Download as PDF, PPTX
![Towards automating [supervised] machine learning:
Benchmarking tools for hyperparameter tuning
Dr. Thorben Jensen
tjensen@informationsfabrik.de](https://image.slidesharecdn.com/pydatahyperparameter-180720220712/85/Towards-automating-machine-learning-benchmarking-tools-for-hyperparameter-tuning-Dr-Thorben-Jensen-1-320.jpg)
![Towards automating [supervised] machine learning:
Benchmarking tools for hyperparameter tuning
Dr. Thorben Jensen
tjensen@informationsfabrik.de](https://image.slidesharecdn.com/pydatahyperparameter-180720220712/75/Towards-automating-machine-learning-benchmarking-tools-for-hyperparameter-tuning-Dr-Thorben-Jensen-1-2048.jpg)

![Finding optimal hyperparameters is important!
|
3
▪ Hyperparameters
are “parameters whose values [are] set before the learning process begins.
By contrast, the values of other parameters are derived via training.” (wikipedia.org)
▪ Hyperparameter example: depth of neural network](https://image.slidesharecdn.com/pydatahyperparameter-180720220712/85/Towards-automating-machine-learning-benchmarking-tools-for-hyperparameter-tuning-Dr-Thorben-Jensen-3-320.jpg)
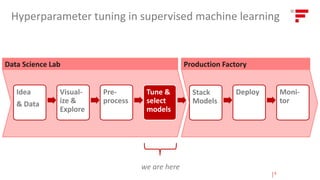

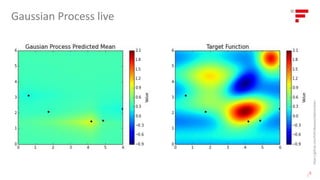
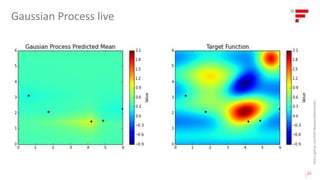

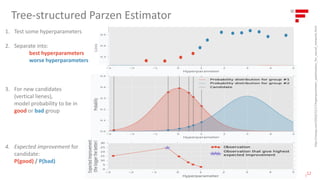



![Data Science Lab Production Factory
Idea
& Data
Visual-
ize &
Explore
Pre-
process
Tune &
select
models
Deploy Moni-
tor
Stack
Models
Towards automating [supervised] machine learning?
?? ?
|22](https://image.slidesharecdn.com/pydatahyperparameter-180720220712/85/Towards-automating-machine-learning-benchmarking-tools-for-hyperparameter-tuning-Dr-Thorben-Jensen-22-320.jpg)


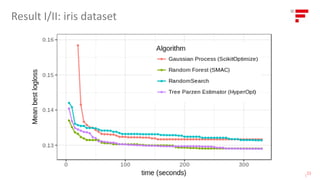
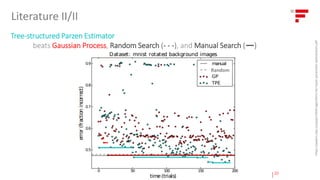
The document discusses the critical role of automating hyperparameter tuning in supervised machine learning to enhance efficiency in model performance. It reviews various benchmarking tools, including grid search, random search, sequential model-based optimization, and different proxy models like Gaussian processes and random forests. The findings indicate that automated tuning methods outperform manual tuning, suggesting the adoption of these techniques can lead to better model optimization and more productive use of data science resources.




































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









