Downloaded 18 times







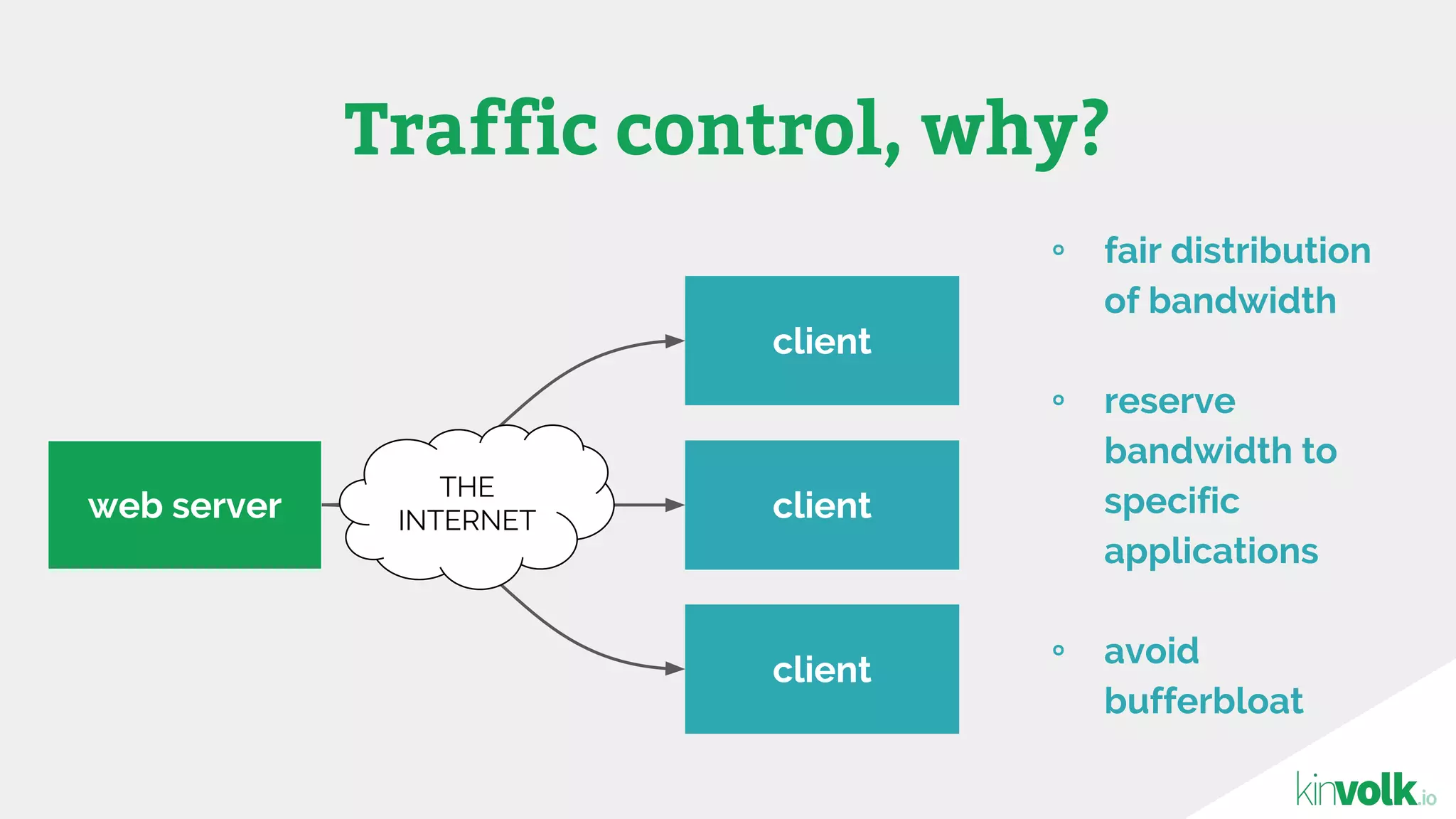
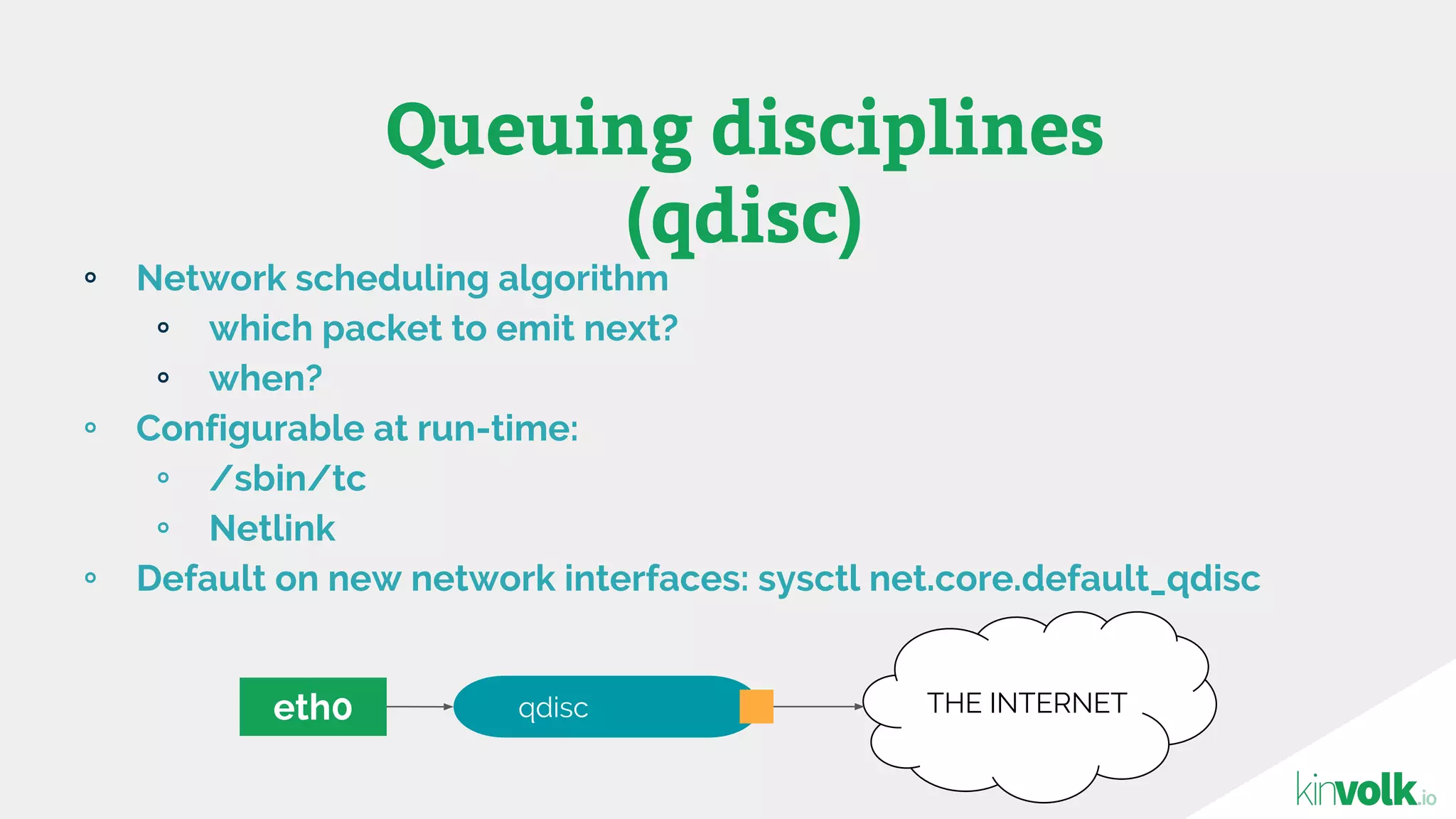
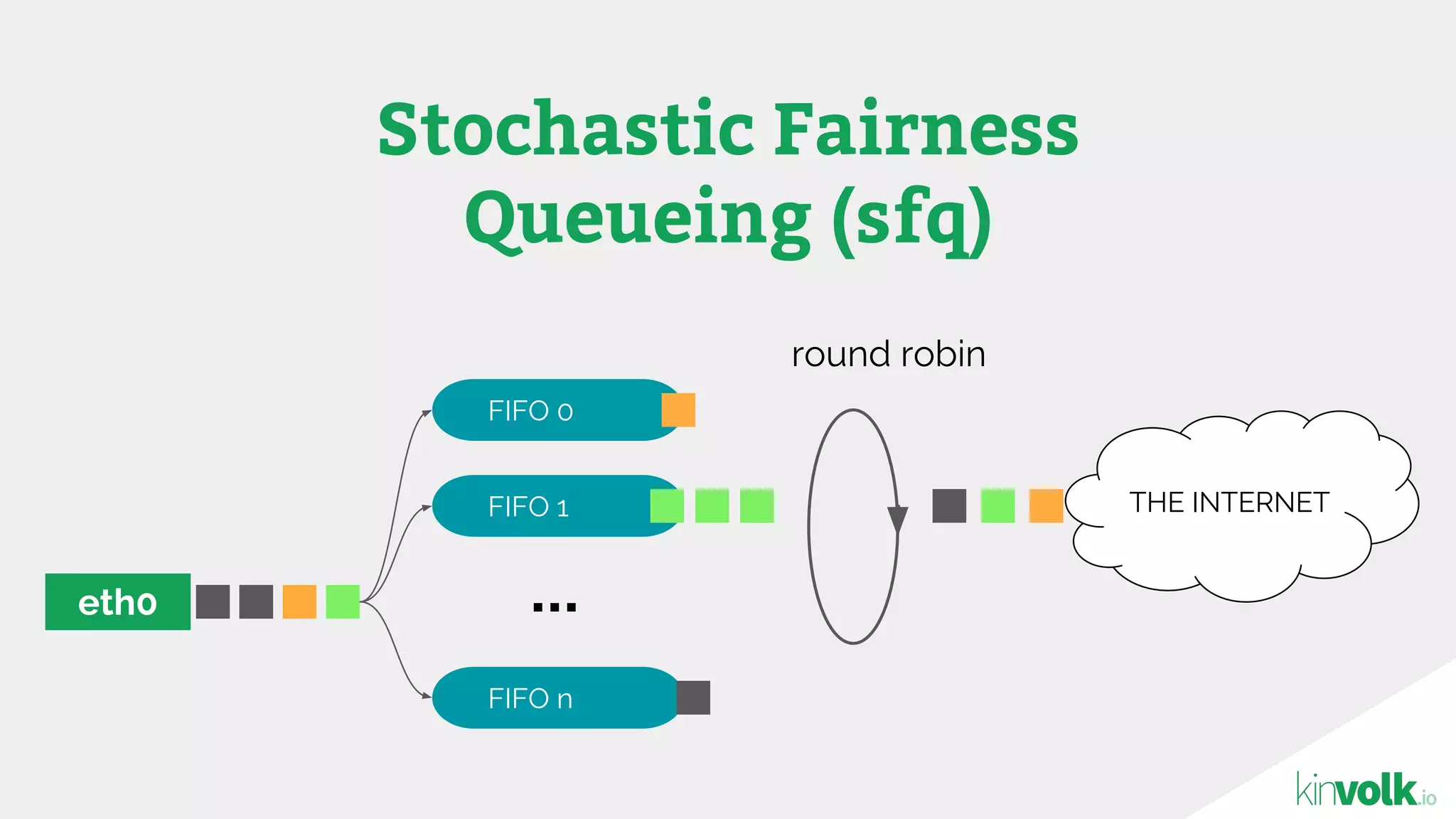


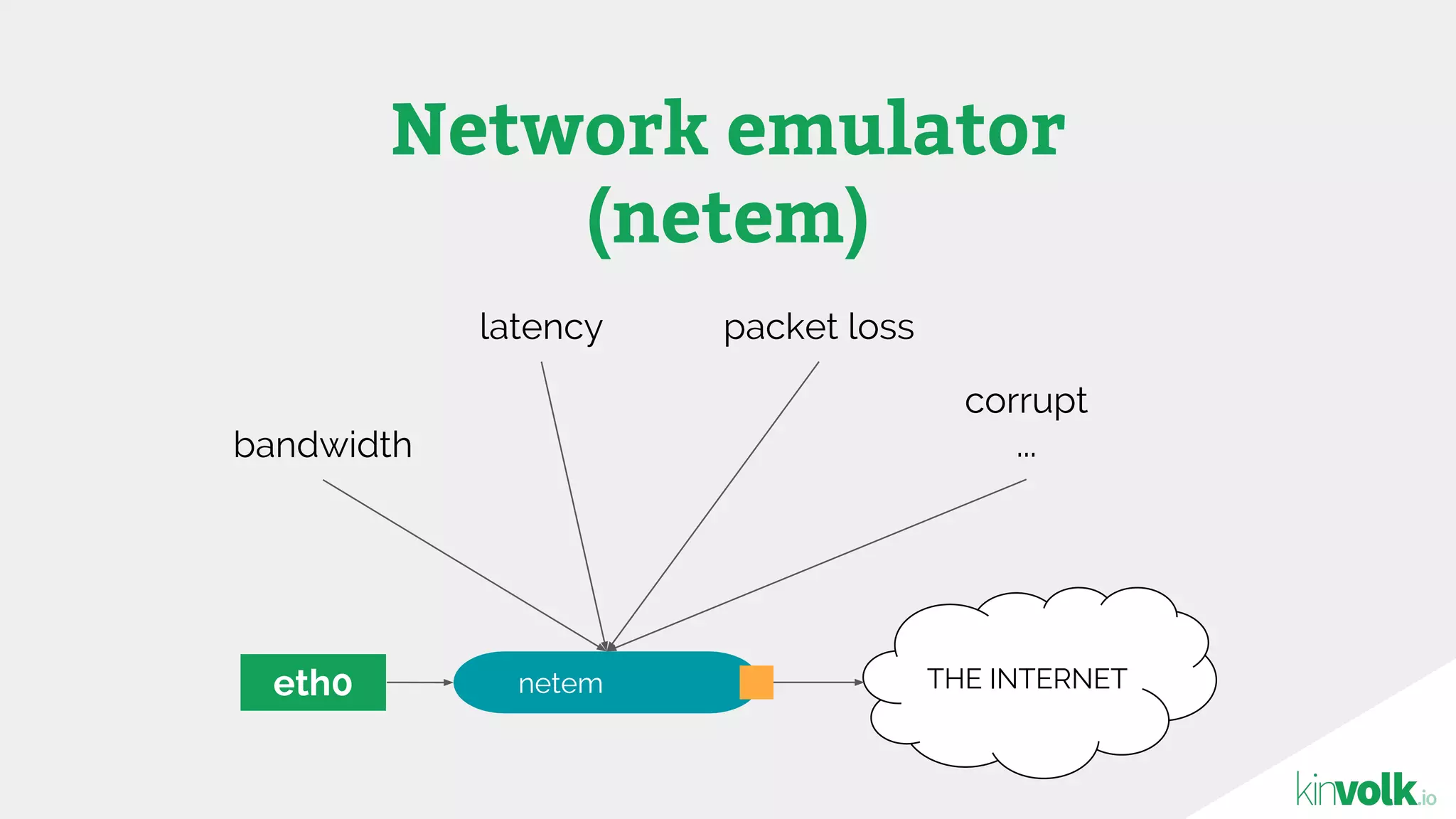
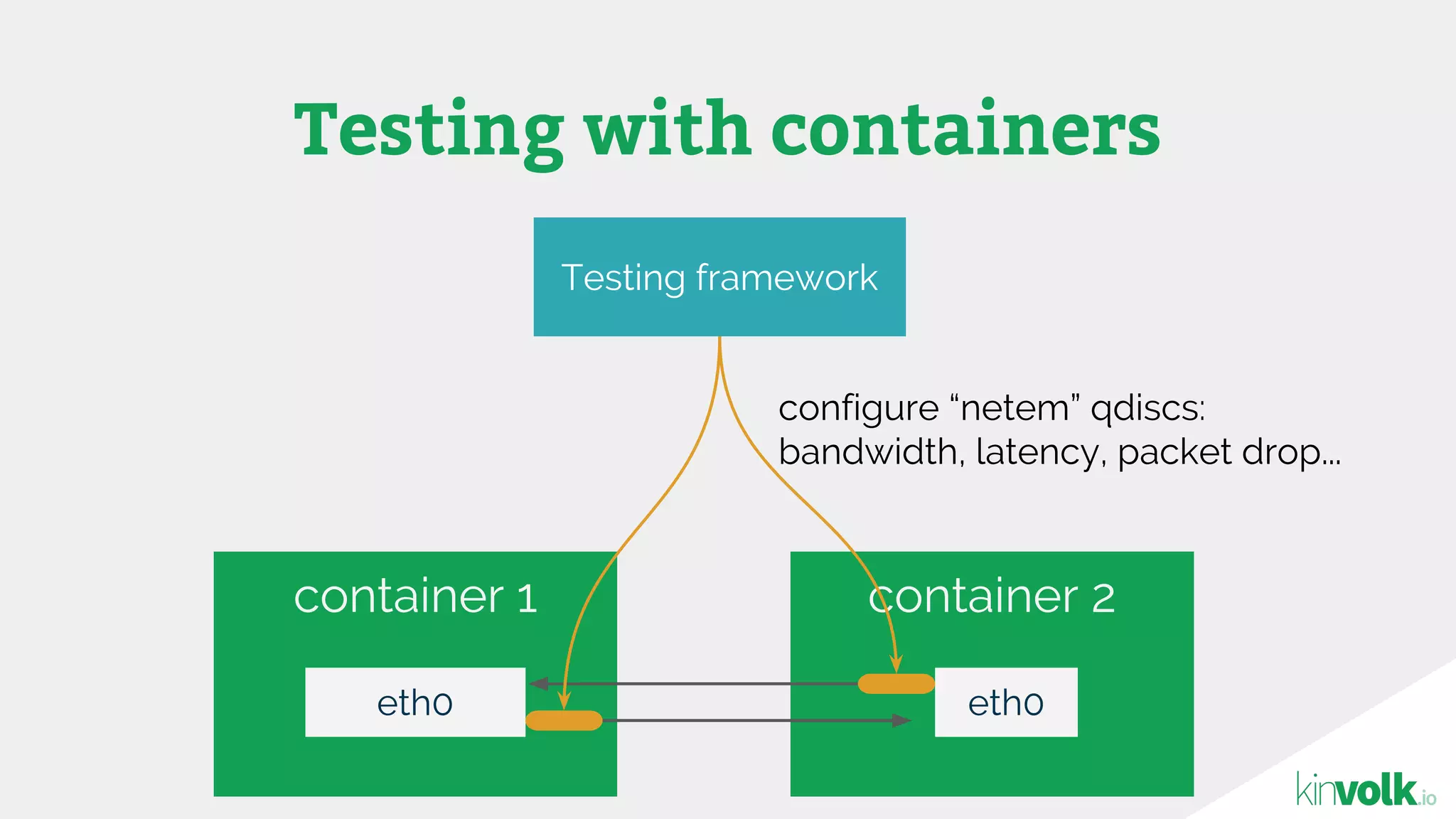

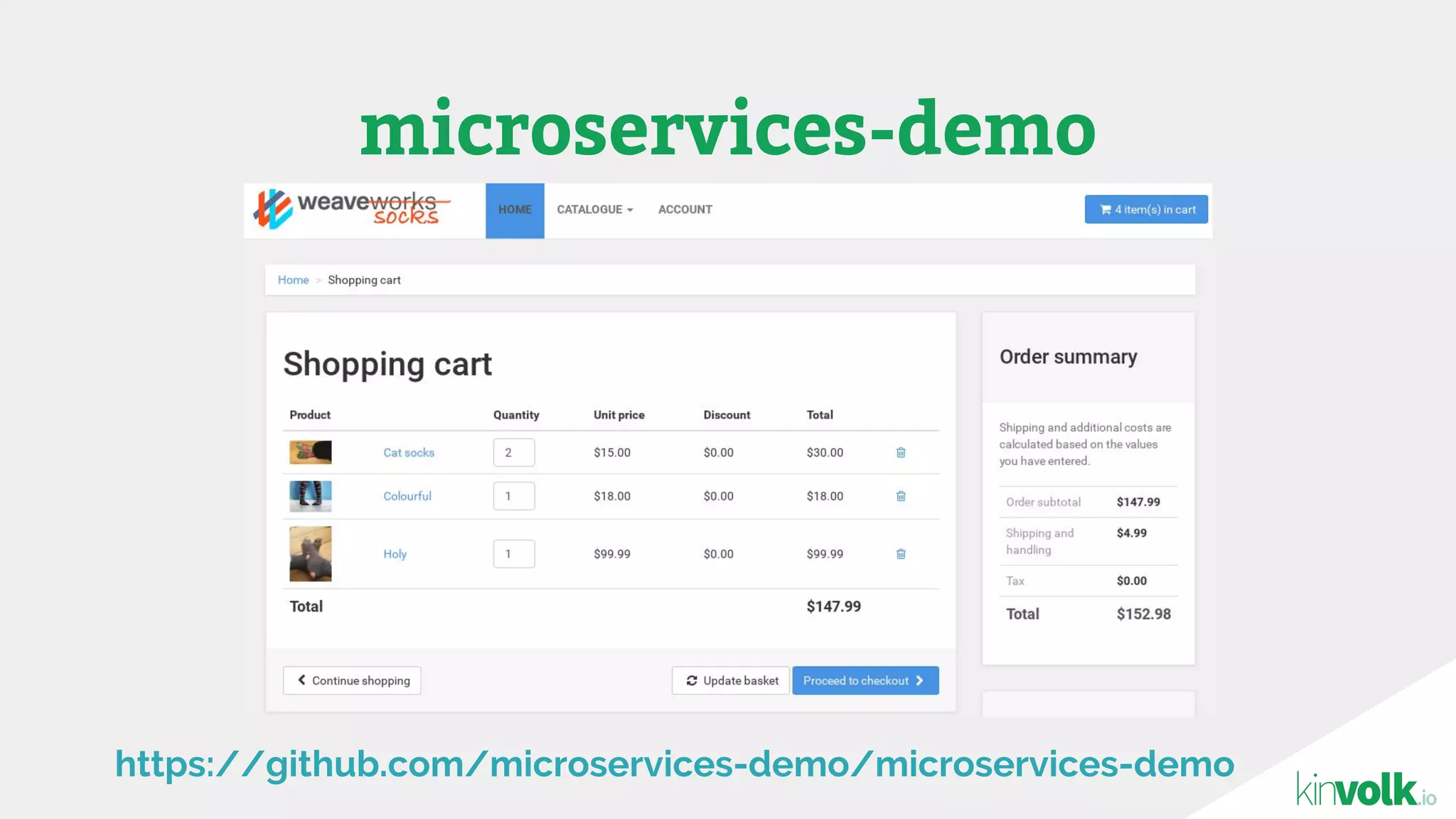
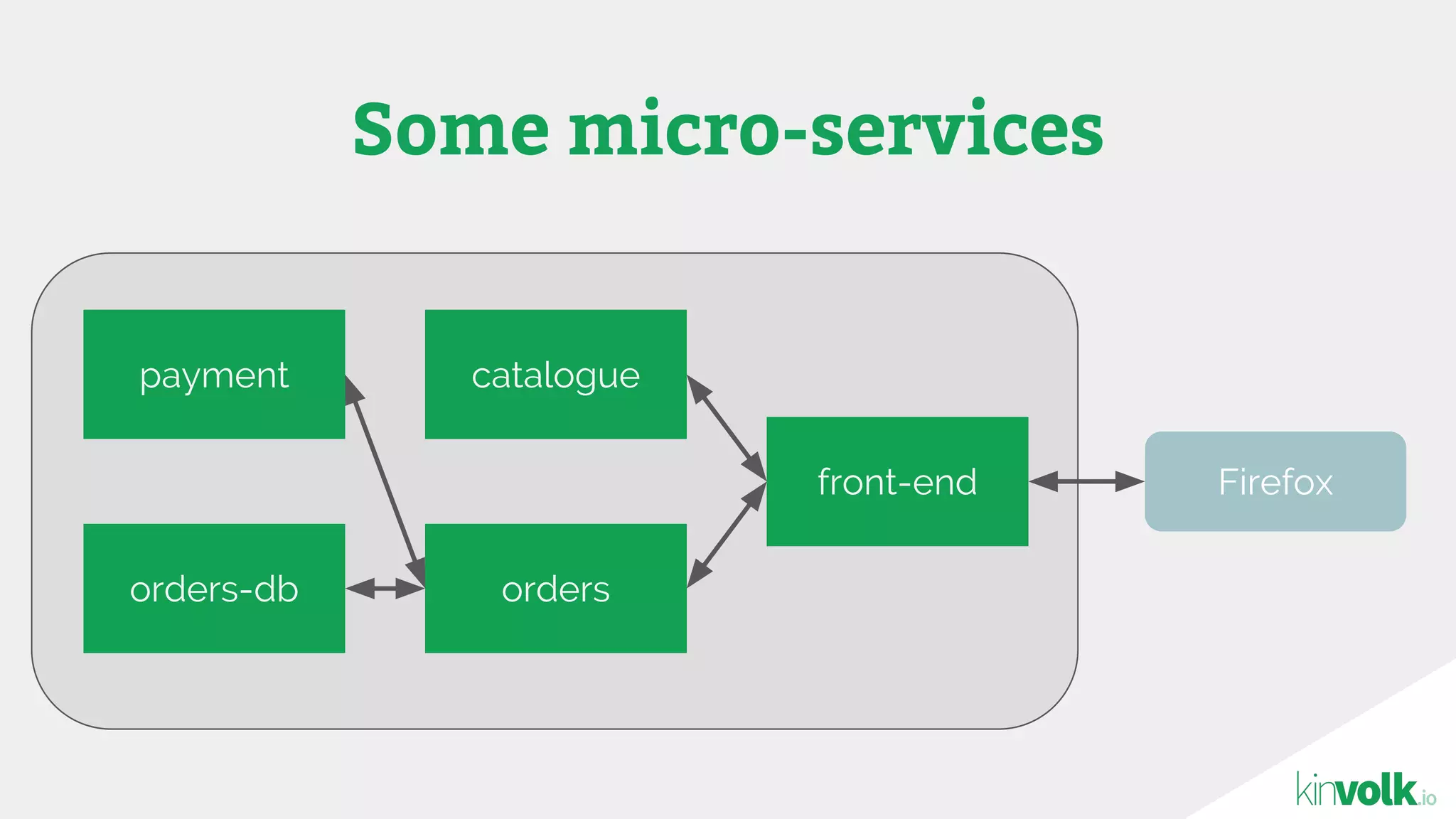

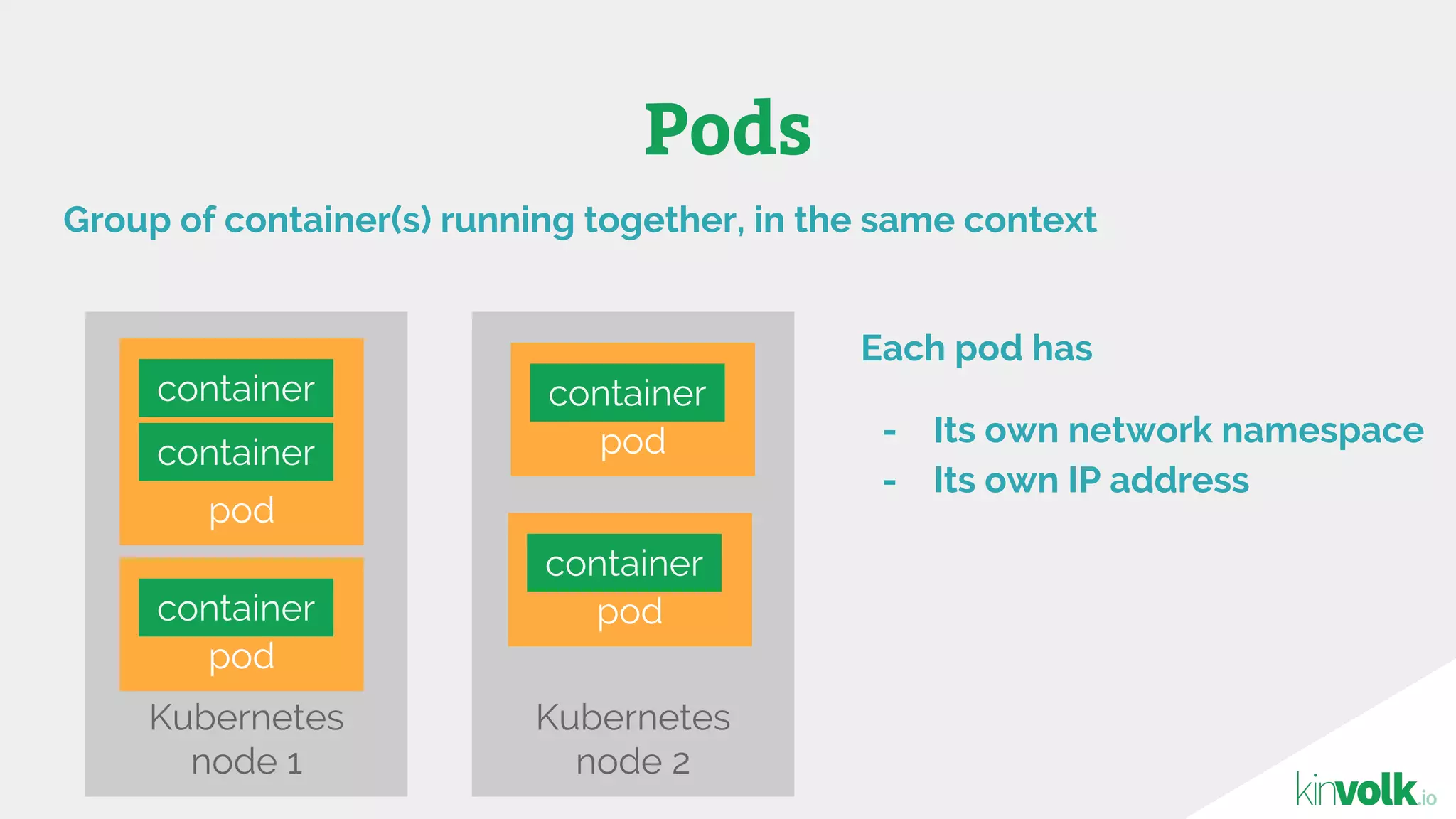
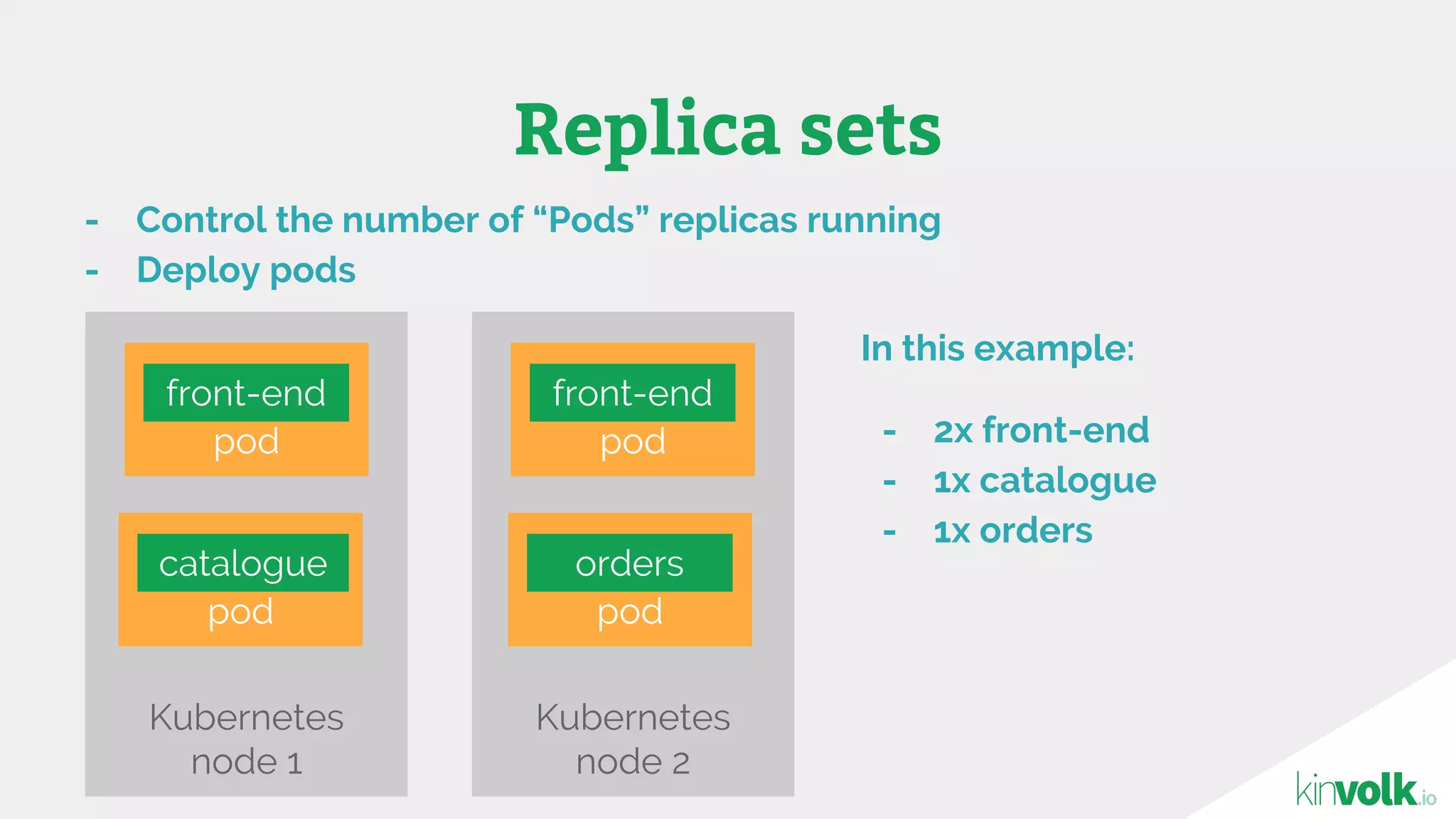
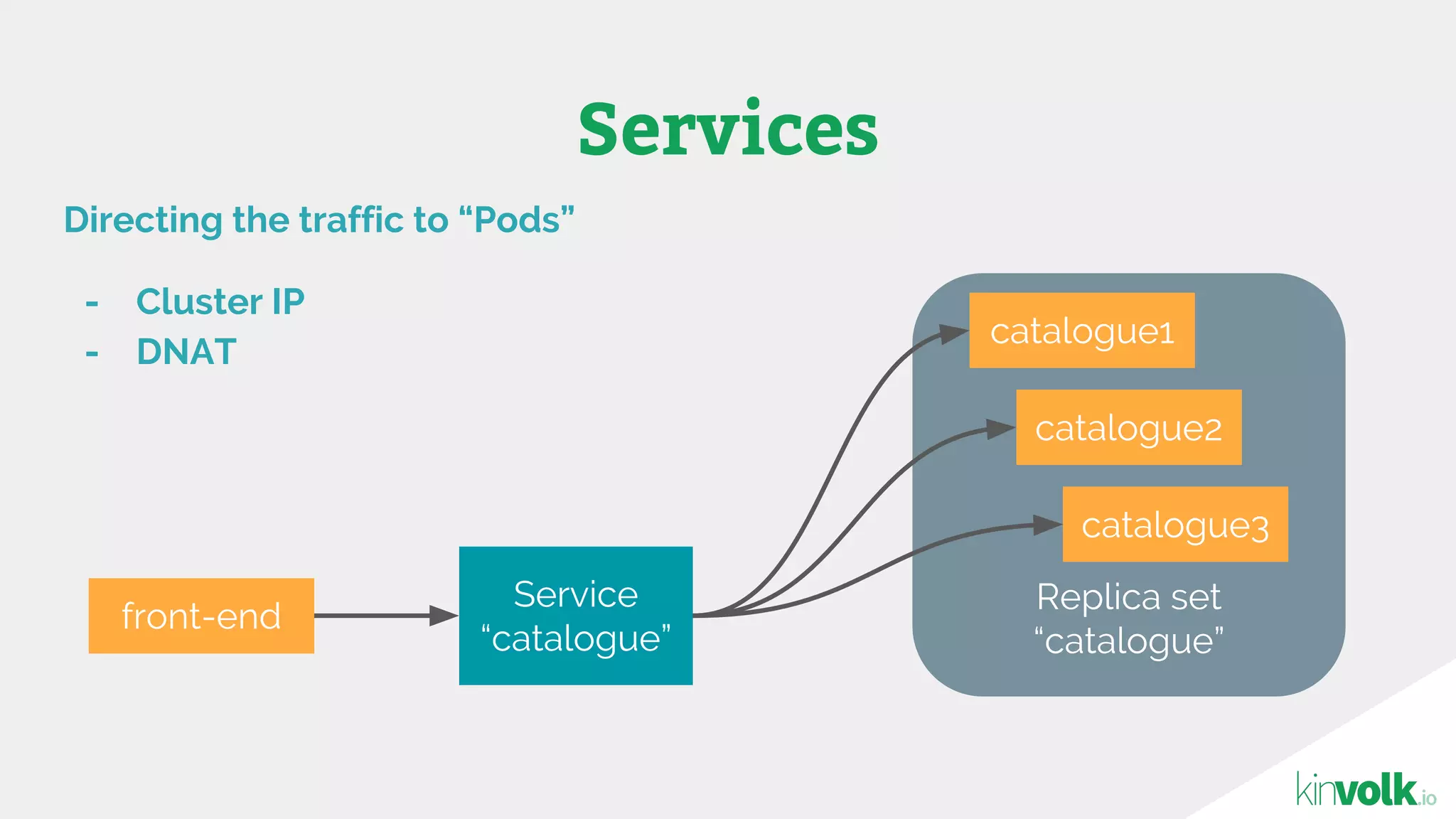
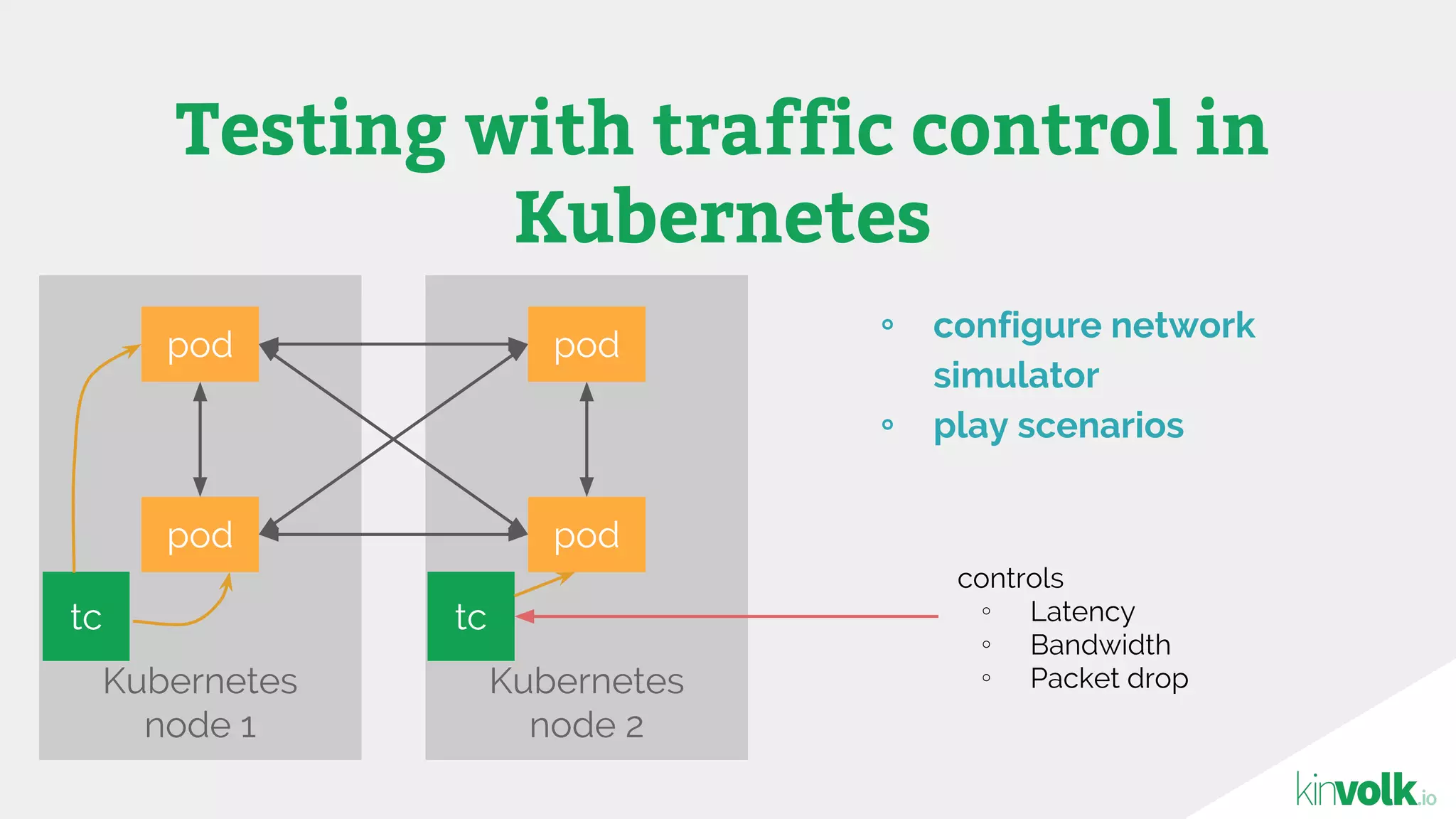

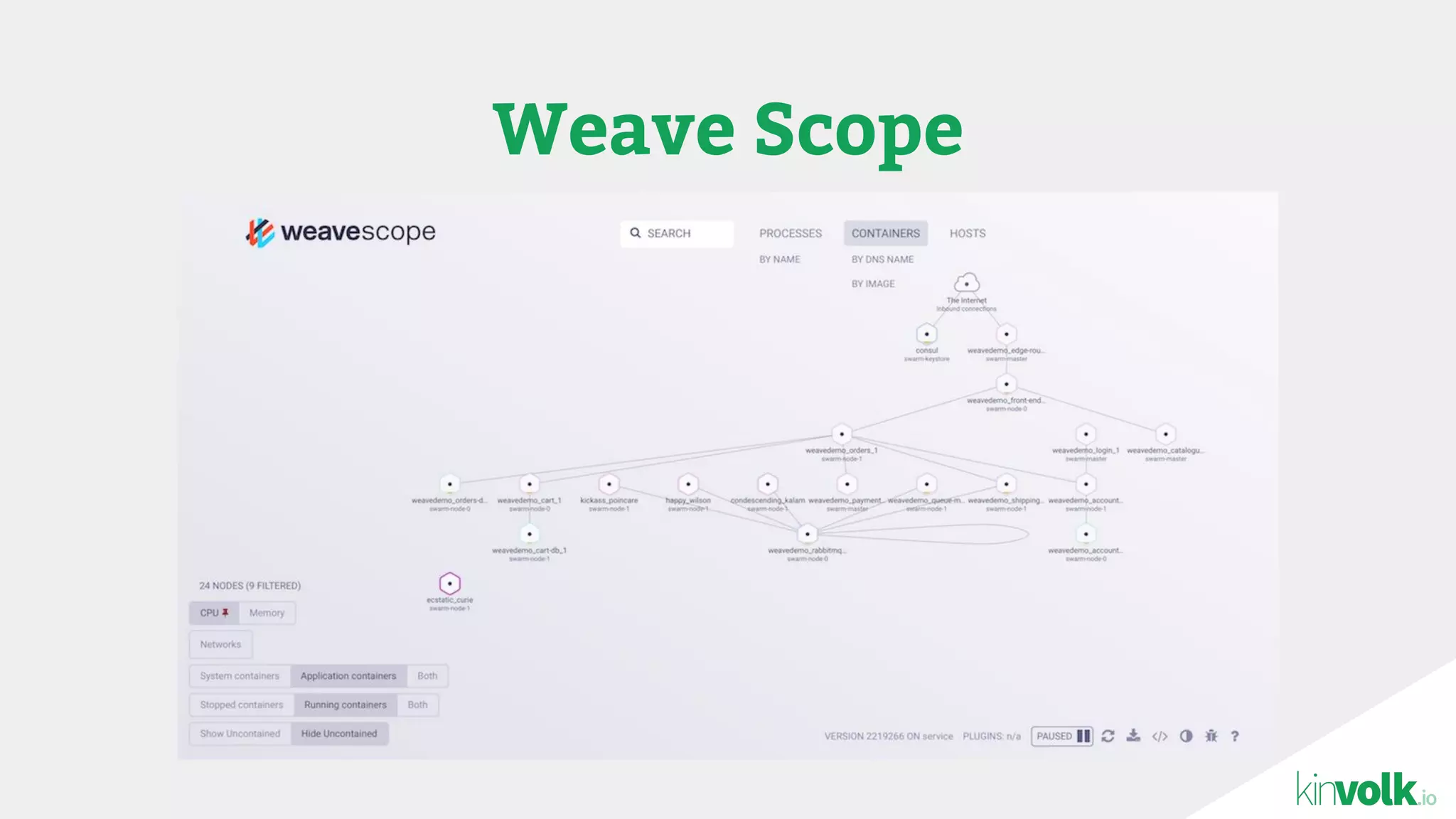
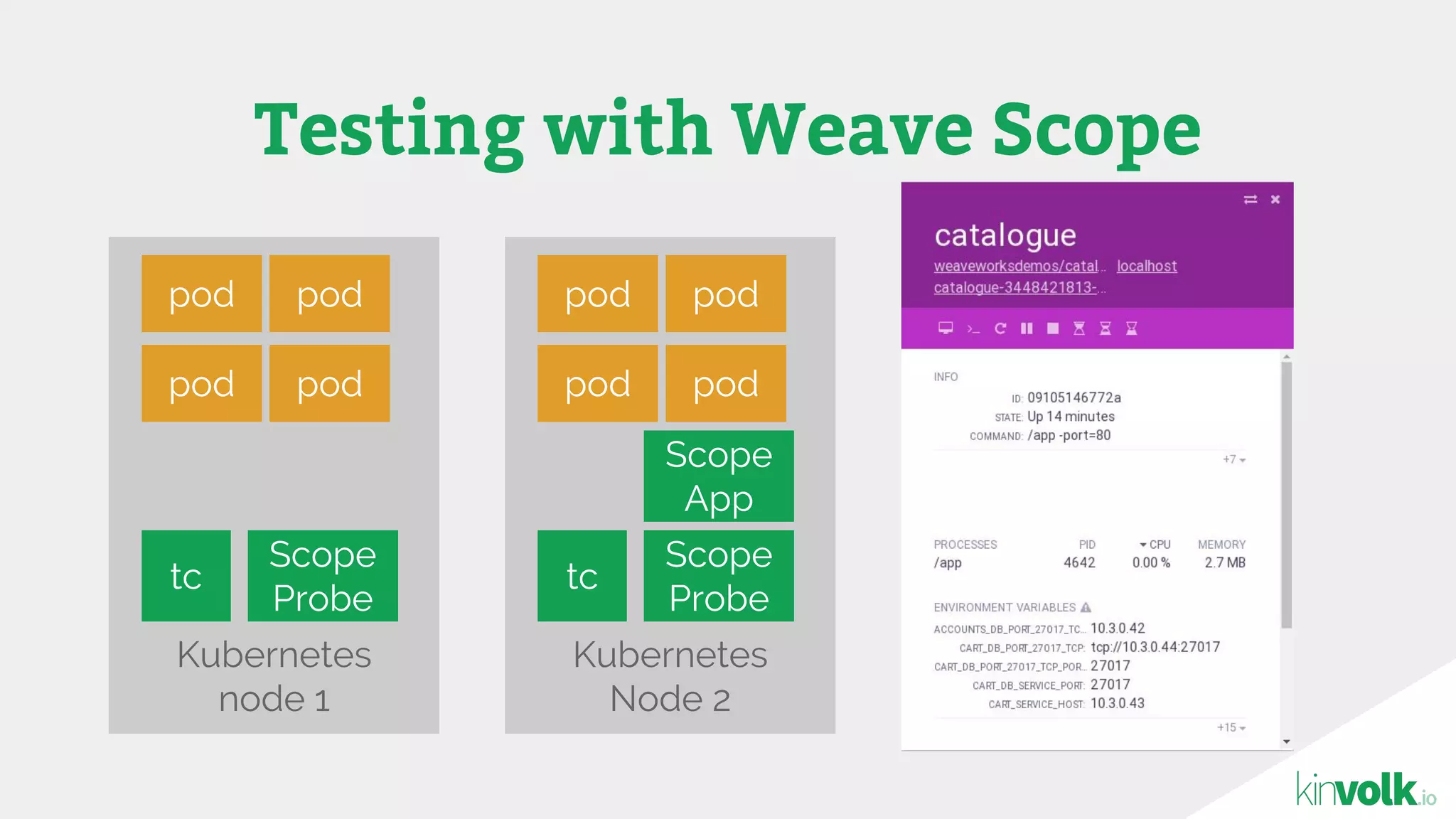
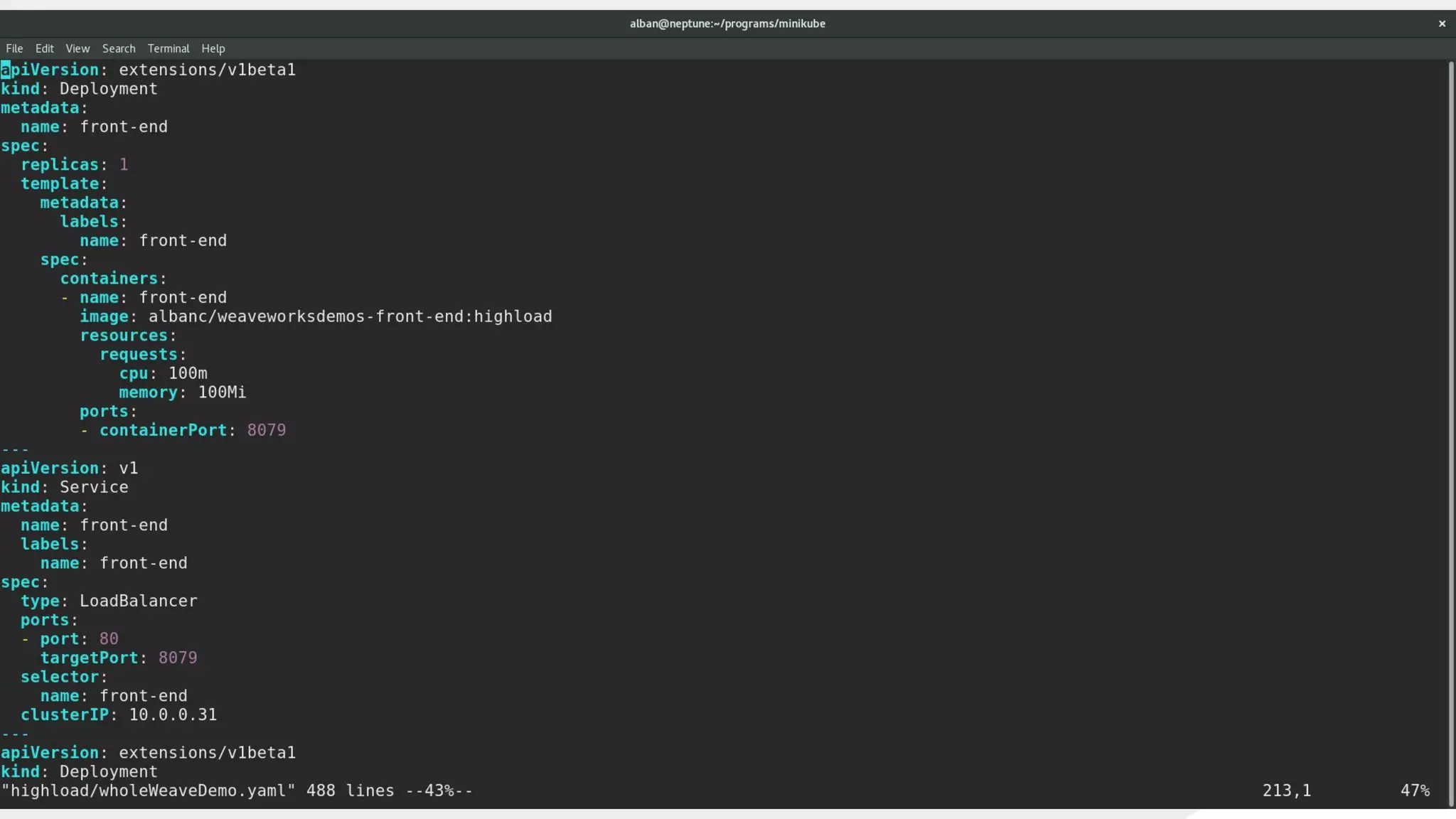
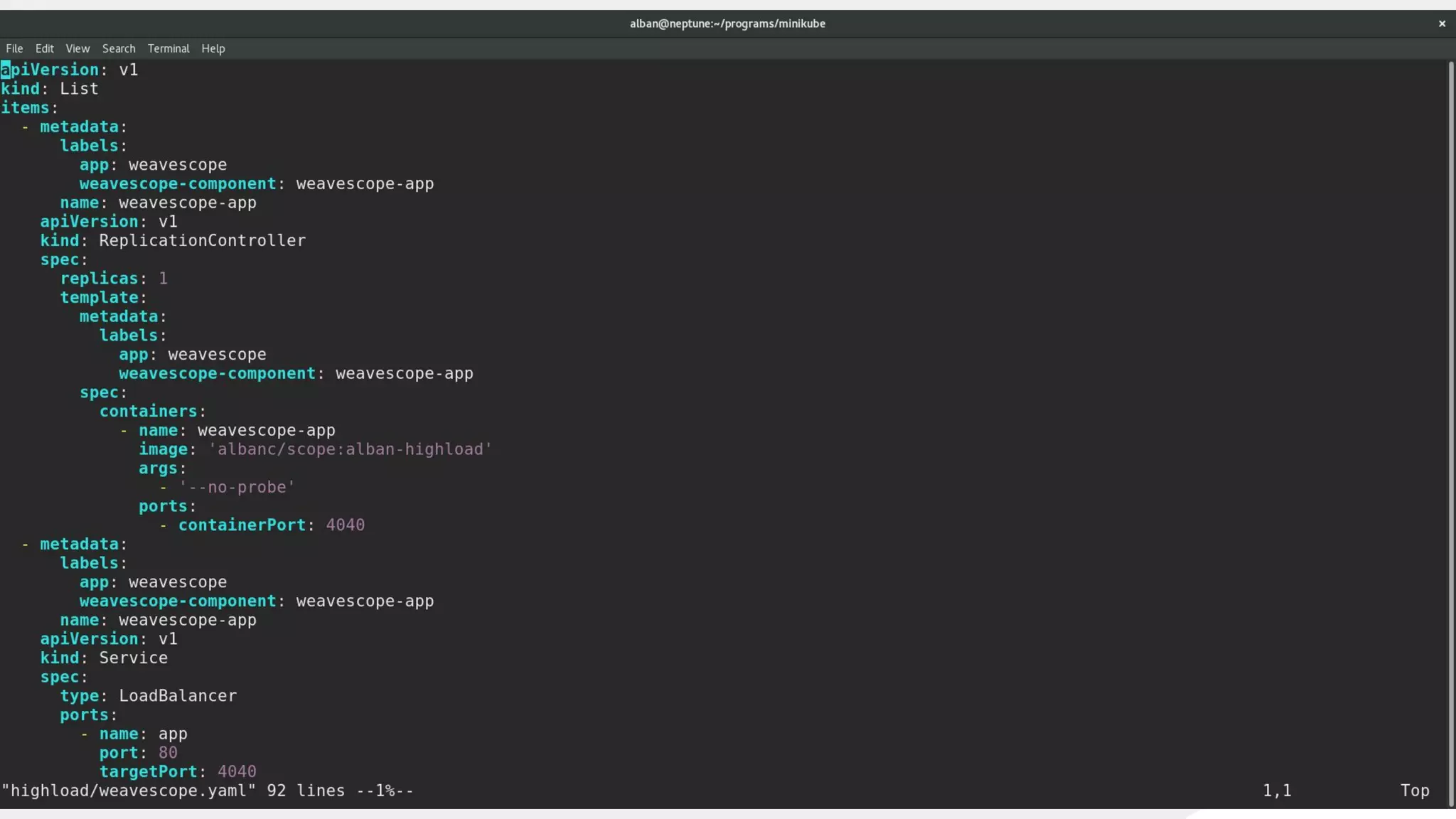
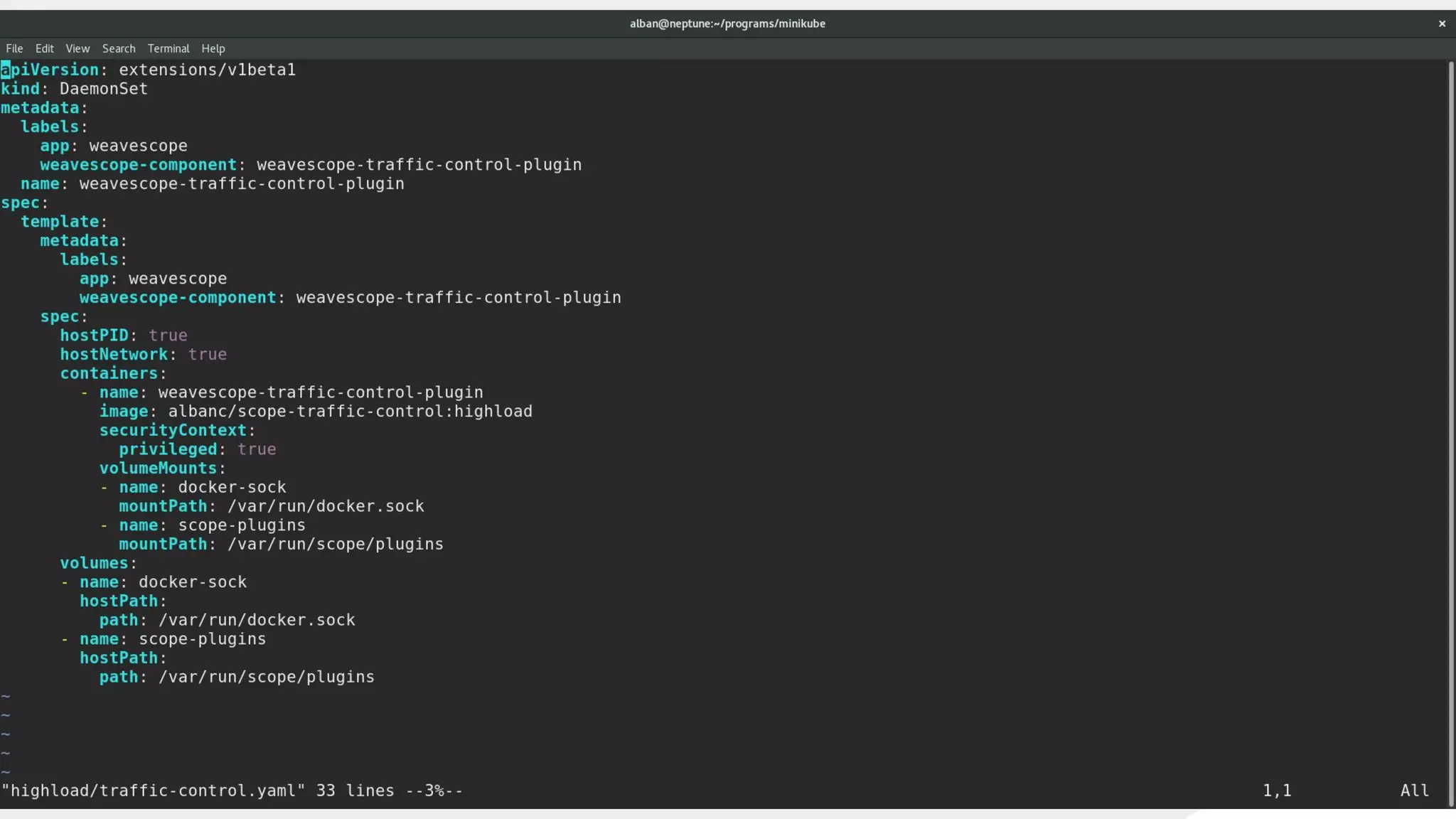
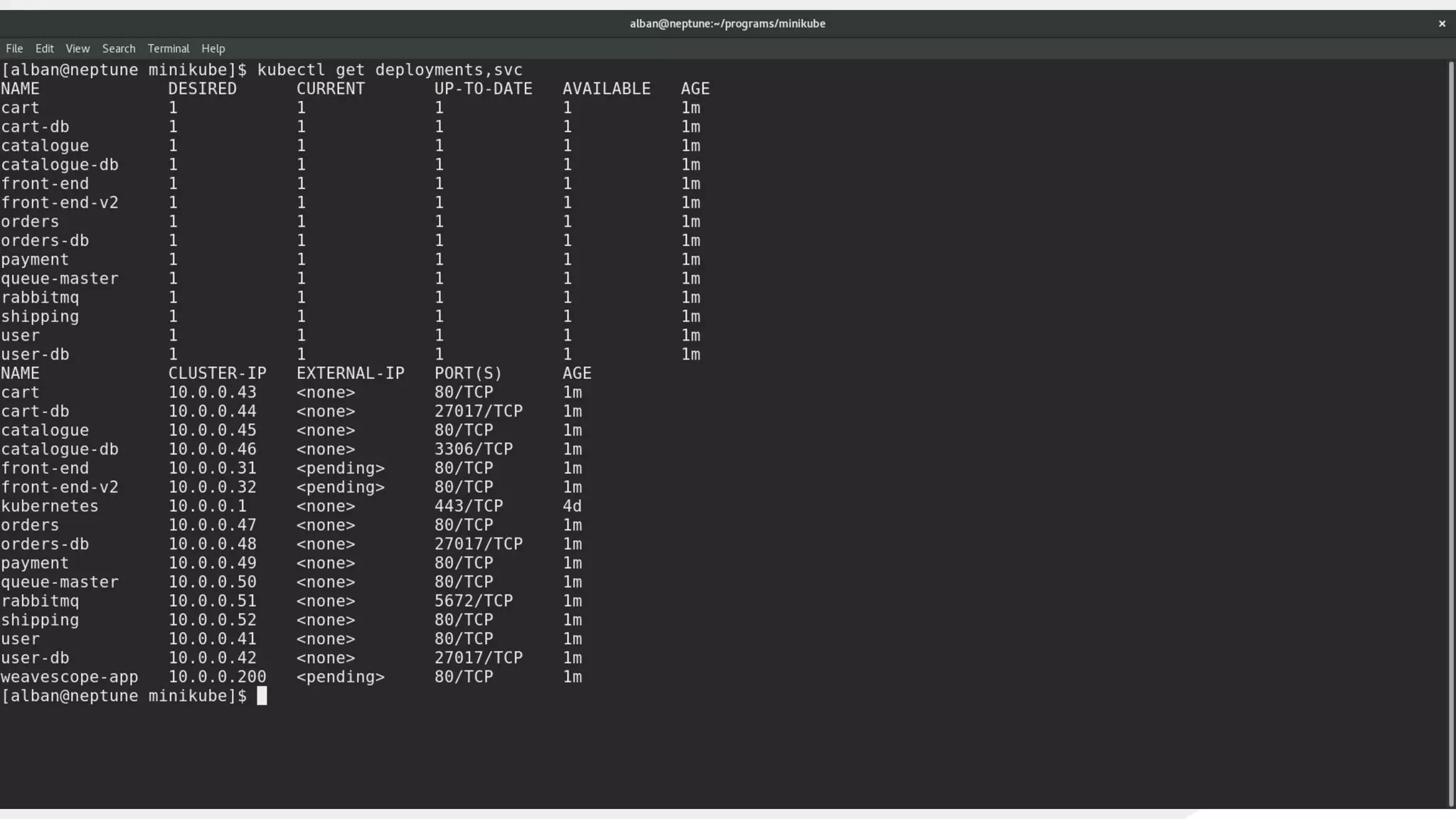
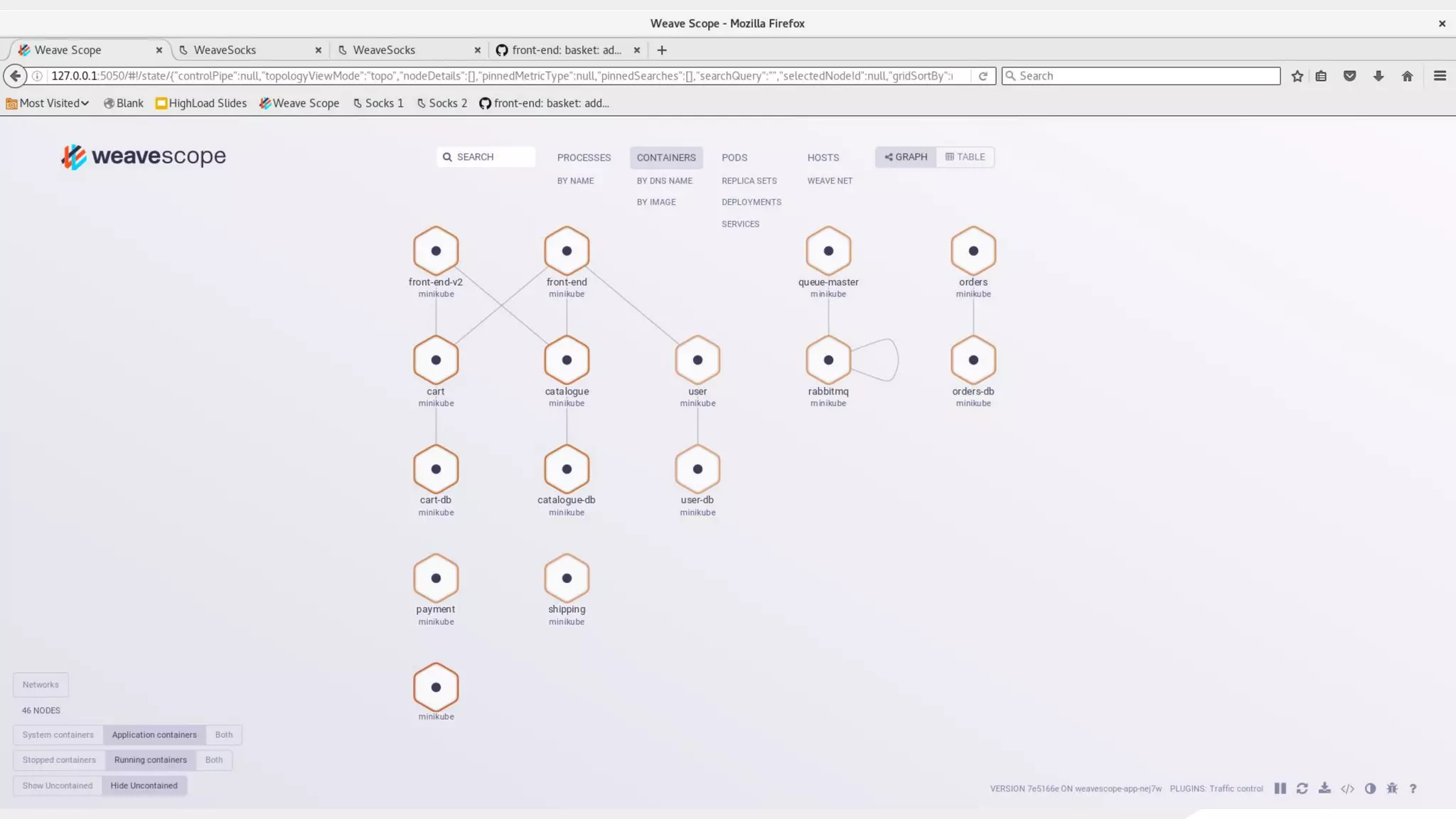
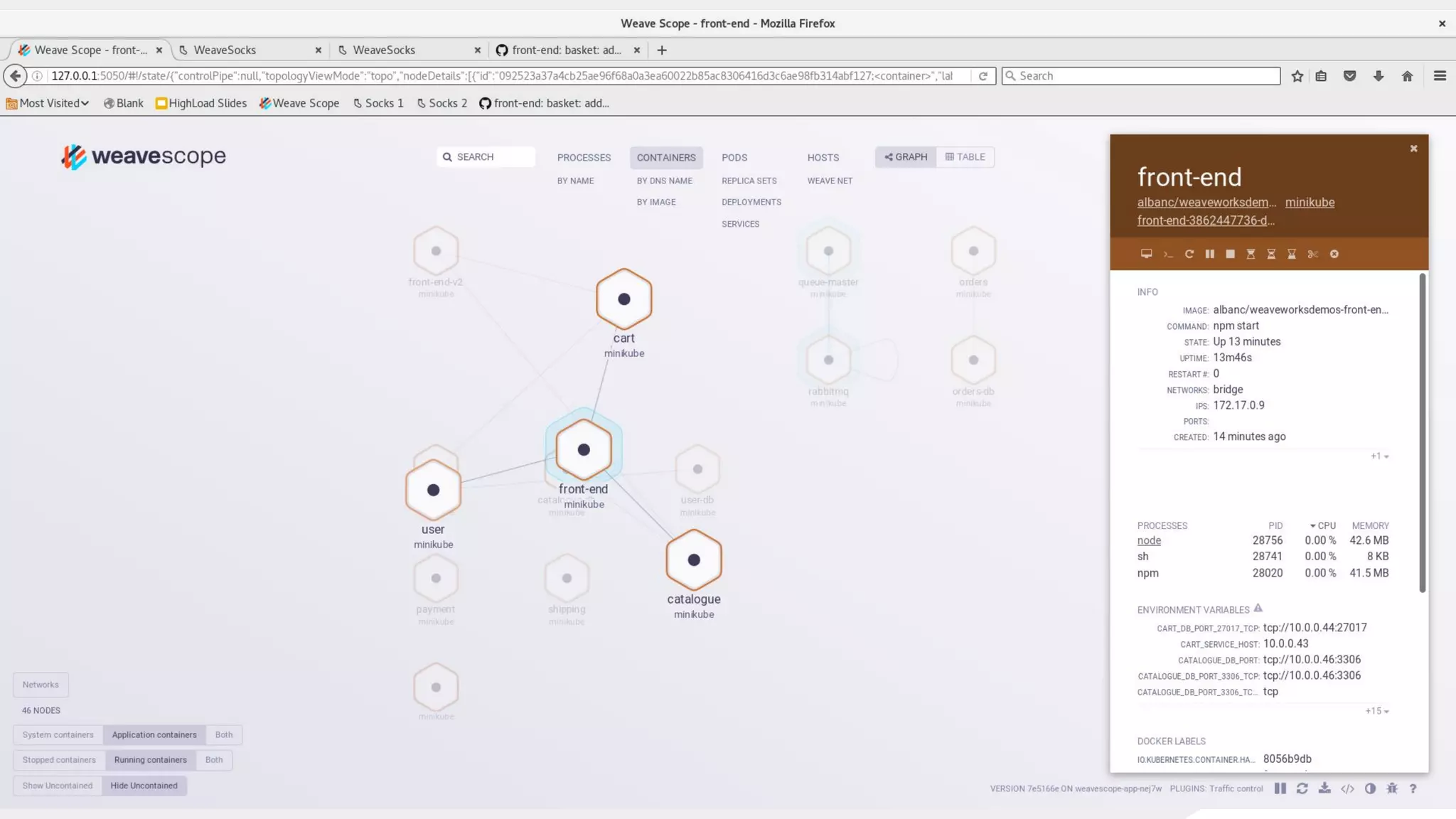
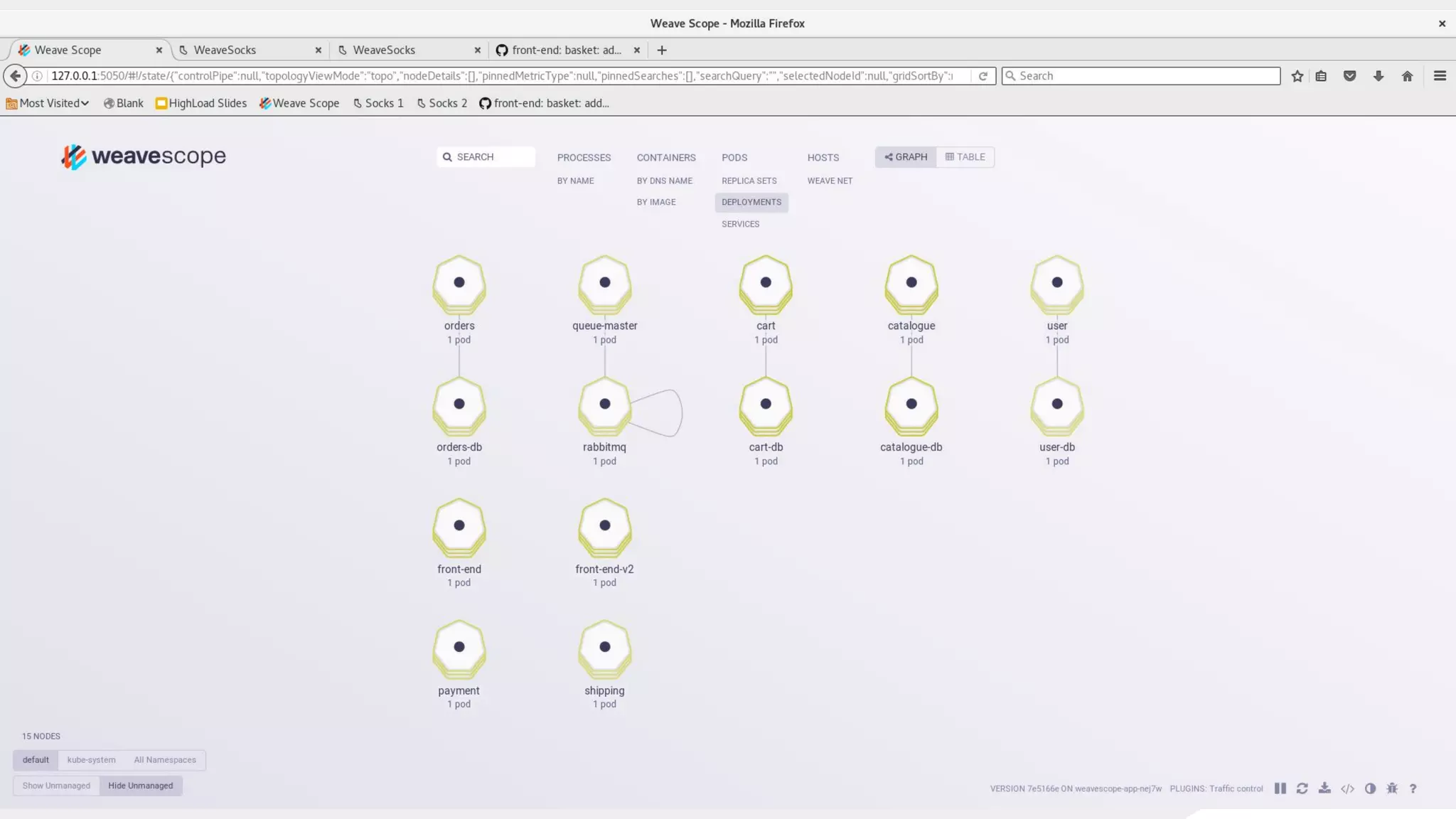
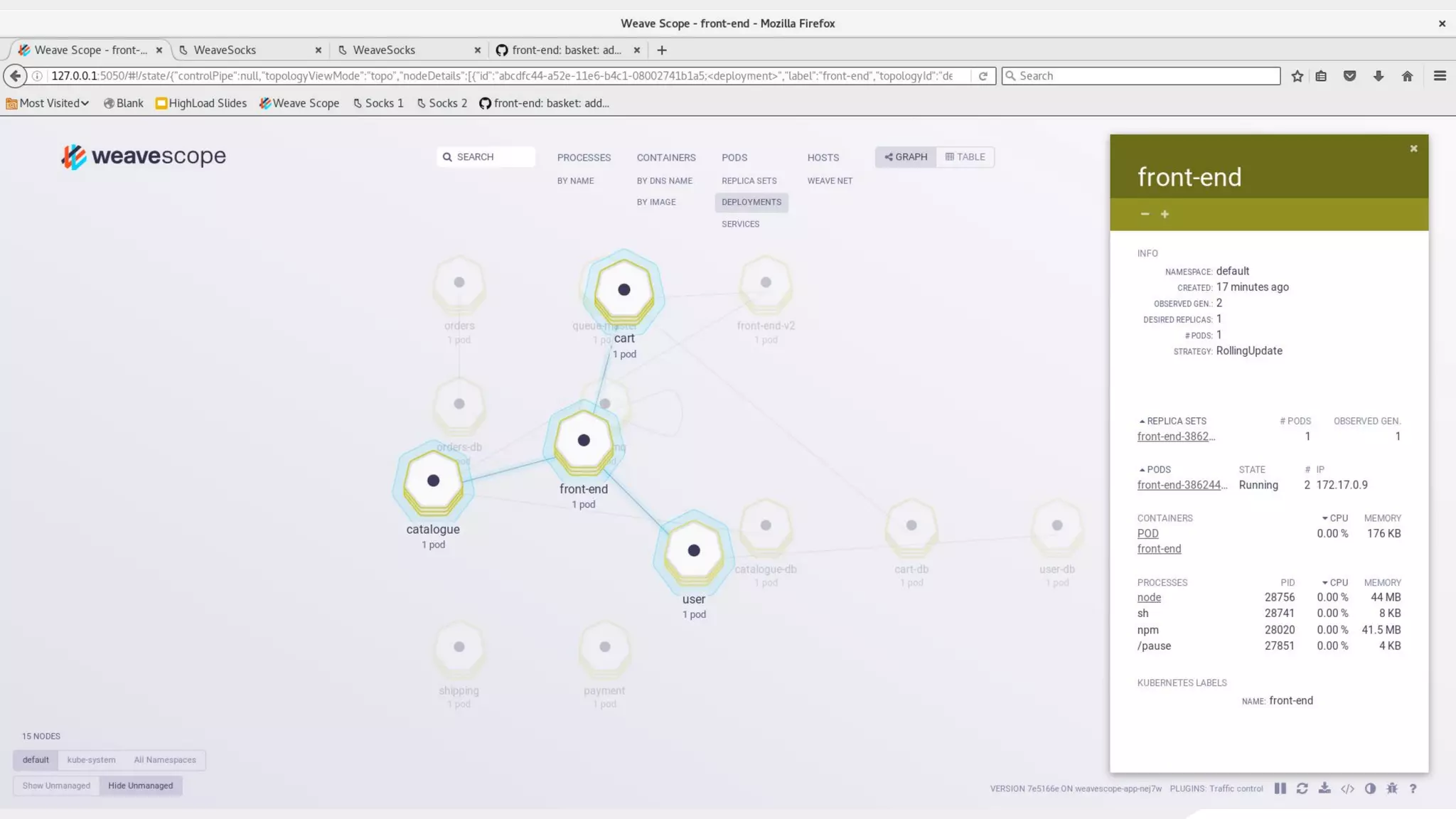
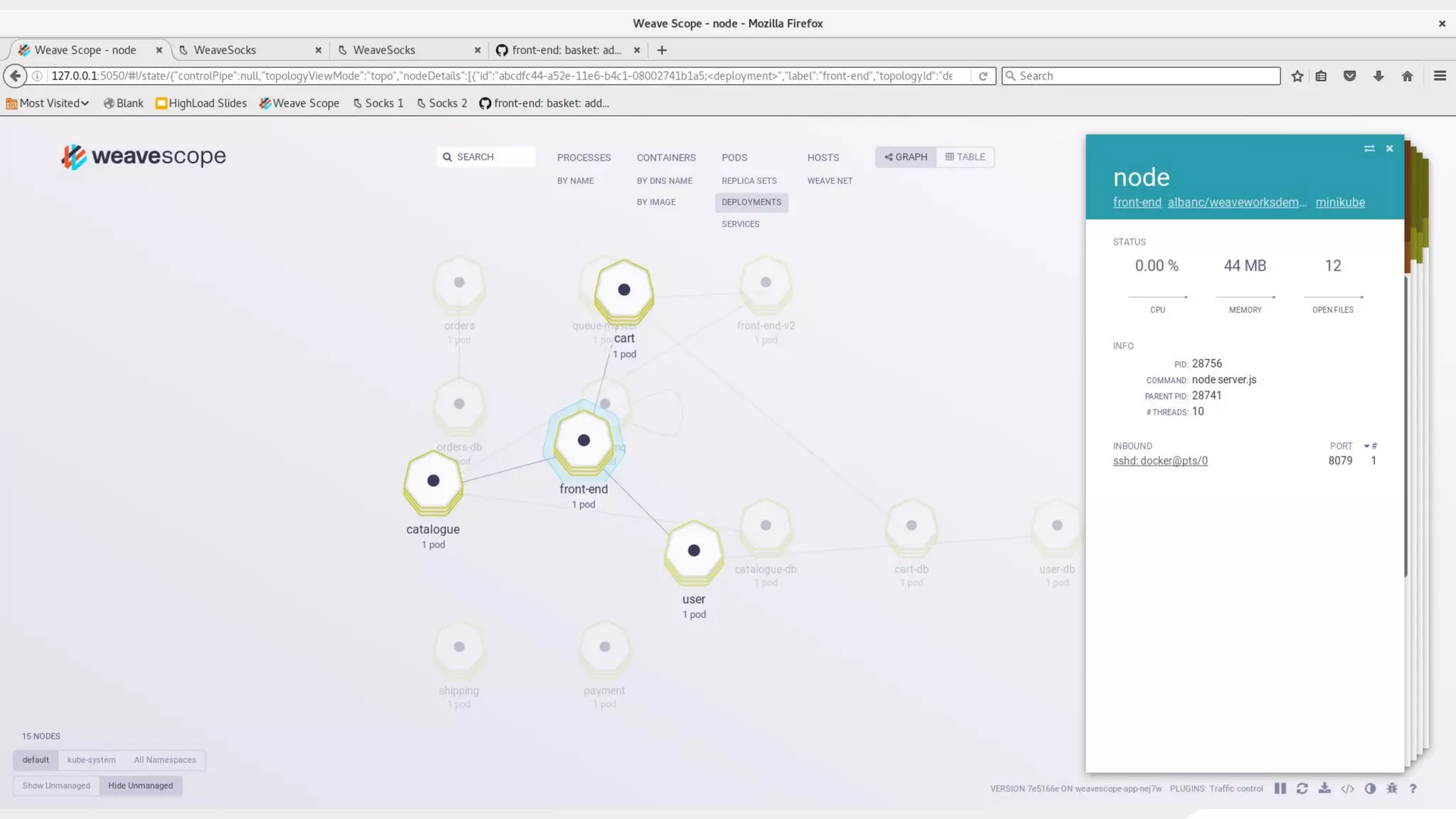
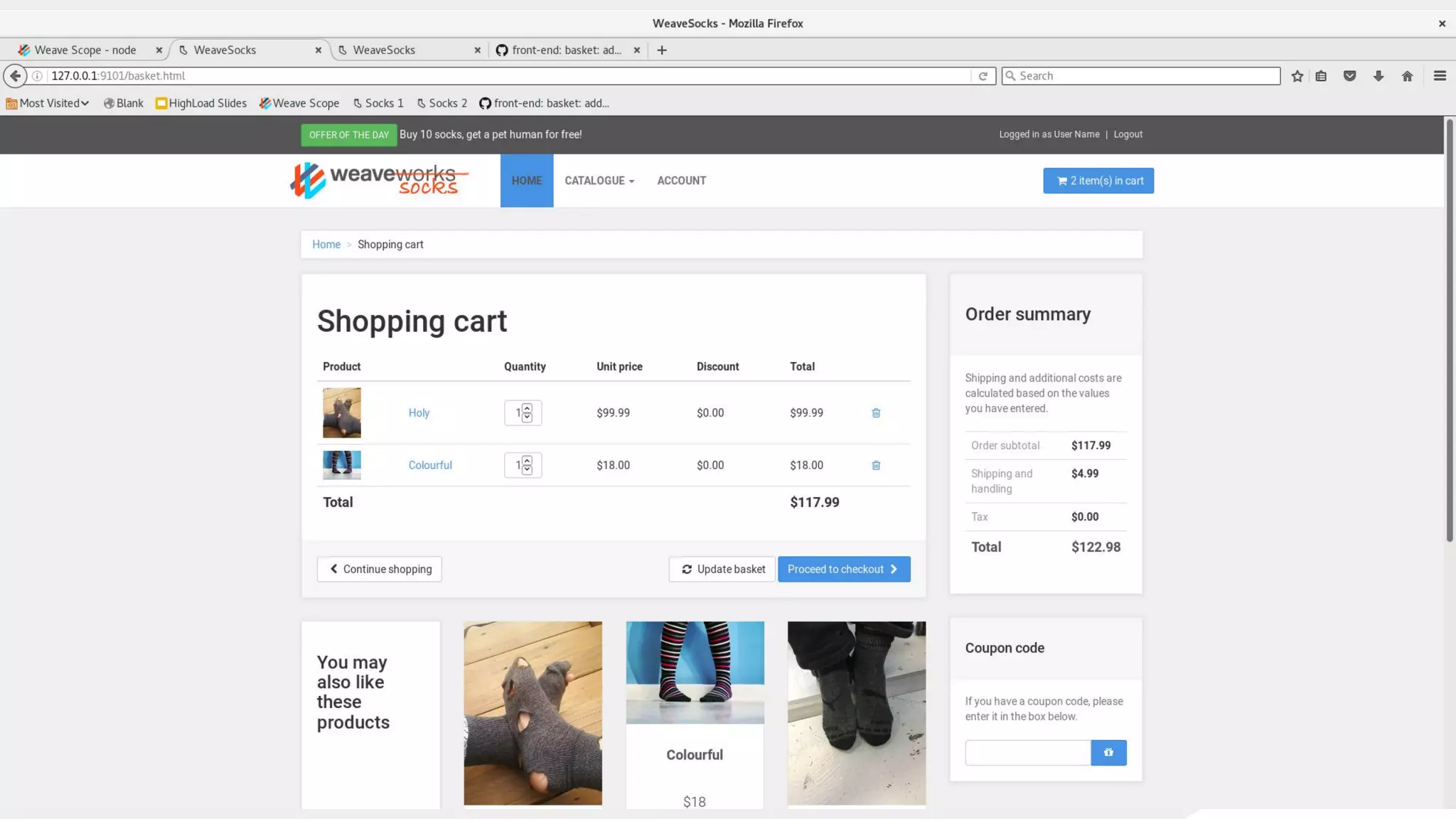
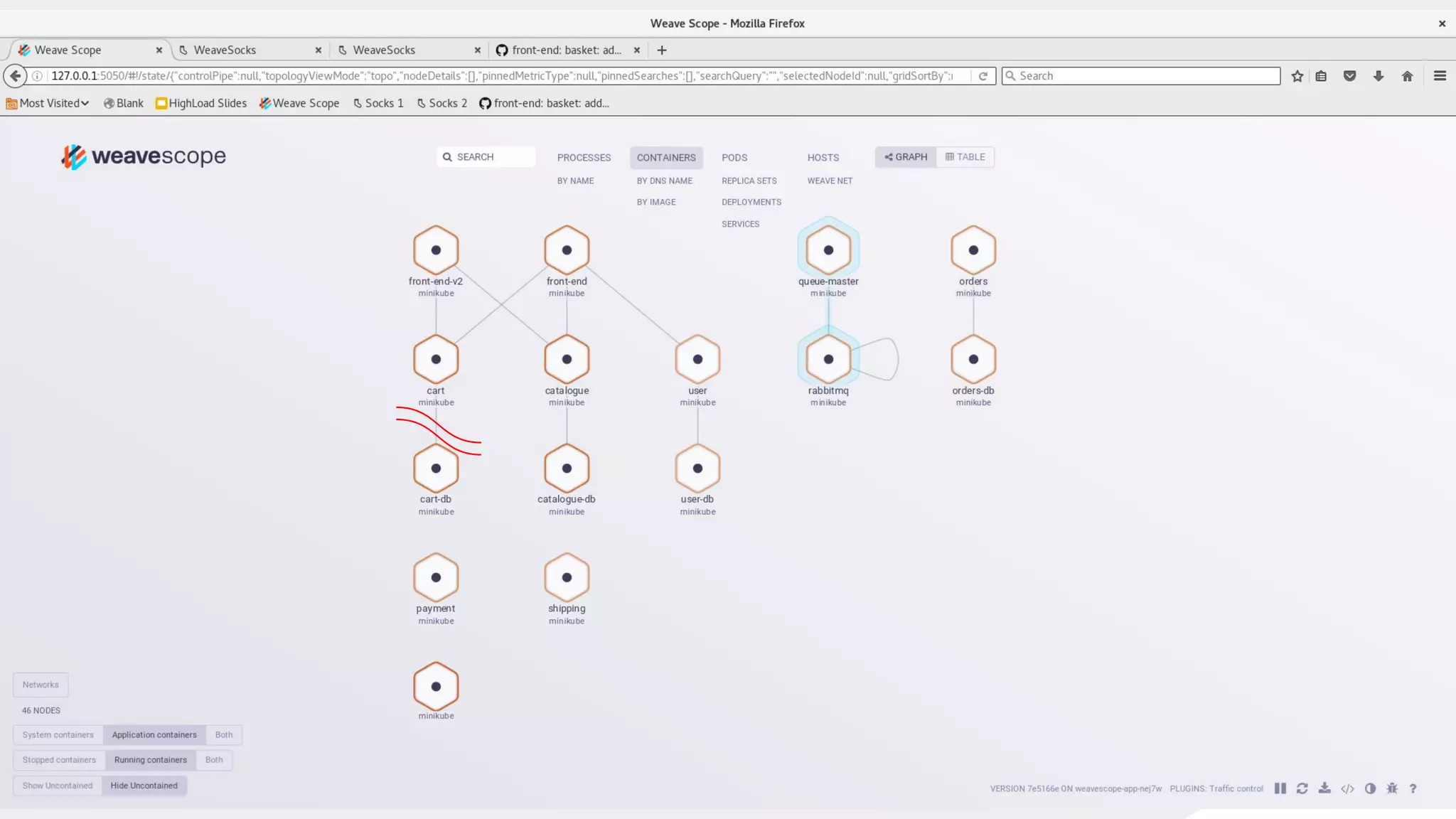
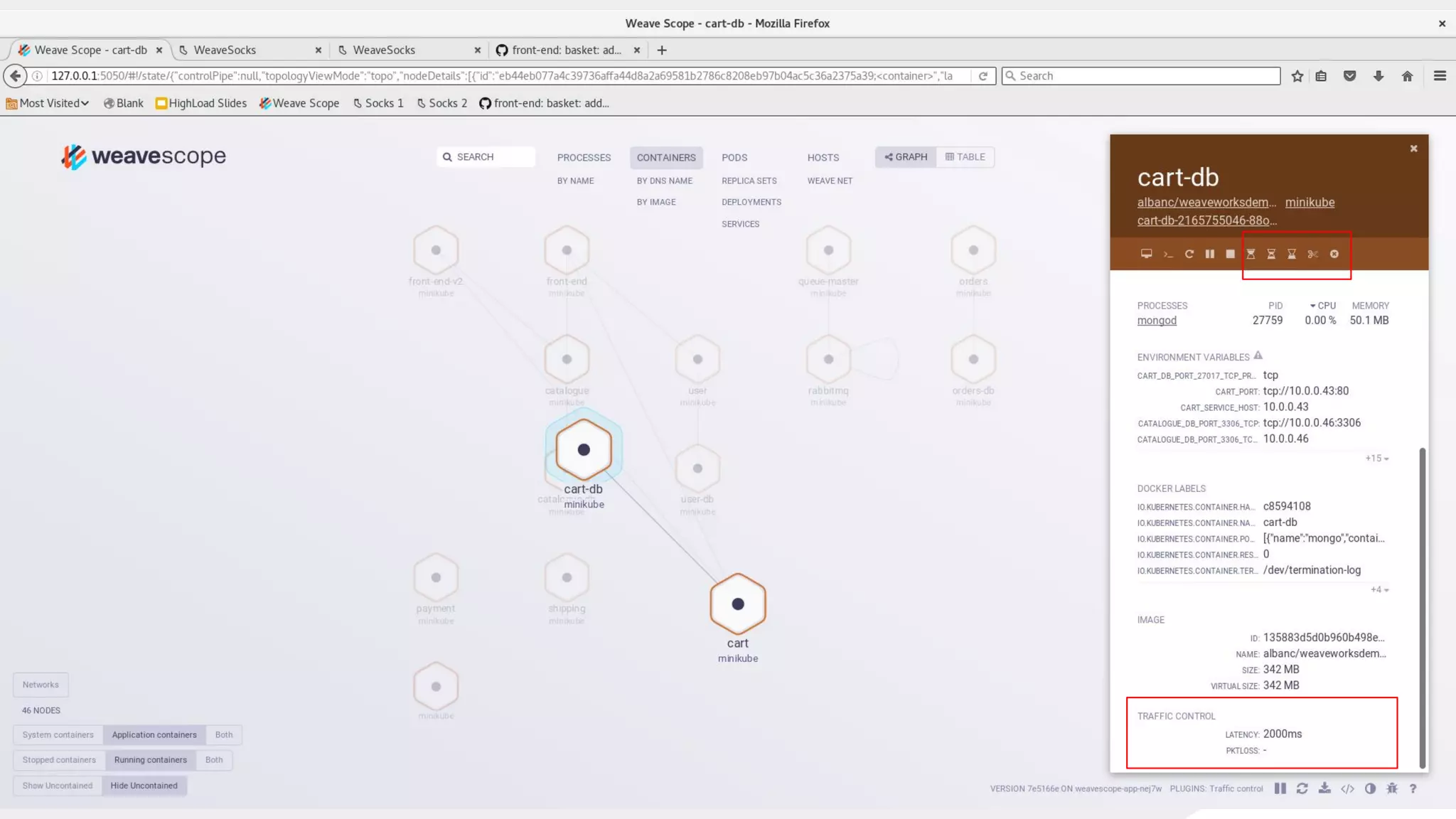
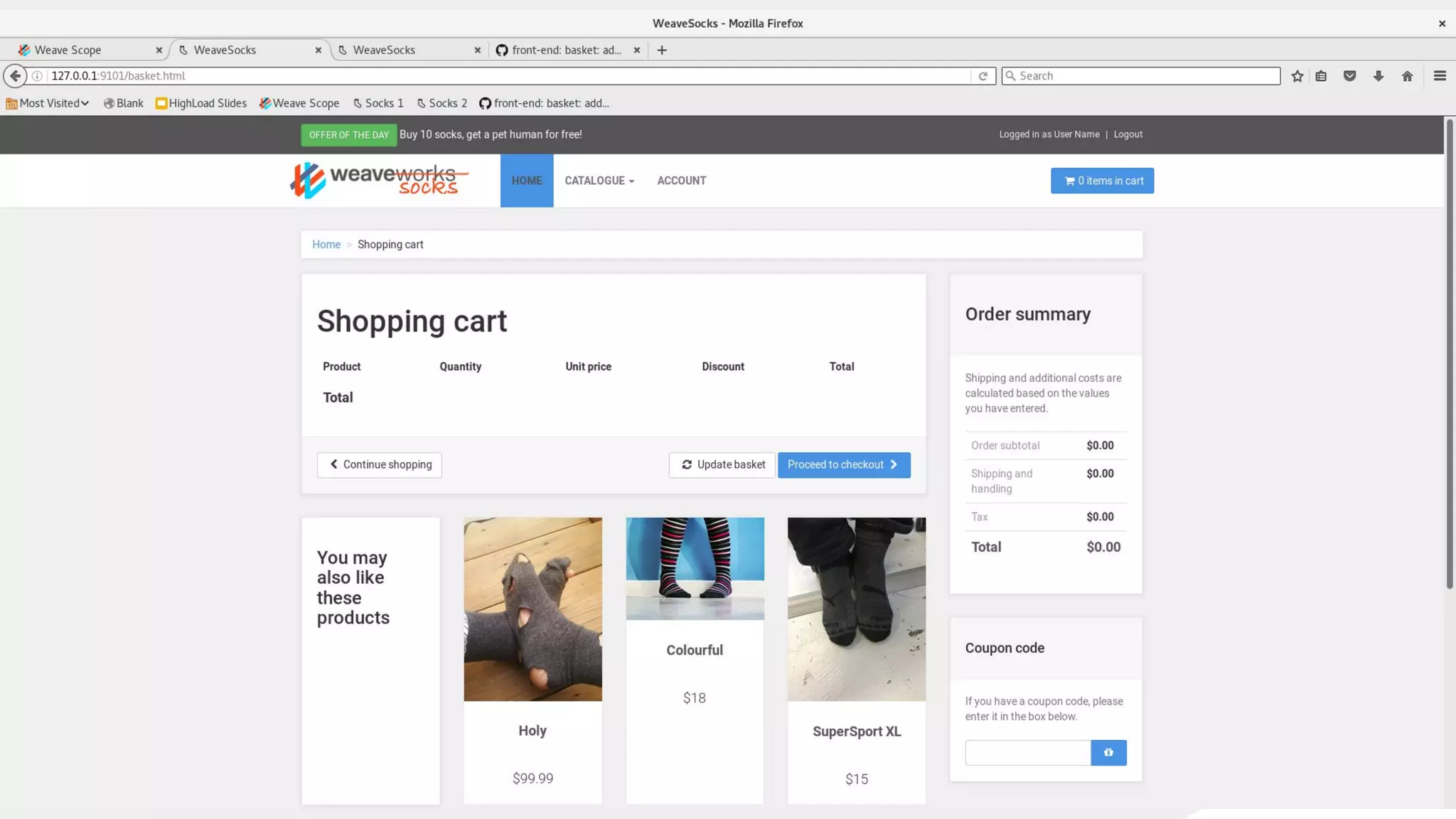
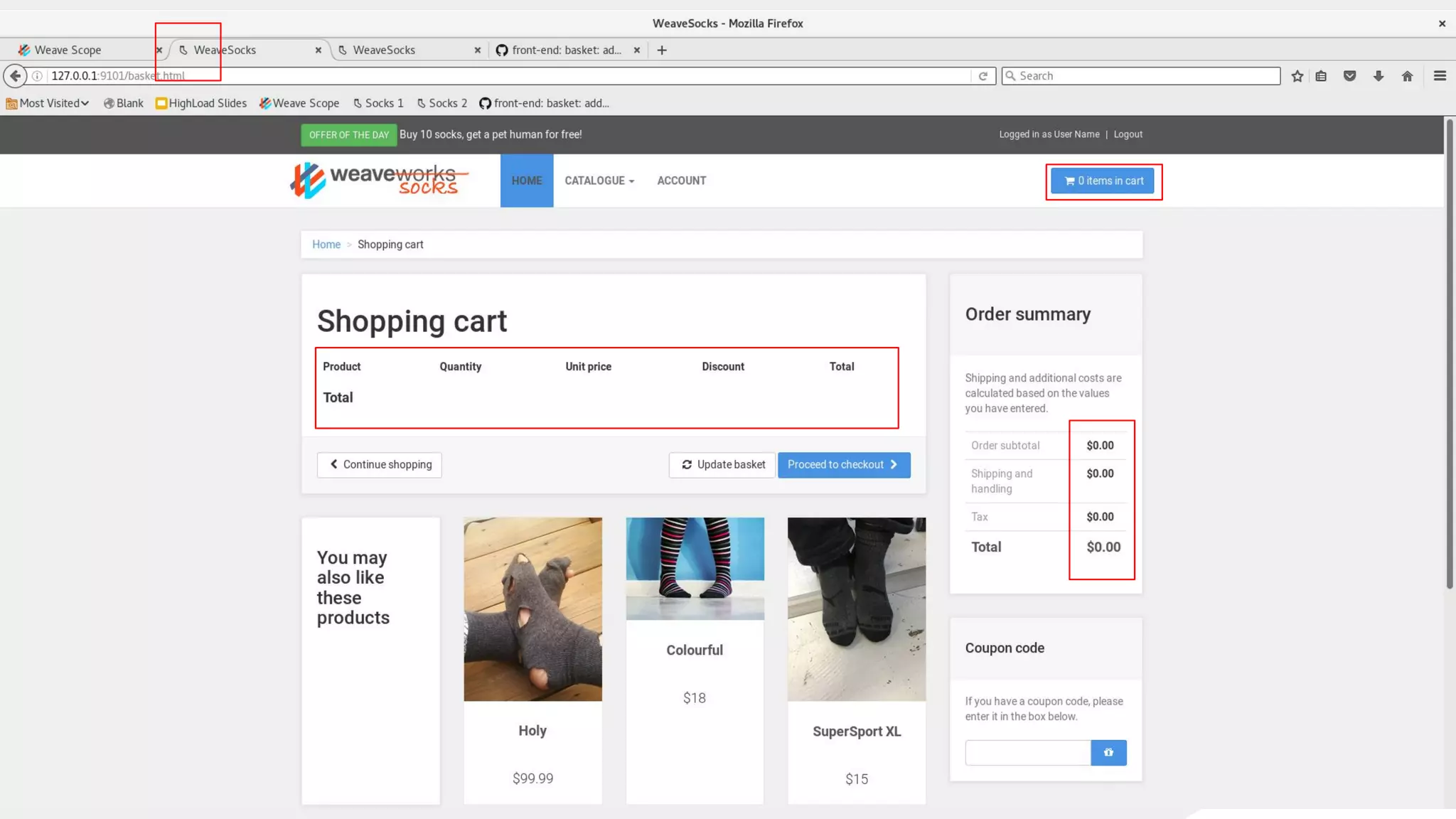
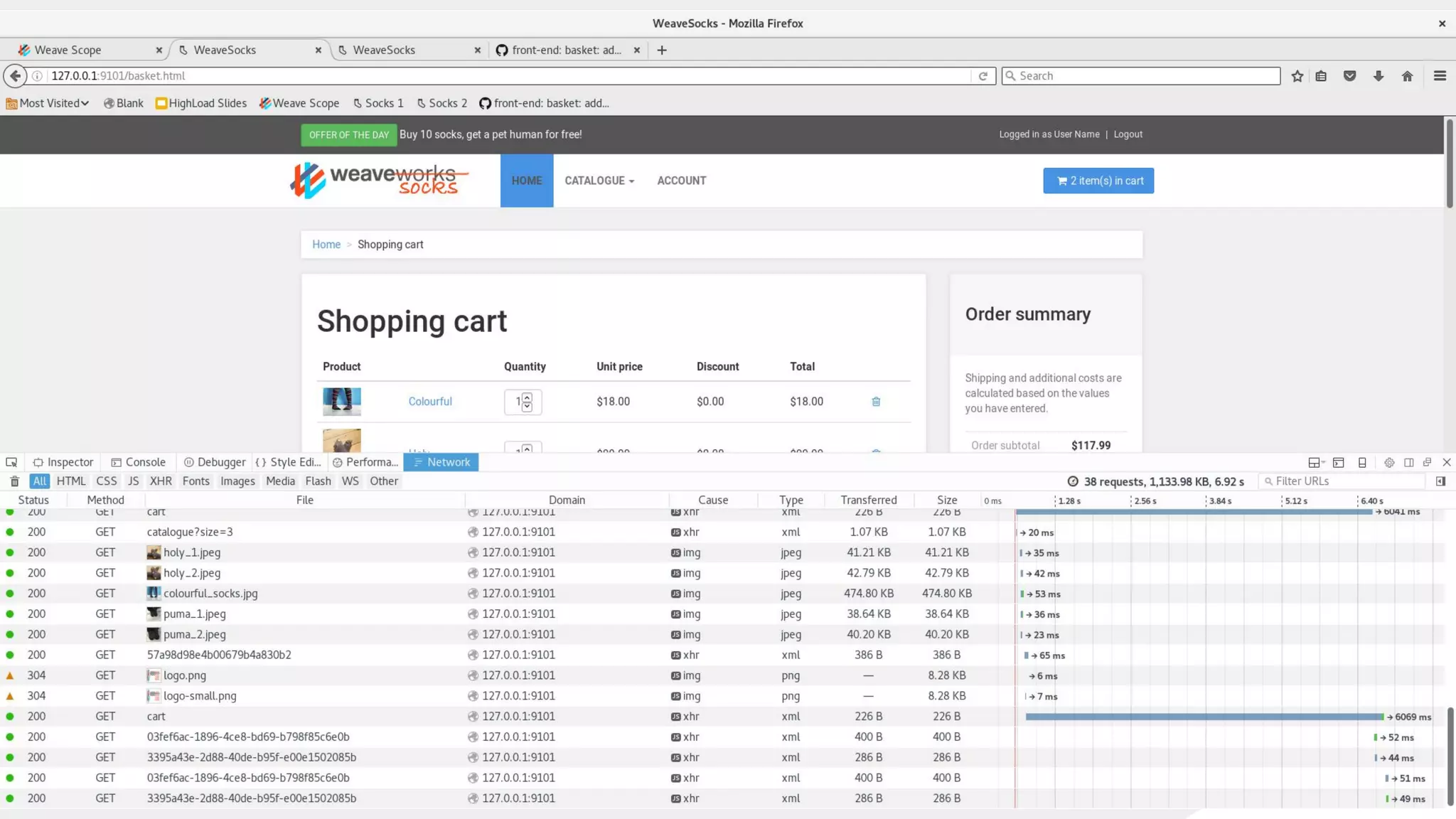
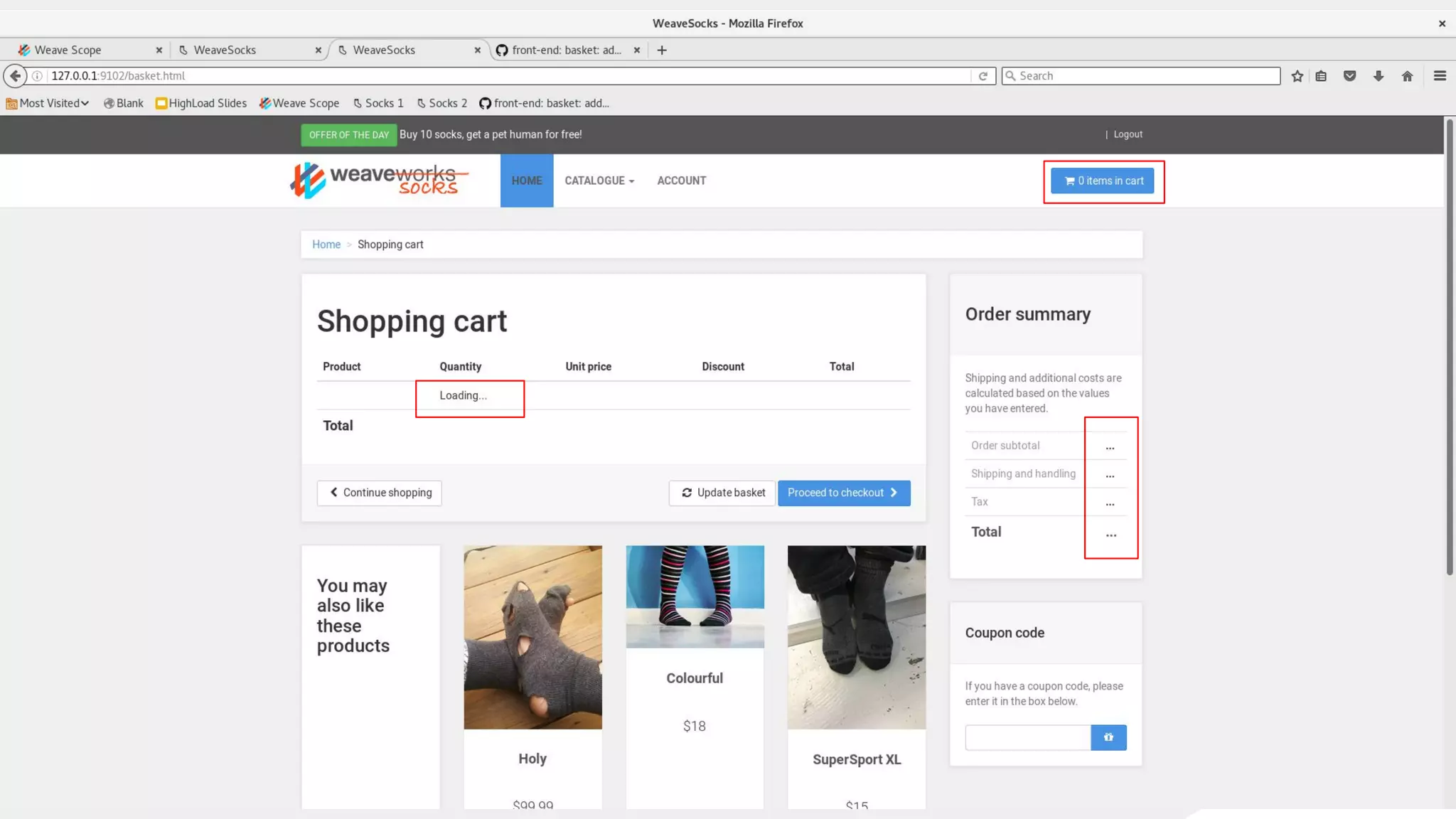
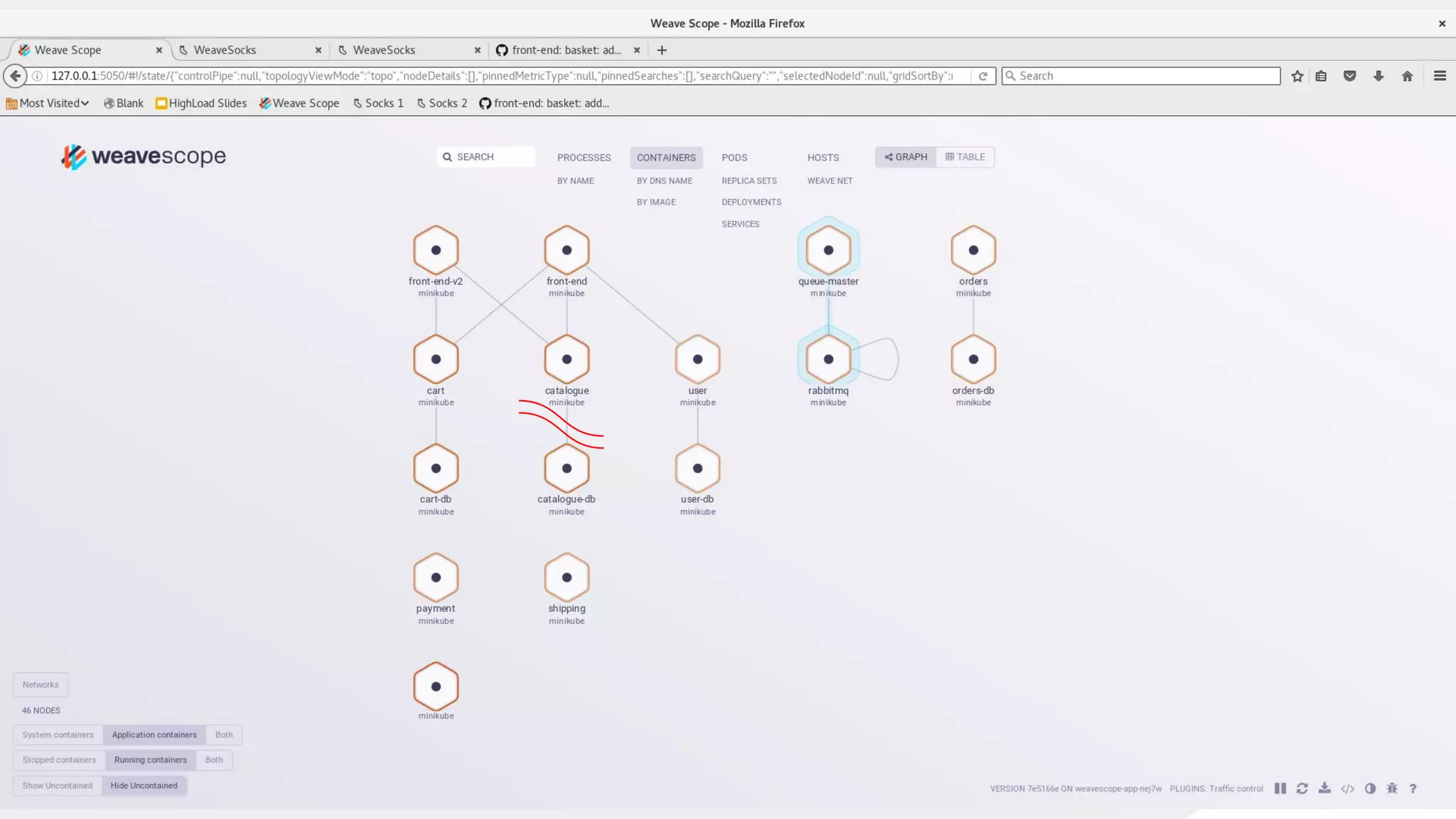


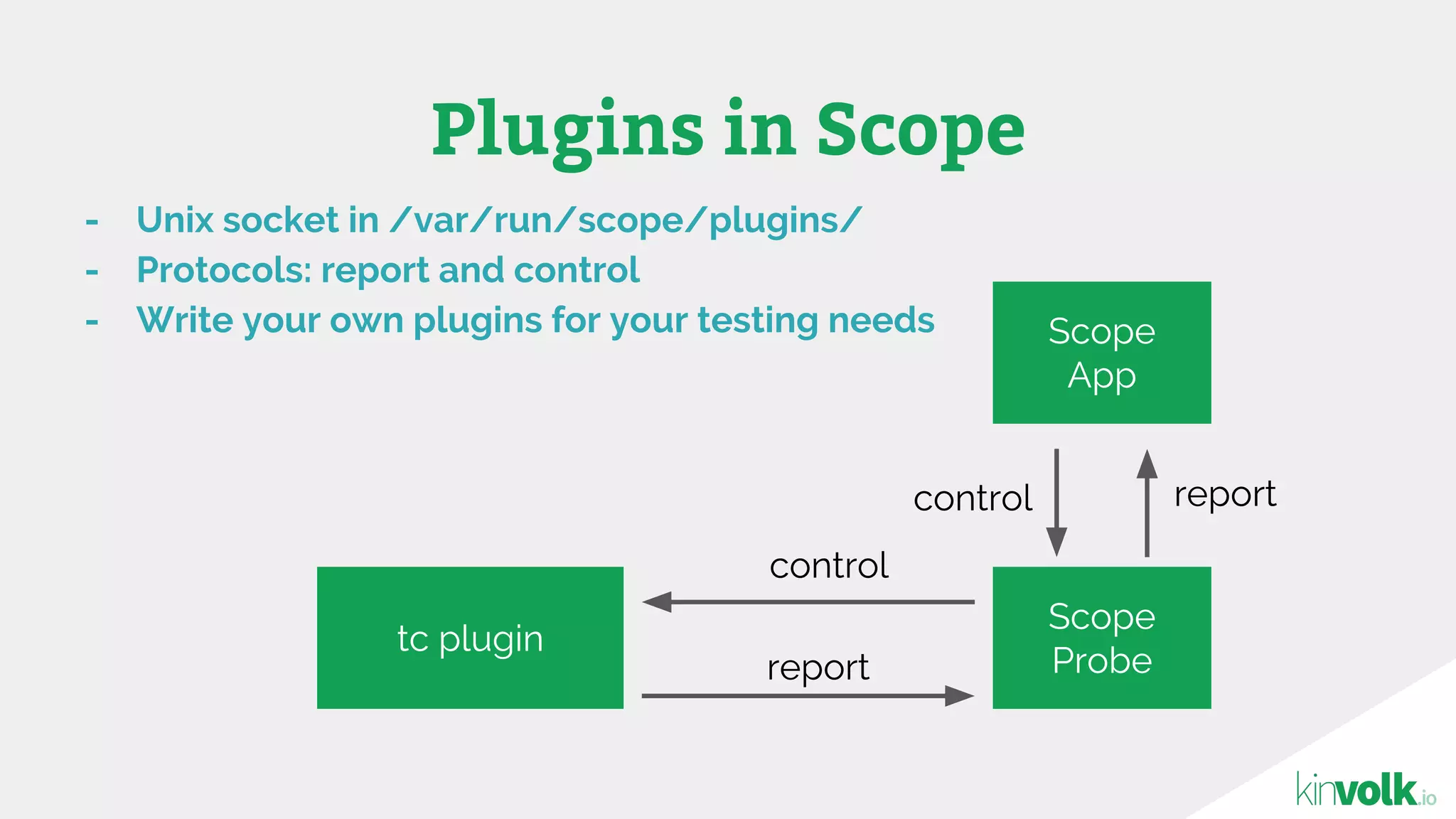
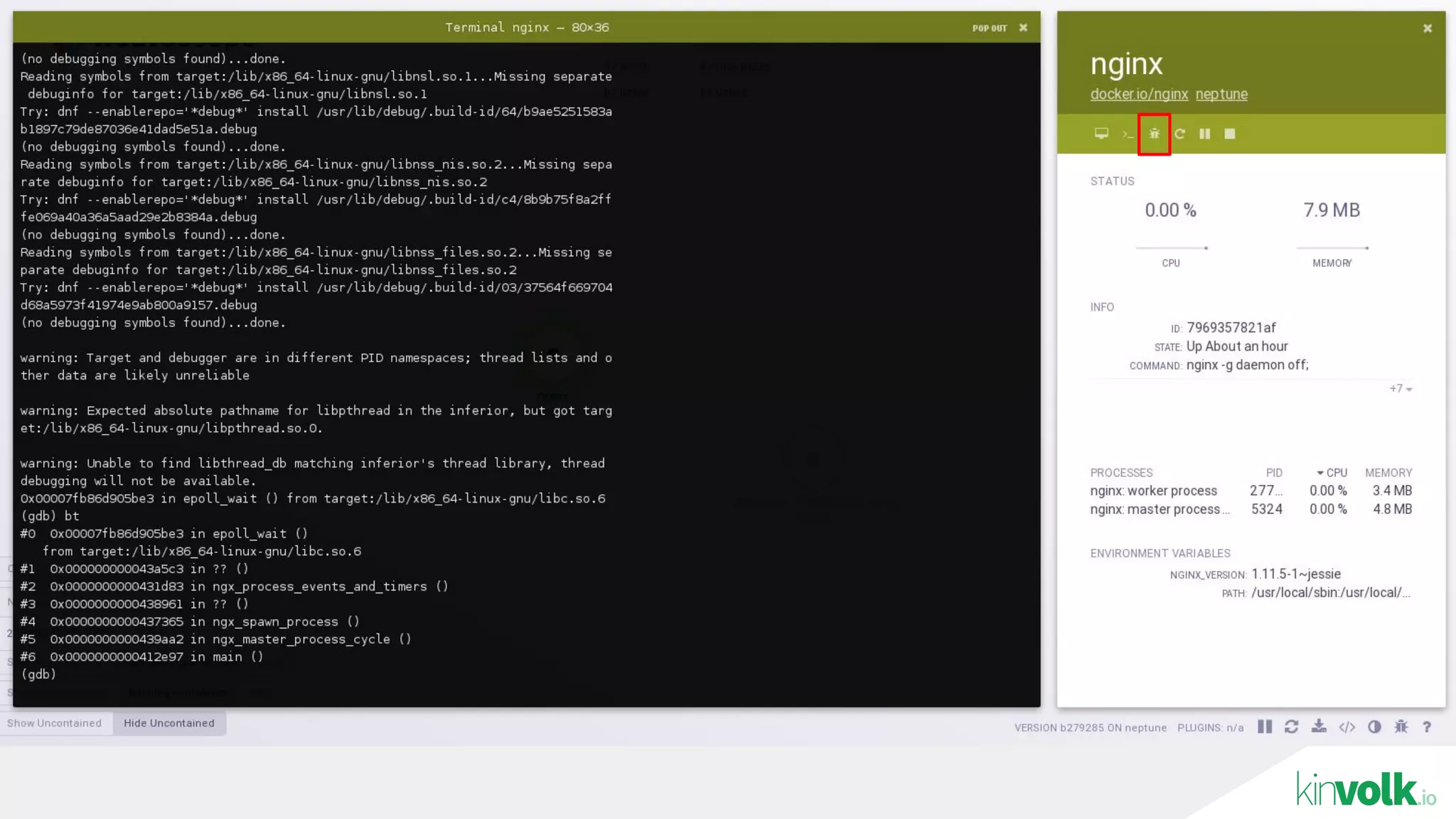

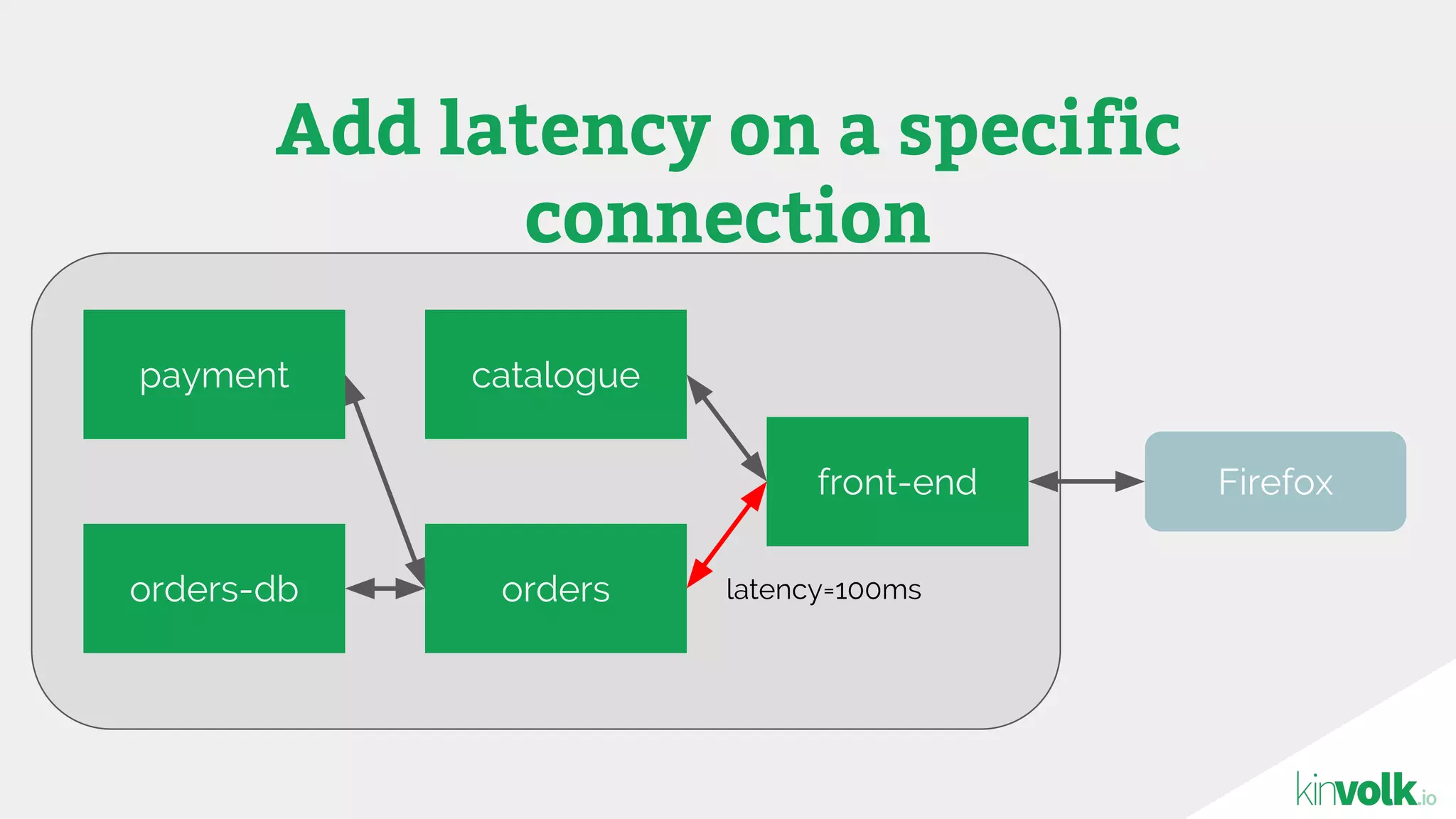
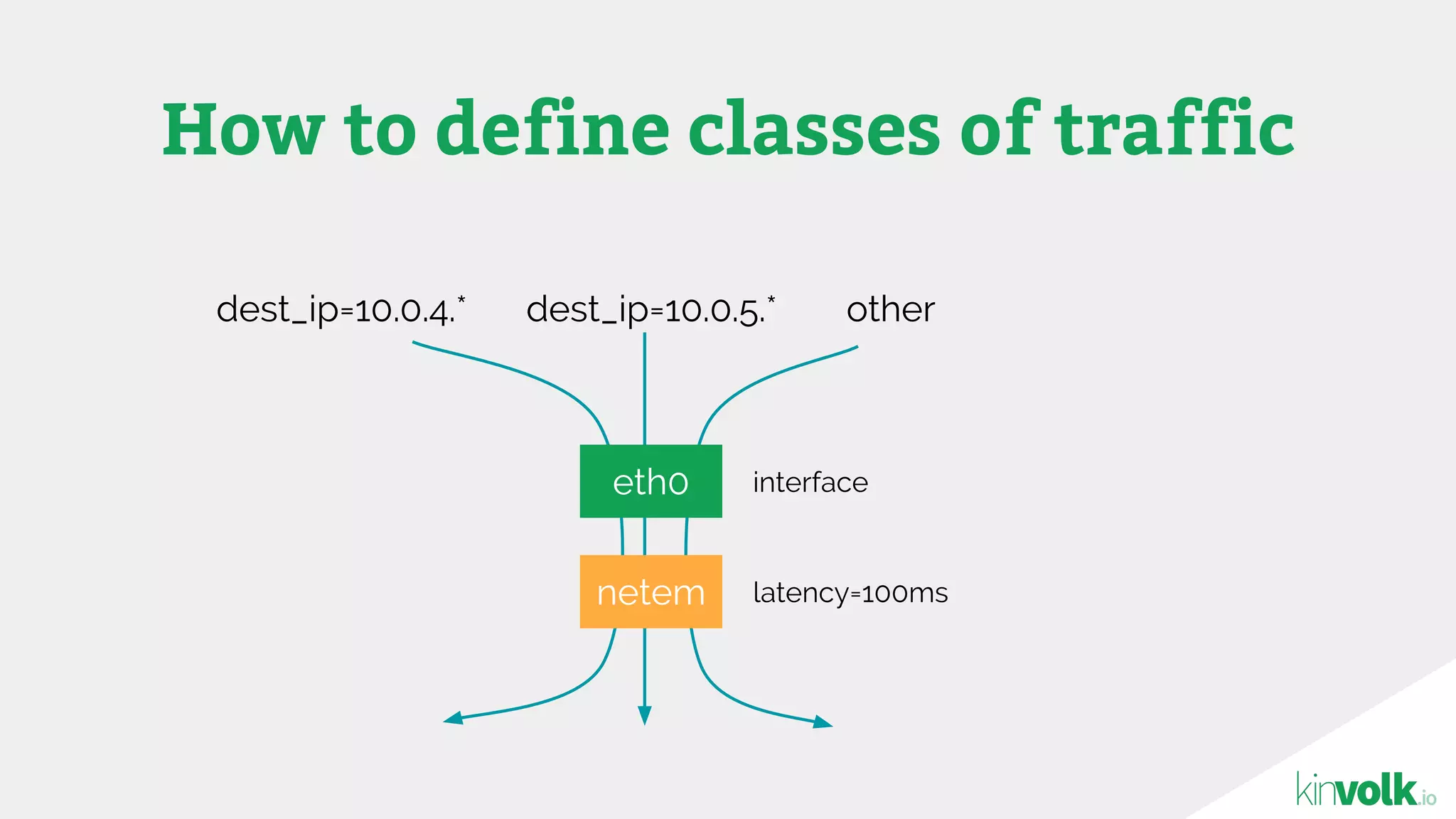
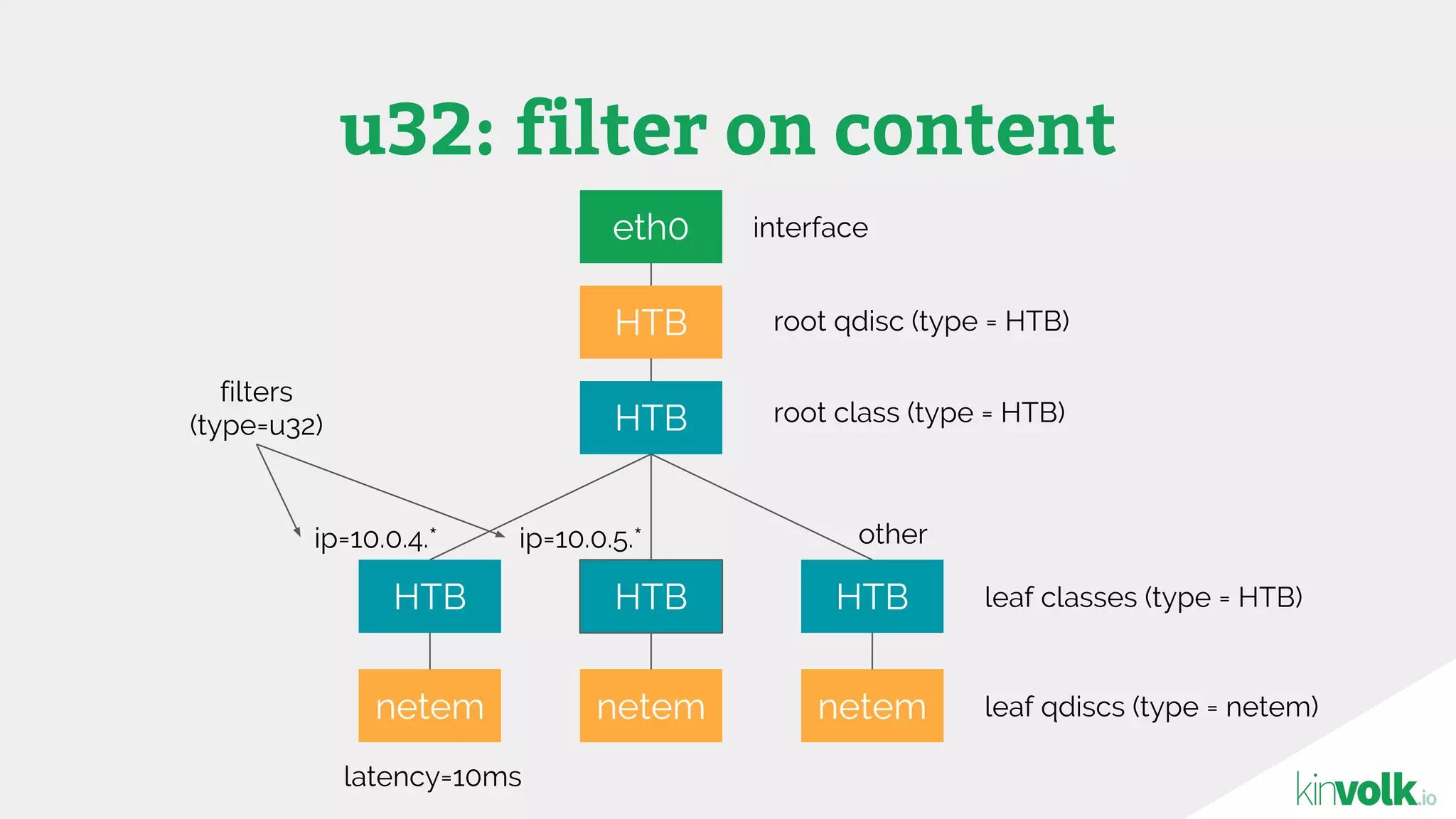
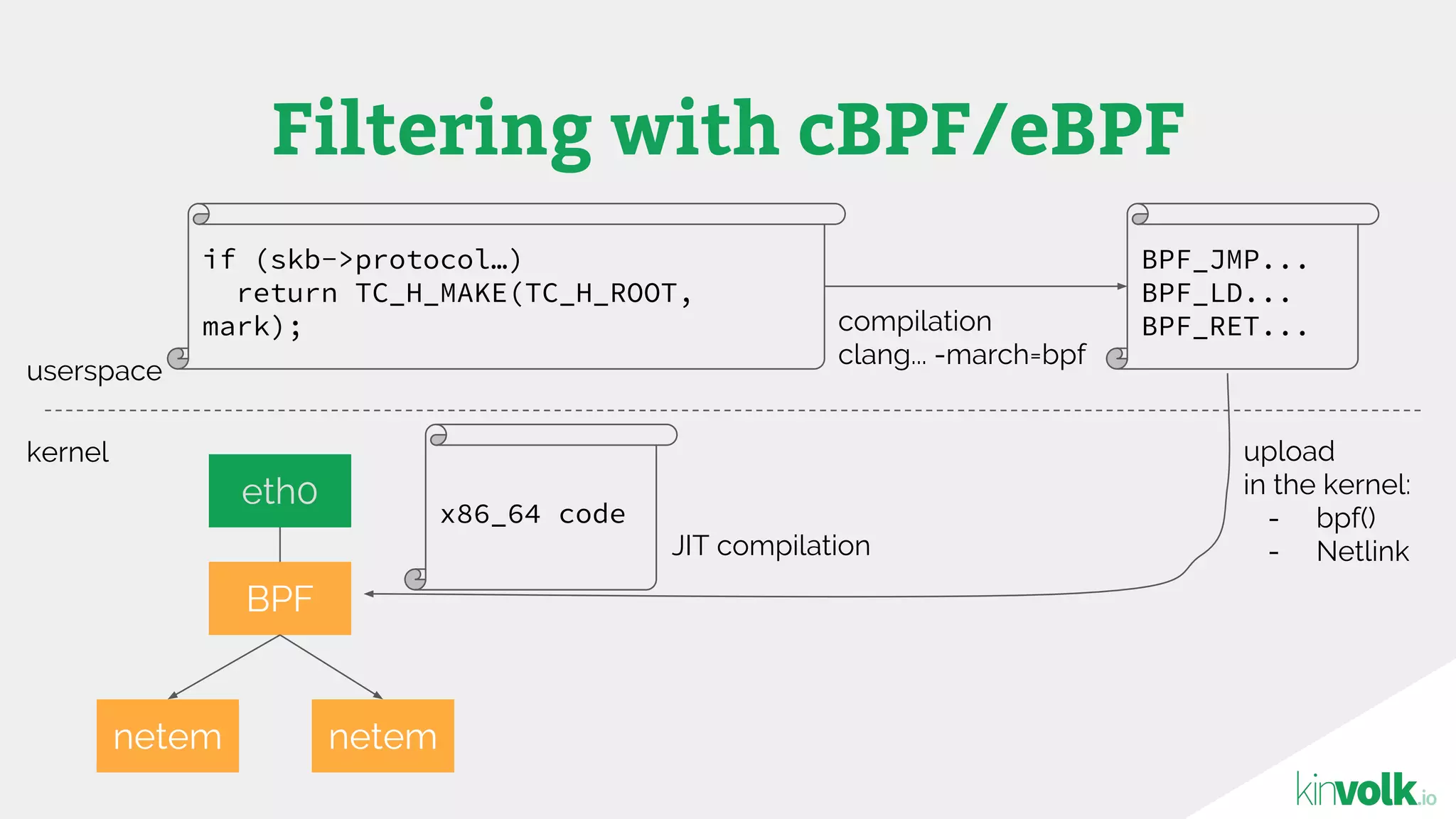
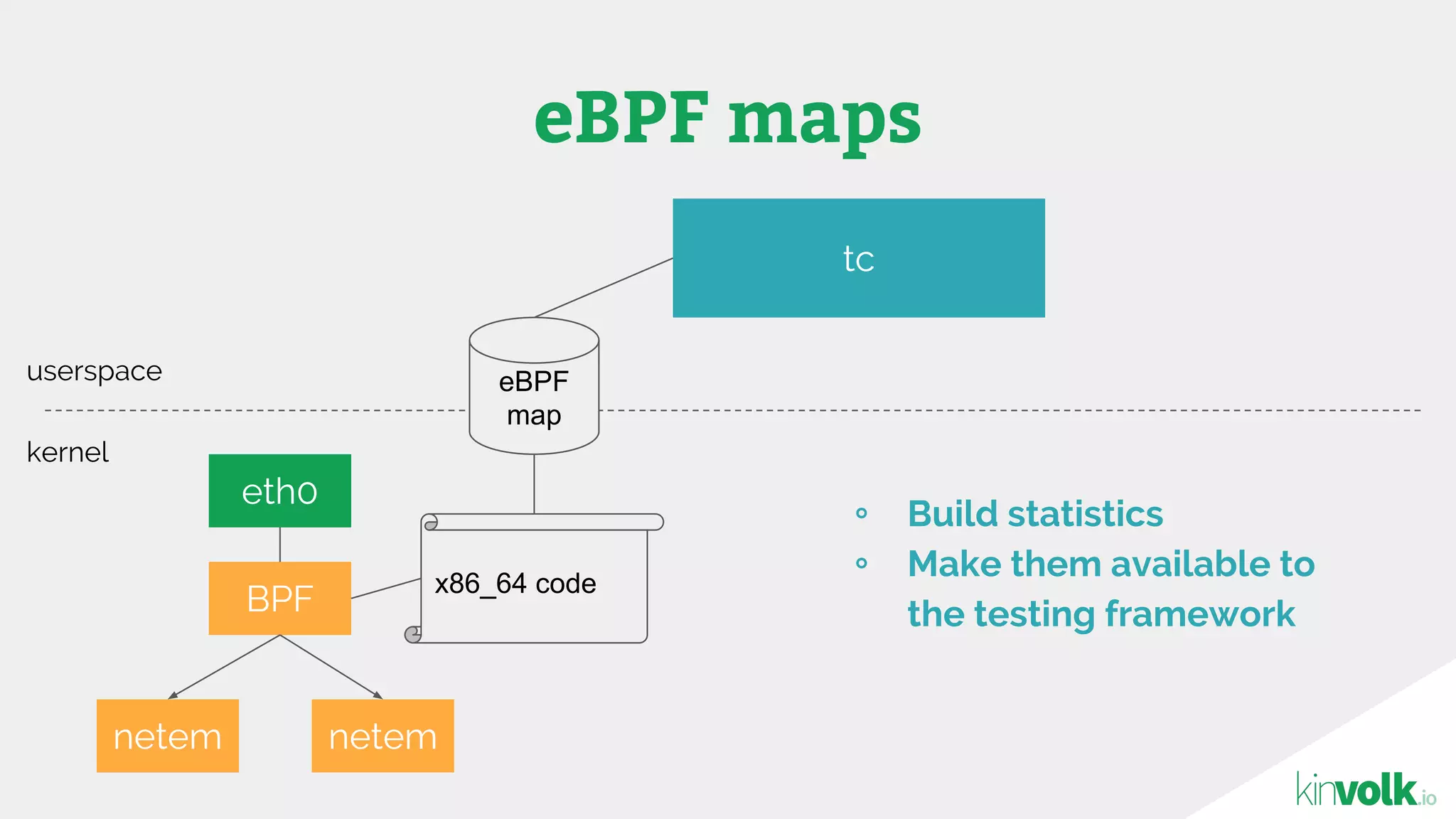
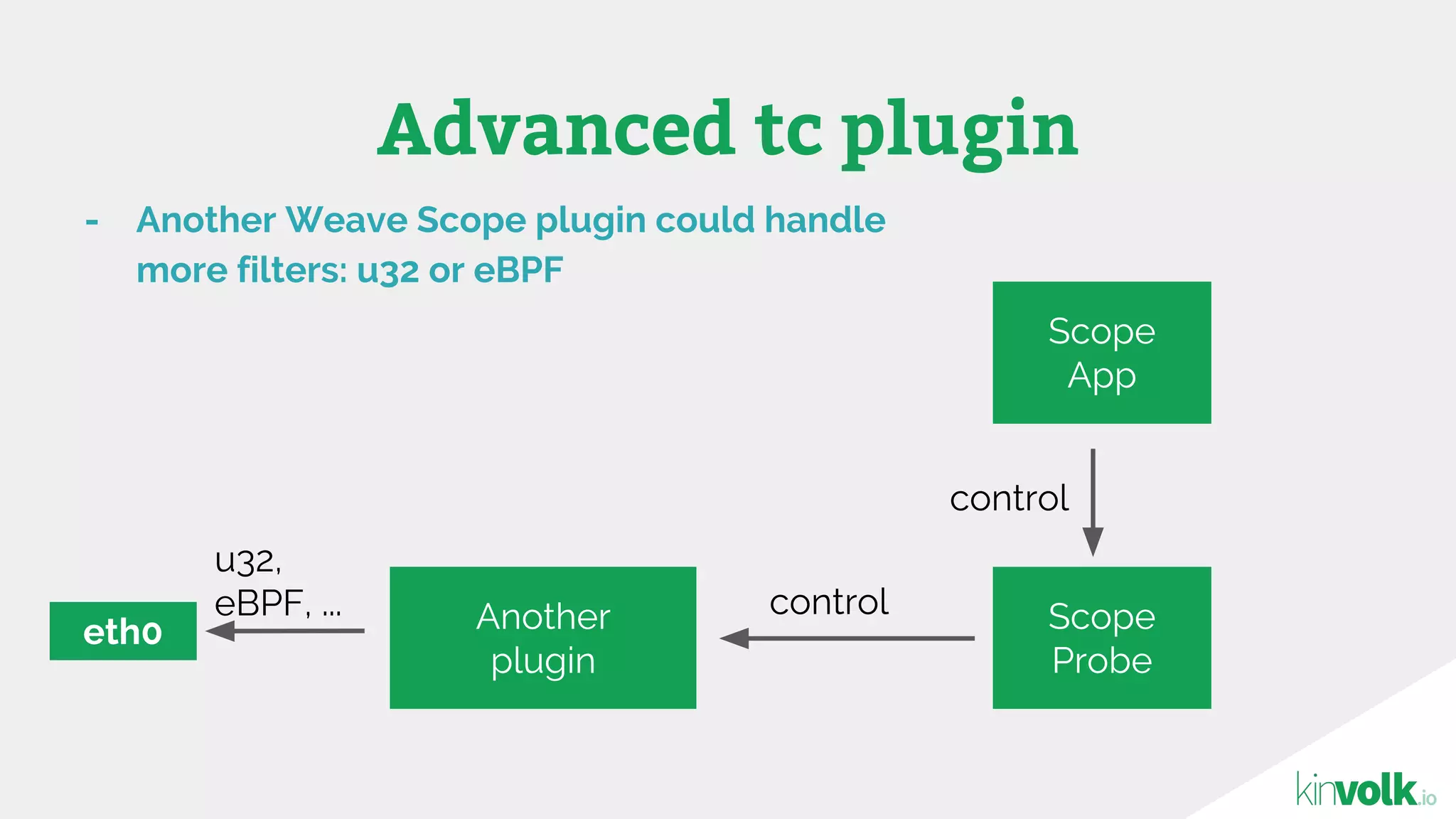



This document discusses using traffic control to test microservices applications running in containers. It describes using tools like Kubernetes, Weave Scope, and netem to configure network emulation scenarios like bandwidth limiting, latency injection and packet dropping. A demo application is shown running in Kubernetes pods with Weave Scope visualizing network traffic and a traffic control plugin modifying network behavior for testing purposes. Advanced filtering options using eBPF and custom plugins are proposed to define more complex traffic classes and collect test statistics.





















![[OpenInfra Days Korea 2018] Day 2 - E5-1: "Invited Talk: Kubicorn - Building ...](https://cdn.slidesharecdn.com/ss_thumbnails/e60955buildingsimplekubernetes-180705043459-thumbnail.jpg?width=640&height=640&fit=bounds)





















































































