Test slide for the lab - Target prioritization
•Download as PPTX, PDF•
1 like•345 views

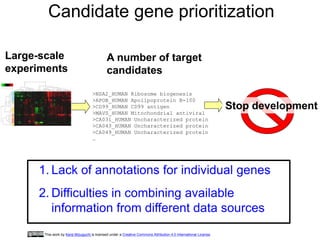
This document discusses candidate gene prioritization for large-scale experiments. It notes that there are challenges in combining available information from different data sources due to lack of annotations for individual genes. The process involves taking many candidate genes as input and applying integrated knowledge discovery to output a smaller number of selected target genes.
Report
Share
Report
Share

Recommended
97 craig c. mello - 7282564 - rna interference pathway genes as tools for t...
Craig C. Mello, Andrew Fire, Hiroaki Tabara, Alla Grishok - RNA Interference Pathway Genes as Tools for Targeted Genetic Interference
Genetic engineering
Genetic engineering uses biotechnology to directly manipulate an organism's genes. The CRISPR-Cas9 system allows genes to be added, removed, or altered by using the Cas9 enzyme to cut DNA at a targeted location. CRISPR-Cas9 acts as a bacterial immune system and can now be programmed to edit genes in other organisms like crops, animals, and potentially humans. This technology could help end diseases by editing genes, create genetically modified crops with desired traits, and potentially lead to "designer babies" with selected genes. However, genetic engineering also raises ethical concerns and risks unpredictable consequences.
Us7279327 Methods for producing recombinant coronavirus
The document is a United States patent describing methods for producing recombinant coronavirus particles. Specifically, it describes developing a helper cell that contains: 1) a coronavirus permissive cell; 2) a coronavirus replicon RNA containing a heterologous sequence and packaging signal but lacking a structural protein gene; and 3) a separate helper RNA encoding the missing structural protein. When these components are expressed in the cell, coronavirus particles are assembled that contain the heterologous RNA sequence but cannot replicate without the helper RNA. The patent claims compositions and methods for making and using these viral particles to deliver heterologous genes.
CORONAVIRUS AKA SARS PATENT
This patent document describes the isolation and characterization of a novel human coronavirus (SARS-CoV) that is the causative agent of severe acute respiratory syndrome (SARS). It provides the nucleic acid sequence of the SARS-CoV genome and the amino acid sequences of its open reading frames. Methods are described for using these molecules to detect SARS-CoV and detect infections. Immune stimulatory compositions are also provided, along with methods for their use.
Genetic engineering
This document discusses genetic engineering techniques such as selective breeding, recombinant DNA, polymerase chain reaction (PCR), gel electrophoresis, and transgenic organisms. Recombinant DNA allows combining DNA from different organisms and was first used in the 1970s with bacteria. Genetically modified plants and animals are created through insertion of foreign DNA and have applications such as producing human proteins and increasing disease resistance. PCR and gel electrophoresis are techniques used to analyze and identify DNA.
113 phillip d. zamore - 7691995 - in vivo production of small interfering r...
Phillip D. Zamore, Juanita McLachlan, Gyorgy Hutvagner, Alla Grishok, Craig C. Mello - In Vivo Production of Small Interfering RN's that Mediate Gene Silencing
Genetic engineering
Genetic engineering involves transferring DNA between organisms. It uses recombinant DNA techniques where the gene of interest is isolated and inserted into a vector like a plasmid or virus, which is then used to introduce the gene into a host cell. This allows the production of useful proteins like insulin through genetically modified bacteria. While genetic engineering has benefits like producing important medicines, there are also potential health and environmental risks to consider.
Genetic engineering- Vincent
Genetic engineering is the process of altering the genetic makeup of an organism using recombinant DNA technology. This involves inserting, altering, or removing genes using laboratory tools. The document discusses the history of genetic engineering, techniques used like Agrobacterium transformation and microprojectile bombardment, applications in developing transgenic crops, commercially available GE crops, and both advantages like higher yields and disadvantages like potential health risks. In conclusion, genetic engineering has benefits for agriculture but must be strictly controlled to manage potential negative effects.
Recommended
97 craig c. mello - 7282564 - rna interference pathway genes as tools for t...
Craig C. Mello, Andrew Fire, Hiroaki Tabara, Alla Grishok - RNA Interference Pathway Genes as Tools for Targeted Genetic Interference
Genetic engineering
Genetic engineering uses biotechnology to directly manipulate an organism's genes. The CRISPR-Cas9 system allows genes to be added, removed, or altered by using the Cas9 enzyme to cut DNA at a targeted location. CRISPR-Cas9 acts as a bacterial immune system and can now be programmed to edit genes in other organisms like crops, animals, and potentially humans. This technology could help end diseases by editing genes, create genetically modified crops with desired traits, and potentially lead to "designer babies" with selected genes. However, genetic engineering also raises ethical concerns and risks unpredictable consequences.
Us7279327 Methods for producing recombinant coronavirus
The document is a United States patent describing methods for producing recombinant coronavirus particles. Specifically, it describes developing a helper cell that contains: 1) a coronavirus permissive cell; 2) a coronavirus replicon RNA containing a heterologous sequence and packaging signal but lacking a structural protein gene; and 3) a separate helper RNA encoding the missing structural protein. When these components are expressed in the cell, coronavirus particles are assembled that contain the heterologous RNA sequence but cannot replicate without the helper RNA. The patent claims compositions and methods for making and using these viral particles to deliver heterologous genes.
CORONAVIRUS AKA SARS PATENT
This patent document describes the isolation and characterization of a novel human coronavirus (SARS-CoV) that is the causative agent of severe acute respiratory syndrome (SARS). It provides the nucleic acid sequence of the SARS-CoV genome and the amino acid sequences of its open reading frames. Methods are described for using these molecules to detect SARS-CoV and detect infections. Immune stimulatory compositions are also provided, along with methods for their use.
Genetic engineering
This document discusses genetic engineering techniques such as selective breeding, recombinant DNA, polymerase chain reaction (PCR), gel electrophoresis, and transgenic organisms. Recombinant DNA allows combining DNA from different organisms and was first used in the 1970s with bacteria. Genetically modified plants and animals are created through insertion of foreign DNA and have applications such as producing human proteins and increasing disease resistance. PCR and gel electrophoresis are techniques used to analyze and identify DNA.
113 phillip d. zamore - 7691995 - in vivo production of small interfering r...
Phillip D. Zamore, Juanita McLachlan, Gyorgy Hutvagner, Alla Grishok, Craig C. Mello - In Vivo Production of Small Interfering RN's that Mediate Gene Silencing
Genetic engineering
Genetic engineering involves transferring DNA between organisms. It uses recombinant DNA techniques where the gene of interest is isolated and inserted into a vector like a plasmid or virus, which is then used to introduce the gene into a host cell. This allows the production of useful proteins like insulin through genetically modified bacteria. While genetic engineering has benefits like producing important medicines, there are also potential health and environmental risks to consider.
Genetic engineering- Vincent
Genetic engineering is the process of altering the genetic makeup of an organism using recombinant DNA technology. This involves inserting, altering, or removing genes using laboratory tools. The document discusses the history of genetic engineering, techniques used like Agrobacterium transformation and microprojectile bombardment, applications in developing transgenic crops, commercially available GE crops, and both advantages like higher yields and disadvantages like potential health risks. In conclusion, genetic engineering has benefits for agriculture but must be strictly controlled to manage potential negative effects.
4.4 genetic engineering & biotechnology
Polymerase chain reaction (PCR) is used to copy and amplify minute quantities of DNA without bacteria. In gel electrophoresis, DNA fragments move in an electric field and are separated by size, and this technique is used in DNA profiling to determine paternity or for forensic investigations. Genetic engineering techniques like PCR, gel electrophoresis, and DNA profiling have various applications and social implications.
Genetic engineering
Genetic engineering involves the direct manipulation of genes through techniques like gene cloning and transfer. Key tools include restriction enzymes, plasmids, and the creation of DNA libraries which allow genes to be identified and isolated. Techniques like PCR, gel electrophoresis, and blotting allow analysis and study of DNA, RNA, and proteins. Restriction mapping uses restriction enzymes to cut DNA into fragments which can then be used to identify genes and construct maps of DNA sequences.
Genetic engineering
Genetic engineering is a branch of molecular biology that allows manipulation of an organism's genome. Common practices include eliminating harmful genes, introducing healthy genes, and modifying genes. The process involves isolating the gene of interest using restriction enzymes, inserting the gene into a cloning vector like a bacterial plasmid, locating host cells containing the gene, and cloning those cells to produce the gene product. For example, the human insulin gene can be cloned into bacteria to produce insulin in large quantities at low cost for treatment of diabetes.
114 craig c. mello - 7759463 - rna interference pathway genes as tools for ...
Craig C. Mello, Hiroaki Tabara, Andrew Fire, Alla Grishok - RNA Interference Pathway Genes as Tools for Targeted Genetic Interference
DNA Technology 2 genetic engineering notes
This document provides an overview of genetic engineering and biotechnology concepts through a series of slides. It discusses how DNA from different organisms can be spliced together, and how genetic engineering involves manipulating genes. Examples are given of inserting select genes into organisms to improve traits or have them mass produce certain proteins. The document also summarizes gene cloning techniques like PCR and discusses applications of genetic engineering in medicine, agriculture, and animal science. Ethical considerations around topics like patenting life forms and conducting safety research are also briefly outlined.
Genetic Engineering and the future of Evolutiom
Genetic engineering will allow humans to direct their own evolution for the first time in history. By arranging the four bases of DNA - A, T, G, C - genetic instructions can be changed, altering organisms. CRISPR is a new, faster, cheaper, and more precise genetic engineering tool that can edit live cells and has reduced the cost of genetic engineering by 99%. If guided with caution, genetic engineering has the potential to cure diseases like HIV and cancer, extend human lifespans by borrowing genes from immortal species, and enhance humans for space travel by engineering plants and stronger bodies. However, there are also risks like the rise of "designer babies", dictators forcing genetic changes, and the creation of super soldiers
DNA Technology 2: Genetic Engineering
This document discusses genetic engineering and DNA technology. It explains that genetic engineering involves manipulating DNA, such as splicing genes from one organism into another. This allows genes to be mass produced using bacteria or inserted into organisms to improve their traits. Examples are given of inserting human genes into bacteria to produce insulin or "glowing" plants created with bioluminescent genes. Concerns discussed include the debate over GMOs in food, ownership of patented life forms, and long term effects on human health and the environment.
In Vitro Diagnostic (IVD) Antibody Development - Creative Biolabs
This slide is a brief introduction of in vitro diagnostic (IVD) antibody development. This presentation includes the introduction of background, principle and process of antibody development, difficulties in antibody development, as well as the antibody services of Creative Biolabs.
Genetic engineering and biotechnology 2016
This document discusses genetic engineering and biotechnology. It begins by defining genetic engineering as the manipulation of genes, usually outside an organism's natural reproductive process. It then discusses chromosomes and mutations, including examples of chromosome numbers in different species. Techniques for genetic engineering are explained, such as restriction enzymes and bacterial transformation. Applications include creating transgenic bacteria, plants, and animals. Ethical issues related to genetic engineering are also reviewed.
4.4 Biotechnology And Genetic Engineering
This document outlines topics related to genetics and genetic engineering, including:
1. Using PCR and gel electrophoresis to analyze and separate DNA fragments.
2. Techniques for genetic engineering like using plasmids, restriction enzymes, and DNA ligase to transfer genes between organisms.
3. Examples of genetically modified crops and animals, and potential benefits and risks of genetic modification.
Genetic engineering
Genetic engineering involves manipulating the structure of genes to create desired characteristics in an organism. It can involve adding genetic material from another species to create a transgenic organism, or removing genetic material to create a knockout organism. Some key events in the history of genetic engineering include the coining of the term in 1941, the discovery of DNA's double helix structure in 1953, and the first genetically engineered plants in 1986. The process involves taking a gene of interest from one cell and inserting it into the DNA of a host cell to create recombinant DNA that can be multiplied. Genetic engineering provides benefits like creating medicines, improving agriculture, and DNA profiling. Examples include using it to create disease-resistant plants, make insulin, and clone Dolly
Genetic Engineering: Chapter 1- History of Genetic Engineering
This document provides a history of genetic engineering. It discusses how genetic engineering began with selective breeding of plants and animals in prehistoric times. The modern field of genetic engineering began in 1973 when Herbert Boyer and Stanley Cohen accomplished the direct transfer of DNA between organisms. Since then, major breakthroughs included the discovery of restriction enzymes in 1969, the first recombinant DNA molecule in 1972, DNA sequencing in 1977, and PCR in 1983. Genetically modified foods and medicines have been commercialized since 1976. The latest developments include gene editing technologies and clinical applications of modified cells.
genetic engineering
Genetic engineering can help address problems like food shortages by developing crops resistant to threats. The Philippines faces a rice shortage due to black bug infestation. A company has developed weevil-resistant corn through genetic engineering that could help if planted there. However, genetic engineering also presents risks that must be considered, like potential health or environmental impacts, before pursuing this solution. Experts would need to evaluate what traits were modified in the corn, the benefits and risks of genetic engineering, and whether the benefits outweigh the risks.
64 andrew fire - 6506559 - genetic inhibition by double-stranded rna
Andrew Fire, Stephen Kostas, Mary Montgomery, Lisa Timmons, SiQun Xu, Hiroaki Tabara, Samuel E. Driver, Craig C. Mello - Genetic Inhibition by Double-Stranded RNA
Genetic Engineering
Genetic engineering involves deliberately manipulating an organism's genes to produce a desired trait. It is done by transferring genes between organisms, such as inserting a gene from one species into a plasmid and introducing that plasmid into a host cell. Genetically modified foods have been produced since the 1990s and include soybeans, corn, canola, and tomatoes. While GM foods aim to create crops with advantages like pest resistance and increased yields, some argue they pose environmental and health risks.
Viral vectors in virology
definition,converting a virus into a vector,main types og viral vectors,principle of retroviral gene transfer,
Singapore grouper iridovirus induced parapoptosis-like death in host cells vi...
Singapore grouper iridovirus (SGIV) induces a type of programmed cell death called parapotosis in host cells. This document summarizes research finding that SGIV activates mitogen-activated protein kinase (MAPK) signaling pathways, including ERK, JNK, and p38 MAPK, to induce parapotosis and facilitate viral replication. Inhibition of the ERK and JNK pathways can delay cytopathic effects and reduce virus production, indicating their role in the viral life cycle. JNK activation in particular promotes viral transcription and protein synthesis. MAPK signaling also modulates the expression of immune genes during infection. Therefore, SGIV utilizes MAPK pathways to induce parapotosis in host cells and
Genetic engineering
genetic engineering: Genetic engineering, also called genetic modification, is the direct manipulation of an organism's genome using biotechnology. It is a set of technologies used to change the genetic makeup of cells, including the transfer of genes within and across species boundaries to produce improved or novel organisms. Many organism are manipulated with the help genetic engineering useful for mankind.
Importance of microbes in genetic engineering
you can gain a good knowledge about importance of microorganisms in genetic engineering and their application.
Biotechnology and1 genetic engineering
Biotechnology and genetic engineering involve manipulating organisms or their genes. Key techniques include classical biotechnology methods like selection and hybridization, as well as molecular biotechnology techniques like gene transfer and recombinant DNA technology. Some applications of biotechnology include producing therapeutic proteins by inserting genes into bacteria, DNA fingerprinting to identify individuals, and gene therapy to treat genetic disorders. However, genetic engineering is also controversial due to potential dangers and its opposition in some parts of the world.
More Related Content
What's hot
4.4 genetic engineering & biotechnology
Polymerase chain reaction (PCR) is used to copy and amplify minute quantities of DNA without bacteria. In gel electrophoresis, DNA fragments move in an electric field and are separated by size, and this technique is used in DNA profiling to determine paternity or for forensic investigations. Genetic engineering techniques like PCR, gel electrophoresis, and DNA profiling have various applications and social implications.
Genetic engineering
Genetic engineering involves the direct manipulation of genes through techniques like gene cloning and transfer. Key tools include restriction enzymes, plasmids, and the creation of DNA libraries which allow genes to be identified and isolated. Techniques like PCR, gel electrophoresis, and blotting allow analysis and study of DNA, RNA, and proteins. Restriction mapping uses restriction enzymes to cut DNA into fragments which can then be used to identify genes and construct maps of DNA sequences.
Genetic engineering
Genetic engineering is a branch of molecular biology that allows manipulation of an organism's genome. Common practices include eliminating harmful genes, introducing healthy genes, and modifying genes. The process involves isolating the gene of interest using restriction enzymes, inserting the gene into a cloning vector like a bacterial plasmid, locating host cells containing the gene, and cloning those cells to produce the gene product. For example, the human insulin gene can be cloned into bacteria to produce insulin in large quantities at low cost for treatment of diabetes.
114 craig c. mello - 7759463 - rna interference pathway genes as tools for ...
Craig C. Mello, Hiroaki Tabara, Andrew Fire, Alla Grishok - RNA Interference Pathway Genes as Tools for Targeted Genetic Interference
DNA Technology 2 genetic engineering notes
This document provides an overview of genetic engineering and biotechnology concepts through a series of slides. It discusses how DNA from different organisms can be spliced together, and how genetic engineering involves manipulating genes. Examples are given of inserting select genes into organisms to improve traits or have them mass produce certain proteins. The document also summarizes gene cloning techniques like PCR and discusses applications of genetic engineering in medicine, agriculture, and animal science. Ethical considerations around topics like patenting life forms and conducting safety research are also briefly outlined.
Genetic Engineering and the future of Evolutiom
Genetic engineering will allow humans to direct their own evolution for the first time in history. By arranging the four bases of DNA - A, T, G, C - genetic instructions can be changed, altering organisms. CRISPR is a new, faster, cheaper, and more precise genetic engineering tool that can edit live cells and has reduced the cost of genetic engineering by 99%. If guided with caution, genetic engineering has the potential to cure diseases like HIV and cancer, extend human lifespans by borrowing genes from immortal species, and enhance humans for space travel by engineering plants and stronger bodies. However, there are also risks like the rise of "designer babies", dictators forcing genetic changes, and the creation of super soldiers
DNA Technology 2: Genetic Engineering
This document discusses genetic engineering and DNA technology. It explains that genetic engineering involves manipulating DNA, such as splicing genes from one organism into another. This allows genes to be mass produced using bacteria or inserted into organisms to improve their traits. Examples are given of inserting human genes into bacteria to produce insulin or "glowing" plants created with bioluminescent genes. Concerns discussed include the debate over GMOs in food, ownership of patented life forms, and long term effects on human health and the environment.
In Vitro Diagnostic (IVD) Antibody Development - Creative Biolabs
This slide is a brief introduction of in vitro diagnostic (IVD) antibody development. This presentation includes the introduction of background, principle and process of antibody development, difficulties in antibody development, as well as the antibody services of Creative Biolabs.
Genetic engineering and biotechnology 2016
This document discusses genetic engineering and biotechnology. It begins by defining genetic engineering as the manipulation of genes, usually outside an organism's natural reproductive process. It then discusses chromosomes and mutations, including examples of chromosome numbers in different species. Techniques for genetic engineering are explained, such as restriction enzymes and bacterial transformation. Applications include creating transgenic bacteria, plants, and animals. Ethical issues related to genetic engineering are also reviewed.
4.4 Biotechnology And Genetic Engineering
This document outlines topics related to genetics and genetic engineering, including:
1. Using PCR and gel electrophoresis to analyze and separate DNA fragments.
2. Techniques for genetic engineering like using plasmids, restriction enzymes, and DNA ligase to transfer genes between organisms.
3. Examples of genetically modified crops and animals, and potential benefits and risks of genetic modification.
Genetic engineering
Genetic engineering involves manipulating the structure of genes to create desired characteristics in an organism. It can involve adding genetic material from another species to create a transgenic organism, or removing genetic material to create a knockout organism. Some key events in the history of genetic engineering include the coining of the term in 1941, the discovery of DNA's double helix structure in 1953, and the first genetically engineered plants in 1986. The process involves taking a gene of interest from one cell and inserting it into the DNA of a host cell to create recombinant DNA that can be multiplied. Genetic engineering provides benefits like creating medicines, improving agriculture, and DNA profiling. Examples include using it to create disease-resistant plants, make insulin, and clone Dolly
Genetic Engineering: Chapter 1- History of Genetic Engineering
This document provides a history of genetic engineering. It discusses how genetic engineering began with selective breeding of plants and animals in prehistoric times. The modern field of genetic engineering began in 1973 when Herbert Boyer and Stanley Cohen accomplished the direct transfer of DNA between organisms. Since then, major breakthroughs included the discovery of restriction enzymes in 1969, the first recombinant DNA molecule in 1972, DNA sequencing in 1977, and PCR in 1983. Genetically modified foods and medicines have been commercialized since 1976. The latest developments include gene editing technologies and clinical applications of modified cells.
genetic engineering
Genetic engineering can help address problems like food shortages by developing crops resistant to threats. The Philippines faces a rice shortage due to black bug infestation. A company has developed weevil-resistant corn through genetic engineering that could help if planted there. However, genetic engineering also presents risks that must be considered, like potential health or environmental impacts, before pursuing this solution. Experts would need to evaluate what traits were modified in the corn, the benefits and risks of genetic engineering, and whether the benefits outweigh the risks.
64 andrew fire - 6506559 - genetic inhibition by double-stranded rna
Andrew Fire, Stephen Kostas, Mary Montgomery, Lisa Timmons, SiQun Xu, Hiroaki Tabara, Samuel E. Driver, Craig C. Mello - Genetic Inhibition by Double-Stranded RNA
Genetic Engineering
Genetic engineering involves deliberately manipulating an organism's genes to produce a desired trait. It is done by transferring genes between organisms, such as inserting a gene from one species into a plasmid and introducing that plasmid into a host cell. Genetically modified foods have been produced since the 1990s and include soybeans, corn, canola, and tomatoes. While GM foods aim to create crops with advantages like pest resistance and increased yields, some argue they pose environmental and health risks.
Viral vectors in virology
definition,converting a virus into a vector,main types og viral vectors,principle of retroviral gene transfer,
Singapore grouper iridovirus induced parapoptosis-like death in host cells vi...
Singapore grouper iridovirus (SGIV) induces a type of programmed cell death called parapotosis in host cells. This document summarizes research finding that SGIV activates mitogen-activated protein kinase (MAPK) signaling pathways, including ERK, JNK, and p38 MAPK, to induce parapotosis and facilitate viral replication. Inhibition of the ERK and JNK pathways can delay cytopathic effects and reduce virus production, indicating their role in the viral life cycle. JNK activation in particular promotes viral transcription and protein synthesis. MAPK signaling also modulates the expression of immune genes during infection. Therefore, SGIV utilizes MAPK pathways to induce parapotosis in host cells and
Genetic engineering
genetic engineering: Genetic engineering, also called genetic modification, is the direct manipulation of an organism's genome using biotechnology. It is a set of technologies used to change the genetic makeup of cells, including the transfer of genes within and across species boundaries to produce improved or novel organisms. Many organism are manipulated with the help genetic engineering useful for mankind.
Importance of microbes in genetic engineering
you can gain a good knowledge about importance of microorganisms in genetic engineering and their application.
Biotechnology and1 genetic engineering
Biotechnology and genetic engineering involve manipulating organisms or their genes. Key techniques include classical biotechnology methods like selection and hybridization, as well as molecular biotechnology techniques like gene transfer and recombinant DNA technology. Some applications of biotechnology include producing therapeutic proteins by inserting genes into bacteria, DNA fingerprinting to identify individuals, and gene therapy to treat genetic disorders. However, genetic engineering is also controversial due to potential dangers and its opposition in some parts of the world.
What's hot (20)
114 craig c. mello - 7759463 - rna interference pathway genes as tools for ...
114 craig c. mello - 7759463 - rna interference pathway genes as tools for ...
In Vitro Diagnostic (IVD) Antibody Development - Creative Biolabs
In Vitro Diagnostic (IVD) Antibody Development - Creative Biolabs
Genetic Engineering: Chapter 1- History of Genetic Engineering
Genetic Engineering: Chapter 1- History of Genetic Engineering
64 andrew fire - 6506559 - genetic inhibition by double-stranded rna
64 andrew fire - 6506559 - genetic inhibition by double-stranded rna
Singapore grouper iridovirus induced parapoptosis-like death in host cells vi...
Singapore grouper iridovirus induced parapoptosis-like death in host cells vi...
Viewers also liked
Schema.org extension for biological database @ Biohackathon2013
Schema.org extension for biological database and database entry. It will make database developers happy in the future.
Microformats, RDFa, and schema.org for Food Bloggers - BlogWorld Expo LA
The document discusses the importance of using microformats or schema.org for food bloggers to help search engines and other programs better understand recipe pages. It recommends including key metadata like title, photos, prep/cook times, calories, and reviews. Plugins are available for WordPress to easily add these microformats or schema.org tags to recipes. While computers still cannot understand context like humans, using these standards helps make recipe pages more accessible.
TechM GIS Telecom
This document discusses how maps and geographic information systems (GIS) have evolved with technology. Maps are now dynamic and adapt as the world changes. GIS has become relevant to analyzing most data due to its geographic component. Tech Mahindra offers GIS services and solutions, including for network planning, engineering, and customer service for telecom companies. They provide experienced GIS consultants and have implemented solutions for clients around the world.
Viewers also liked (6)
Schema.org extension for biological database @ Biohackathon2013
Schema.org extension for biological database @ Biohackathon2013
Microformats, RDFa, and schema.org for Food Bloggers - BlogWorld Expo LA
Microformats, RDFa, and schema.org for Food Bloggers - BlogWorld Expo LA
More from Maori Ito
Presentation forpd bj_1
This presentation discusses ways to improve biomedical database search services through the use of semantic web technologies like schema.org and metadata tagging. It explains how marking up database entries with metadata and declaring vocabularies allows search engines to better understand and return more informative results for biomedical queries. The presentation provides examples of how Sagace and other search collaboration organizations are already reflecting semantic metadata in their results.
Bh13.13 sagace 1
国内版バイオハッカソン BH13.13 - http://wiki.lifesciencedb.jp/mw/index.php/BH13.13
内で発表した資料(抜粋)です。
Cross search and_semantic_web_mbsj2013
第36回日本分子生物学会年会のワークショップ"データベースを使い倒した新しい研究スタイルによる分子生物学"での発表資料を公開します。
The Progress on Sagace and Data Integration
This slide explains the progress of Sagace ( cross search engine for for Biomedical Data & Resources in Japan) and data integration by using RDF.
More from Maori Ito (20)
Recently uploaded
DSSML24_tspann_CodelessGenerativeAIPipelines
Codeless Generative AI Pipelines
(GenAI with Milvus)
https://ml.dssconf.pl/user.html#!/lecture/DSSML24-041a/rate
Discover the potential of real-time streaming in the context of GenAI as we delve into the intricacies of Apache NiFi and its capabilities. Learn how this tool can significantly simplify the data engineering workflow for GenAI applications, allowing you to focus on the creative aspects rather than the technical complexities. I will guide you through practical examples and use cases, showing the impact of automation on prompt building. From data ingestion to transformation and delivery, witness how Apache NiFi streamlines the entire pipeline, ensuring a smooth and hassle-free experience.
Timothy Spann
https://www.youtube.com/@FLaNK-Stack
https://medium.com/@tspann
https://www.datainmotion.dev/
milvus, unstructured data, vector database, zilliz, cloud, vectors, python, deep learning, generative ai, genai, nifi, kafka, flink, streaming, iot, edge
End-to-end pipeline agility - Berlin Buzzwords 2024
We describe how we achieve high change agility in data engineering by eliminating the fear of breaking downstream data pipelines through end-to-end pipeline testing, and by using schema metaprogramming to safely eliminate boilerplate involved in changes that affect whole pipelines.
A quick poll on agility in changing pipelines from end to end indicated a huge span in capabilities. For the question "How long time does it take for all downstream pipelines to be adapted to an upstream change," the median response was 6 months, but some respondents could do it in less than a day. When quantitative data engineering differences between the best and worst are measured, the span is often 100x-1000x, sometimes even more.
A long time ago, we suffered at Spotify from fear of changing pipelines due to not knowing what the impact might be downstream. We made plans for a technical solution to test pipelines end-to-end to mitigate that fear, but the effort failed for cultural reasons. We eventually solved this challenge, but in a different context. In this presentation we will describe how we test full pipelines effectively by manipulating workflow orchestration, which enables us to make changes in pipelines without fear of breaking downstream.
Making schema changes that affect many jobs also involves a lot of toil and boilerplate. Using schema-on-read mitigates some of it, but has drawbacks since it makes it more difficult to detect errors early. We will describe how we have rejected this tradeoff by applying schema metaprogramming, eliminating boilerplate but keeping the protection of static typing, thereby further improving agility to quickly modify data pipelines without fear.
一比一原版英国赫特福德大学毕业证(hertfordshire毕业证书)如何办理
原版一模一样【微信:741003700 】【英国赫特福德大学毕业证(hertfordshire毕业证书)成绩单】【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
办理英国赫特福德大学毕业证(hertfordshire毕业证书)【微信:741003700 】外观非常简单,由纸质材料制成,上面印有校徽、校名、毕业生姓名、专业等信息。
办理英国赫特福德大学毕业证(hertfordshire毕业证书)【微信:741003700 】格式相对统一,各专业都有相应的模板。通常包括以下部分:
校徽:象征着学校的荣誉和传承。
校名:学校英文全称
授予学位:本部分将注明获得的具体学位名称。
毕业生姓名:这是最重要的信息之一,标志着该证书是由特定人员获得的。
颁发日期:这是毕业正式生效的时间,也代表着毕业生学业的结束。
其他信息:根据不同的专业和学位,可能会有一些特定的信息或章节。
办理英国赫特福德大学毕业证(hertfordshire毕业证书)【微信:741003700 】价值很高,需要妥善保管。一般来说,应放置在安全、干燥、防潮的地方,避免长时间暴露在阳光下。如需使用,最好使用复印件而不是原件,以免丢失。
综上所述,办理英国赫特福德大学毕业证(hertfordshire毕业证书)【微信:741003700 】是证明身份和学历的高价值文件。外观简单庄重,格式统一,包括重要的个人信息和发布日期。对持有人来说,妥善保管是非常重要的。
一比一原版爱尔兰都柏林大学毕业证(本硕)ucd学位证书如何办理
原版一模一样【微信:741003700 】【爱尔兰都柏林大学毕业证(本硕)ucd成绩单】【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
办理爱尔兰都柏林大学毕业证(本硕)ucd学位证书【微信:741003700 】外观非常简单,由纸质材料制成,上面印有校徽、校名、毕业生姓名、专业等信息。
办理爱尔兰都柏林大学毕业证(本硕)ucd学位证书【微信:741003700 】格式相对统一,各专业都有相应的模板。通常包括以下部分:
校徽:象征着学校的荣誉和传承。
校名:学校英文全称
授予学位:本部分将注明获得的具体学位名称。
毕业生姓名:这是最重要的信息之一,标志着该证书是由特定人员获得的。
颁发日期:这是毕业正式生效的时间,也代表着毕业生学业的结束。
其他信息:根据不同的专业和学位,可能会有一些特定的信息或章节。
办理爱尔兰都柏林大学毕业证(本硕)ucd学位证书【微信:741003700 】价值很高,需要妥善保管。一般来说,应放置在安全、干燥、防潮的地方,避免长时间暴露在阳光下。如需使用,最好使用复印件而不是原件,以免丢失。
综上所述,办理爱尔兰都柏林大学毕业证(本硕)ucd学位证书【微信:741003700 】是证明身份和学历的高价值文件。外观简单庄重,格式统一,包括重要的个人信息和发布日期。对持有人来说,妥善保管是非常重要的。
Open Source Contributions to Postgres: The Basics POSETTE 2024
Postgres is the most advanced open-source database in the world and it's supported by a community, not a single company. So how does this work? How does code actually get into Postgres? I recently had a patch submitted and committed and I want to share what I learned in that process. I’ll give you an overview of Postgres versions and how the underlying project codebase functions. I’ll also show you the process for submitting a patch and getting that tested and committed.
UofT毕业证如何办理
原件一模一样【微信:95270640】【多伦多大学毕业证UofT学位证成绩单】【微信:95270640】(留信学历认证永久存档查询)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信:95270640】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信:95270640】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份【微信:95270640】
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
→ 【关于价格问题(保证一手价格)
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:可来公司面谈,可签订合同,会陪同客户一起到教育部认证窗口递交认证材料,客户在教育部官方认证查询网站查询到认证通过结果后付款,不成功不收费!
办理多伦多大学毕业证硕士毕业证成绩单UofT学位证【微信:95270640 】外观非常精致,由特殊纸质材料制成,上面印有校徽、校名、毕业生姓名、专业等信息。
办理多伦多大学毕业证UofT学位证硕士毕业证成绩单【微信:95270640 】格式相对统一,各专业都有相应的模板。通常包括以下部分:
校徽:象征着学校的荣誉和传承。
校名:学校英文全称
授予学位:本部分将注明获得的具体学位名称。
毕业生姓名:这是最重要的信息之一,标志着该证书是由特定人员获得的。
颁发日期:这是毕业正式生效的时间,也代表着毕业生学业的结束。
其他信息:根据不同的专业和学位,可能会有一些特定的信息或章节。
办理多伦多大学毕业证硕士毕业证成绩单UofT学位证【微信:95270640 】价值很高,需要妥善保管。一般来说,应放置在安全、干燥、防潮的地方,避免长时间暴露在阳光下。如需使用,最好使用复印件而不是原件,以免丢失。
综上所述,办理多伦多大学毕业证硕士毕业证成绩单UofT学位证【微信:95270640 】是证明身份和学历的高价值文件。外观简单庄重,格式统一,包括重要的个人信息和发布日期。对持有人来说,妥善保管是非常重要的。
[VCOSA] Monthly Report - Cotton & Yarn Statistics March 2024
We are pleased to share with you the latest VCOSA statistical report on the cotton and yarn industry for the month of March 2024.
Starting from January 2024, the full weekly and monthly reports will only be available for free to VCOSA members. To access the complete weekly report with figures, charts, and detailed analysis of the cotton fiber market in the past week, interested parties are kindly requested to contact VCOSA to subscribe to the newsletter.
University of New South Wales degree offer diploma Transcript
澳洲UNSW毕业证书制作新南威尔士大学假文凭定制Q微168899991做UNSW留信网教留服认证海牙认证改UNSW成绩单GPA做UNSW假学位证假文凭高仿毕业证申请新南威尔士大学University of New South Wales degree offer diploma Transcript
一比一原版英属哥伦比亚大学毕业证(UBC毕业证书)学历如何办理
原版办【微信号:BYZS866】【英属哥伦比亚大学毕业证(UBC毕业证书)】【微信号:BYZS866】《成绩单、外壳、雅思、offer、真实留信官方学历认证(永久存档/真实可查)》采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路)我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信号BYZS866】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信号BYZS866】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
一比一原版(UCSB文凭证书)圣芭芭拉分校毕业证如何办理
毕业原版【微信:176555708】【(UCSB毕业证书)圣芭芭拉分校毕业证】【微信:176555708】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信176555708】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信176555708】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
一比一原版(GWU,GW文凭证书)乔治·华盛顿大学毕业证如何办理
毕业原版【微信:176555708】【(GWU,GW毕业证书)乔治·华盛顿大学毕业证】【微信:176555708】成绩单、外壳、offer、留信学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路),我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信176555708】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信176555708】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
→ 【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
一比一原版(harvard毕业证书)哈佛大学毕业证如何办理
一模一样【微信:A575476】【(harvard毕业证书)哈佛大学毕业证成绩单Offer】【微信:A575476】(留信学历认证永久存档查询)采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信:A575476】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信:A575476】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
→ 【关于价格问题(保证一手价格)
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:可来公司面谈,可签订合同,会陪同客户一起到教育部认证窗口递交认证材料,客户在教育部官方认证查询网站查询到认证通过结果后付款,不成功不收费!
一比一原版南十字星大学毕业证(SCU毕业证书)学历如何办理
原版办理【微信号:BYZS866】【南十字星大学毕业证(SCU毕业证书)】【微信号:BYZS866】《成绩单、外壳、雅思、offer、真实留信官方学历认证(永久存档/真实可查)》采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路)我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信号BYZS866】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信号BYZS866】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
原版一比一爱尔兰都柏林大学毕业证(UCD毕业证书)如何办理
原版制作【微信:41543339】【爱尔兰都柏林大学毕业证(UCD毕业证书)】【微信:41543339】《成绩单、外壳、雅思、offer、真实留信官方学历认证(永久存档/真实可查)》采用学校原版纸张、特殊工艺完全按照原版一比一制作(包括:隐形水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠,文字图案浮雕,激光镭射,紫外荧光,温感,复印防伪)行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备,十五年致力于帮助留学生解决难题,业务范围有加拿大、英国、澳洲、韩国、美国、新加坡,新西兰等学历材料,包您满意。
【我们承诺采用的是学校原版纸张(纸质、底色、纹路)我们拥有全套进口原装设备,特殊工艺都是采用不同机器制作,仿真度基本可以达到100%,所有工艺效果都可提前给客户展示,不满意可以根据客户要求进行调整,直到满意为止!】
【业务选择办理准则】
一、工作未确定,回国需先给父母、亲戚朋友看下文凭的情况,办理一份就读学校的毕业证【微信41543339】文凭即可
二、回国进私企、外企、自己做生意的情况,这些单位是不查询毕业证真伪的,而且国内没有渠道去查询国外文凭的真假,也不需要提供真实教育部认证。鉴于此,办理一份毕业证【微信41543339】即可
三、进国企,银行,事业单位,考公务员等等,这些单位是必需要提供真实教育部认证的,办理教育部认证所需资料众多且烦琐,所有材料您都必须提供原件,我们凭借丰富的经验,快捷的绿色通道帮您快速整合材料,让您少走弯路。
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
留信网服务项目:
1、留学生专业人才库服务(留信分析)
2、国(境)学习人员提供就业推荐信服务
3、留学人员区块链存储服务
【关于价格问题(保证一手价格)】
我们所定的价格是非常合理的,而且我们现在做得单子大多数都是代理和回头客户介绍的所以一般现在有新的单子 我给客户的都是第一手的代理价格,因为我想坦诚对待大家 不想跟大家在价格方面浪费时间
对于老客户或者被老客户介绍过来的朋友,我们都会适当给一些优惠。
选择实体注册公司办理,更放心,更安全!我们的承诺:客户在留信官方认证查询网站查询到认证通过结果后付款,不成功不收费!
在线办理(英国UCA毕业证书)创意艺术大学毕业证在读证明一模一样
学校原件一模一样【微信:741003700 】《(英国UCA毕业证书)创意艺术大学毕业证》【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
Orchestrating the Future: Navigating Today's Data Workflow Challenges with Ai...
Navigating today's data landscape isn't just about managing workflows; it's about strategically propelling your business forward. Apache Airflow has stood out as the benchmark in this arena, driving data orchestration forward since its early days. As we dive into the complexities of our current data-rich environment, where the sheer volume of information and its timely, accurate processing are crucial for AI and ML applications, the role of Airflow has never been more critical.
In my journey as the Senior Engineering Director and a pivotal member of Apache Airflow's Project Management Committee (PMC), I've witnessed Airflow transform data handling, making agility and insight the norm in an ever-evolving digital space. At Astronomer, our collaboration with leading AI & ML teams worldwide has not only tested but also proven Airflow's mettle in delivering data reliably and efficiently—data that now powers not just insights but core business functions.
This session is a deep dive into the essence of Airflow's success. We'll trace its evolution from a budding project to the backbone of data orchestration it is today, constantly adapting to meet the next wave of data challenges, including those brought on by Generative AI. It's this forward-thinking adaptability that keeps Airflow at the forefront of innovation, ready for whatever comes next.
The ever-growing demands of AI and ML applications have ushered in an era where sophisticated data management isn't a luxury—it's a necessity. Airflow's innate flexibility and scalability are what makes it indispensable in managing the intricate workflows of today, especially those involving Large Language Models (LLMs).
This talk isn't just a rundown of Airflow's features; it's about harnessing these capabilities to turn your data workflows into a strategic asset. Together, we'll explore how Airflow remains at the cutting edge of data orchestration, ensuring your organization is not just keeping pace but setting the pace in a data-driven future.
Session in https://budapestdata.hu/2024/04/kaxil-naik-astronomer-io/ | https://dataml24.sessionize.com/session/667627
Predictably Improve Your B2B Tech Company's Performance by Leveraging Data
Harness the power of AI-backed reports, benchmarking and data analysis to predict trends and detect anomalies in your marketing efforts.
Peter Caputa, CEO at Databox, reveals how you can discover the strategies and tools to increase your growth rate (and margins!).
From metrics to track to data habits to pick up, enhance your reporting for powerful insights to improve your B2B tech company's marketing.
- - -
This is the webinar recording from the June 2024 HubSpot User Group (HUG) for B2B Technology USA.
Watch the video recording at https://youtu.be/5vjwGfPN9lw
Sign up for future HUG events at https://events.hubspot.com/b2b-technology-usa/
一比一原版(lbs毕业证书)伦敦商学院毕业证如何办理
原版一模一样【微信:741003700 】【(lbs毕业证书)伦敦商学院毕业证成绩单】【微信:741003700 】学位证,留信认证(真实可查,永久存档)原件一模一样纸张工艺/offer、雅思、外壳等材料/诚信可靠,可直接看成品样本,帮您解决无法毕业带来的各种难题!外壳,原版制作,诚信可靠,可直接看成品样本。行业标杆!精益求精,诚心合作,真诚制作!多年品质 ,按需精细制作,24小时接单,全套进口原装设备。十五年致力于帮助留学生解决难题,包您满意。
本公司拥有海外各大学样板无数,能完美还原。
1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。材料咨询办理、认证咨询办理请加学历顾问Q/微741003700
【主营项目】
一.毕业证【q微741003700】成绩单、使馆认证、教育部认证、雅思托福成绩单、学生卡等!
二.真实使馆公证(即留学回国人员证明,不成功不收费)
三.真实教育部学历学位认证(教育部存档!教育部留服网站永久可查)
四.办理各国各大学文凭(一对一专业服务,可全程监控跟踪进度)
如果您处于以下几种情况:
◇在校期间,因各种原因未能顺利毕业……拿不到官方毕业证【q/微741003700】
◇面对父母的压力,希望尽快拿到;
◇不清楚认证流程以及材料该如何准备;
◇回国时间很长,忘记办理;
◇回国马上就要找工作,办给用人单位看;
◇企事业单位必须要求办理的
◇需要报考公务员、购买免税车、落转户口
◇申请留学生创业基金
留信网认证的作用:
1:该专业认证可证明留学生真实身份
2:同时对留学生所学专业登记给予评定
3:国家专业人才认证中心颁发入库证书
4:这个认证书并且可以归档倒地方
5:凡事获得留信网入网的信息将会逐步更新到个人身份内,将在公安局网内查询个人身份证信息后,同步读取人才网入库信息
6:个人职称评审加20分
7:个人信誉贷款加10分
8:在国家人才网主办的国家网络招聘大会中纳入资料,供国家高端企业选择人才
办理(lbs毕业证书)伦敦商学院毕业证【微信:741003700 】外观非常简单,由纸质材料制成,上面印有校徽、校名、毕业生姓名、专业等信息。
办理(lbs毕业证书)伦敦商学院毕业证【微信:741003700 】格式相对统一,各专业都有相应的模板。通常包括以下部分:
校徽:象征着学校的荣誉和传承。
校名:学校英文全称
授予学位:本部分将注明获得的具体学位名称。
毕业生姓名:这是最重要的信息之一,标志着该证书是由特定人员获得的。
颁发日期:这是毕业正式生效的时间,也代表着毕业生学业的结束。
其他信息:根据不同的专业和学位,可能会有一些特定的信息或章节。
办理(lbs毕业证书)伦敦商学院毕业证【微信:741003700 】价值很高,需要妥善保管。一般来说,应放置在安全、干燥、防潮的地方,避免长时间暴露在阳光下。如需使用,最好使用复印件而不是原件,以免丢失。
综上所述,办理(lbs毕业证书)伦敦商学院毕业证【微信:741003700 】是证明身份和学历的高价值文件。外观简单庄重,格式统一,包括重要的个人信息和发布日期。对持有人来说,妥善保管是非常重要的。
Recently uploaded (20)
End-to-end pipeline agility - Berlin Buzzwords 2024
End-to-end pipeline agility - Berlin Buzzwords 2024
Open Source Contributions to Postgres: The Basics POSETTE 2024
Open Source Contributions to Postgres: The Basics POSETTE 2024
[VCOSA] Monthly Report - Cotton & Yarn Statistics March 2024
[VCOSA] Monthly Report - Cotton & Yarn Statistics March 2024
University of New South Wales degree offer diploma Transcript
University of New South Wales degree offer diploma Transcript
Orchestrating the Future: Navigating Today's Data Workflow Challenges with Ai...
Orchestrating the Future: Navigating Today's Data Workflow Challenges with Ai...
Predictably Improve Your B2B Tech Company's Performance by Leveraging Data
Predictably Improve Your B2B Tech Company's Performance by Leveraging Data
Test slide for the lab - Target prioritization
- 1. Candidate gene prioritization >NSA2_HUMAN Ribosome biogenesis >APOB_HUMAN Apolipoprotein B-100 >CD99_HUMAN CD99 antigen >MAVS_HUMAN Mitochondrial antiviral >CA031_HUMAN Uncharacterized protein >CA043_HUMAN Uncharacterized protein >CA049_HUMAN Uncharacterized protein … Large-scale experiments A number of target candidates Stop development 1. Lack of annotations for individual genes 2. Difficulties in combining available information from different data sources This work by Kenji Mizuguchi is licensed under a Creative Commons Attribution 4.0 International License.
- 2. Gene 1 Gene 2 Gene 3 Gene 4 Gene 5 …. …. …. Gene 200 Gene 4 Gene 17 Gene 45 Gene 87 Integrated knowledge discovery INPUT OUTPUT Many candidates Selected targets This work by Kenji Mizuguchi is licensed under a Creative Commons Attribution 4.0 International License.