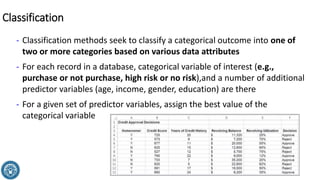
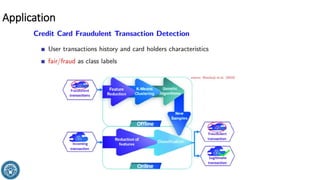
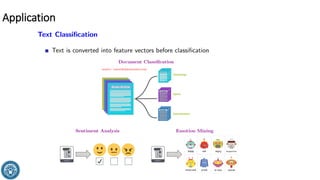
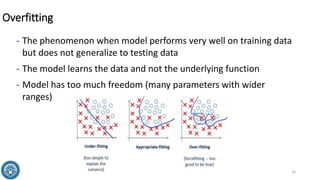
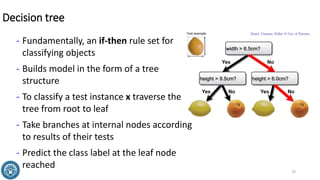
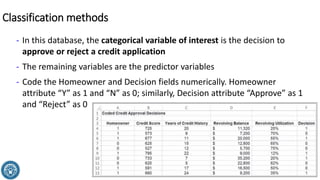
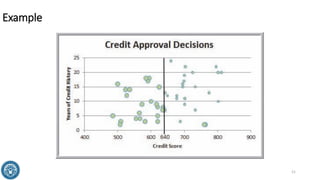
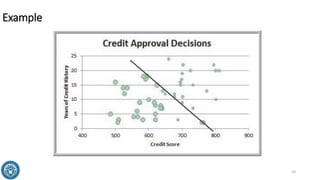
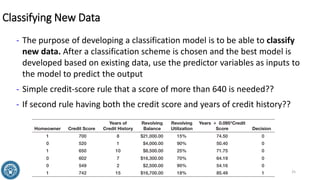
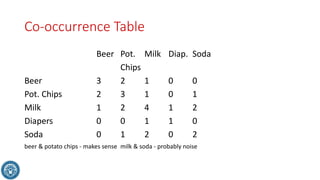
The document discusses classification methods in data mining, focusing on how to categorize outcomes based on predictor variables, such as credit scores and application approvals. It outlines the processes of model training, validation, and testing, emphasizing the importance of representative data sets and the risks of overfitting. Additionally, it covers association rule mining with an emphasis on market basket analysis, highlighting its applications in understanding consumer purchasing behavior and improving marketing strategies.