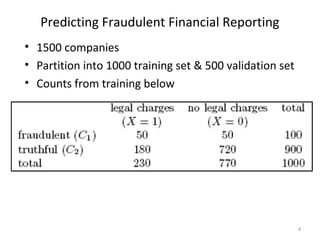
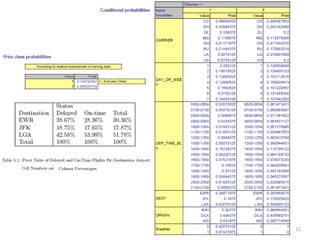
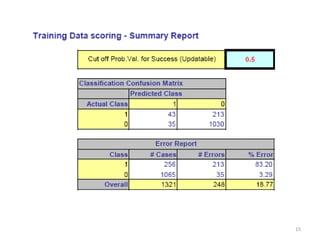
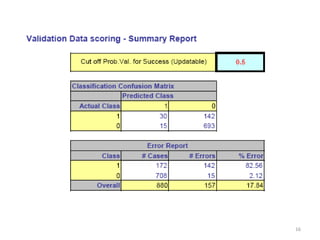
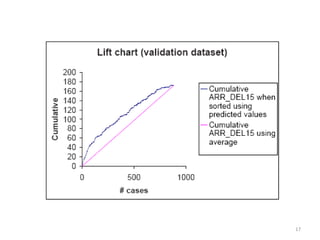
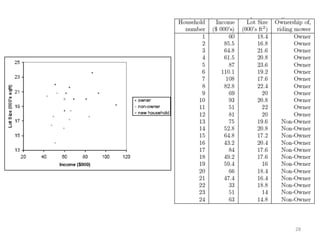
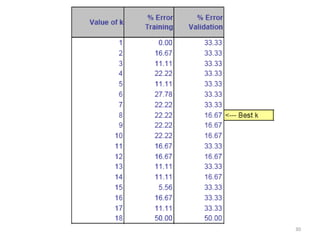
This document summarizes three simple classification methods: Naive Rule, Naive Bayes, and k-Nearest Neighbor (k-NN). It provides examples of using each method to predict fraudulent financial reporting and delayed flights. For Naive Rule, it classifies all cases based on the majority class in the training data. Naive Bayes improves on this by using predictor variables to estimate conditional probabilities of class membership. k-NN classifies new cases based on the classes of the k nearest cases in the training data in predictor space. The document evaluates the performance of Naive Bayes on these examples and discusses its advantages and limitations.