kBqrzHlmikdcbFC/Qt84gI/OEKLlQnqTKc8tlXPlpqCVzvcTCDJJ7lKm5eGSJwZ3c6E5xDnbuJ8YNMJbDqAGMZw0BAfUltosU7yNdR3l/2MTMEPD4Ga0o8Ei7shA23/Z0dt3J05ZueuTorlcISJb+dGO9E6Vy8HAw3Hfbw9dArHWA35BPoYzOCgAFXdm8HKSjAcDvB49JDrYZA9gY+LfXt6ddRYOyWcLqJaXLkXjHA7piA5viDPsiL8Q9XeXuVdCs7+lWeBEp+loPkItY3dlX4w7Aefni6tr9YP1IJ333vgPfQC77m37r33Nr0dj3qF99374f3s3OisdF50Xs2kFy/UzD1vrnXe/gbgSMFJ</latexit><latexit sha1_base64="hNsGvK+TMjKv1OqYlg5W0s5xIXU=">AAAHinicjZXbbtQwEIbDcctyKnDJTURViYP2kApEAVUqBSS4QaWlBalZVY4zu4nWsVPb6UEmT8ItPBRvwzgbaDdxBZYiTcb/Z4/H9jjKWar0cPjrwsVLl69c7Sxc616/cfPW7cU7d3eVKCSFHSqYkF8jooClHHZ0qhl8zSWQLGLwJZq+sf1fDkGqVPDP+iSHUUYmPB2nlGh07S/eDvN0P9QJaPKw+KYe7S8uDfvDqvltI6iNJa9um/t3rtIwFrTIgGvKiFJ7wTDXI0OkTimDshsWCnJCp2QCe2hykoEamSry0l9GT+yPhcSPa7/yniUMyZQ6ySJUZkQnqtlnna6+vUKPV0cm5XmhgdPZROOC+Vr4Ng1+nEqgmp2gQahMMVafJkQSqjFZc7PEyoaGI/gYO6ZV+aGdLoqyORlN+CRHY27Bxiq1EEzNuyMhpppE6O2GfyUKtFGJOBKcnUgYqzUtC7AKDkdUZBnh8WMTMnFUmhC4KiRY1ISE5Qkpy4YuSSdJQxjhJrd07xqi2drMu7Kl3CXSrd11aP9b+UYcOrQyM7ajpd7WRINyAJQws416H/dJWZGvMNnQwF9Te+rP43dqnlQq5wBb7nVt1STePNYgPrqJjzXBiS5kCyJykpFjd17qvlZqKEtzN1H1tPR5Wt36ecScloM2sSEksHNyt9GWwwGeS65F1kBqrzHlmikdcbFC/Qt84gI/OEKLlQnqTKc8tlXPlpqCVzvcTCDJJ7lKm5eGSJwZ3c6E5xDnbuJ8YNMJbDqAGMZw0BAfUltosU7yNdR3l/2MTMEPD4Ga0o8Ei7shA23/Z0dt3J05ZueuTorlcISJb+dGO9E6Vy8HAw3Hfbw9dArHWA35BPoYzOCgAFXdm8HKSjAcDvB49JDrYZA9gY+LfXt6ddRYOyWcLqJaXLkXjHA7piA5viDPsiL8Q9XeXuVdCs7+lWeBEp+loPkItY3dlX4w7Aefni6tr9YP1IJ333vgPfQC77m37r33Nr0dj3qF99374f3s3OisdF50Xs2kFy/UzD1vrnXe/gbgSMFJ</latexit>
PDF
action u<latexit sha1_base64="m83+VgcK88NknGpfy90zJR76HqQ=">AAAHenicjZXbbtQwEIZDgW5ZTgUuuYmoKnHQHlKBqJAqlSIkuKnaQkulZlU5zuwmWsdObacHWXkCbuHheBcuGGcDdBNXYCnSZOb/7PH4FOUsVXo4/HFt4fqNm4udpVvd23fu3ru//ODhgRKFpLBPBRPyMCIKWMphX6eawWEugWQRgy/R9J2NfzkFqVLBP+uLHEYZmfB0nFKi0bVbHC+vDPvDqvltI6iNFa9uO8cPFmkYC1pkwDVlRKmjYJjrkSFSp5RB2Q0LBTmhUzKBIzQ5yUCNTJVp6a+iJ/bHQuLHtV95LxOGZEpdZBEqM6IT1YxZpyt2VOjx+sikPC80cDobaFwwXwvfTtuPUwlUsws0CJUp5urThEhCNRZnbpRY2dSwBx9zxzIqP7TDRVE2J6MJn+RozE3YWKUWgql5dyTEVJMIvd3wj0SBNioRZ4KzCwljtaFlAVbB4YyKLCM8fm5CJs5KEwJXhQSLmpCwPCFl2dAl6SRpCCPQbd37hmg2N/O+bCkPiHRrDxza/1a+E6cOrcyMDbTUnzTRoBwAJcx8Qr2P66SsyFdYbGjgb6nd5Vfx+zVPKpWzgz33vPZqEk8aaxDbbmK7JjjRhWxBRE4ycu6uSx1rlYayNHcTVaSlz1Od2A0xh1j3cTgLtIgtIYFdUbutthxOcF9yLbIGUnuNKTdM6ciLFepf4AsX+NGRWqxMUFc65bG95exVU/BqhZsFJPkkV2nz0BCJI6PbWfAc4txNXA3sOIEdBxDDGE4a4lNqL1q8J/kG6rurfkam4IenQE3pR4LF3ZCBtv+zrTbuzhyzfVcXxXLYw8S3Y6OdaJ2rN4OBhvM+nh46hXO8DfkE+pjM4KQAVZ2bwdpaMBwOcHv0kOthkj2Bj4l9a3p11nh3Svg7iWpy5VEwwuWYguT4grzKivA3VXt7lXcluPxXXgZKfJaC5iPUNg7W+sGwH+y+XNlcrx+oJe+x98R76gXea2/T++DtePse9cD76n3zvi/+7DzpPOu8mEkXrtXMI2+udV7+AgXIvEU=</latexit><latexit sha1_base64="m83+VgcK88NknGpfy90zJR76HqQ=">AAAHenicjZXbbtQwEIZDgW5ZTgUuuYmoKnHQHlKBqJAqlSIkuKnaQkulZlU5zuwmWsdObacHWXkCbuHheBcuGGcDdBNXYCnSZOb/7PH4FOUsVXo4/HFt4fqNm4udpVvd23fu3ru//ODhgRKFpLBPBRPyMCIKWMphX6eawWEugWQRgy/R9J2NfzkFqVLBP+uLHEYZmfB0nFKi0bVbHC+vDPvDqvltI6iNFa9uO8cPFmkYC1pkwDVlRKmjYJjrkSFSp5RB2Q0LBTmhUzKBIzQ5yUCNTJVp6a+iJ/bHQuLHtV95LxOGZEpdZBEqM6IT1YxZpyt2VOjx+sikPC80cDobaFwwXwvfTtuPUwlUsws0CJUp5urThEhCNRZnbpRY2dSwBx9zxzIqP7TDRVE2J6MJn+RozE3YWKUWgql5dyTEVJMIvd3wj0SBNioRZ4KzCwljtaFlAVbB4YyKLCM8fm5CJs5KEwJXhQSLmpCwPCFl2dAl6SRpCCPQbd37hmg2N/O+bCkPiHRrDxza/1a+E6cOrcyMDbTUnzTRoBwAJcx8Qr2P66SsyFdYbGjgb6nd5Vfx+zVPKpWzgz33vPZqEk8aaxDbbmK7JjjRhWxBRE4ycu6uSx1rlYayNHcTVaSlz1Od2A0xh1j3cTgLtIgtIYFdUbutthxOcF9yLbIGUnuNKTdM6ciLFepf4AsX+NGRWqxMUFc65bG95exVU/BqhZsFJPkkV2nz0BCJI6PbWfAc4txNXA3sOIEdBxDDGE4a4lNqL1q8J/kG6rurfkam4IenQE3pR4LF3ZCBtv+zrTbuzhyzfVcXxXLYw8S3Y6OdaJ2rN4OBhvM+nh46hXO8DfkE+pjM4KQAVZ2bwdpaMBwOcHv0kOthkj2Bj4l9a3p11nh3Svg7iWpy5VEwwuWYguT4grzKivA3VXt7lXcluPxXXgZKfJaC5iPUNg7W+sGwH+y+XNlcrx+oJe+x98R76gXea2/T++DtePse9cD76n3zvi/+7DzpPOu8mEkXrtXMI2+udV7+AgXIvEU=</latexit><latexit sha1_base64="m83+VgcK88NknGpfy90zJR76HqQ=">AAAHenicjZXbbtQwEIZDgW5ZTgUuuYmoKnHQHlKBqJAqlSIkuKnaQkulZlU5zuwmWsdObacHWXkCbuHheBcuGGcDdBNXYCnSZOb/7PH4FOUsVXo4/HFt4fqNm4udpVvd23fu3ru//ODhgRKFpLBPBRPyMCIKWMphX6eawWEugWQRgy/R9J2NfzkFqVLBP+uLHEYZmfB0nFKi0bVbHC+vDPvDqvltI6iNFa9uO8cPFmkYC1pkwDVlRKmjYJjrkSFSp5RB2Q0LBTmhUzKBIzQ5yUCNTJVp6a+iJ/bHQuLHtV95LxOGZEpdZBEqM6IT1YxZpyt2VOjx+sikPC80cDobaFwwXwvfTtuPUwlUsws0CJUp5urThEhCNRZnbpRY2dSwBx9zxzIqP7TDRVE2J6MJn+RozE3YWKUWgql5dyTEVJMIvd3wj0SBNioRZ4KzCwljtaFlAVbB4YyKLCM8fm5CJs5KEwJXhQSLmpCwPCFl2dAl6SRpCCPQbd37hmg2N/O+bCkPiHRrDxza/1a+E6cOrcyMDbTUnzTRoBwAJcx8Qr2P66SsyFdYbGjgb6nd5Vfx+zVPKpWzgz33vPZqEk8aaxDbbmK7JjjRhWxBRE4ycu6uSx1rlYayNHcTVaSlz1Od2A0xh1j3cTgLtIgtIYFdUbutthxOcF9yLbIGUnuNKTdM6ciLFepf4AsX+NGRWqxMUFc65bG95exVU/BqhZsFJPkkV2nz0BCJI6PbWfAc4txNXA3sOIEdBxDDGE4a4lNqL1q8J/kG6rurfkam4IenQE3pR4LF3ZCBtv+zrTbuzhyzfVcXxXLYw8S3Y6OdaJ2rN4OBhvM+nh46hXO8DfkE+pjM4KQAVZ2bwdpaMBwOcHv0kOthkj2Bj4l9a3p11nh3Svg7iWpy5VEwwuWYguT4grzKivA3VXt7lXcluPxXXgZKfJaC5iPUNg7W+sGwH+y+XNlcrx+oJe+x98R76gXea2/T++DtePse9cD76n3zvi/+7DzpPOu8mEkXrtXMI2+udV7+AgXIvEU=</latexit><latexit sha1_base64="m83+VgcK88NknGpfy90zJR76HqQ=">AAAHenicjZXbbtQwEIZDgW5ZTgUuuYmoKnHQHlKBqJAqlSIkuKnaQkulZlU5zuwmWsdObacHWXkCbuHheBcuGGcDdBNXYCnSZOb/7PH4FOUsVXo4/HFt4fqNm4udpVvd23fu3ru//ODhgRKFpLBPBRPyMCIKWMphX6eawWEugWQRgy/R9J2NfzkFqVLBP+uLHEYZmfB0nFKi0bVbHC+vDPvDqvltI6iNFa9uO8cPFmkYC1pkwDVlRKmjYJjrkSFSp5RB2Q0LBTmhUzKBIzQ5yUCNTJVp6a+iJ/bHQuLHtV95LxOGZEpdZBEqM6IT1YxZpyt2VOjx+sikPC80cDobaFwwXwvfTtuPUwlUsws0CJUp5urThEhCNRZnbpRY2dSwBx9zxzIqP7TDRVE2J6MJn+RozE3YWKUWgql5dyTEVJMIvd3wj0SBNioRZ4KzCwljtaFlAVbB4YyKLCM8fm5CJs5KEwJXhQSLmpCwPCFl2dAl6SRpCCPQbd37hmg2N/O+bCkPiHRrDxza/1a+E6cOrcyMDbTUnzTRoBwAJcx8Qr2P66SsyFdYbGjgb6nd5Vfx+zVPKpWzgz33vPZqEk8aaxDbbmK7JjjRhWxBRE4ycu6uSx1rlYayNHcTVaSlz1Od2A0xh1j3cTgLtIgtIYFdUbutthxOcF9yLbIGUnuNKTdM6ciLFepf4AsX+NGRWqxMUFc65bG95exVU/BqhZsFJPkkV2nz0BCJI6PbWfAc4txNXA3sOIEdBxDDGE4a4lNqL1q8J/kG6rurfkam4IenQE3pR4LF3ZCBtv+zrTbuzhyzfVcXxXLYw8S3Y6OdaJ2rN4OBhvM+nh46hXO8DfkE+pjM4KQAVZ2bwdpaMBwOcHv0kOthkj2Bj4l9a3p11nh3Svg7iWpy5VEwwuWYguT4grzKivA3VXt7lXcluPxXXgZKfJaC5iPUNg7W+sGwH+y+XNlcrx+oJe+x98R76gXea2/T++DtePse9cD76n3zvi/+7DzpPOu8mEkXrtXMI2+udV7+AgXIvEU=</latexit>
[ 1, 1]<latexit sha1_base64="Rf1gSvKKs0+n4XxCiZmEJZE11fg=">AAAHgHicjZVZb9QwEMdDORaWq8AjLxYVEgL2SAUCIVXiEBK8oHK0RdqsKseZ3UTr2Knt9JCVD8ErfDK+DeNsgG7iCixFmsz8f/Z4fMUFz7QZj3+eWzt/4eKl3uUr/avXrt+4uX7r9q6WpWKwwySX6mtMNfBMwI7JDIevhQKaxxz24sUbF987BKUzKb6YkwKmOZ2LbJYxatC1NxmEj0k43V/fGA/HdSNdI2yMjaBp2/u3LrEokazMQRjGqdaTcFyYqaXKZIxD1Y9KDQVlCzqHCZqC5qCnts63IvfRk5CZVPgJQ2rvacLSXOuTPEZlTk2q2zHn9MUmpZk9n9pMFKUBwZYDzUpOjCRu8iTJFDDDT9CgTGWYK2EpVZQZLNHKKIl2qWEPBHPHYmoSueHiOF+RsVTMCzRWJmyd0kjJ9ao7lnJhaIzefvRHosFYncojKfiJgpneMqoEpxBwxGSeU5E8tBGXR5WNQOhSgUNtRHmR0qpq6dJsnraEMZiu7m1LtJybfVt1lLtU+bW7Hu1/K9/IQ49W5dYFOurPhhrQHoBRbj+jnuA6aSciGosNLfwVc3v9LH6n4Wmt8nbwyT+vTw2J5423iA9+4kNDCGpK1YGomuf02F+XJtYpDeNZ4SfqSEdfZCZ1G2IFce79aBnoEK+lAn5G7V535XCA+1IYmbeQxmtttWUrT1681P8CH/nA957UEm3DptKZSNxd566aUtQr3C4gLeaFztqHhiocGd3egheQFH7ibGDbC2x7gARmcNASHzJ30eI9KbZQ379PcroAEh0CsxWJJU/6EQfj/pdbbdZfOpb7rimK47CHOXFjo50aU+gXo5GB4yGeHraAY7wNxRyGmMzooARdn5vR5mY4Ho9wewyQG2CSA4lPintxBk3WeHcq+DuJenLVJJzicixACXxBnuZl9JtqvIPauxGe/qtOAxU+S2H7Eeoau5vDcDwMPz7ZePm8eaAuB3eDe8GDIAyeBS+Dd8F2sBOwYBF8C74HP3prvQe9US9cStfONcydYKX1XvwCzZq8oA==</latexit><latexit sha1_base64="Rf1gSvKKs0+n4XxCiZmEJZE11fg=">AAAHgHicjZVZb9QwEMdDORaWq8AjLxYVEgL2SAUCIVXiEBK8oHK0RdqsKseZ3UTr2Knt9JCVD8ErfDK+DeNsgG7iCixFmsz8f/Z4fMUFz7QZj3+eWzt/4eKl3uUr/avXrt+4uX7r9q6WpWKwwySX6mtMNfBMwI7JDIevhQKaxxz24sUbF987BKUzKb6YkwKmOZ2LbJYxatC1NxmEj0k43V/fGA/HdSNdI2yMjaBp2/u3LrEokazMQRjGqdaTcFyYqaXKZIxD1Y9KDQVlCzqHCZqC5qCnts63IvfRk5CZVPgJQ2rvacLSXOuTPEZlTk2q2zHn9MUmpZk9n9pMFKUBwZYDzUpOjCRu8iTJFDDDT9CgTGWYK2EpVZQZLNHKKIl2qWEPBHPHYmoSueHiOF+RsVTMCzRWJmyd0kjJ9ao7lnJhaIzefvRHosFYncojKfiJgpneMqoEpxBwxGSeU5E8tBGXR5WNQOhSgUNtRHmR0qpq6dJsnraEMZiu7m1LtJybfVt1lLtU+bW7Hu1/K9/IQ49W5dYFOurPhhrQHoBRbj+jnuA6aSciGosNLfwVc3v9LH6n4Wmt8nbwyT+vTw2J5423iA9+4kNDCGpK1YGomuf02F+XJtYpDeNZ4SfqSEdfZCZ1G2IFce79aBnoEK+lAn5G7V535XCA+1IYmbeQxmtttWUrT1681P8CH/nA957UEm3DptKZSNxd566aUtQr3C4gLeaFztqHhiocGd3egheQFH7ibGDbC2x7gARmcNASHzJ30eI9KbZQ379PcroAEh0CsxWJJU/6EQfj/pdbbdZfOpb7rimK47CHOXFjo50aU+gXo5GB4yGeHraAY7wNxRyGmMzooARdn5vR5mY4Ho9wewyQG2CSA4lPintxBk3WeHcq+DuJenLVJJzicixACXxBnuZl9JtqvIPauxGe/qtOAxU+S2H7Eeoau5vDcDwMPz7ZePm8eaAuB3eDe8GDIAyeBS+Dd8F2sBOwYBF8C74HP3prvQe9US9cStfONcydYKX1XvwCzZq8oA==</latexit><latexit sha1_base64="Rf1gSvKKs0+n4XxCiZmEJZE11fg=">AAAHgHicjZVZb9QwEMdDORaWq8AjLxYVEgL2SAUCIVXiEBK8oHK0RdqsKseZ3UTr2Knt9JCVD8ErfDK+DeNsgG7iCixFmsz8f/Z4fMUFz7QZj3+eWzt/4eKl3uUr/avXrt+4uX7r9q6WpWKwwySX6mtMNfBMwI7JDIevhQKaxxz24sUbF987BKUzKb6YkwKmOZ2LbJYxatC1NxmEj0k43V/fGA/HdSNdI2yMjaBp2/u3LrEokazMQRjGqdaTcFyYqaXKZIxD1Y9KDQVlCzqHCZqC5qCnts63IvfRk5CZVPgJQ2rvacLSXOuTPEZlTk2q2zHn9MUmpZk9n9pMFKUBwZYDzUpOjCRu8iTJFDDDT9CgTGWYK2EpVZQZLNHKKIl2qWEPBHPHYmoSueHiOF+RsVTMCzRWJmyd0kjJ9ao7lnJhaIzefvRHosFYncojKfiJgpneMqoEpxBwxGSeU5E8tBGXR5WNQOhSgUNtRHmR0qpq6dJsnraEMZiu7m1LtJybfVt1lLtU+bW7Hu1/K9/IQ49W5dYFOurPhhrQHoBRbj+jnuA6aSciGosNLfwVc3v9LH6n4Wmt8nbwyT+vTw2J5423iA9+4kNDCGpK1YGomuf02F+XJtYpDeNZ4SfqSEdfZCZ1G2IFce79aBnoEK+lAn5G7V535XCA+1IYmbeQxmtttWUrT1681P8CH/nA957UEm3DptKZSNxd566aUtQr3C4gLeaFztqHhiocGd3egheQFH7ibGDbC2x7gARmcNASHzJ30eI9KbZQ379PcroAEh0CsxWJJU/6EQfj/pdbbdZfOpb7rimK47CHOXFjo50aU+gXo5GB4yGeHraAY7wNxRyGmMzooARdn5vR5mY4Ho9wewyQG2CSA4lPintxBk3WeHcq+DuJenLVJJzicixACXxBnuZl9JtqvIPauxGe/qtOAxU+S2H7Eeoau5vDcDwMPz7ZePm8eaAuB3eDe8GDIAyeBS+Dd8F2sBOwYBF8C74HP3prvQe9US9cStfONcydYKX1XvwCzZq8oA==</latexit><latexit sha1_base64="Rf1gSvKKs0+n4XxCiZmEJZE11fg=">AAAHgHicjZVZb9QwEMdDORaWq8AjLxYVEgL2SAUCIVXiEBK8oHK0RdqsKseZ3UTr2Knt9JCVD8ErfDK+DeNsgG7iCixFmsz8f/Z4fMUFz7QZj3+eWzt/4eKl3uUr/avXrt+4uX7r9q6WpWKwwySX6mtMNfBMwI7JDIevhQKaxxz24sUbF987BKUzKb6YkwKmOZ2LbJYxatC1NxmEj0k43V/fGA/HdSNdI2yMjaBp2/u3LrEokazMQRjGqdaTcFyYqaXKZIxD1Y9KDQVlCzqHCZqC5qCnts63IvfRk5CZVPgJQ2rvacLSXOuTPEZlTk2q2zHn9MUmpZk9n9pMFKUBwZYDzUpOjCRu8iTJFDDDT9CgTGWYK2EpVZQZLNHKKIl2qWEPBHPHYmoSueHiOF+RsVTMCzRWJmyd0kjJ9ao7lnJhaIzefvRHosFYncojKfiJgpneMqoEpxBwxGSeU5E8tBGXR5WNQOhSgUNtRHmR0qpq6dJsnraEMZiu7m1LtJybfVt1lLtU+bW7Hu1/K9/IQ49W5dYFOurPhhrQHoBRbj+jnuA6aSciGosNLfwVc3v9LH6n4Wmt8nbwyT+vTw2J5423iA9+4kNDCGpK1YGomuf02F+XJtYpDeNZ4SfqSEdfZCZ1G2IFce79aBnoEK+lAn5G7V535XCA+1IYmbeQxmtttWUrT1681P8CH/nA957UEm3DptKZSNxd566aUtQr3C4gLeaFztqHhiocGd3egheQFH7ibGDbC2x7gARmcNASHzJ30eI9KbZQ379PcroAEh0CsxWJJU/6EQfj/pdbbdZfOpb7rimK47CHOXFjo50aU+gXo5GB4yGeHraAY7wNxRyGmMzooARdn5vR5mY4Ho9wewyQG2CSA4lPintxBk3WeHcq+DuJenLVJJzicixACXxBnuZl9JtqvIPauxGe/qtOAxU+S2H7Eeoau5vDcDwMPz7ZePm8eaAuB3eDe8GDIAyeBS+Dd8F2sBOwYBF8C74HP3prvQe9US9cStfONcydYKX1XvwCzZq8oA==</latexit>](https://image.slidesharecdn.com/icml2018capgupload-180728051747/85/Clipped-Action-Policy-Gradient-2-320.jpg)
![Policy gradient with action clipping
l Policy gradient (PG) uses actions before clipping, not
l It is unbiased
l It works well
l But, why not use the knowledge of actions being clipped?
E[Q⇡✓
(s, u) (s, u)] = r✓ E
h X
t
t
rt
i
| {z }
expected return<latexit sha1_base64="yaabuIKwpJjR5SUJfgS5PLKhDoM=">AAAH9HicjZXfj9w0EMezhXbLAu0VHnmxOFUqP/ZHTiAqpJPKVSfBS3VtuWul9XblOLNJtI6ds529W1n5T3hDvPL/8MS/wjgb4DbJCSJFmoy/n3g8tmeiQmTGzmZ/DO689/7de8P7H4w+/OjjBw8PHn1yYVSpOZxzJZR+GzEDIpNwbjMr4G2hgeWRgDfR+rkff7MBbTIlf7bbAhY5S2S2yjiz6FoebOnpnLx852iRLalNwbLqifm6/ILQwmQ7a0GOCZUsEqxREFrKGHSkGQdHT+lJlsypKfOlJTRhec7eWaKX1vsX1dJRC9fWwXUB3EJMNNhSy6paHhzOJrP6IV0jbIzDoHnOlo/ucRorXuYgLRfMmHk4K+zCMW0zLqAa0dJAwfiaJTBHU7IczMLVOarIY/TEZKU0vtKS2nuTcCw3ZptHqMyZTU17zDv7xualXT1duEwWpQXJdxOtSkGsIj7hJM40Llxs0WBcZxgr4SnD3Fnclr1ZYuNDwz8Q8OkGQ6ifLoryPRlPZVKgsbdg55VWKWH23ZFSa8si9I7oPxID1plUXSkpthpW5tjqErxCwhVXuIEy/tJRoa4qR0GaUoNHHWWiSFlVtXRplqQtYeTPUVt32hLt1uZOq47ygul+7UWP9n8rn6tNj1bnzg901K8ts2B6AM6Ee416gvtkvIgYTDa08B+4v1+38ecNz2pV7w9e9a/rVUPiHRct4kU/8aIhJMN714GYTnJ23Z+XZqyTGi6yop+oRzr6ItsVlj3kZsXpECdKg7gldyddOVziuZRW5S2k8TpXHbuqJy5Rmv8Cv+oDf+oJLTYubDKdydjXV19qSlnvcDuBrEiwvLYvDdPOV93+hBcQF/3E7cBZL3DWA8SwgsuWeMN9ocU6KY9RP3pMcrYGQjfAXUUiJeIRFWD99+6orUY7x+7cNUnxHP4hIX5utFNrC/P9dIo9YYK3h6/hGquhTGCCwUwvSzD1vZkeHYWz2RSPxxi5MQY5VtjGfJcbN1Fj7dTw7yLqxVXzcIHbsQYtsYN8m5f0b6rxjmvvYXjzq7oJ+LYUtptQ17g4moSzSfjym8NnT5sGdT/4LPg8eBKEwXfBs+DH4Cw4D3jw5+Du4MHg4XAz/GX46/C3nfTOoGE+Dfae4e9/AXue6bU=</latexit><latexit sha1_base64="yaabuIKwpJjR5SUJfgS5PLKhDoM=">AAAH9HicjZXfj9w0EMezhXbLAu0VHnmxOFUqP/ZHTiAqpJPKVSfBS3VtuWul9XblOLNJtI6ds529W1n5T3hDvPL/8MS/wjgb4DbJCSJFmoy/n3g8tmeiQmTGzmZ/DO689/7de8P7H4w+/OjjBw8PHn1yYVSpOZxzJZR+GzEDIpNwbjMr4G2hgeWRgDfR+rkff7MBbTIlf7bbAhY5S2S2yjiz6FoebOnpnLx852iRLalNwbLqifm6/ILQwmQ7a0GOCZUsEqxREFrKGHSkGQdHT+lJlsypKfOlJTRhec7eWaKX1vsX1dJRC9fWwXUB3EJMNNhSy6paHhzOJrP6IV0jbIzDoHnOlo/ucRorXuYgLRfMmHk4K+zCMW0zLqAa0dJAwfiaJTBHU7IczMLVOarIY/TEZKU0vtKS2nuTcCw3ZptHqMyZTU17zDv7xualXT1duEwWpQXJdxOtSkGsIj7hJM40Llxs0WBcZxgr4SnD3Fnclr1ZYuNDwz8Q8OkGQ6ifLoryPRlPZVKgsbdg55VWKWH23ZFSa8si9I7oPxID1plUXSkpthpW5tjqErxCwhVXuIEy/tJRoa4qR0GaUoNHHWWiSFlVtXRplqQtYeTPUVt32hLt1uZOq47ygul+7UWP9n8rn6tNj1bnzg901K8ts2B6AM6Ee416gvtkvIgYTDa08B+4v1+38ecNz2pV7w9e9a/rVUPiHRct4kU/8aIhJMN714GYTnJ23Z+XZqyTGi6yop+oRzr6ItsVlj3kZsXpECdKg7gldyddOVziuZRW5S2k8TpXHbuqJy5Rmv8Cv+oDf+oJLTYubDKdydjXV19qSlnvcDuBrEiwvLYvDdPOV93+hBcQF/3E7cBZL3DWA8SwgsuWeMN9ocU6KY9RP3pMcrYGQjfAXUUiJeIRFWD99+6orUY7x+7cNUnxHP4hIX5utFNrC/P9dIo9YYK3h6/hGquhTGCCwUwvSzD1vZkeHYWz2RSPxxi5MQY5VtjGfJcbN1Fj7dTw7yLqxVXzcIHbsQYtsYN8m5f0b6rxjmvvYXjzq7oJ+LYUtptQ17g4moSzSfjym8NnT5sGdT/4LPg8eBKEwXfBs+DH4Cw4D3jw5+Du4MHg4XAz/GX46/C3nfTOoGE+Dfae4e9/AXue6bU=</latexit><latexit sha1_base64="yaabuIKwpJjR5SUJfgS5PLKhDoM=">AAAH9HicjZXfj9w0EMezhXbLAu0VHnmxOFUqP/ZHTiAqpJPKVSfBS3VtuWul9XblOLNJtI6ds529W1n5T3hDvPL/8MS/wjgb4DbJCSJFmoy/n3g8tmeiQmTGzmZ/DO689/7de8P7H4w+/OjjBw8PHn1yYVSpOZxzJZR+GzEDIpNwbjMr4G2hgeWRgDfR+rkff7MBbTIlf7bbAhY5S2S2yjiz6FoebOnpnLx852iRLalNwbLqifm6/ILQwmQ7a0GOCZUsEqxREFrKGHSkGQdHT+lJlsypKfOlJTRhec7eWaKX1vsX1dJRC9fWwXUB3EJMNNhSy6paHhzOJrP6IV0jbIzDoHnOlo/ucRorXuYgLRfMmHk4K+zCMW0zLqAa0dJAwfiaJTBHU7IczMLVOarIY/TEZKU0vtKS2nuTcCw3ZptHqMyZTU17zDv7xualXT1duEwWpQXJdxOtSkGsIj7hJM40Llxs0WBcZxgr4SnD3Fnclr1ZYuNDwz8Q8OkGQ6ifLoryPRlPZVKgsbdg55VWKWH23ZFSa8si9I7oPxID1plUXSkpthpW5tjqErxCwhVXuIEy/tJRoa4qR0GaUoNHHWWiSFlVtXRplqQtYeTPUVt32hLt1uZOq47ygul+7UWP9n8rn6tNj1bnzg901K8ts2B6AM6Ee416gvtkvIgYTDa08B+4v1+38ecNz2pV7w9e9a/rVUPiHRct4kU/8aIhJMN714GYTnJ23Z+XZqyTGi6yop+oRzr6ItsVlj3kZsXpECdKg7gldyddOVziuZRW5S2k8TpXHbuqJy5Rmv8Cv+oDf+oJLTYubDKdydjXV19qSlnvcDuBrEiwvLYvDdPOV93+hBcQF/3E7cBZL3DWA8SwgsuWeMN9ocU6KY9RP3pMcrYGQjfAXUUiJeIRFWD99+6orUY7x+7cNUnxHP4hIX5utFNrC/P9dIo9YYK3h6/hGquhTGCCwUwvSzD1vZkeHYWz2RSPxxi5MQY5VtjGfJcbN1Fj7dTw7yLqxVXzcIHbsQYtsYN8m5f0b6rxjmvvYXjzq7oJ+LYUtptQ17g4moSzSfjym8NnT5sGdT/4LPg8eBKEwXfBs+DH4Cw4D3jw5+Du4MHg4XAz/GX46/C3nfTOoGE+Dfae4e9/AXue6bU=</latexit><latexit sha1_base64="yaabuIKwpJjR5SUJfgS5PLKhDoM=">AAAH9HicjZXfj9w0EMezhXbLAu0VHnmxOFUqP/ZHTiAqpJPKVSfBS3VtuWul9XblOLNJtI6ds529W1n5T3hDvPL/8MS/wjgb4DbJCSJFmoy/n3g8tmeiQmTGzmZ/DO689/7de8P7H4w+/OjjBw8PHn1yYVSpOZxzJZR+GzEDIpNwbjMr4G2hgeWRgDfR+rkff7MBbTIlf7bbAhY5S2S2yjiz6FoebOnpnLx852iRLalNwbLqifm6/ILQwmQ7a0GOCZUsEqxREFrKGHSkGQdHT+lJlsypKfOlJTRhec7eWaKX1vsX1dJRC9fWwXUB3EJMNNhSy6paHhzOJrP6IV0jbIzDoHnOlo/ucRorXuYgLRfMmHk4K+zCMW0zLqAa0dJAwfiaJTBHU7IczMLVOarIY/TEZKU0vtKS2nuTcCw3ZptHqMyZTU17zDv7xualXT1duEwWpQXJdxOtSkGsIj7hJM40Llxs0WBcZxgr4SnD3Fnclr1ZYuNDwz8Q8OkGQ6ifLoryPRlPZVKgsbdg55VWKWH23ZFSa8si9I7oPxID1plUXSkpthpW5tjqErxCwhVXuIEy/tJRoa4qR0GaUoNHHWWiSFlVtXRplqQtYeTPUVt32hLt1uZOq47ygul+7UWP9n8rn6tNj1bnzg901K8ts2B6AM6Ee416gvtkvIgYTDa08B+4v1+38ecNz2pV7w9e9a/rVUPiHRct4kU/8aIhJMN714GYTnJ23Z+XZqyTGi6yop+oRzr6ItsVlj3kZsXpECdKg7gldyddOVziuZRW5S2k8TpXHbuqJy5Rmv8Cv+oDf+oJLTYubDKdydjXV19qSlnvcDuBrEiwvLYvDdPOV93+hBcQF/3E7cBZL3DWA8SwgsuWeMN9ocU6KY9RP3pMcrYGQjfAXUUiJeIRFWD99+6orUY7x+7cNUnxHP4hIX5utFNrC/P9dIo9YYK3h6/hGquhTGCCwUwvSzD1vZkeHYWz2RSPxxi5MQY5VtjGfJcbN1Fj7dTw7yLqxVXzcIHbsQYtsYN8m5f0b6rxjmvvYXjzq7oJ+LYUtptQ17g4moSzSfjym8NnT5sGdT/4LPg8eBKEwXfBs+DH4Cw4D3jw5+Du4MHg4XAz/GX46/C3nfTOoGE+Dfae4e9/AXue6bU=</latexit>
u<latexit sha1_base64="dwQi/GSg/5Ve+tLQrQww/MqnfJE=">AAAHgHicjZVZa9wwEMed9Nh0e7ePfTENgdCyh0NLQyCQJgTal5AeOSBegizPrs3KkiPJORD+EH1tP1m/TUdet83aCq3BMJ75/6TRWBpFOUuVHg5/Lizeun3nbmfpXvf+g4ePHj95+uxQiUJSOKCCCXkcEQUs5XCgU83gOJdAsojBUTTdsfGjc5AqFfyrvsphlJEJT8cpJRpdR2FEpCnK0yfLw/6wevy2EdTGslc/+6dP79IwFrTIgGvKiFInwTDXI0OkTimDshsWCnJCp2QCJ2hykoEamSrf0l9BT+yPhcSXa7/yXicMyZS6yiJUZkQnqhmzTlfspNDj9ZFJeV5o4HQ20bhgvha+XbwfpxKoZldoECpTzNWnCZGEaizR3CyxsqnhCD7mjsVUfmini6JsTkYTPsnRmFuwsUotBFPz7kiIqSYRervhH4kCbVQiLgRnVxLGalPLAqyCwwUVWUZ4/MqETFyUJgSuCgkWNSFheULKsqFL0knSEEag27rdhmi2NrNbtpSHRLq1hw7tfyt3xLlDKzNjAy31F000KAdACTNfUO/jf1JW5CssNjTw99Tu9Zv4g5onlco5wGf3uj7XJJ431iD23MReTXCiC9mCiJxk5NJdlzrWKg1lae4mqkhLn6c6sRtiDrHu03AWaBHbQgK7oXbbbTmc4b7kWmQNpPYaU26a0pEXK9S/wNcu8KMjtViZoK50ymPb62yrKXj1h5sFJPkkV2nz0GBbDK3bWfAc4txN3AzsO4F9BxDDGM4a4nNqGy32Sb6J+u6Kn5Ep+OE5UFP6kWBxN2Sg7fdsq427M8ds39VFsRyOMPHt3GgnWudqYzDQcNnH00OncIndkE+gj8kMzgpQ1bkZrK0Fw+EAt0cPuR4m2RN4pdgbp1dnjb1Twt9FVIsrT4IR/o4pSI43yNusCH9TtbdXeZeD61/ldcBeS0HzEmobh2v9YNgPPr1Z3lqvL6gl74X30lv1Au+dt+V98Pa9A496U++b99370VnsrHYGnWAmXVyomefe3NPZ+AXd/b4L</latexit><latexit sha1_base64="dwQi/GSg/5Ve+tLQrQww/MqnfJE=">AAAHgHicjZVZa9wwEMed9Nh0e7ePfTENgdCyh0NLQyCQJgTal5AeOSBegizPrs3KkiPJORD+EH1tP1m/TUdet83aCq3BMJ75/6TRWBpFOUuVHg5/Lizeun3nbmfpXvf+g4ePHj95+uxQiUJSOKCCCXkcEQUs5XCgU83gOJdAsojBUTTdsfGjc5AqFfyrvsphlJEJT8cpJRpdR2FEpCnK0yfLw/6wevy2EdTGslc/+6dP79IwFrTIgGvKiFInwTDXI0OkTimDshsWCnJCp2QCJ2hykoEamSrf0l9BT+yPhcSXa7/yXicMyZS6yiJUZkQnqhmzTlfspNDj9ZFJeV5o4HQ20bhgvha+XbwfpxKoZldoECpTzNWnCZGEaizR3CyxsqnhCD7mjsVUfmini6JsTkYTPsnRmFuwsUotBFPz7kiIqSYRervhH4kCbVQiLgRnVxLGalPLAqyCwwUVWUZ4/MqETFyUJgSuCgkWNSFheULKsqFL0knSEEag27rdhmi2NrNbtpSHRLq1hw7tfyt3xLlDKzNjAy31F000KAdACTNfUO/jf1JW5CssNjTw99Tu9Zv4g5onlco5wGf3uj7XJJ431iD23MReTXCiC9mCiJxk5NJdlzrWKg1lae4mqkhLn6c6sRtiDrHu03AWaBHbQgK7oXbbbTmc4b7kWmQNpPYaU26a0pEXK9S/wNcu8KMjtViZoK50ymPb62yrKXj1h5sFJPkkV2nz0GBbDK3bWfAc4txN3AzsO4F9BxDDGM4a4nNqGy32Sb6J+u6Kn5Ep+OE5UFP6kWBxN2Sg7fdsq427M8ds39VFsRyOMPHt3GgnWudqYzDQcNnH00OncIndkE+gj8kMzgpQ1bkZrK0Fw+EAt0cPuR4m2RN4pdgbp1dnjb1Twt9FVIsrT4IR/o4pSI43yNusCH9TtbdXeZeD61/ldcBeS0HzEmobh2v9YNgPPr1Z3lqvL6gl74X30lv1Au+dt+V98Pa9A496U++b99370VnsrHYGnWAmXVyomefe3NPZ+AXd/b4L</latexit><latexit sha1_base64="dwQi/GSg/5Ve+tLQrQww/MqnfJE=">AAAHgHicjZVZa9wwEMed9Nh0e7ePfTENgdCyh0NLQyCQJgTal5AeOSBegizPrs3KkiPJORD+EH1tP1m/TUdet83aCq3BMJ75/6TRWBpFOUuVHg5/Lizeun3nbmfpXvf+g4ePHj95+uxQiUJSOKCCCXkcEQUs5XCgU83gOJdAsojBUTTdsfGjc5AqFfyrvsphlJEJT8cpJRpdR2FEpCnK0yfLw/6wevy2EdTGslc/+6dP79IwFrTIgGvKiFInwTDXI0OkTimDshsWCnJCp2QCJ2hykoEamSrf0l9BT+yPhcSXa7/yXicMyZS6yiJUZkQnqhmzTlfspNDj9ZFJeV5o4HQ20bhgvha+XbwfpxKoZldoECpTzNWnCZGEaizR3CyxsqnhCD7mjsVUfmini6JsTkYTPsnRmFuwsUotBFPz7kiIqSYRervhH4kCbVQiLgRnVxLGalPLAqyCwwUVWUZ4/MqETFyUJgSuCgkWNSFheULKsqFL0knSEEag27rdhmi2NrNbtpSHRLq1hw7tfyt3xLlDKzNjAy31F000KAdACTNfUO/jf1JW5CssNjTw99Tu9Zv4g5onlco5wGf3uj7XJJ431iD23MReTXCiC9mCiJxk5NJdlzrWKg1lae4mqkhLn6c6sRtiDrHu03AWaBHbQgK7oXbbbTmc4b7kWmQNpPYaU26a0pEXK9S/wNcu8KMjtViZoK50ymPb62yrKXj1h5sFJPkkV2nz0GBbDK3bWfAc4txN3AzsO4F9BxDDGM4a4nNqGy32Sb6J+u6Kn5Ep+OE5UFP6kWBxN2Sg7fdsq427M8ds39VFsRyOMPHt3GgnWudqYzDQcNnH00OncIndkE+gj8kMzgpQ1bkZrK0Fw+EAt0cPuR4m2RN4pdgbp1dnjb1Twt9FVIsrT4IR/o4pSI43yNusCH9TtbdXeZeD61/ldcBeS0HzEmobh2v9YNgPPr1Z3lqvL6gl74X30lv1Au+dt+V98Pa9A496U++b99370VnsrHYGnWAmXVyomefe3NPZ+AXd/b4L</latexit><latexit sha1_base64="dwQi/GSg/5Ve+tLQrQww/MqnfJE=">AAAHgHicjZVZa9wwEMed9Nh0e7ePfTENgdCyh0NLQyCQJgTal5AeOSBegizPrs3KkiPJORD+EH1tP1m/TUdet83aCq3BMJ75/6TRWBpFOUuVHg5/Lizeun3nbmfpXvf+g4ePHj95+uxQiUJSOKCCCXkcEQUs5XCgU83gOJdAsojBUTTdsfGjc5AqFfyrvsphlJEJT8cpJRpdR2FEpCnK0yfLw/6wevy2EdTGslc/+6dP79IwFrTIgGvKiFInwTDXI0OkTimDshsWCnJCp2QCJ2hykoEamSrf0l9BT+yPhcSXa7/yXicMyZS6yiJUZkQnqhmzTlfspNDj9ZFJeV5o4HQ20bhgvha+XbwfpxKoZldoECpTzNWnCZGEaizR3CyxsqnhCD7mjsVUfmini6JsTkYTPsnRmFuwsUotBFPz7kiIqSYRervhH4kCbVQiLgRnVxLGalPLAqyCwwUVWUZ4/MqETFyUJgSuCgkWNSFheULKsqFL0knSEEag27rdhmi2NrNbtpSHRLq1hw7tfyt3xLlDKzNjAy31F000KAdACTNfUO/jf1JW5CssNjTw99Tu9Zv4g5onlco5wGf3uj7XJJ431iD23MReTXCiC9mCiJxk5NJdlzrWKg1lae4mqkhLn6c6sRtiDrHu03AWaBHbQgK7oXbbbTmc4b7kWmQNpPYaU26a0pEXK9S/wNcu8KMjtViZoK50ymPb62yrKXj1h5sFJPkkV2nz0GBbDK3bWfAc4txN3AzsO4F9BxDDGM4a4nNqGy32Sb6J+u6Kn5Ep+OE5UFP6kWBxN2Sg7fdsq427M8ds39VFsRyOMPHt3GgnWudqYzDQcNnH00OncIndkE+gj8kMzgpQ1bkZrK0Fw+EAt0cPuR4m2RN4pdgbp1dnjb1Twt9FVIsrT4IR/o4pSI43yNusCH9TtbdXeZeD61/ldcBeS0HzEmobh2v9YNgPPr1Z3lqvL6gl74X30lv1Au+dt+V98Pa9A496U++b99370VnsrHYGnWAmXVyomefe3NPZ+AXd/b4L</latexit>
PG: Q⇡✓
(s, u)
| {z }
action value
r✓ log ⇡✓(u|s)
| {z }
(s, u)<latexit sha1_base64="WyXT3TDFerJaT275SAvIWc9D4WA=">AAAIHHicjZXdjtw0FMczBTpl+NrCDRI3pqtKy8d8ZAWiQlqptKoEN9W2ZbeVNsPIcc5MrHHsrO3M7mLyBjwDT8Md4haJ1+AJOE7SdibJCiKN5Dn+/46Pj+1z4lxwY2ezvwc33njzrZvDW2+P3nn3vfc/2Lv94alRhWZwwpRQ+kVMDQgu4cRyK+BFroFmsYDn8fqhn3++AW24kj/aqxzmGV1JvuSMWjQt9n6NCpmAjjVl4J785KKcLyKbgqXlgfmy+KxcuCijNhVUr0C7yMKldZR5mGyoKKAsS7LtI5I0FrTxQSKhVuS1z4PiF9NxmRteL1Uu9vZnk1n1ke4gbAb7QfMdL27fvIwSxYoMpGWCGnMWznI7d1RbzgSUo6gwkFO2pis4w6GkGZi5q9JWkrtoSchSafxJSyrrNuFoZsxVFqPSx2vac97YN3dW2OW9ueMyLyxIVi+0LASxivgzIAnXwKy4wgFlmmOshKUU02fxpHZWSYwPDT0Q8HkFQ6rUxXG2I2OpXOU42Nmw80qrlDC75liptaVxy6pBGP4zehhFrzgD1plUXSgprjQszZHVRaWQcMFUllGZfO7wiC9KF4E0hQaPuoiKPKVl2dKlfJW2hLG/Z23do5ao3rB7VHaUp1T3a097tP9b+VBterQ6c36io35mqQXTAzAq3DP/OvDwjBcRg7mGFv5d9ZSu408avnlwfQ6e9u/raUNiLRAt4nE/8bghJLWF7kD4VjN62Z+XZq6TGiZ43k9UMx19zuvCs4NsV6QO8UDhtb0mdw+6cjjHeymtylpIY3WuPHJlT1yiMP8FftEH/tATWmJc2GSay8TXYV9/ClmdcDuBNF9hdWw/GloXzf6E55Dk/cT1wHEvcNwDJLCE85Z4w3z1xeIpj1A/uksyugYSbYC5ksRKJKNIgPX/66u2HNWG+t41SfEcesBmgWvjOLU2N99Op9hvJvh62BousUTKFUwwmOl5AaZ6N9PDw3A2m+L1GCM3xiDHCtud74bjJmosqBpeb6LaXHkWzvE41qAltpWvsyJ6STXWcWXdD7f/lduA71VhuzN1B6eHk3A2CZ98tX//XtO1bgWfBHeCgyAMvgnuB98Hx8FJwIJ/Bh8PPh3cGf42/H34x/DPWnpj0DAfBTvf8K9/AfQW/b8=</latexit><latexit sha1_base64="WyXT3TDFerJaT275SAvIWc9D4WA=">AAAIHHicjZXdjtw0FMczBTpl+NrCDRI3pqtKy8d8ZAWiQlqptKoEN9W2ZbeVNsPIcc5MrHHsrO3M7mLyBjwDT8Md4haJ1+AJOE7SdibJCiKN5Dn+/46Pj+1z4lxwY2ezvwc33njzrZvDW2+P3nn3vfc/2Lv94alRhWZwwpRQ+kVMDQgu4cRyK+BFroFmsYDn8fqhn3++AW24kj/aqxzmGV1JvuSMWjQt9n6NCpmAjjVl4J785KKcLyKbgqXlgfmy+KxcuCijNhVUr0C7yMKldZR5mGyoKKAsS7LtI5I0FrTxQSKhVuS1z4PiF9NxmRteL1Uu9vZnk1n1ke4gbAb7QfMdL27fvIwSxYoMpGWCGnMWznI7d1RbzgSUo6gwkFO2pis4w6GkGZi5q9JWkrtoSchSafxJSyrrNuFoZsxVFqPSx2vac97YN3dW2OW9ueMyLyxIVi+0LASxivgzIAnXwKy4wgFlmmOshKUU02fxpHZWSYwPDT0Q8HkFQ6rUxXG2I2OpXOU42Nmw80qrlDC75liptaVxy6pBGP4zehhFrzgD1plUXSgprjQszZHVRaWQcMFUllGZfO7wiC9KF4E0hQaPuoiKPKVl2dKlfJW2hLG/Z23do5ao3rB7VHaUp1T3a097tP9b+VBterQ6c36io35mqQXTAzAq3DP/OvDwjBcRg7mGFv5d9ZSu408avnlwfQ6e9u/raUNiLRAt4nE/8bghJLWF7kD4VjN62Z+XZq6TGiZ43k9UMx19zuvCs4NsV6QO8UDhtb0mdw+6cjjHeymtylpIY3WuPHJlT1yiMP8FftEH/tATWmJc2GSay8TXYV9/ClmdcDuBNF9hdWw/GloXzf6E55Dk/cT1wHEvcNwDJLCE85Z4w3z1xeIpj1A/uksyugYSbYC5ksRKJKNIgPX/66u2HNWG+t41SfEcesBmgWvjOLU2N99Op9hvJvh62BousUTKFUwwmOl5AaZ6N9PDw3A2m+L1GCM3xiDHCtud74bjJmosqBpeb6LaXHkWzvE41qAltpWvsyJ6STXWcWXdD7f/lduA71VhuzN1B6eHk3A2CZ98tX//XtO1bgWfBHeCgyAMvgnuB98Hx8FJwIJ/Bh8PPh3cGf42/H34x/DPWnpj0DAfBTvf8K9/AfQW/b8=</latexit><latexit sha1_base64="WyXT3TDFerJaT275SAvIWc9D4WA=">AAAIHHicjZXdjtw0FMczBTpl+NrCDRI3pqtKy8d8ZAWiQlqptKoEN9W2ZbeVNsPIcc5MrHHsrO3M7mLyBjwDT8Md4haJ1+AJOE7SdibJCiKN5Dn+/46Pj+1z4lxwY2ezvwc33njzrZvDW2+P3nn3vfc/2Lv94alRhWZwwpRQ+kVMDQgu4cRyK+BFroFmsYDn8fqhn3++AW24kj/aqxzmGV1JvuSMWjQt9n6NCpmAjjVl4J785KKcLyKbgqXlgfmy+KxcuCijNhVUr0C7yMKldZR5mGyoKKAsS7LtI5I0FrTxQSKhVuS1z4PiF9NxmRteL1Uu9vZnk1n1ke4gbAb7QfMdL27fvIwSxYoMpGWCGnMWznI7d1RbzgSUo6gwkFO2pis4w6GkGZi5q9JWkrtoSchSafxJSyrrNuFoZsxVFqPSx2vac97YN3dW2OW9ueMyLyxIVi+0LASxivgzIAnXwKy4wgFlmmOshKUU02fxpHZWSYwPDT0Q8HkFQ6rUxXG2I2OpXOU42Nmw80qrlDC75liptaVxy6pBGP4zehhFrzgD1plUXSgprjQszZHVRaWQcMFUllGZfO7wiC9KF4E0hQaPuoiKPKVl2dKlfJW2hLG/Z23do5ao3rB7VHaUp1T3a097tP9b+VBterQ6c36io35mqQXTAzAq3DP/OvDwjBcRg7mGFv5d9ZSu408avnlwfQ6e9u/raUNiLRAt4nE/8bghJLWF7kD4VjN62Z+XZq6TGiZ43k9UMx19zuvCs4NsV6QO8UDhtb0mdw+6cjjHeymtylpIY3WuPHJlT1yiMP8FftEH/tATWmJc2GSay8TXYV9/ClmdcDuBNF9hdWw/GloXzf6E55Dk/cT1wHEvcNwDJLCE85Z4w3z1xeIpj1A/uksyugYSbYC5ksRKJKNIgPX/66u2HNWG+t41SfEcesBmgWvjOLU2N99Op9hvJvh62BousUTKFUwwmOl5AaZ6N9PDw3A2m+L1GCM3xiDHCtud74bjJmosqBpeb6LaXHkWzvE41qAltpWvsyJ6STXWcWXdD7f/lduA71VhuzN1B6eHk3A2CZ98tX//XtO1bgWfBHeCgyAMvgnuB98Hx8FJwIJ/Bh8PPh3cGf42/H34x/DPWnpj0DAfBTvf8K9/AfQW/b8=</latexit><latexit sha1_base64="WyXT3TDFerJaT275SAvIWc9D4WA=">AAAIHHicjZXdjtw0FMczBTpl+NrCDRI3pqtKy8d8ZAWiQlqptKoEN9W2ZbeVNsPIcc5MrHHsrO3M7mLyBjwDT8Md4haJ1+AJOE7SdibJCiKN5Dn+/46Pj+1z4lxwY2ezvwc33njzrZvDW2+P3nn3vfc/2Lv94alRhWZwwpRQ+kVMDQgu4cRyK+BFroFmsYDn8fqhn3++AW24kj/aqxzmGV1JvuSMWjQt9n6NCpmAjjVl4J785KKcLyKbgqXlgfmy+KxcuCijNhVUr0C7yMKldZR5mGyoKKAsS7LtI5I0FrTxQSKhVuS1z4PiF9NxmRteL1Uu9vZnk1n1ke4gbAb7QfMdL27fvIwSxYoMpGWCGnMWznI7d1RbzgSUo6gwkFO2pis4w6GkGZi5q9JWkrtoSchSafxJSyrrNuFoZsxVFqPSx2vac97YN3dW2OW9ueMyLyxIVi+0LASxivgzIAnXwKy4wgFlmmOshKUU02fxpHZWSYwPDT0Q8HkFQ6rUxXG2I2OpXOU42Nmw80qrlDC75liptaVxy6pBGP4zehhFrzgD1plUXSgprjQszZHVRaWQcMFUllGZfO7wiC9KF4E0hQaPuoiKPKVl2dKlfJW2hLG/Z23do5ao3rB7VHaUp1T3a097tP9b+VBterQ6c36io35mqQXTAzAq3DP/OvDwjBcRg7mGFv5d9ZSu408avnlwfQ6e9u/raUNiLRAt4nE/8bghJLWF7kD4VjN62Z+XZq6TGiZ43k9UMx19zuvCs4NsV6QO8UDhtb0mdw+6cjjHeymtylpIY3WuPHJlT1yiMP8FftEH/tATWmJc2GSay8TXYV9/ClmdcDuBNF9hdWw/GloXzf6E55Dk/cT1wHEvcNwDJLCE85Z4w3z1xeIpj1A/uksyugYSbYC5ksRKJKNIgPX/66u2HNWG+t41SfEcesBmgWvjOLU2N99Op9hvJvh62BousUTKFUwwmOl5AaZ6N9PDw3A2m+L1GCM3xiDHCtud74bjJmosqBpeb6LaXHkWzvE41qAltpWvsyJ6STXWcWXdD7f/lduA71VhuzN1B6eHk3A2CZ98tX//XtO1bgWfBHeCgyAMvgnuB98Hx8FJwIJ/Bh8PPh3cGf42/H34x/DPWnpj0DAfBTvf8K9/AfQW/b8=</latexit>](https://image.slidesharecdn.com/icml2018capgupload-180728051747/85/Clipped-Action-Policy-Gradient-4-320.jpg)



![What is good about CAPG?
l Under mild assumptions, for any , CAPG is
– unbiased
– elementwise lower-variance than PG
s<latexit sha1_base64="P9kt+2hoUT1YphS4BYG+DBY0D5s=">AAAHyXicjZVbj9Q2FMcDFIZOgS70sS9WVytxm0tWRaBKK3ERElWl1XLZAWkyrBznzCQax87azl6w8tSv1C/TvsIH4TiTwk7iFUSKdHz8/9nHx/ZxXPBMm/H43wsXL/1w+Urv6o/9n65dv/Hzxs1bEy1LxWCfSS7Vu5hq4JmAfZMZDu8KBTSPObyNl89c/9sjUDqT4o05LWCW04XI5hmjBl0HG7tb0WT68r2NiuwgMikYWt3W98s7JGK0WBQ6q1szEnEg5ym/qPr6YGNzPBzXH+kaYWNsBs23d3DzCosSycochGGcaj0Nx4WZWapMxjhU/ajUUFC2pAuYoiloDnpm64VXZAs9CZlLhb8wpPaeJSzNtT7NY1Tm1KS63eecvr5paeaPZjYTRWlAsNVE85ITI4nLIkkyBczwUzQoUxnGSlhKFWUGc702S6JdaDgCwdhxVzSJ3HRxnK/JWCoWBRprC7ZOaaTket0dS7k0NEZvP/oi0WCsTuWxFPxUwVzvGFWCUwg4ZjLPqUju2ojL48pGIHSpwKE2orxIaVW1dGm2SFvC2G15W/e8JVqtzT6vOsoJVX7txKP9buUzeeTRqty6jo76taEGtAdglNvXqCe4T9qJiMZkQwt/wtylOY/fb3haq7wDvPKv61VD4sXlLWLXT+w2hKCmVB2IqkVOT/x5afo6qWE8K/xE3dPRF9mqBqwhZ4tDh3gqFfBzcve0K4dDPJfCyLyFNF5rqx1beeLipf4WeM8H/ukJLdE2bDKdicQVTVdqSlHvcDuBq3rZvjRUWVcg/QkvICn8xPnAnhfY8wAJzOGwJT5irtBinRQ7qO9vkZwusbIfAbMViSVP+ljpjWuvjtq8v3Kszl2TFMfhCAvi5kY7NabQf4xGBk6GeHvYEk6wGooFDDGY0WEJur43o+3tcDwe4fEYIDfAIAcS3yb3dA2aqLF2Kvi6iHpx1TSc4XYsQQl8QR7kZfQ/1XgHtXczPNuqzgIVPkth+xHqGpPtYTgehi9/33z8qHmgrga/Br8Ft4MweBg8Dl4Ee8F+wIJ/gv+Cj8Gn3l+9w95J78NKevFCw/wSrH29vz8DDwXZAA==</latexit><latexit sha1_base64="P9kt+2hoUT1YphS4BYG+DBY0D5s=">AAAHyXicjZVbj9Q2FMcDFIZOgS70sS9WVytxm0tWRaBKK3ERElWl1XLZAWkyrBznzCQax87azl6w8tSv1C/TvsIH4TiTwk7iFUSKdHz8/9nHx/ZxXPBMm/H43wsXL/1w+Urv6o/9n65dv/Hzxs1bEy1LxWCfSS7Vu5hq4JmAfZMZDu8KBTSPObyNl89c/9sjUDqT4o05LWCW04XI5hmjBl0HG7tb0WT68r2NiuwgMikYWt3W98s7JGK0WBQ6q1szEnEg5ym/qPr6YGNzPBzXH+kaYWNsBs23d3DzCosSycochGGcaj0Nx4WZWapMxjhU/ajUUFC2pAuYoiloDnpm64VXZAs9CZlLhb8wpPaeJSzNtT7NY1Tm1KS63eecvr5paeaPZjYTRWlAsNVE85ITI4nLIkkyBczwUzQoUxnGSlhKFWUGc702S6JdaDgCwdhxVzSJ3HRxnK/JWCoWBRprC7ZOaaTket0dS7k0NEZvP/oi0WCsTuWxFPxUwVzvGFWCUwg4ZjLPqUju2ojL48pGIHSpwKE2orxIaVW1dGm2SFvC2G15W/e8JVqtzT6vOsoJVX7txKP9buUzeeTRqty6jo76taEGtAdglNvXqCe4T9qJiMZkQwt/wtylOY/fb3haq7wDvPKv61VD4sXlLWLXT+w2hKCmVB2IqkVOT/x5afo6qWE8K/xE3dPRF9mqBqwhZ4tDh3gqFfBzcve0K4dDPJfCyLyFNF5rqx1beeLipf4WeM8H/ukJLdE2bDKdicQVTVdqSlHvcDuBq3rZvjRUWVcg/QkvICn8xPnAnhfY8wAJzOGwJT5irtBinRQ7qO9vkZwusbIfAbMViSVP+ljpjWuvjtq8v3Kszl2TFMfhCAvi5kY7NabQf4xGBk6GeHvYEk6wGooFDDGY0WEJur43o+3tcDwe4fEYIDfAIAcS3yb3dA2aqLF2Kvi6iHpx1TSc4XYsQQl8QR7kZfQ/1XgHtXczPNuqzgIVPkth+xHqGpPtYTgehi9/33z8qHmgrga/Br8Ft4MweBg8Dl4Ee8F+wIJ/gv+Cj8Gn3l+9w95J78NKevFCw/wSrH29vz8DDwXZAA==</latexit><latexit sha1_base64="P9kt+2hoUT1YphS4BYG+DBY0D5s=">AAAHyXicjZVbj9Q2FMcDFIZOgS70sS9WVytxm0tWRaBKK3ERElWl1XLZAWkyrBznzCQax87azl6w8tSv1C/TvsIH4TiTwk7iFUSKdHz8/9nHx/ZxXPBMm/H43wsXL/1w+Urv6o/9n65dv/Hzxs1bEy1LxWCfSS7Vu5hq4JmAfZMZDu8KBTSPObyNl89c/9sjUDqT4o05LWCW04XI5hmjBl0HG7tb0WT68r2NiuwgMikYWt3W98s7JGK0WBQ6q1szEnEg5ym/qPr6YGNzPBzXH+kaYWNsBs23d3DzCosSycochGGcaj0Nx4WZWapMxjhU/ajUUFC2pAuYoiloDnpm64VXZAs9CZlLhb8wpPaeJSzNtT7NY1Tm1KS63eecvr5paeaPZjYTRWlAsNVE85ITI4nLIkkyBczwUzQoUxnGSlhKFWUGc702S6JdaDgCwdhxVzSJ3HRxnK/JWCoWBRprC7ZOaaTket0dS7k0NEZvP/oi0WCsTuWxFPxUwVzvGFWCUwg4ZjLPqUju2ojL48pGIHSpwKE2orxIaVW1dGm2SFvC2G15W/e8JVqtzT6vOsoJVX7txKP9buUzeeTRqty6jo76taEGtAdglNvXqCe4T9qJiMZkQwt/wtylOY/fb3haq7wDvPKv61VD4sXlLWLXT+w2hKCmVB2IqkVOT/x5afo6qWE8K/xE3dPRF9mqBqwhZ4tDh3gqFfBzcve0K4dDPJfCyLyFNF5rqx1beeLipf4WeM8H/ukJLdE2bDKdicQVTVdqSlHvcDuBq3rZvjRUWVcg/QkvICn8xPnAnhfY8wAJzOGwJT5irtBinRQ7qO9vkZwusbIfAbMViSVP+ljpjWuvjtq8v3Kszl2TFMfhCAvi5kY7NabQf4xGBk6GeHvYEk6wGooFDDGY0WEJur43o+3tcDwe4fEYIDfAIAcS3yb3dA2aqLF2Kvi6iHpx1TSc4XYsQQl8QR7kZfQ/1XgHtXczPNuqzgIVPkth+xHqGpPtYTgehi9/33z8qHmgrga/Br8Ft4MweBg8Dl4Ee8F+wIJ/gv+Cj8Gn3l+9w95J78NKevFCw/wSrH29vz8DDwXZAA==</latexit><latexit sha1_base64="P9kt+2hoUT1YphS4BYG+DBY0D5s=">AAAHyXicjZVbj9Q2FMcDFIZOgS70sS9WVytxm0tWRaBKK3ERElWl1XLZAWkyrBznzCQax87azl6w8tSv1C/TvsIH4TiTwk7iFUSKdHz8/9nHx/ZxXPBMm/H43wsXL/1w+Urv6o/9n65dv/Hzxs1bEy1LxWCfSS7Vu5hq4JmAfZMZDu8KBTSPObyNl89c/9sjUDqT4o05LWCW04XI5hmjBl0HG7tb0WT68r2NiuwgMikYWt3W98s7JGK0WBQ6q1szEnEg5ym/qPr6YGNzPBzXH+kaYWNsBs23d3DzCosSycochGGcaj0Nx4WZWapMxjhU/ajUUFC2pAuYoiloDnpm64VXZAs9CZlLhb8wpPaeJSzNtT7NY1Tm1KS63eecvr5paeaPZjYTRWlAsNVE85ITI4nLIkkyBczwUzQoUxnGSlhKFWUGc702S6JdaDgCwdhxVzSJ3HRxnK/JWCoWBRprC7ZOaaTket0dS7k0NEZvP/oi0WCsTuWxFPxUwVzvGFWCUwg4ZjLPqUju2ojL48pGIHSpwKE2orxIaVW1dGm2SFvC2G15W/e8JVqtzT6vOsoJVX7txKP9buUzeeTRqty6jo76taEGtAdglNvXqCe4T9qJiMZkQwt/wtylOY/fb3haq7wDvPKv61VD4sXlLWLXT+w2hKCmVB2IqkVOT/x5afo6qWE8K/xE3dPRF9mqBqwhZ4tDh3gqFfBzcve0K4dDPJfCyLyFNF5rqx1beeLipf4WeM8H/ukJLdE2bDKdicQVTVdqSlHvcDuBq3rZvjRUWVcg/QkvICn8xPnAnhfY8wAJzOGwJT5irtBinRQ7qO9vkZwusbIfAbMViSVP+ljpjWuvjtq8v3Kszl2TFMfhCAvi5kY7NabQf4xGBk6GeHvYEk6wGooFDDGY0WEJur43o+3tcDwe4fEYIDfAIAcS3yb3dA2aqLF2Kvi6iHpx1TSc4XYsQQl8QR7kZfQ/1XgHtXczPNuqzgIVPkth+xHqGpPtYTgehi9/33z8qHmgrga/Br8Ft4MweBg8Dl4Ee8F+wIJ/gv+Cj8Gn3l+9w95J78NKevFCw/wSrH29vz8DDwXZAA==</latexit>
Eu[Q⇡✓
(s, u) (s, u)
| {z }
CAPG
|s] = Eu[Q⇡✓
(s, u) (s, u)
| {z }
PG
|s]
<latexit sha1_base64="r9VmjpiqG9yfPAyr4yqiPQSOPS0=">AAAIAHicjZVbj9w0FMczLXTa4bZb3uiLxapSucwlKxAV0kptVyvgpZq27LbSZBg5zplJNI6dtZ29yM1LpX4X3hCvfBM+A1+C40yAncQrGimSffz/2cfH9jlxwTNtJpM/ezduvvf+rf7tO4MPPvzo4092du+eaFkqBsdMcqlexVQDzwQcm8xweFUooHnM4WW8PnTjL89A6UyKn81lAfOcrkS2zBg1aFrsvI2OFuUsKkUCKlaUgX32i42KbBGZFAytHuivyy9IxGixKnRW96qFjQxcGHv4ePpDVb3Wc3JA3m2azhTNBIudvcloUn+k2wibxl7QfNPF7i0WJZKVOQjDONV6Fk4KM7dUmYxxqAZRqaGgbE1XMMOmoDnoua3jVZH7aEnIUir8hSG19Sphaa71ZR6jMqcm1e0xZ/SNzUqzfDi3mShKA4JtFlqWnBhJXPBJkilghl9igzKVoa+EpRTjZfCItlZJtHMNZyDoOx6mJpFbLo7zLRlLxarAxtaGrVMaKbneNsdSrg2N0TqI/pVoMFan8lwKfqlgqQ+MKsEpBJwzmedUJF/aiMvzykYgdKnAoTaivEhpVbV0abZKW8LYnX9bd9QSbfZmj6qO8oQqv/bEo31n5aE882hVbt1AR/3CUAPaAzDK7QvUEzwn7UREY7ChhT9m7q1dxx83PK1V3gme+/f1vCHxvfMW8dRPPG0IQU2pOhBVq5xe+OPSjHVCw3hW+Il6pKMvsk1C2EKuZooO8UQq4NfE7klXDqd4L4WReQtprNZWB7by+MVL/X/gVz7wJ49ribZhE+lMJC7XulRTivqE2wHcZNb2o6HKumzpD3gBSeEnrgemXmDqARJYwmlLfMZcosU8KQ5QP7hPcroGEp0BsxWJJU8GEQfj+purthxsDJt71wTFcTjDiri1sZ0aU+jvx2OsBCN8PWwNF5gNxQpG6Mz4tARdv5vx/n44mYzxegyRG6KTQ4klzVW8YeM15k4F/22i3lw1C+d4HGtQAivIt3kZ/UM11mFt3Quv9qqrQIVlKWwXoW7jZH8UTkbhs2/2Hj1sCtTt4F7wefAgCIPvgkfBj8E0OA5Y8Fdvt/dZ717/Tf/X/m/93zfSG72G+TTY+vp//A2Fru9r</latexit><latexit sha1_base64="r9VmjpiqG9yfPAyr4yqiPQSOPS0=">AAAIAHicjZVbj9w0FMczLXTa4bZb3uiLxapSucwlKxAV0kptVyvgpZq27LbSZBg5zplJNI6dtZ29yM1LpX4X3hCvfBM+A1+C40yAncQrGimSffz/2cfH9jlxwTNtJpM/ezduvvf+rf7tO4MPPvzo4092du+eaFkqBsdMcqlexVQDzwQcm8xweFUooHnM4WW8PnTjL89A6UyKn81lAfOcrkS2zBg1aFrsvI2OFuUsKkUCKlaUgX32i42KbBGZFAytHuivyy9IxGixKnRW96qFjQxcGHv4ePpDVb3Wc3JA3m2azhTNBIudvcloUn+k2wibxl7QfNPF7i0WJZKVOQjDONV6Fk4KM7dUmYxxqAZRqaGgbE1XMMOmoDnoua3jVZH7aEnIUir8hSG19Sphaa71ZR6jMqcm1e0xZ/SNzUqzfDi3mShKA4JtFlqWnBhJXPBJkilghl9igzKVoa+EpRTjZfCItlZJtHMNZyDoOx6mJpFbLo7zLRlLxarAxtaGrVMaKbneNsdSrg2N0TqI/pVoMFan8lwKfqlgqQ+MKsEpBJwzmedUJF/aiMvzykYgdKnAoTaivEhpVbV0abZKW8LYnX9bd9QSbfZmj6qO8oQqv/bEo31n5aE882hVbt1AR/3CUAPaAzDK7QvUEzwn7UREY7ChhT9m7q1dxx83PK1V3gme+/f1vCHxvfMW8dRPPG0IQU2pOhBVq5xe+OPSjHVCw3hW+Il6pKMvsk1C2EKuZooO8UQq4NfE7klXDqd4L4WReQtprNZWB7by+MVL/X/gVz7wJ49ribZhE+lMJC7XulRTivqE2wHcZNb2o6HKumzpD3gBSeEnrgemXmDqARJYwmlLfMZcosU8KQ5QP7hPcroGEp0BsxWJJU8GEQfj+purthxsDJt71wTFcTjDiri1sZ0aU+jvx2OsBCN8PWwNF5gNxQpG6Mz4tARdv5vx/n44mYzxegyRG6KTQ4klzVW8YeM15k4F/22i3lw1C+d4HGtQAivIt3kZ/UM11mFt3Quv9qqrQIVlKWwXoW7jZH8UTkbhs2/2Hj1sCtTt4F7wefAgCIPvgkfBj8E0OA5Y8Fdvt/dZ717/Tf/X/m/93zfSG72G+TTY+vp//A2Fru9r</latexit><latexit sha1_base64="r9VmjpiqG9yfPAyr4yqiPQSOPS0=">AAAIAHicjZVbj9w0FMczLXTa4bZb3uiLxapSucwlKxAV0kptVyvgpZq27LbSZBg5zplJNI6dtZ29yM1LpX4X3hCvfBM+A1+C40yAncQrGimSffz/2cfH9jlxwTNtJpM/ezduvvf+rf7tO4MPPvzo4092du+eaFkqBsdMcqlexVQDzwQcm8xweFUooHnM4WW8PnTjL89A6UyKn81lAfOcrkS2zBg1aFrsvI2OFuUsKkUCKlaUgX32i42KbBGZFAytHuivyy9IxGixKnRW96qFjQxcGHv4ePpDVb3Wc3JA3m2azhTNBIudvcloUn+k2wibxl7QfNPF7i0WJZKVOQjDONV6Fk4KM7dUmYxxqAZRqaGgbE1XMMOmoDnoua3jVZH7aEnIUir8hSG19Sphaa71ZR6jMqcm1e0xZ/SNzUqzfDi3mShKA4JtFlqWnBhJXPBJkilghl9igzKVoa+EpRTjZfCItlZJtHMNZyDoOx6mJpFbLo7zLRlLxarAxtaGrVMaKbneNsdSrg2N0TqI/pVoMFan8lwKfqlgqQ+MKsEpBJwzmedUJF/aiMvzykYgdKnAoTaivEhpVbV0abZKW8LYnX9bd9QSbfZmj6qO8oQqv/bEo31n5aE882hVbt1AR/3CUAPaAzDK7QvUEzwn7UREY7ChhT9m7q1dxx83PK1V3gme+/f1vCHxvfMW8dRPPG0IQU2pOhBVq5xe+OPSjHVCw3hW+Il6pKMvsk1C2EKuZooO8UQq4NfE7klXDqd4L4WReQtprNZWB7by+MVL/X/gVz7wJ49ribZhE+lMJC7XulRTivqE2wHcZNb2o6HKumzpD3gBSeEnrgemXmDqARJYwmlLfMZcosU8KQ5QP7hPcroGEp0BsxWJJU8GEQfj+purthxsDJt71wTFcTjDiri1sZ0aU+jvx2OsBCN8PWwNF5gNxQpG6Mz4tARdv5vx/n44mYzxegyRG6KTQ4klzVW8YeM15k4F/22i3lw1C+d4HGtQAivIt3kZ/UM11mFt3Quv9qqrQIVlKWwXoW7jZH8UTkbhs2/2Hj1sCtTt4F7wefAgCIPvgkfBj8E0OA5Y8Fdvt/dZ717/Tf/X/m/93zfSG72G+TTY+vp//A2Fru9r</latexit><latexit sha1_base64="r9VmjpiqG9yfPAyr4yqiPQSOPS0=">AAAIAHicjZVbj9w0FMczLXTa4bZb3uiLxapSucwlKxAV0kptVyvgpZq27LbSZBg5zplJNI6dtZ29yM1LpX4X3hCvfBM+A1+C40yAncQrGimSffz/2cfH9jlxwTNtJpM/ezduvvf+rf7tO4MPPvzo4092du+eaFkqBsdMcqlexVQDzwQcm8xweFUooHnM4WW8PnTjL89A6UyKn81lAfOcrkS2zBg1aFrsvI2OFuUsKkUCKlaUgX32i42KbBGZFAytHuivyy9IxGixKnRW96qFjQxcGHv4ePpDVb3Wc3JA3m2azhTNBIudvcloUn+k2wibxl7QfNPF7i0WJZKVOQjDONV6Fk4KM7dUmYxxqAZRqaGgbE1XMMOmoDnoua3jVZH7aEnIUir8hSG19Sphaa71ZR6jMqcm1e0xZ/SNzUqzfDi3mShKA4JtFlqWnBhJXPBJkilghl9igzKVoa+EpRTjZfCItlZJtHMNZyDoOx6mJpFbLo7zLRlLxarAxtaGrVMaKbneNsdSrg2N0TqI/pVoMFan8lwKfqlgqQ+MKsEpBJwzmedUJF/aiMvzykYgdKnAoTaivEhpVbV0abZKW8LYnX9bd9QSbfZmj6qO8oQqv/bEo31n5aE882hVbt1AR/3CUAPaAzDK7QvUEzwn7UREY7ChhT9m7q1dxx83PK1V3gme+/f1vCHxvfMW8dRPPG0IQU2pOhBVq5xe+OPSjHVCw3hW+Il6pKMvsk1C2EKuZooO8UQq4NfE7klXDqd4L4WReQtprNZWB7by+MVL/X/gVz7wJ49ribZhE+lMJC7XulRTivqE2wHcZNb2o6HKumzpD3gBSeEnrgemXmDqARJYwmlLfMZcosU8KQ5QP7hPcroGEp0BsxWJJU8GEQfj+purthxsDJt71wTFcTjDiri1sZ0aU+jvx2OsBCN8PWwNF5gNxQpG6Mz4tARdv5vx/n44mYzxegyRG6KTQ4klzVW8YeM15k4F/22i3lw1C+d4HGtQAivIt3kZ/UM11mFt3Quv9qqrQIVlKWwXoW7jZH8UTkbhs2/2Hj1sCtTt4F7wefAgCIPvgkfBj8E0OA5Y8Fdvt/dZ717/Tf/X/m/93zfSG72G+TTY+vp//A2Fru9r</latexit>
Vu[Q⇡✓
(s, u) (s, u)
| {z }
CAPG
|s] Vu[Q⇡✓
(s, u) (s, u)
| {z }
PG
|s]
<latexit sha1_base64="FJAjQgycxGqmqAzY41DtUOdHBsQ=">AAAIAnicjZXdjtw0FMczBTpl+NrSS1rJYlWpQOcjKxAV0kptVxVwU01bdlppMowc58wkGsfO2s5+yM1dJd6FO8QtL8JD8A4cZwLsJF7RSJHs4//PPj62z4kLnmkzmfzZu/bOu+9d7994f/DBhx99/MnezU9nWpaKwTGTXKpXMdXAMwHHJjMcXhUKaB5zeBlvjtz4y1NQOpPiJ3NRwCKna5GtMkYNmpZ7v0SzZTmPSpGAihVlYJ/9bKMiW0YmBUOre/p++QWJGC3Whc7qXrW0kYFzY48eTb+vqtd6QSIO5O0m6kzSTLHc25+MJvVHuo2waewHzTdd3rzOokSyMgdhGKdaz8NJYRaWKpMxDtUgKjUUlG3oGubYFDQHvbB1xCpyFy0JWUmFvzCktl4mLM21vshjVObUpLo95oy+sXlpVg8WNhNFaUCw7UKrkhMjiQs/STIFzPALbFCmMvSVsJRivAwe0s4qiXau4QwEfcfj1CRyy8VxviNjqVgX2NjZsHVKIyXXu+ZYyo2hMVoH0b8SDcbqVJ5JwS8UrPShUSU4hYAzJvOciuRLG3F5VtkIhC4VONRGlBcpraqWLs3WaUsYu/Nv6560RNu92SdVRzmjyq+debRvrTySpx6tyq0b6KhfGGpAewBGuX2BeoLnpJ2IaAw2tPBHzL22q/jjhqe1yjvBc/++njckvnjeIp76iacNIagpVQeiap3Tc39cmrFOaBjPCj9Rj3T0RbZNCDvI5UzRIR5LBfyK2D3uyuEE76UwMm8hjdXa6tBWHr94qf8P/MoH/uhxLdE2bCKdicRlW5dqSlGfcDuA29zafjRUWZct/QEvICn8xNXA1AtMPUACKzhpiU+ZS7SYJ8Uh6gd3SU43mPRPgdmKxJInAywCxvW3V2012Bq2964JiuNwhjVxa2M7NabQ343HWAlG+HrYBs4xG4o1jNCZ8UkJun4344ODcDIZ4/UYIjdEJ4cSi5qrecPGa8ydCv7bRL25ah4u8Dg2oARWkG/yMvqHaqzD2rofXu5Vl4EKy1LYLkLdxuxgFE5G4bOv9x8+aArUjeCz4PPgXhAG3wYPgx+CaXAcsOCv3q3e7d6d/pv+r/3f+r9vpdd6DXMr2Pn6f/wN8BPwkQ==</latexit><latexit sha1_base64="FJAjQgycxGqmqAzY41DtUOdHBsQ=">AAAIAnicjZXdjtw0FMczBTpl+NrSS1rJYlWpQOcjKxAV0kptVxVwU01bdlppMowc58wkGsfO2s5+yM1dJd6FO8QtL8JD8A4cZwLsJF7RSJHs4//PPj62z4kLnmkzmfzZu/bOu+9d7994f/DBhx99/MnezU9nWpaKwTGTXKpXMdXAMwHHJjMcXhUKaB5zeBlvjtz4y1NQOpPiJ3NRwCKna5GtMkYNmpZ7v0SzZTmPSpGAihVlYJ/9bKMiW0YmBUOre/p++QWJGC3Whc7qXrW0kYFzY48eTb+vqtd6QSIO5O0m6kzSTLHc25+MJvVHuo2waewHzTdd3rzOokSyMgdhGKdaz8NJYRaWKpMxDtUgKjUUlG3oGubYFDQHvbB1xCpyFy0JWUmFvzCktl4mLM21vshjVObUpLo95oy+sXlpVg8WNhNFaUCw7UKrkhMjiQs/STIFzPALbFCmMvSVsJRivAwe0s4qiXau4QwEfcfj1CRyy8VxviNjqVgX2NjZsHVKIyXXu+ZYyo2hMVoH0b8SDcbqVJ5JwS8UrPShUSU4hYAzJvOciuRLG3F5VtkIhC4VONRGlBcpraqWLs3WaUsYu/Nv6560RNu92SdVRzmjyq+debRvrTySpx6tyq0b6KhfGGpAewBGuX2BeoLnpJ2IaAw2tPBHzL22q/jjhqe1yjvBc/++njckvnjeIp76iacNIagpVQeiap3Tc39cmrFOaBjPCj9Rj3T0RbZNCDvI5UzRIR5LBfyK2D3uyuEE76UwMm8hjdXa6tBWHr94qf8P/MoH/uhxLdE2bCKdicRlW5dqSlGfcDuA29zafjRUWZct/QEvICn8xNXA1AtMPUACKzhpiU+ZS7SYJ8Uh6gd3SU43mPRPgdmKxJInAywCxvW3V2012Bq2964JiuNwhjVxa2M7NabQ343HWAlG+HrYBs4xG4o1jNCZ8UkJun4344ODcDIZ4/UYIjdEJ4cSi5qrecPGa8ydCv7bRL25ah4u8Dg2oARWkG/yMvqHaqzD2rofXu5Vl4EKy1LYLkLdxuxgFE5G4bOv9x8+aArUjeCz4PPgXhAG3wYPgx+CaXAcsOCv3q3e7d6d/pv+r/3f+r9vpdd6DXMr2Pn6f/wN8BPwkQ==</latexit><latexit sha1_base64="FJAjQgycxGqmqAzY41DtUOdHBsQ=">AAAIAnicjZXdjtw0FMczBTpl+NrSS1rJYlWpQOcjKxAV0kptVxVwU01bdlppMowc58wkGsfO2s5+yM1dJd6FO8QtL8JD8A4cZwLsJF7RSJHs4//PPj62z4kLnmkzmfzZu/bOu+9d7994f/DBhx99/MnezU9nWpaKwTGTXKpXMdXAMwHHJjMcXhUKaB5zeBlvjtz4y1NQOpPiJ3NRwCKna5GtMkYNmpZ7v0SzZTmPSpGAihVlYJ/9bKMiW0YmBUOre/p++QWJGC3Whc7qXrW0kYFzY48eTb+vqtd6QSIO5O0m6kzSTLHc25+MJvVHuo2waewHzTdd3rzOokSyMgdhGKdaz8NJYRaWKpMxDtUgKjUUlG3oGubYFDQHvbB1xCpyFy0JWUmFvzCktl4mLM21vshjVObUpLo95oy+sXlpVg8WNhNFaUCw7UKrkhMjiQs/STIFzPALbFCmMvSVsJRivAwe0s4qiXau4QwEfcfj1CRyy8VxviNjqVgX2NjZsHVKIyXXu+ZYyo2hMVoH0b8SDcbqVJ5JwS8UrPShUSU4hYAzJvOciuRLG3F5VtkIhC4VONRGlBcpraqWLs3WaUsYu/Nv6560RNu92SdVRzmjyq+debRvrTySpx6tyq0b6KhfGGpAewBGuX2BeoLnpJ2IaAw2tPBHzL22q/jjhqe1yjvBc/++njckvnjeIp76iacNIagpVQeiap3Tc39cmrFOaBjPCj9Rj3T0RbZNCDvI5UzRIR5LBfyK2D3uyuEE76UwMm8hjdXa6tBWHr94qf8P/MoH/uhxLdE2bCKdicRlW5dqSlGfcDuA29zafjRUWZct/QEvICn8xNXA1AtMPUACKzhpiU+ZS7SYJ8Uh6gd3SU43mPRPgdmKxJInAywCxvW3V2012Bq2964JiuNwhjVxa2M7NabQ343HWAlG+HrYBs4xG4o1jNCZ8UkJun4344ODcDIZ4/UYIjdEJ4cSi5qrecPGa8ydCv7bRL25ah4u8Dg2oARWkG/yMvqHaqzD2rofXu5Vl4EKy1LYLkLdxuxgFE5G4bOv9x8+aArUjeCz4PPgXhAG3wYPgx+CaXAcsOCv3q3e7d6d/pv+r/3f+r9vpdd6DXMr2Pn6f/wN8BPwkQ==</latexit><latexit sha1_base64="FJAjQgycxGqmqAzY41DtUOdHBsQ=">AAAIAnicjZXdjtw0FMczBTpl+NrSS1rJYlWpQOcjKxAV0kptVxVwU01bdlppMowc58wkGsfO2s5+yM1dJd6FO8QtL8JD8A4cZwLsJF7RSJHs4//PPj62z4kLnmkzmfzZu/bOu+9d7994f/DBhx99/MnezU9nWpaKwTGTXKpXMdXAMwHHJjMcXhUKaB5zeBlvjtz4y1NQOpPiJ3NRwCKna5GtMkYNmpZ7v0SzZTmPSpGAihVlYJ/9bKMiW0YmBUOre/p++QWJGC3Whc7qXrW0kYFzY48eTb+vqtd6QSIO5O0m6kzSTLHc25+MJvVHuo2waewHzTdd3rzOokSyMgdhGKdaz8NJYRaWKpMxDtUgKjUUlG3oGubYFDQHvbB1xCpyFy0JWUmFvzCktl4mLM21vshjVObUpLo95oy+sXlpVg8WNhNFaUCw7UKrkhMjiQs/STIFzPALbFCmMvSVsJRivAwe0s4qiXau4QwEfcfj1CRyy8VxviNjqVgX2NjZsHVKIyXXu+ZYyo2hMVoH0b8SDcbqVJ5JwS8UrPShUSU4hYAzJvOciuRLG3F5VtkIhC4VONRGlBcpraqWLs3WaUsYu/Nv6560RNu92SdVRzmjyq+debRvrTySpx6tyq0b6KhfGGpAewBGuX2BeoLnpJ2IaAw2tPBHzL22q/jjhqe1yjvBc/++njckvnjeIp76iacNIagpVQeiap3Tc39cmrFOaBjPCj9Rj3T0RbZNCDvI5UzRIR5LBfyK2D3uyuEE76UwMm8hjdXa6tBWHr94qf8P/MoH/uhxLdE2bCKdicRlW5dqSlGfcDuA29zafjRUWZct/QEvICn8xNXA1AtMPUACKzhpiU+ZS7SYJ8Uh6gd3SU43mPRPgdmKxJInAywCxvW3V2012Bq2964JiuNwhjVxa2M7NabQ343HWAlG+HrYBs4xG4o1jNCZ8UkJun4344ODcDIZ4/UYIjdEJ4cSi5qrecPGa8ydCv7bRL25ah4u8Dg2oARWkG/yMvqHaqzD2rofXu5Vl4EKy1LYLkLdxuxgFE5G4bOv9x8+aArUjeCz4PPgXhAG3wYPgx+CaXAcsOCv3q3e7d6d/pv+r/3f+r9vpdd6DXMr2Pn6f/wN8BPwkQ==</latexit>](https://image.slidesharecdn.com/icml2018capgupload-180728051747/85/Clipped-Action-Policy-Gradient-8-320.jpg)