


































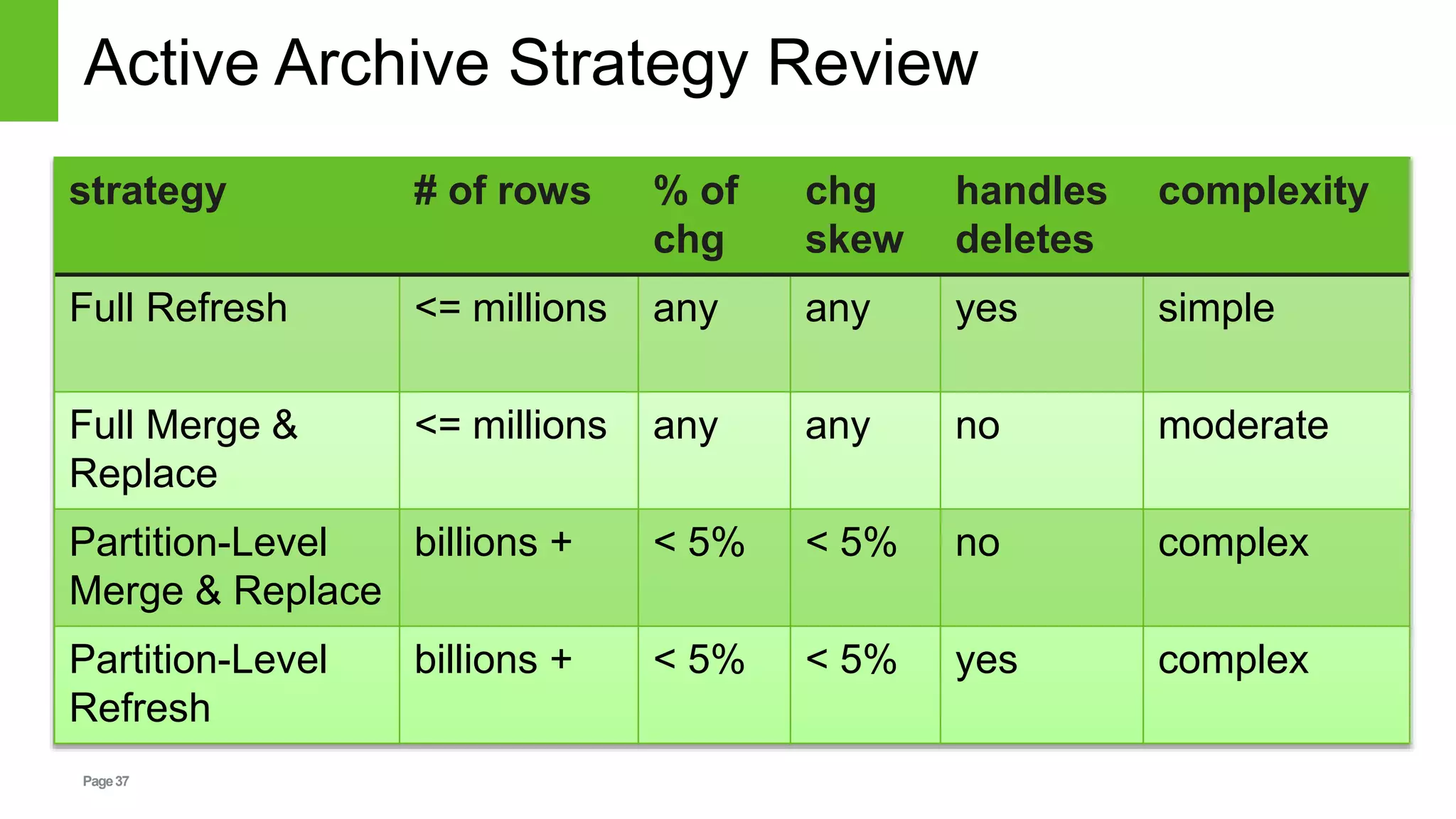





This document discusses strategies for handling mutable data in Hive's immutable data model. It presents several approaches including full refresh, full merge and replace, and partition-level merge and replace. The partition-level strategies allow merging incremental data updates into existing partitions in Hive tables. The document provides examples using Pig to filter, join, and load data to demonstrate performing incremental updates at the partition level. It evaluates the tradeoffs of different strategies based on data volumes and change rates.













































![Inspiring Travel at Airbnb [WIP]](https://cdn.slidesharecdn.com/ss_thumbnails/june91205pmairbnbqiancheng-150616222059-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




























































