Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning Lab(ディープラーニング・ラボ)
PDF, PPTX
3,271 views
[Track2-5] CPUだけでAIをやり切った最近のお客様事例 と インテルの先進的な取り組み
2020/8/1 Deep Learning Digital Conference インテル株式会社 大内山 浩 氏
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 26
2
/ 26
3
/ 26
4
/ 26
5
/ 26
6
/ 26
7
/ 26
8
/ 26
9
/ 26
10
/ 26
11
/ 26
12
/ 26
13
/ 26
14
/ 26
15
/ 26
16
/ 26
17
/ 26
18
/ 26
19
/ 26
20
/ 26
21
/ 26
22
/ 26
23
/ 26
24
/ 26
25
/ 26
26
/ 26
More Related Content
PDF
いまさら聞けないarmを使ったNEONの基礎と活用事例
by
Fixstars Corporation
PPTX
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
PDF
機械学習モデルのハイパパラメータ最適化
by
gree_tech
PPTX
MS COCO Dataset Introduction
by
Shinagawa Seitaro
PPTX
モデル高速化百選
by
Yusuke Uchida
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
PPTX
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
by
Yosuke Shinya
PDF
Active Learning 入門
by
Shuyo Nakatani
いまさら聞けないarmを使ったNEONの基礎と活用事例
by
Fixstars Corporation
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
機械学習モデルのハイパパラメータ最適化
by
gree_tech
MS COCO Dataset Introduction
by
Shinagawa Seitaro
モデル高速化百選
by
Yusuke Uchida
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
by
Yosuke Shinya
Active Learning 入門
by
Shuyo Nakatani
What's hot
PDF
カスタムSIで使ってみよう ~ OpenAI Gym を使った強化学習
by
Hori Tasuku
PDF
A100 GPU 搭載! P4d インスタンス 使いこなしのコツ
by
Kuninobu SaSaki
PDF
全力解説!Transformer
by
Arithmer Inc.
PDF
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PPT
Gurobi python
by
Mikio Kubo
PDF
モジュールの凝集度・結合度・インタフェース
by
Hajime Yanagawa
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PDF
言語モデル入門 (第二版)
by
Yoshinari Fujinuma
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
PDF
ブースティング入門
by
Retrieva inc.
PDF
一般向けのDeep Learning
by
Preferred Networks
PPTX
畳み込みニューラルネットワークの研究動向
by
Yusuke Uchida
PDF
3D CNNによる人物行動認識の動向
by
Kensho Hara
PDF
論文紹介:Temporal Action Segmentation: An Analysis of Modern Techniques
by
Toru Tamaki
PPTX
強化学習 DQNからPPOまで
by
harmonylab
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
PCAの最終形態GPLVMの解説
by
弘毅 露崎
カスタムSIで使ってみよう ~ OpenAI Gym を使った強化学習
by
Hori Tasuku
A100 GPU 搭載! P4d インスタンス 使いこなしのコツ
by
Kuninobu SaSaki
全力解説!Transformer
by
Arithmer Inc.
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
Gurobi python
by
Mikio Kubo
モジュールの凝集度・結合度・インタフェース
by
Hajime Yanagawa
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
言語モデル入門 (第二版)
by
Yoshinari Fujinuma
深層学習の数理
by
Taiji Suzuki
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
ブースティング入門
by
Retrieva inc.
一般向けのDeep Learning
by
Preferred Networks
畳み込みニューラルネットワークの研究動向
by
Yusuke Uchida
3D CNNによる人物行動認識の動向
by
Kensho Hara
論文紹介:Temporal Action Segmentation: An Analysis of Modern Techniques
by
Toru Tamaki
強化学習 DQNからPPOまで
by
harmonylab
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PCAの最終形態GPLVMの解説
by
弘毅 露崎
Similar to [Track2-5] CPUだけでAIをやり切った最近のお客様事例 と インテルの先進的な取り組み
PDF
FPGAを用いたEdge AIの現状
by
Yukitaka Takemura
PDF
OpenVINOとAzure こう連携できるのでは?
by
Hiroshi Ouchiyama
PDF
AMD_Xilinx_AI_VCK5000_20220602R1.pdf
by
直久 住川
PDF
第11回ACRiウェビナー_インテル/竹村様ご講演資料
by
直久 住川
PDF
PCCC22:インテル株式会社 テーマ1「インテル® Agilex™ FPGA デバイス 最新情報」
by
PC Cluster Consortium
PDF
【de:code 2020】 AI on IA 最新情報 ~ CPU で AI を上手に動かすための 5 つのヒント ~
by
日本マイクロソフト株式会社
PDF
Intel AI in Healthcare 各国事例からみるAIとの向き合い方
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
【日商USA】インフラ担当者向け AIインフラとEdge AI 最新トレンド
by
Sojitz Tech-Innovation USA
PDF
IoTの技術的課題と実現のポイント~実装例・エンジニアリングのヒント
by
Trainocate Japan, Ltd.
PDF
IoTの技術的課題と実現のポイント~実装例・エンジニアリングのヒント
by
Trainocate Japan, Ltd.
PDF
AIアクセラレータによって実現する次世代AI革新の最前線:研究開発から産業応用までの全貌
by
Data Source
PDF
AiとIoTによる産業最適化と社会問題解決
by
Osaka University
PDF
Microsoft の深層学習への取り組み
by
Hirono Jumpei
PPTX
Microsoft AI Platform
by
Daiyu Hatakeyama
PPTX
IoT World Conference 2017 - Microsoft AI Platform
by
Daiyu Hatakeyama
PPTX
不足するAI人材に対する「パソナテックの人材育成ソリューション」
by
Natsutani Minoru
PPTX
【日商USA】webinar 2023.10.6 クラウドだけじゃない!Edge AIの進化とは?
by
Sojitz Tech-Innovation USA
PDF
IVS CTO Night & Day 2016 Tech Talk - AI
by
Toshiaki Enami
PDF
MII conference177 nvidia
by
Tak Izaki
PDF
インテルFPGAのDeep Learning Acceleration SuiteとマイクロソフトのBrainwaveをHW視点から比較してみる Intel編
by
Deep Learning Lab(ディープラーニング・ラボ)
FPGAを用いたEdge AIの現状
by
Yukitaka Takemura
OpenVINOとAzure こう連携できるのでは?
by
Hiroshi Ouchiyama
AMD_Xilinx_AI_VCK5000_20220602R1.pdf
by
直久 住川
第11回ACRiウェビナー_インテル/竹村様ご講演資料
by
直久 住川
PCCC22:インテル株式会社 テーマ1「インテル® Agilex™ FPGA デバイス 最新情報」
by
PC Cluster Consortium
【de:code 2020】 AI on IA 最新情報 ~ CPU で AI を上手に動かすための 5 つのヒント ~
by
日本マイクロソフト株式会社
Intel AI in Healthcare 各国事例からみるAIとの向き合い方
by
Deep Learning Lab(ディープラーニング・ラボ)
【日商USA】インフラ担当者向け AIインフラとEdge AI 最新トレンド
by
Sojitz Tech-Innovation USA
IoTの技術的課題と実現のポイント~実装例・エンジニアリングのヒント
by
Trainocate Japan, Ltd.
IoTの技術的課題と実現のポイント~実装例・エンジニアリングのヒント
by
Trainocate Japan, Ltd.
AIアクセラレータによって実現する次世代AI革新の最前線:研究開発から産業応用までの全貌
by
Data Source
AiとIoTによる産業最適化と社会問題解決
by
Osaka University
Microsoft の深層学習への取り組み
by
Hirono Jumpei
Microsoft AI Platform
by
Daiyu Hatakeyama
IoT World Conference 2017 - Microsoft AI Platform
by
Daiyu Hatakeyama
不足するAI人材に対する「パソナテックの人材育成ソリューション」
by
Natsutani Minoru
【日商USA】webinar 2023.10.6 クラウドだけじゃない!Edge AIの進化とは?
by
Sojitz Tech-Innovation USA
IVS CTO Night & Day 2016 Tech Talk - AI
by
Toshiaki Enami
MII conference177 nvidia
by
Tak Izaki
インテルFPGAのDeep Learning Acceleration SuiteとマイクロソフトのBrainwaveをHW視点から比較してみる Intel編
by
Deep Learning Lab(ディープラーニング・ラボ)
More from Deep Learning Lab(ディープラーニング・ラボ)
PDF
Edge AI ソリューションを支える Azure IoT サービス
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
深層強化学習を用いた複合機の搬送制御
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream With Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
厚生労働分野におけるAI技術の利活用について
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
AIによる細胞診支援技術の紹介と、AI人材が考える医療バイオ領域における参入障壁の乗り越え方
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Azure ML 強化学習を用いた最新アルゴリズムの活用手法
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson 活用による スタートアップ企業支援
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Jetson x Azure ハンズオン DeepStream With Azure IoT 事前準備
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
「言語」×AI Digital Device
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
医学と工学の垣根を越えた医療AI開発
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
DLLAB Healthcare Day 2021 Event Report
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
[Track3-4] アカデミックにおけるAI/ディープラーニング の教育と学習支援に関する研究
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
先端技術がもたらす「より良いヘルスケアのかたち」
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
ICTを用いた健康なまちづくりの 取り組みとAI活用への期待
by
Deep Learning Lab(ディープラーニング・ラボ)
Edge AI ソリューションを支える Azure IoT サービス
by
Deep Learning Lab(ディープラーニング・ラボ)
深層強化学習を用いた複合機の搬送制御
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream With Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream Azure IoT
by
Deep Learning Lab(ディープラーニング・ラボ)
深層強化学習と実装例
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測
by
Deep Learning Lab(ディープラーニング・ラボ)
厚生労働分野におけるAI技術の利活用について
by
Deep Learning Lab(ディープラーニング・ラボ)
AIによる細胞診支援技術の紹介と、AI人材が考える医療バイオ領域における参入障壁の乗り越え方
by
Deep Learning Lab(ディープラーニング・ラボ)
Azure ML 強化学習を用いた最新アルゴリズムの活用手法
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson 活用による スタートアップ企業支援
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略
by
Deep Learning Lab(ディープラーニング・ラボ)
Jetson x Azure ハンズオン DeepStream With Azure IoT 事前準備
by
Deep Learning Lab(ディープラーニング・ラボ)
「言語」×AI Digital Device
by
Deep Learning Lab(ディープラーニング・ラボ)
医学と工学の垣根を越えた医療AI開発
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~
by
Deep Learning Lab(ディープラーニング・ラボ)
DLLAB Healthcare Day 2021 Event Report
by
Deep Learning Lab(ディープラーニング・ラボ)
[Track3-4] アカデミックにおけるAI/ディープラーニング の教育と学習支援に関する研究
by
Deep Learning Lab(ディープラーニング・ラボ)
先端技術がもたらす「より良いヘルスケアのかたち」
by
Deep Learning Lab(ディープラーニング・ラボ)
ICTを用いた健康なまちづくりの 取り組みとAI活用への期待
by
Deep Learning Lab(ディープラーニング・ラボ)
Recently uploaded
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PDF
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PMBOK 7th Edition Project Management Process Scrum
by
akipii ogaoga
PMBOK 7th Edition_Project Management Context Diagram
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
FY2025 IT Strategist Afternoon I Question-1 Balanced Scorecard
by
akipii ogaoga
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PMBOK 7th Edition_Project Management Process_WF Type Development
by
akipii ogaoga
[Track2-5] CPUだけでAIをやり切った最近のお客様事例 と インテルの先進的な取り組み
1.
インテル株式会社 APJデータセンター・グループ・セールス AI・テクニカル・ソリューション・スペシャリスト 大内山 浩 DLLAB Deep
Learning Digital Conference (2020/8/1) CPUだけでAIをやり切った ここ最近のお客様事例と インテルの先進的な取り組みのご紹介
2.
2 注意:本日、製品紹介はほぼ致しません。 インテルのAI関連製品に関してはこちらへどうぞ↓ https://webinar.intel.com/Intel_AI _Park_online https://www.cvent.com/events/- 2020/event-summary- afa95371020345e68f58bc85691cfe 7b.aspx https://www.youtube.com/watch? v=Uf1aYXbalZU Intel AI Park
インテル・データ・セントリック・ イノベーション・デイ 2020 Microsoft de:code 2020
3.
3
4.
4 インテルのAI事業 サーバー/PC/デバイス メーカー企業様 SI/ISV/クラウド企業様 等 ユーザー企業様 新規ビジネス創出、市場開発等で協業 AI導入までのトータル技術支援 (コンサル~実装~導入) → こうした活動から得られた事例を紹 介 ※全てインテルのCPUベース 協業
5.
AIは動かしてこそ意味がある モデルを作った後も重要! 5 課題発見 データ 学習
導入 1 2 3 4 性能 セキュ リティ 精度維 持 スケー ラビリ ティ アーキ テク チャ デザイ ン ・・ ・
6.
6 製造 メディア 流通 スマート ホーム
テレコム 交通 あらゆる業界へのAI導入を体現 農業 エネルギー 教育 公共 金融 医療 理化学研究所 様 大手電池 メーカー 様 中国銀聯 様
7.
7 ①理化学研究所 様 胸部疾患の自動診断 課題 手段 結果 • モデル:CheXNet(DenseNet121ベース、胸部疾患の画像分類などに利用、PyTorch
1.2.0) • 当該モデルを用いたX線画像分類サービスの実用化をするうえで、アクセラレータを使用し ないで推論処理(バッチ処理)の性能を向上させたい。 • 第2世代 インテル® Xeon® スケーラブル・プロセッサー • インテル® OpenVINO™ ツールキット • モデルの量子化(FP32→INT8) • 並列プログラミング • 当初の推論性能から44倍の向上を実現
8.
8 理化学研究所 様 胸部疾患の自動診断 -
詳細 744 sec 11,177 sec (Baseline) 1,116 sec 359 sec 251 sec on 他社アクセラレータ on Xeon 6252 x2 約2.2万枚のテスト画像 をバッチ処理で推論 → After OptimizationBefore Optimization← x10.0 x3.1 x1.4 上記対応内容は下記Githubを参照 https://github.com/taneishi/CheXNet (計算科学研究機構 種石 様のレポジトリ) x 44.5 against Baseline • モデルをONNXに変換 • OpenVINOのモデルオプ ティマイザーで ONNX→IRへ変換 • OpenVINOの推論エンジ ン上で同期実行 • OpenVINOの量子化ツー ルにてIR内一部のレイ ヤーの数値表現をINT8へ 変換(ツールのカスタマ イズ含む) • OpenVINOの推論エンジ ン上で同期実行(VNNI 利用) • OpenVINOの推論エンジ ン上で非同期実行(8並 列で推論処理を実行) 最適化 量子化 並列化
9.
9 ②中国銀聯 様 カード不正利用検知システム 課題 手段 結果 • モデル:GRU(Tensorflow
1.2.0) • よりRecall、および、Precisionともにより高い精度が必要 • 1日あたり最大数百億トランザクションからリアルタイムに検出したい • 第2世代 インテル® Xeon® スケーラブル・プロセッサー • インテル® Optimized Tensorflow • Scikit-learn • GBDT、GRU、ランダムフォレスト • それまでの手法に比べてF1を1.3倍以上向上
10.
10 中国銀聯 様 カード不正利用検知システム -
詳細 https://arxiv.org/ftp/arxiv/papers/1711/1711.01434.pdf LSTM/GRU”だけ”を使った場合の課題 トランザクションのシーケンシャルな事 象に対して認識精度は優れていたが、 個々のトランザクションの内容まで加味 しての認識精度が期待以下。 GBDT、GRUそれぞれ による特徴量抽出 RandomForest
11.
11 中国銀聯 様 カード不正利用検知システム -
詳細 続き https://www.intel.com/content/dam/www/public/us/en/documents/case-studies/fraud-detections-models-case-study.pdf それまでの方法に比較してF1値が向上 実際のデータフロー
12.
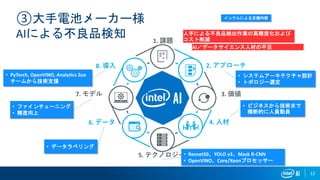
12 ③大手電池メーカー様 AIによる不良品検知 2. アプローチ 3. 価値 5.
テクノロジー 7. モデル 4. 人材 8. 導入 1. 課題 6. データ • システムアーキテクチャ設計 • トポロジー選定 • PyTorch, OpenVINO, Analytics Zoo チームから技術支援 • ファインチューニング • 精度向上 • データラベリング • ビジネスから技術まで 横断的に人員動員 • Resnet50、YOLO v3、Mask R-CNN • OpenVINO、Core/Xeonプロセッサー インテルによる支援内容 人手による不良品検出作業の高精度化および コスト削減 AI/データサイエンス人材の不足
13.
13 大手電池メーカー様 不良品検出における要件 不良品の種別 サンプル画像 インテルからの提案 1 絶縁フィルム同士の隙間の ずれやサイズが正しくない 画像セグメンテーション
(MASK-RCNN) を採用。 ずれを検出し、ピクセル単位でサイズを計測 2 絶縁フィルム自体の異常 (破 れ, 欠け, 折れ, 等) 多クラス分類問題として扱い、Resnet50による 異常を検出 3 陰極と陽極のヘッドのずれ 物体検出 (tiny Yolo_v3)を採用し、陰極と陽極を 検出後に、Bounding Boxからずれをチェック 製造ラインから送られる画像データの仕様 • 画像Resolution: 1920*1200 • データスピード: 7614 images/sec (1工場あたり) 検出精度要件: • 1DPPM(エラー率:1/100万)
14.
14 Accuracy向上のためにDL+MLアンサンブル ▪ Resnet50による特徴量抽出+SVMによる分類 最終性能 大手電池メーカー様 モデルの精度およびパフォーマンスの向上 CNN Layers FC
Layers Resnet50 97.85% precision 94.00% recall CNN Layers Resnet50+ SVM Classifier 99.12% precision 99.16% recall ML Classifier Finetune Baseline Final Result Precision 97.85% 99.12% recall 94% 99.16% 97.85% 99.12% 94% 99.16% Precision & Recall Rate Precision recall Customer Request Final Result FPS 423 570 423 570 Per Line FPS FPS 線形 (FPS)
15.
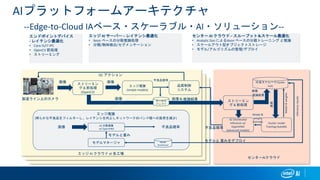
AIプラットフォームアーキテクチャ --Edge-to-Cloud IAベース・スケーラブル・AI・ソリューション-- エンドポイントデバイス - レイテンシ最適化 •
Core i5/i7 IPC • OpenCV 前処理 • ストリーミング エッジ AI サーバー – レイテンシ最適化 • Xeon ベースの分散推論処理 • 分類/物体検出/セグメンテーション センター AI クラウド – スループット&スケール最適化 • Analytic Zoo によるXeon ベースの分散トレーニング と推論 • スケールアウト型オブジェクトストレージ • モデル/アルゴリズムの管理/デプロイ エッジ AI クラウド at 各工場 製造ライン上のカメラ ストリーミン グ & 前処理 (OpenCV) エッジ推論 (simple models) エッジ推論 (明らかな不良品をフィルターし、レイテンシを向上しネットワークのバンド幅への負荷を減少) AZ 分散推論 w/ OpenVINO 画像 画像 画像 不良品確率 品質制御 システム 不良品確率 ローカル バッファ モデルマネージャ モデルと重み Model Warehouse 中央ストレージ (scale- out) ストリーミン グ & 前処理 AZ Distributed Inference w/ OpenVINO (advanced models) Cluster model Training+AutoML Model & weight matrixes 画像&推論結果画像 不良品確率 画像 推論結果 画像 Model&weights Inferenceresults モデルと 重みをデプロイ センターAIクラウド QC アクション
16.
16 製造 メディア 流通 スマート ホーム
テレコム 交通 あらゆる業界へのAI導入を体現 農業 エネルギー 教育 公共 金融 医療 理化学研究所 様 大手電池 メーカー様 中国銀聯 様 推論性能改善モデル精度改善 トータル ソリューション提供
17.
17 各業界向けAI実践ガイドブック提供中! 是非お近くのインテル社員までお尋ねください!! 製造業界向け AI実践ガイドブック
18.
18 インテル社内でのAI活用事例 https://webinar.intel.com/Intel_AI _Park_online Intel AI Park その他、パナソニック株式会社様、Slack
Japan株式会社様に よるウェビナー講演もお送りします
19.
19
20.
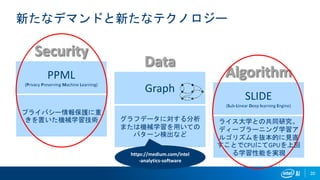
20 新たなデマンドと新たなテクノロジー Security Data AlgorithmPPML (Privacy Preserving Machine
Learning) Graph SLIDE (Sub-LInear Deep learning Engine) - ★ - ★ - - - - - - - ★ - ★ - - - - - ★ - ★ - ★ - - - - - - - - - ★ - - - ★ - - - - - - ★ ★ ★ - - A = From vertex (rows) Graphs as Linear Algebra 1 5 3 2 0 46 プライバシー情報保護に重 きを置いた機械学習技術 グラフデータに対する分析 または機械学習を用いての パターン検出など ライス大学との共同研究。 ディープラーニング学習ア ルゴリズムを抜本的に見直 すことでCPUにてGPUを上回 る学習性能を実現https://medium.com/intel -analytics-software
21.
21 PPMLの応用例:Federated Learning ~ペンシルベニア大学様との共同研究~ U-Netの学習にFederated Learningを適用。データ保護にインテル®
SGX活用。 https://www.intel.ai/federated-learning-for-medical-imaging/ Horizontal Federated Learning Vertical Federated Learning Federated Transfer Learning ノード間でのデータ共有無しに モデルの学習を実施 通常の分散学習と同程度 のモデル精度を獲得
22.
22 インテル® SGX(Software Guard
Extensions)について データを保護 (暗号化)した状態でメモリ内での計算を実現するCPUの技術です。 https://www.intel.co.jp/content/www/jp/ja/architecture-and-technology/software-guard-extensions.html • ハードウェア攻撃 • プロセス内攻撃 • OSによる攻撃 • SGXサポートのインテルCPU • https://www.intel.co.jp/content/ww w/jp/ja/support/articles/000028173/ processors.html • Azure Confidential Computing • http://aka.ms/AzureCC • SDK • SGX SDK: https://github.com/intel/linux-sgx- driver • Graphene: https://github.com/oscarlab/graphen e 保存中 転送中 使用中 暗号化 により 保護 (既存技術) メモリ 内で使 用中も 暗号化 何を実現する技術か? どんな脅威が防げるか? どのように使うのか? Graphene-SGXの論文より
23.
23 背景 課題と解決アプローチ SLIDE (Sub-LInear
Deep learning Engine) ~技術の登場背景~ Forward Pass Backward Pass × 大量の行列計算 GPUが 有利 Adaptive Sparsity 既存の学習手法 Adaptive Sparsityを意識 せずフル行列計算によ り膨大なパラメータを 更新 新たな学習手法 Adaptive Samplingという 技術で適切なニューロ ンだけを特定(探索)し てパラメータを更新 論文はこちら:https://www.cs.rice.edu/~as143/Papers/SLIDE_MLSys.pdf
24.
24 LSHハッシュテーブルを用いて、 各層毎に入力データおよびアク ティベーションと関連する ニューロンを特定し、それらの パラメータのみを更新 各層毎に大きなハッシュテーブ ルを持つため大量メモリを消費。 起こる問題の一つとして 「キャッシュスラッシング」が 上げられるが、インテルのサ ポートにより解決 Amazon-670Kのデータにて、CPU (Xeon)がGPU(Volta)よりも 3.5倍高速な学習時間を達成 SLIDE(Sub-LInear Deep learning
Engine) ~技術概要と効果~ コードはこちら:https://github.com/keroro824/HashingDeepLearning 処理概要 技術的改善点 効果 メインメモリアクセ ス時にキャッシュの 追い出しが毎度発生 (スラッシング)
25.
25 © 2020 Intel
Corporation AIを実学へ 2. アプローチ 3. 価値 5. テクノロジー 7. モデル 4. 人材 8. 導入 1. 課題 6. データ インテルとの 連携により AI の取り組みが加速
26.
ありがとうございました ← 大内山のLinkedIn https://www.linkedin.com/in/hiroshi-ouchiyama-605ab872/ メール: hiroshi.ouchiyama@intel.com
Download

























![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)








































![[Track3-2] AI活用人材の社内育成に関する取り組みについて ~ダイキン情報技術大学~](https://cdn.slidesharecdn.com/ss_thumbnails/3-2dllabconferencedaikinisid2020-07-20-2-200819034039-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Track1-2] ディープラーニングを用いたワインブドウの収穫量予測](https://cdn.slidesharecdn.com/ss_thumbnails/dldc20200801nssoltokutake-200819025900-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Track1-1] AIの売上予測を発注システムに組み込んだリンガーハットのデータ活用戦略](https://cdn.slidesharecdn.com/ss_thumbnails/datumstudiomitsuda-200819031400-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Track 4-6] ディープラーニングxものづくりが日本を強くする ~高専DCONの挑戦~](https://cdn.slidesharecdn.com/ss_thumbnails/integraixdllpdf-200819065852-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Track3-4] アカデミックにおけるAI/ディープラーニング の教育と学習支援に関する研究](https://cdn.slidesharecdn.com/ss_thumbnails/20200731dldcyamashita-200817042234-thumbnail.jpg?width=640&height=640&fit=bounds)














