The site architecture you can edit
•Download as ODP, PDF•
4 likes•1,423 views

The document proposes an architecture for improving collaboration between staff and volunteers on Wikimedia projects. It involves setting up a test/development OpenStack cluster that is a clone of the production environment. This would allow volunteers liberal access to test proposed changes without affecting production. The architecture aims to provide privilege escalation for non-ops users and an environment for testing major changes. Key aspects include using OpenStack, LDAP, Puppet, PowerDNS, Gerrit and CloudInit to manage the test/dev cluster and integrate tools like MediaWiki, Nova and DNS.

More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (20)
Similar to The site architecture you can edit
Similar to The site architecture you can edit (20)
More from Open Stack
More from Open Stack (20)
Recently uploaded
Recently uploaded (20)
The site architecture you can edit
- 1. The Site Architecture You Can Edit Varnish Mobile? Ryan Lane Wikimedia Foundation Membase? Swift
- 2. Content
- 3. Interface
- 5. Localization
- 7. Admin logs
- 9. Monitoring
- 13. Early Community: No staff
- 14. Current Ops Situation: No new non-staff
- 15. Current Dev Situation: Minimal staff and community project collaboration
- 16. OpenStack: An Empowerment Technology
- 17. Community Oriented Test and Development
- 19. Privilege escalation for non-ops
- 20. Environment for testing major changes
- 22. Allow liberal access to the clone
- 23. Provide a way to add new architecture without affecting clone
- 24. Provide a way to make changes without root
- 25. Provide a way to migrate changes to production
- 29. Devs request merge for puppet changes via gerrit
- 30. Project instances moved to default project and tested
- 31. Project moved to production cluster
- 36. Production zone per datacenter
- 37. Wikimedia Labs
- 40. Support for instance, security group, address, volume, key, sudo, DNS, and LDAP management
- 41. Using EC2 API
- 42. Self-documenting via MediaWiki templates
- 44. Nova information queryable via annotations
- 45. Queries displayable via numerous outputs
- 46. Example: Display the sum of storage in GB used for instances in project “tesla” who have the puppet variable “storage_server” set to “true”
- 51. Nova projects = Posix Groups
- 52. Special project role = Sudo access
- 54. Default gid/shell via MediaWiki configuration
- 55. Sudo policies managed via puppet and LDAP
- 63. Instance creation = Private DNS LDAP entry
- 64. Can add public DNS entries to floating IPs
- 68. Cloud-config, scripts, and upstarts supported
- 69. Using to connect instances with puppet
- 72. First change approval by community
- 73. Final approvals and merges by ops team
- 77. Our architecture as a reference use
Editor's Notes
- The Wikimedia sites are a massive volunteer effort to share knowledge with the world. These volunteer efforts have created the 5 th largest web presence in the world, and one of the largest collections of knowledge online in the world. This effort is so successful because of willingness and drive of people to share knowledge, the openness of the content, and the freedom our environment provides to create.
- A major freedom of our sites is the ability to edit. If you are reading an article, and see a typo, you can fix it. If you are reading an article about your hometown, and some information you feel is interesting or important is missing, you can add it. If something is wrong, you can correct it. But in the current state of the web editable content isn't terribly novel. Facebook, twitter, slashdot, digg, reddit, etc., are all user generated content.
- However, we extend the concept of editing to the interface as well. It's possible to edit interface messages, site javascript, site css, the navigation sidebar, sitenotices and other interface elements that control how users see and interact with the sites. It's also possible to edit one's own css and javascript so that one's experience is custom to themselves. A community member may do activities that require quite a bit of repetition, and as such may write tools to automate or add usability to their process. Often these tools are very useful to others in the community as well, and can be shared, like the content of our sites.
- We also extend the concept of editing to our software. Changes to our software, like our content are open to all. The software is GPL licensed, and is used extensively by third parties. In fact, I became a volunteer for the Wikimedia effort by using and improving the software for another organization. We give out commit access fairly liberally. If you have the PHP chops, and discuss what you'll be working on, you'll very likely get commit access.
- We also extend the editability of our stack to our translations. We have a very diverse community, and a lot of that diversity in language diversity. We have projects in 250 languages, and as such the software must also be localized for those languages. We use translatewiki.net to localize the MediaWiki software, and like Wikimedia sites, translate wiki is volunteer based, and uses MediaWiki. We have localization support in over 300 languages, all of which was totally volunteer created. The translatewiki community has roughly 2,500 members, and continues to grow. We continue our trend of letting community members edit everything by going deeper and deeper into our stack.
- We extend the concept of editing further into our stack, and into our site architecture, from the documentation point of view. People are occasionally shocked at the level of openness of our community, and our environment. For instance, we have all of our architecture documentation on a public wiki. I recently did an LDAP implementation, and while doing so, I added complete documentation on the implementation. It covers installation, configuration, directory information tree design, schema design, security decisions, and backup design. This gives a freedom to the community to participate in our site architecture, at least from a viewing perspective. Our working environment is very public, and this includes our logging and communications, which occurs via IRC.
- The operations team's daily working environment is IRC, and we log server actions via bots in IRC. These logs are available on a wiki. This provides the community with the freedom to participate in our site operations by watching us work, and offering help. Operations volunteers can work with us in this environment, and add to the log as well. This is unfortunately the depth level at which editing stops. Our openness continues though.
- We go one step further than simply opening our operations documentation. We also provide live versions of a lot of our configuration files. Right now it isn't possible to see all of our configuration, but this is something I'd like to change. The provides the community the ability to actively participate in our site architecture by providing patches to issues, or to enable features.
- Our monitoring infrastructure is also publicly accessible. We have one service that is meant to be a dashboard of whether are services are up or not, and we have another that is meant more for backend support.
- Like monitoring, our performance statistics are publicly viewable. This, along with monitoring, provides the community the freedom to participate by reporting issues, or informing other users of ongoing issues. It can also be used to help us diagnose issues as they are occurring
- The theme here is that we as a community, and specifically the Wikimedia Foundation emphasize the empowerment of our community through freedoms expressed in software, and open content. Our community also empowers itself through self-funding. Wikimedia is a non-profit and is funded by its community. We are primarily funded by small donations made by our editors and readers.
- The power of these freedoms is outstanding. The explosive growth of Wikipedia is a testament that people want to share knowledge, and will if they have the ability to easily do so. So let's look back to the beginning of this project, to see how things began.
- The freedoms our community have used to extend through our entire environment, all the way to root access on our production cluster. When Wikipedia was first started, there was no paid tech staff. Everyone was a volunteer, including all roots.
- Unfortunately, with the massive growth of the sites, and the importance of keeping the sites up and the content secure, we now lack the ability to easily give root access to volunteers. Most of our operations team is paid staff, and we haven't had a new ops volunteer with production cluster access in a while.
- We also have a similar situation occurring with development. We have foundation initiated projects occasionally, and we are having a difficult time properly integrating our volunteer developers into these projects.
- This is where OpenStack comes in. I believe that OpenStack is an empowerment technology, and will provide our community with a new, quite awesome, freedom to participate. I feel OpenStack is especially empowering because it is open source. There are some closed source solutions we could use to empower our users, but OpenStack being open source means we can change the software how we need, and we can steer the project in a way that ensures our project will continue to work in the way we need. Also, the foundation has a policy to use open source unless there is no alternative. Often we won't use closed source even if there is no other alternative.
- The way I'm going to use OpenStack to empower our community is going to be a community oriented test and development environment.
- I have three main goals: 1. Improve collaboration between staff and volunteers for software development 2. Have a process for providing higher levels of access for people who are not on the paid operation team staff. This includes staff developers, and all volunteers. I'd like to have an environment where anyone can eventually become root, even on our production cluster. 3. I'd like to have an environment where we can test major changes before we deploy them to the live site. We currently have no test environment.
- We can achieve the goals by providing liberal access to an environment that is a clone of our production environment. In this environment it should be possible to add new architecture without affecting the production clone. Users should be able to make root level changes without having root, and they should be able to eventually have these changes implemented on the production cluster.
- The basic use case is that the operations team will create an initial default project. This project will be a clone of our production cluster. Like our production cluster, direct root access will be limited here. However, shell access will be given our fairly liberally. Basically, if someone has MediaWiki commit access, or they wish to do volunteer operations work, they'll be given access. This environment will be used for most test and development; it will not be used for production work. I hope for this to be used as a shared environment where staff and volunteers can collaboratively work together on projects. I also would like this environment to be a place where we can do operations testing, such as failover between datacenters, and service degradation tests.
- New projects should mirror community or foundation initiatives. These will be used for new site architecture. For instance, we are implementing Open Web Analytics currently, and this required architecture that is separate from our normal architecture. In our production environment, it is difficult to give out root access, which made OWA integration more difficult than necessary. In this test/dev environment, ops can create a project, assign members, and let the developers create the architecture themselves. Once the devs create the architecture, and are happy with how it is working, they can create puppet manifests describing the system design, and can push the manifests to the test/dev puppet git branch for review. After the community approves them, ops can approve them, and merge the changes in. Once the changes are merged in, ops can create instances for this project in the default project using the puppet configuration. If everything looks good, and it is interacting with the production clone properly, ops can merge the test/dev branch changes to the production puppet git branch. After merging the changes, ops can add hardware, and bring the systems online, and add the project to the production environment. This is basically having root, without having root! We are treating operations as a software development project.
- Let's look into how I'll be implementing this project.
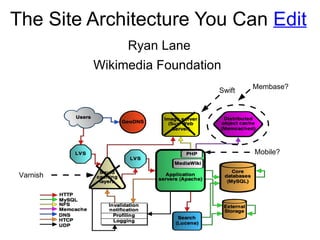
- Here's the current architecture I've built. It contains the following: MediaWiki, which is the user's interface for controlling most of the architecture LDAP, which is used for tight integration of all services, and instances DNS, which is controlled by MediaWiki Puppet, which from the instance POV is controlled by MediaWiki Gerrit, which is a Git interface for code review and will contain all puppet information Nova, which is used for managing infrastructure
- First, let's look at how openstack fits in.
- We are running a multi-node nova installation with MySQL and LDAP. We are starting small, with one controller, and three compute nodes so that we can properly vet the architecture. In the future we'll likely grow this quite a bit. Ideally we'll have a test/dev zone in each of our datacenters. We'll also likely use a production zone in each datacenter to host instances for some of the miscellaneous services we run that aren't necessary for the site. We also have a possible future project, that isn't yet budgeted, or confirmed as an official project, called Wikimedia Labs. This will be an environment that is a clone of our production environment that will have much more liberal access than the test/dev environment. It'll be for tools and research.
- Next, let's look at MediaWiki, which we are using to control this architecture.
- I wrote a MediaWiki extension called OpenStackManager. In conjunction with the LdapAuthentication extension, it controls all aspects of the environment. The extension supports essentially all of the EC2 exposed functionality of Nova. As a plus, it also enables the self-documentation of the architecture. When a nova resource is created, it automatically pulls instance information from a number of places and creates MediaWiki templates. This information is also kept up to date when things change, or when resources are deleted. I extend this documentation to be more useful too, though.
- I extend this documentation with Semantic MediaWiki (SMW). SMW is a system for adding structured data to a wiki. It can add semantic annotations to wiki content, which turns it into data that is queryable, and exported. These queries can output this data in a number of different formats. So, the templates that are being created have this data turned into structured data, and as such, you can do queries on it. Queries like the above example can be done. On my blog, I also show how you can use this data inside of system scripts, via JSON display formats of SMW.
- Here's an example of the MediaWiki template that is created, in property/value format.
- Here's an example of a really basic query that outputs in broadtable format, for displaying the information in the wiki.
- Next let's look at how I'm using LDAP (using OpenDJ).
- LDAP is used for all services in the architecture. LDAP is also used for the instances that are created as well. Nova concepts are expanded to system level concepts on the instances. For instance, a nova account (which is the user's wiki account), is the user's instance shell account. When a user is added to a nova project, they also are added to a posix group on the instance. It's also possible to give sudo access by adding users into a special role.
- Authentication and authorization is done via LDAP, and is managed by the OpenStackManager and LdapAuthentication extensions. When a MediaWiki account is created for a user, nova, gerrit, and shell account credentials are also added.
- Here's an example of an LDAP entry that is created.
- Next, let's look at how we are integrating puppet.
- We are using puppet to manage all instances that are created. When users create instances, the puppet information is added to LDAP for that instance. Puppet is integrated with LDAP, where all puppet nodes are stored in LDAP. There is some puppet information that is always added for instances. Specifically, MediaWiki adds variables for the instance's project, the user's wiki name, their email address, and their language. I use this in puppet to send an email to a user, in their language, telling them when their instance is finished being created. More puppet classes and variables can be added by default via the MediaWiki config, so this is extendable for your own purposes.
- Next let's look at how I'm handling DNS.
- Like puppet, DNS is using LDAP as a backend for its information. The OpenStackManager extensions manages both private and public DNS domains. When an instance is created, it also adds a private DNS address. When a user allocates an IP address, and associates that address with an instance, they can also add public DNS information to that address.
- Here's an example of an LDAP entry for an instance. Notice that both puppet and DNS information is on the same entry. The nice thing about this, is that puppet can use all of the attributes as variables, so the DNS information can be used in puppet manifests. One especially nice thing about this, is that the private DNS entries have a location field, which can be used in puppet to do location specific configuration.
- Next let's see how I'm using Nova's metadata service.
- We are using cloud init fairly extensively to bootstrap puppet. MediaWiki can be configured to add default cloudinit configuration, scripts, and upstarts to instances.
- Lastly, there is Gerrit.
- Gerrit is a code review tool for git that manages the git repositories and can also handle things like branching and merges. All wiki users will have the ability to branch, and propose changes for merge. Two approvals will be required for merges. The first approval will come from the community. The second approval will come from ops. Ops will have the ability to merge. This is an example of a place we can increase privileges for non-staff ops. Over time we can give out the ability for non-staff ops to do final approvals and merges in the test/dev branch.
- We can use help with this! There are a number of things we'd like to accomplish with nova, the OpenStackManager extension, and with our test/dev architecture that will take a lot of work. If you'd like to work with us, we are hiring. If you would like to volunteer we are very welcoming. You don't need to be an expert to volunteer. If you are looking to learn more about openstack, and want to help, we are more than willing to do mentorship on the project, as long as you can help us get the work done!
- Though my efforts are Wikimedia oriented, I also took consideration of how I could build this to benefit outside organizations. Every organization I've worked at has had contention between operations and developers when it comes to the level of access that is given to developers. Generally the developers want full access, but don't follow ops procedures closely enough for the ops team's tastes. This architecture focuses on giving developers a high level of access while forcing standardized procedures where they are necessary. In the cluster clone they do not get root access, but can make changes through puppet. In their projects they get full access, but must standardize their builds before they can be deployed. I'd like our architecture to be a reference to vet this idea.
- Another thing I often see is architecture documentation that is out of date. This architecture focuses on solving this problem as well, as the documentation is mostly handled automatically. Also, this documentation can be used in a structured way by the use of queries on the structured data, allowing the documentation to also be used for scripts, or data calls.
- Please don't hesitate to contact me. I'm very active on IRC, and would love to talk to you.