Download as PDF, PPTX





Actian Vector in Hadoop Architecture
SQLProcessing
SQL parser
Optimizer
Cross compiler
parsed tree
query plan
Client application
X100 algebra
X100
Distributed rewriter
Builder
Execution engine
annotated query tree
operator tree
Buffer manager
datadata request
HDFS
Masternode
SQL query
I/O
X100
Rewriter
Builder
Execution engine
annotated query tree
partial operator tree
Buffer manager
datadata request
HDFS
I/O
MPI
annotated tree
result
MPI
partial result set
MPI
inter-nodecommunication
HDFS
namenode
HDFS
datanode
X100
X100
X100
X100](https://image.slidesharecdn.com/sqlinhadooptoboldlygowherenodatawarehousehasgonebeforepresentation-150605190110-lva1-app6891/85/SQL-in-Hadoop-To-Boldly-Go-Where-no-Data-Warehouse-Has-Gone-Before-4-320.jpg)




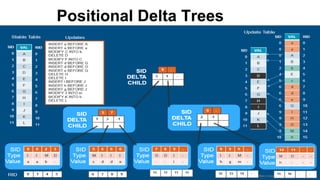




Actian is a $140M revenue company with 10,000+ customers that provides big data and analytics solutions. One of its key products is Actian Vector in Hadoop, which provides SQL analytics on Hadoop up to 30x faster than Impala. Vector uses single instruction, multiple data processing and storage indexes to minimize I/O and maximize throughput. It also supports trickle updates without impacting read performance through positional delta trees.























































































