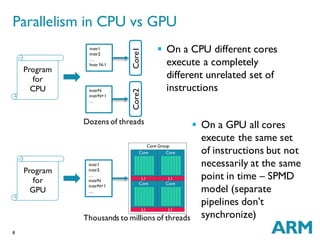
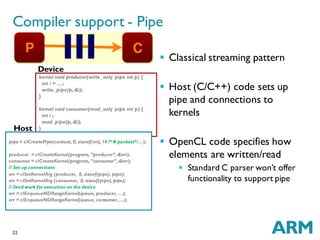
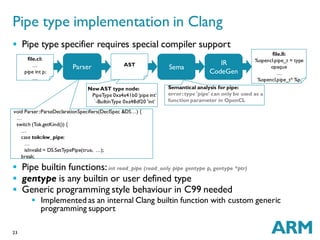
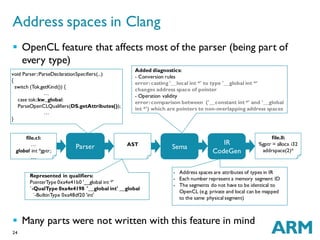
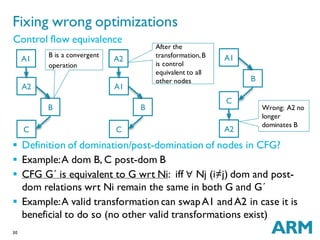
The document discusses challenges in GPU compilers. It begins with introductions and abbreviations. It then outlines the topics to be covered: a brief history of GPUs, what makes GPUs special, how to program GPUs, writing a GPU compiler including front-end, middle-end, and back-end aspects, and a few words about graphics. Key points are that GPUs are massively data-parallel, execute instructions in lockstep, and require supporting new language features like OpenCL as well as optimizing for and mapping to the GPU hardware architecture.







![7
Classical CPU pipeline
[DLX]
SIMD (vector) pipeline –
operates on closely located
data
SIMT pipeline with a bundle
of 4 threads
SPMD contains a
combination of
(SIMD&SIMT)
Types of data-level parallelism
MEMFE DE EX WB
MEMFE DE EX WB
EXEXEXMEM
EXEXEXEXFE DE
EXEXEXWB
Typically all are present in GPUs](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-7-320.jpg)


![11
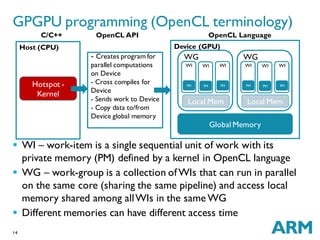
A bundle (subgroup in OpenCL) of threads has to execute the
same PC in lock step
All threads in the bundle have to go through instructions in
divergent branches (even when condition evaluates to false)
Similar to predicated execution
Inefficient because more time is spent to execute the whole program
Do all GPUs execute instructions in lock step? Mali-T6xx has
separate PC for each thread [IWOCL]
Lockstep execution (SIMT)
Divergence issue
if (thread_id==0)
r3 = r1+r2;
else
r3 = r1-r2;
r4 = r0 * r3
Thread 0 Thread 1 Thread 2 Thread 4
ADD r1 r2 ACTIVE INACTIVE INACTIVE INACTIVE
SUB r1 r2 INACTIVE ACTIVE ACTIVE ACTIVE
MUL r0 r3 ACTIVE ACTIVE ACTIVE ACTIVE
Bundle of 4 threads executing in lock step
Time
Each thread executes 3 instr instead of 2](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-11-320.jpg)

![15
kernel void foo(global int* buf){
int tid = get_global_id(0) *
get_global_size(1) +
get_global_id(1);
buf[tid] = cos(tid);
}
OpenCL program
Starting from C99
+ Keywords (specify kernels
i.e.parallel work items,
address spaces (AS) to allocate objects
to mem e.g.global,local,private …)
+ Builtin functions and types
- Disallowed features
(function pointers,recursion, C std
includes)](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-15-320.jpg)
![16
kernel void foo(global int* buf){
int tid = get_global_id(0) *
get_global_size(1) +
get_global_id(1);
buf[tid] = cos(tid);
}
for (int i = 0; i<DIM1; i++)
for (int j = 0; j<DIM2; j++)
std::thread([i, j, buf]() {
int tid = i*DIM2 + j;
buf[tid] = cos(tid);
}
OpenCL program
Starting from C99
+ Keywords (specify kernels
i.e.parallel work items,
address spaces (AS) to allocate objects
to mem e.g.global,local,private …)
+ Builtin functions and types
- Disallowed features
(function pointers,recursion, C std
includes)
DIM1
DIM2](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-16-320.jpg)
![17
kernel void foo(global int* buf){
int tid = get_global_id(0) *
get_global_size(1) +
get_global_id(1);
buf[tid] = cos(tid);
}
for (int i = 0; i<DIM1; i++)
for (int j = 0; j<DIM2; j++)
std::thread([i, j, buf]() {
int tid = i*DIM2 + j;
buf[tid] = cos(tid);
}
OpenCL program
Starting from C99
+ Keywords (specify kernels
i.e.parallel work items,
address spaces (AS) to allocate objects
to mem e.g.global,local,private …)
+ Builtin functions and types
- Disallowed features
(function pointers,recursion, C std
includes)
DIM1
DIM2
C99
OpenCL](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-17-320.jpg)


![21
Example:
float cos (float x) __attribute((overloadable))
double cos(double x) __attribute((overloadable))
Many builtin functions have multiple prototypes i.e.overloads
(supported in C via __attribute((overloadable)))
OpenCL header is 20K lines of declarations
Automatically loaded by compiler (no #include needed)
Affects parse time
To speedup parsing – Precompiled Headers (PCHs) [PCH]
has large size ~ 2Mb for OpenCL header
Size affects memory consumed and disk space
BUT some types and functions require special compiler
support…
Builtin functions and types](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-21-320.jpg)





![31
1: if (tid == 0) c = a[i + 1]; // compute address of array element = load address of a and
compute the offset (a+1) => 2 instr, only 1 thread active
2: if (tid != 0) e = a[i + 2];// as in line 1- 2 instr for address computation (a+2) all threads other
than thread 0
Transformed into:
1: p = &a[i + 1]; // load address of a and compute the offset => 2 instr all threads
2: if (tid == 0) c = *p; // only thread 0 will perform this computation
3: q = &a[i + 2]; // address of a is loaded on line 3 thus only offset is to be computed (CSE
optimisation) => 1 instr all threads
4: if (tid != 0) e = *q; // all threads other than thread 0 will run this
In SPMT all lines of code will be executed, therefore the transformed program
will run 1 instr less (the transformed code will run longer for a single thread)
Optimizations for SPMD
Speculative execution](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-31-320.jpg)
![32
Exploring different types of parallelism
SPMD vs SIMD
r0= load
r1= load
r1=r0+r1
r0= load
r1= load
r1=r0+r1
r0= load
r1= load
r1=r0+r1
int *a, *b, c;
…
a[tid] = b[tid] + c;
r0= load
r1= load
r1=r0+r1
int2 *a, *b, c;
;…
//a vector operation
is performed with
multiple elements at
once
a[tid] = b[tid] + c;
Is it always good to vectorize?
Speed up if fewer
threads are created
while each thread
execution time
remains the same](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-32-320.jpg)
![33
Exploring different types of parallelism
SPMD vs SIMD
r0= load
r1= load
r1=r0+r1
r0= load
r1= load
r1=r0+r1
r0= load
r1= load
r1=r0+r1
int *a, *b, c;
…
a[i] = b[i] + c;
r0= load
r1= load
r1=r0+r1
int2 *a, *b, c;
;…
//a vector operation
is performed with
multiple elements at
once
a[i] = b[i] + c;
Is it always good to vectorize?
Speed up if fewer
threads are created
while each thread
execution time
remains the same
What if the computation of c (calling some builtin functions)
results in many instructions that have to be duplicated in a
vectorized kernel:
vectorized application longer threads by 100 cycles
c = builtin100cysles(x)
c.s1 = builtin100cysles(x1);
c.s2 = builtin100cysles(x2)](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-33-320.jpg)

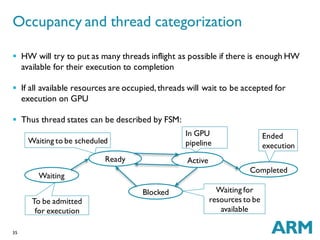
![36
How many registers to allocate for the kernel
Using more registers reduces spilling (storing to/loading from memory)
by keeping data in a register
For GPUs #REGs can affect amount of threads that can be
created because all registers are shared and allocated to threads
before scheduling them (Waiting -> Ready transition)
Thread interleaving reduces idle time while waiting for result
Example RA tread off - 1024 registers in total
Allocate 4 REGs with 20 spills and run max 256 threads to mask blocking
Allocate 16 REGs with 5 spills and run max 64 threads to mask blocking
More information in
Occupancy in RegisterAllocation
[OPT]](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-36-320.jpg)

![38
Fixed pipeline with programmable functionality
Evolved from very fixed functionality to highly programmable
components by writing shaders (in C like syntax - OpenGL)
Evolving towards unifying graphics and compute - Vulkan [VUL]
Sometimes requires less accuracy as soon as visualization is
correct and therefore alternative optimizations are possible
Harder to estimate the workload
What about graphics?
Geometry
(Vertexes)
Vertex
Shader
Fragment
Shader
BlenderRasterizer
A boundary
between vertex and
pixel processing](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-38-320.jpg)

![40
[DLX] https://en.wikipedia.org/wiki/DLX
[IWOCL] http://www.iwocl.org/wp-content/uploads/iwocl-2014-
workshop-Tim-Hartley.pdf
[PCH] http://clang.llvm.org/docs/PCHInternals.html
[OPT] https://www.cvg.ethz.ch/teaching/2011spring/gpgpu/GPU-
Optimization.pdf
[VUL] https://www.khronos.org/vulkan/
References](https://image.slidesharecdn.com/gpucompcu2016-201028112007/85/Challenges-in-GPU-compilers-40-320.jpg)

































![[232] 성능어디까지쥐어짜봤니 송태웅](https://cdn.slidesharecdn.com/ss_thumbnails/232-161025013504-thumbnail.jpg?width=640&height=640&fit=bounds)














































