Download to read offline




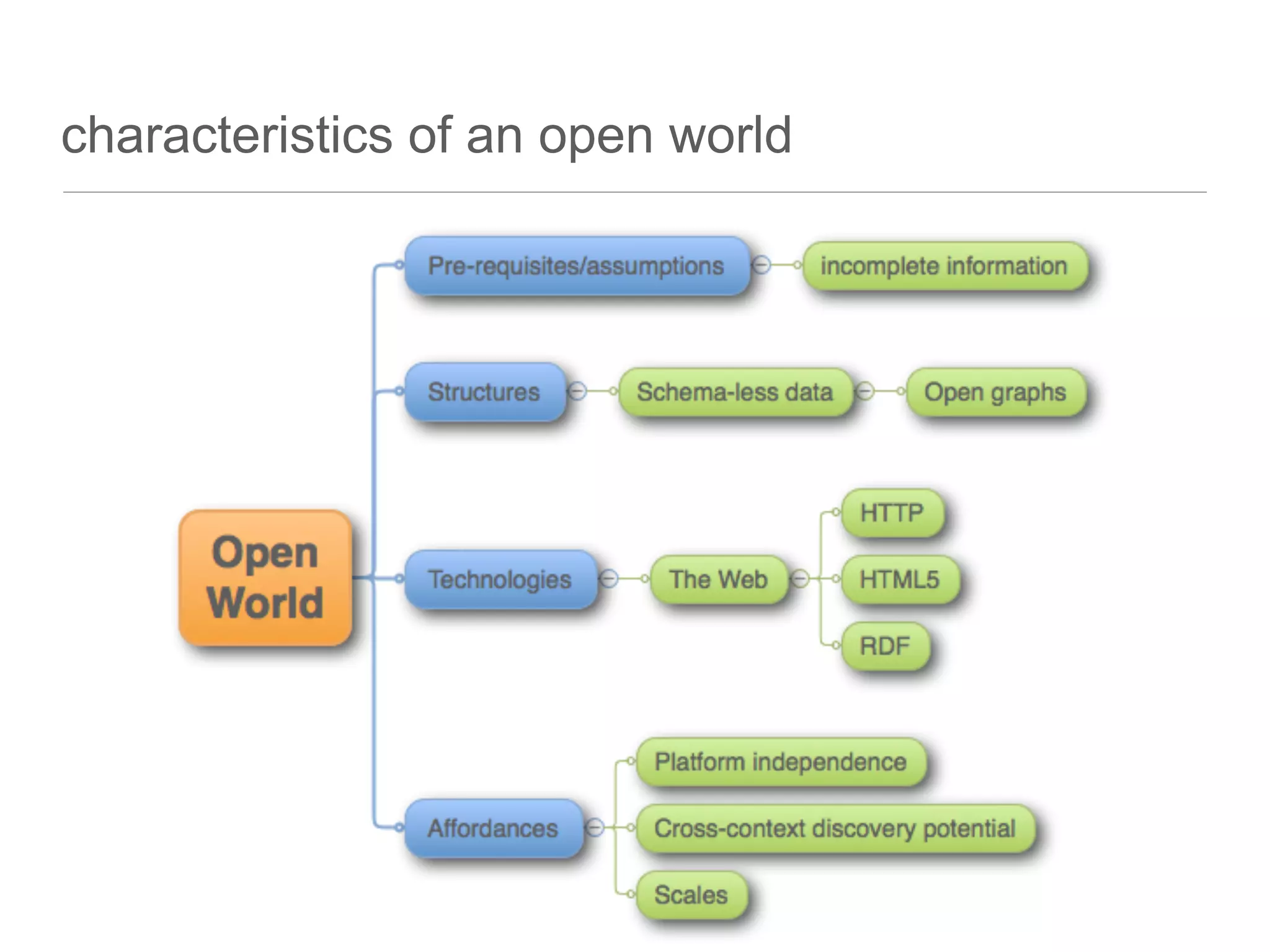
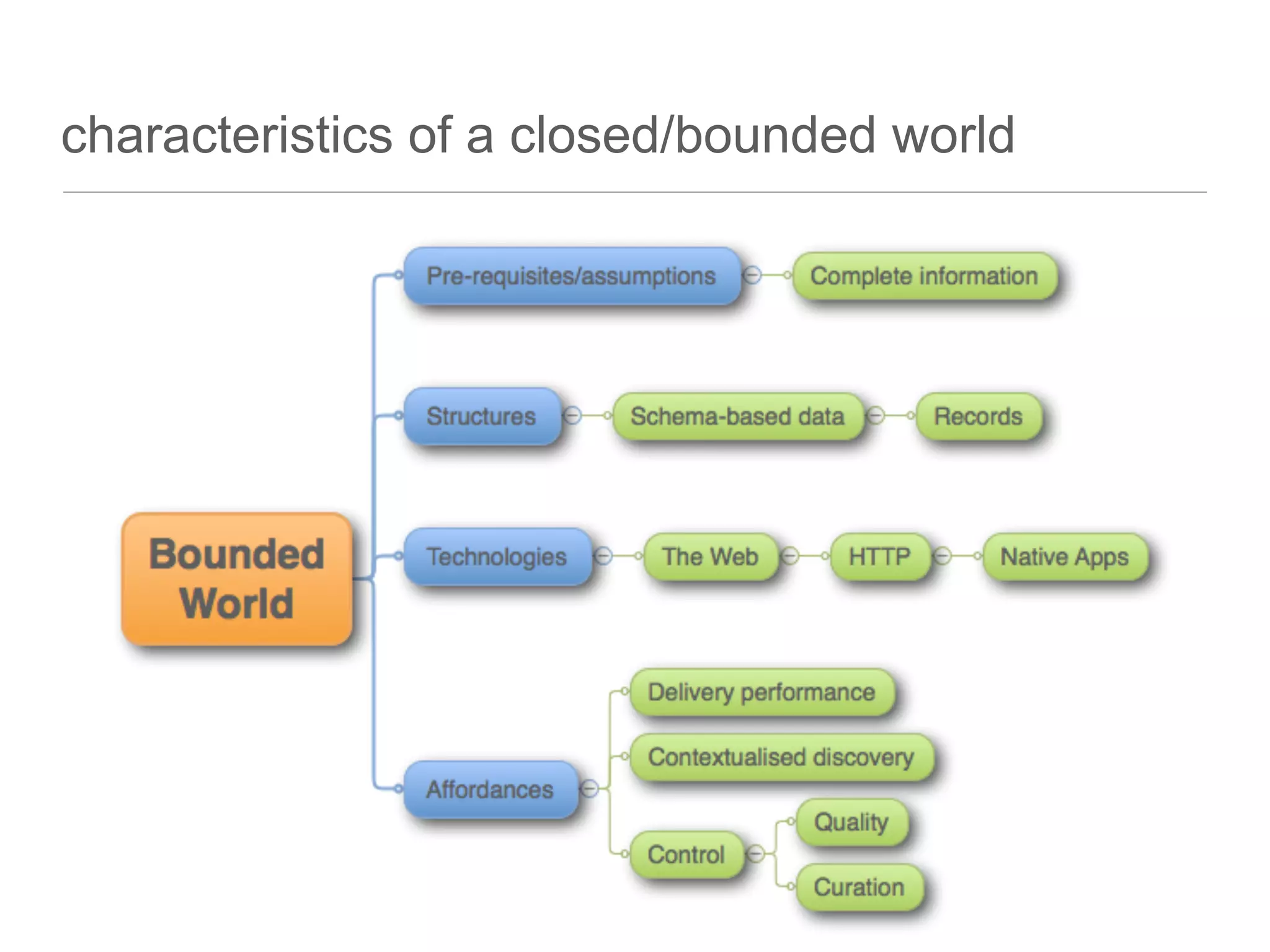


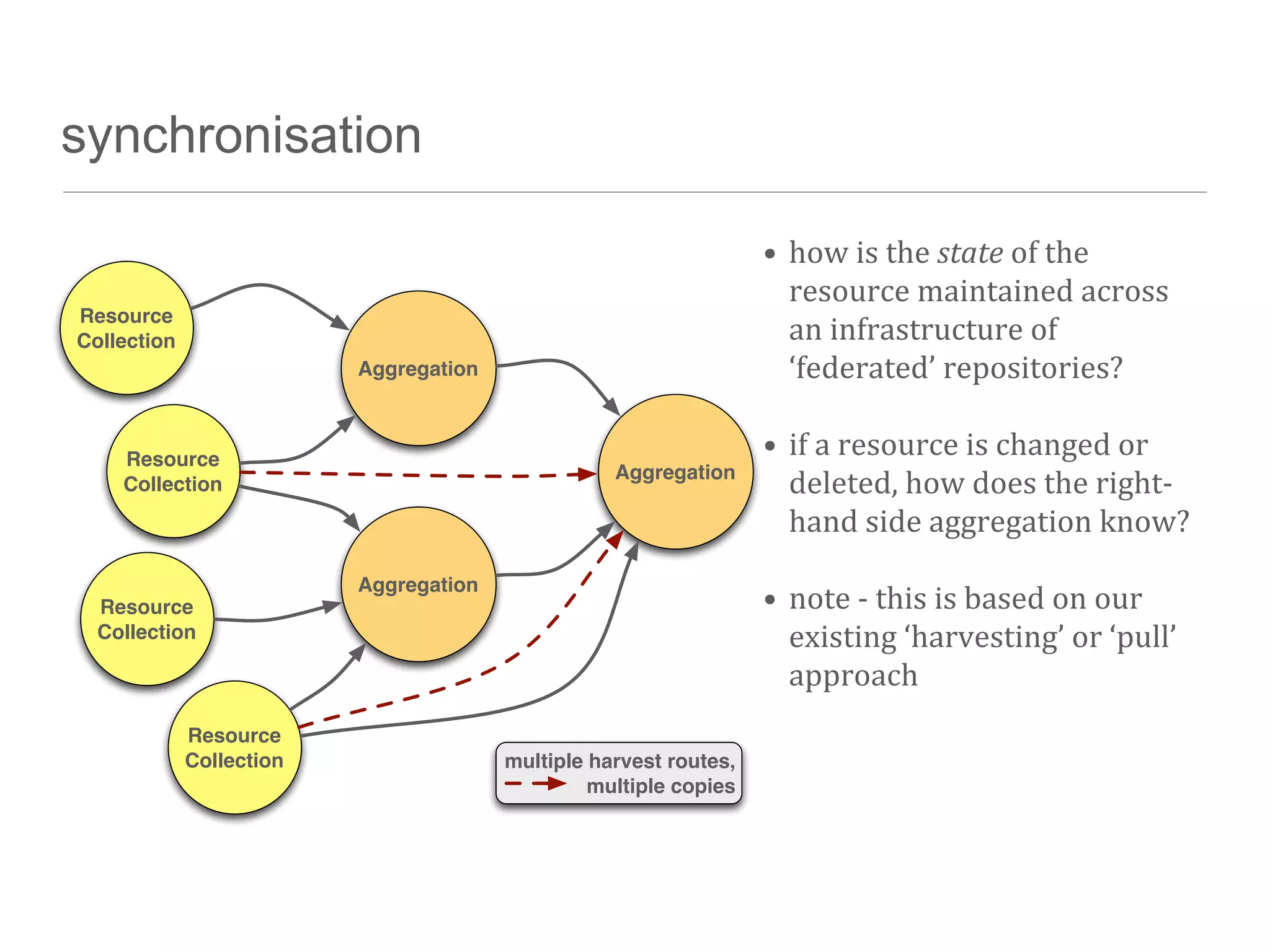



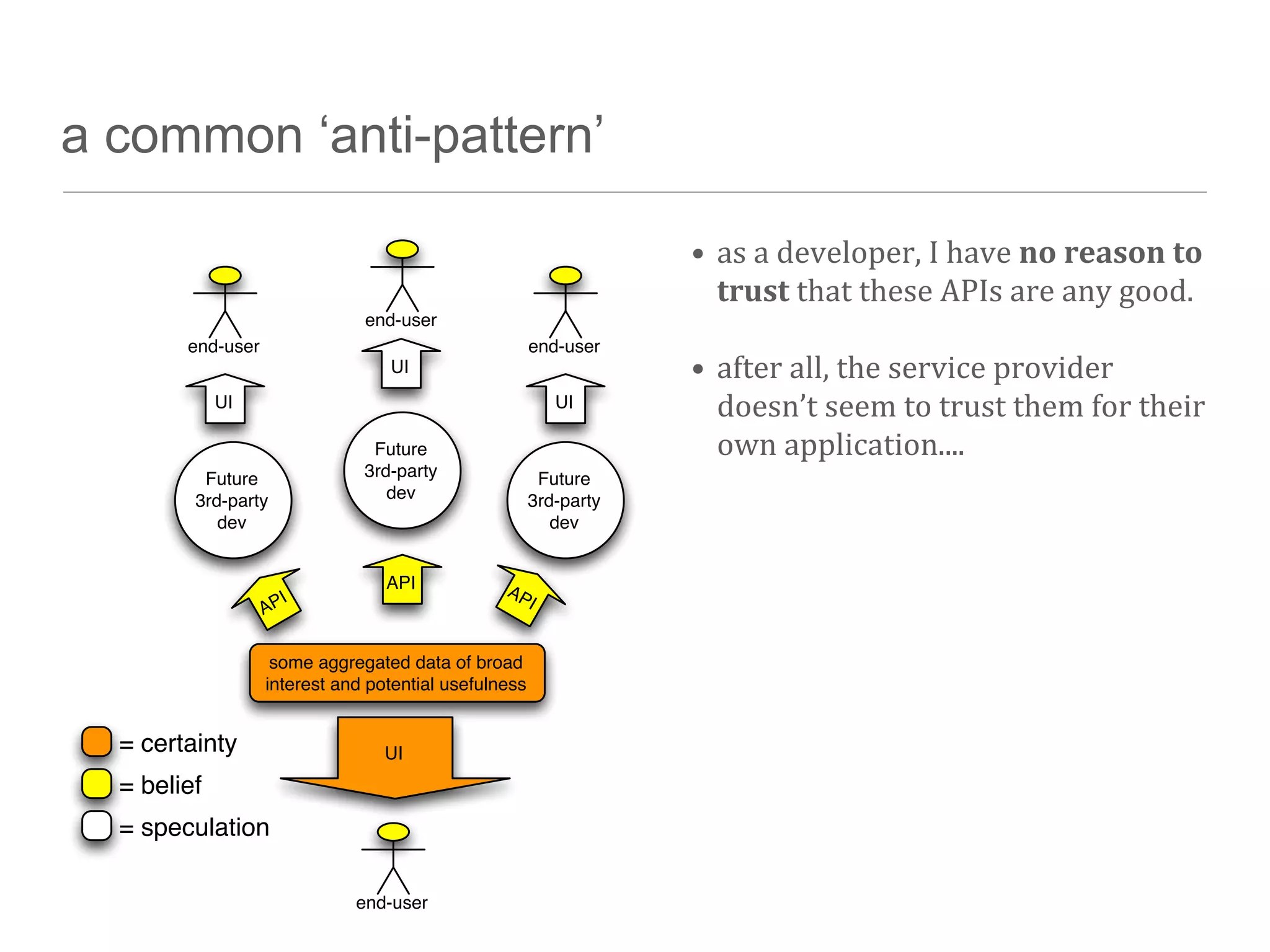
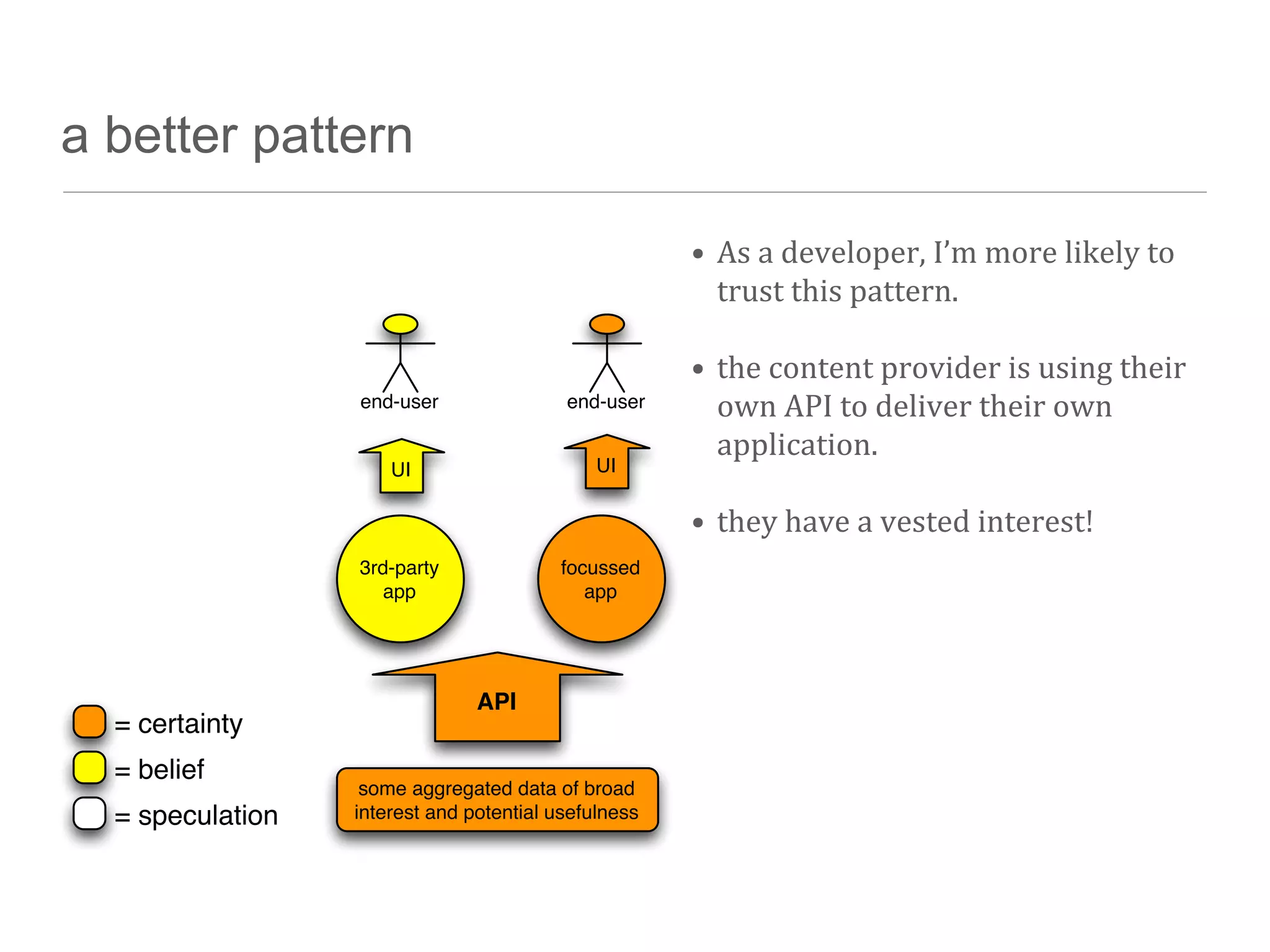



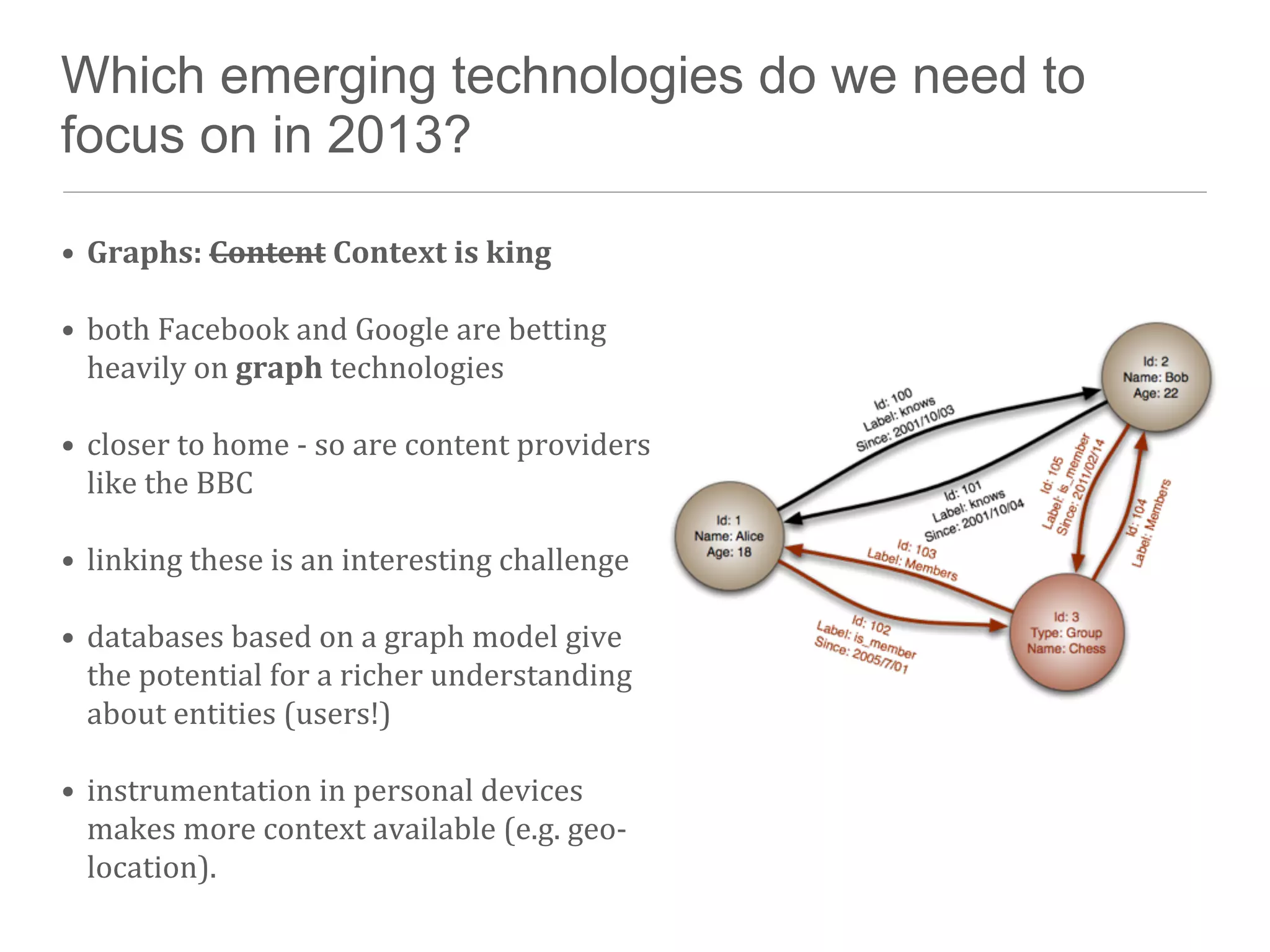




The document discusses the technical challenges in resource discovery, particularly focusing on the balance between open and closed systems and the importance of synchronization across aggregated resources. It highlights the need for trusted APIs that provide complete data access to enhance user experience and improve system integration. Additionally, emerging technologies such as graph databases are identified as key areas to focus on in the near future for better understanding and utilization of data.
































































































