Downloaded 24 times







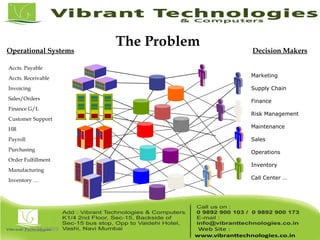
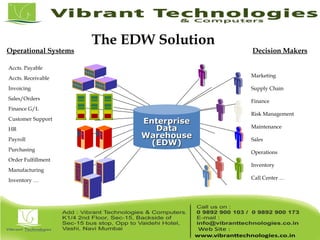
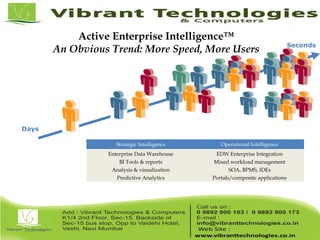
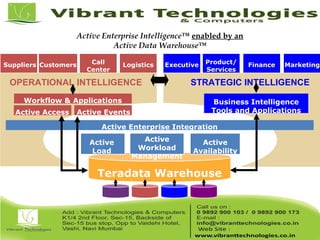




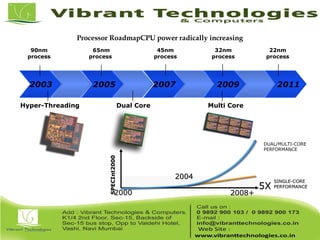

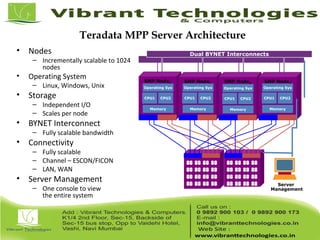

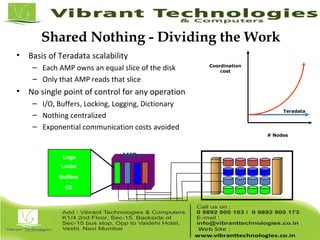
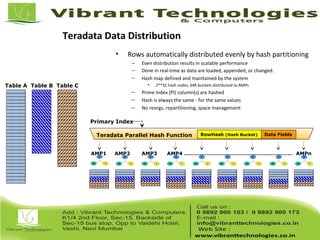
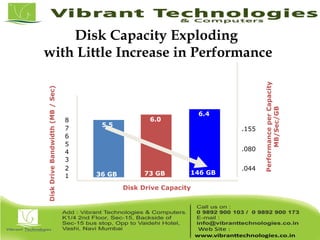



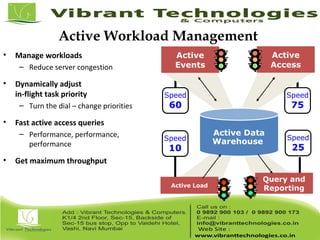
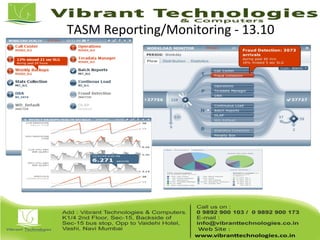
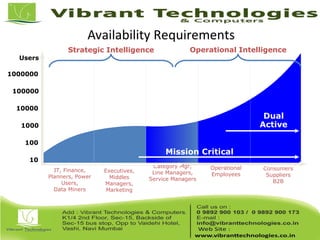





Teradata is a global leader in enterprise data warehousing, founded in 1979 and known for innovative data solutions and analytics. The company focuses on scalable architecture and workload management to handle massive data operations, achieving significant impacts in various sectors such as retail and finance. Teradata continues to evolve its technologies to meet the increasing demands of active enterprise intelligence, maintaining a strong presence in the market with a solid growth trajectory.