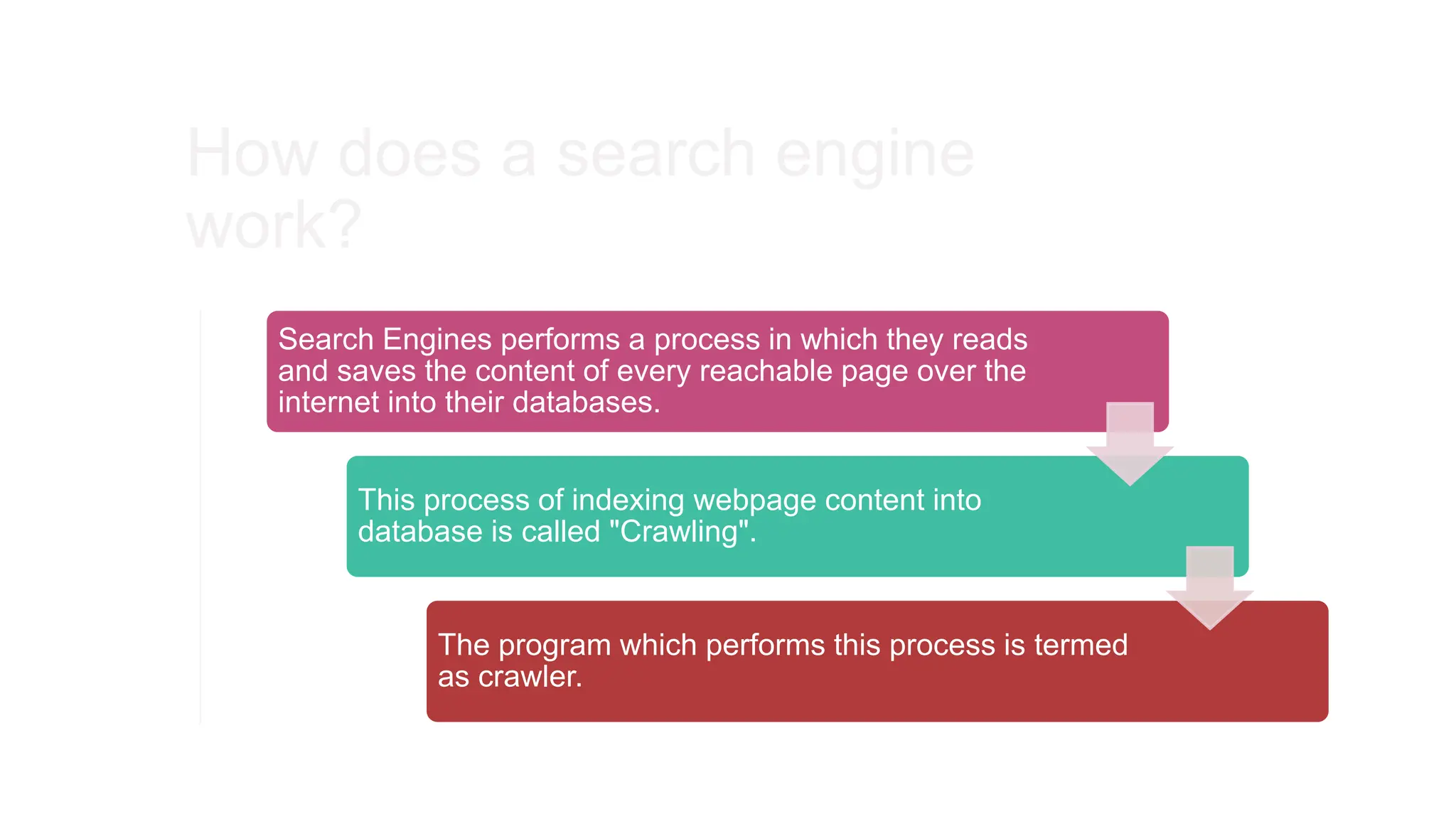
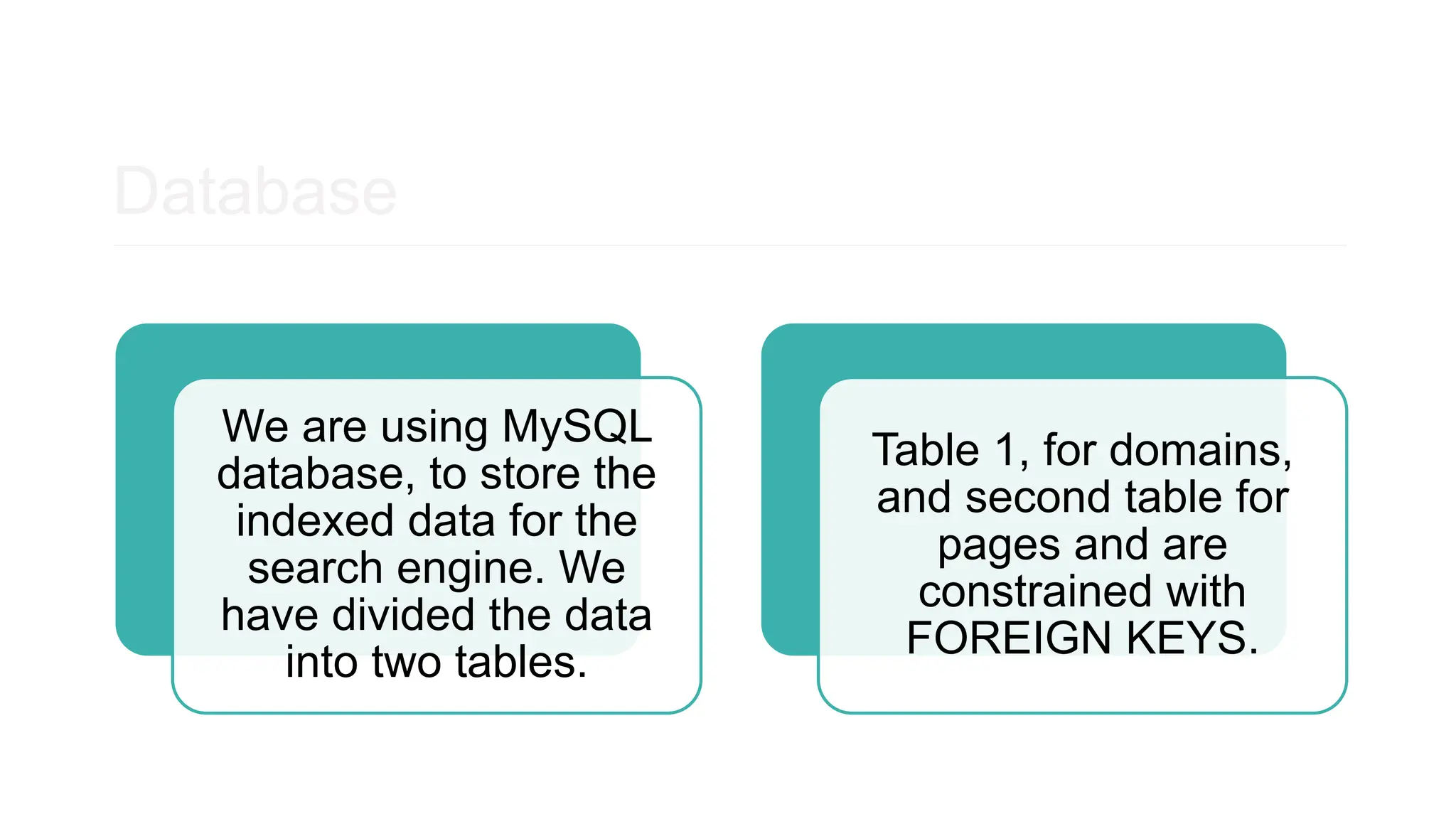
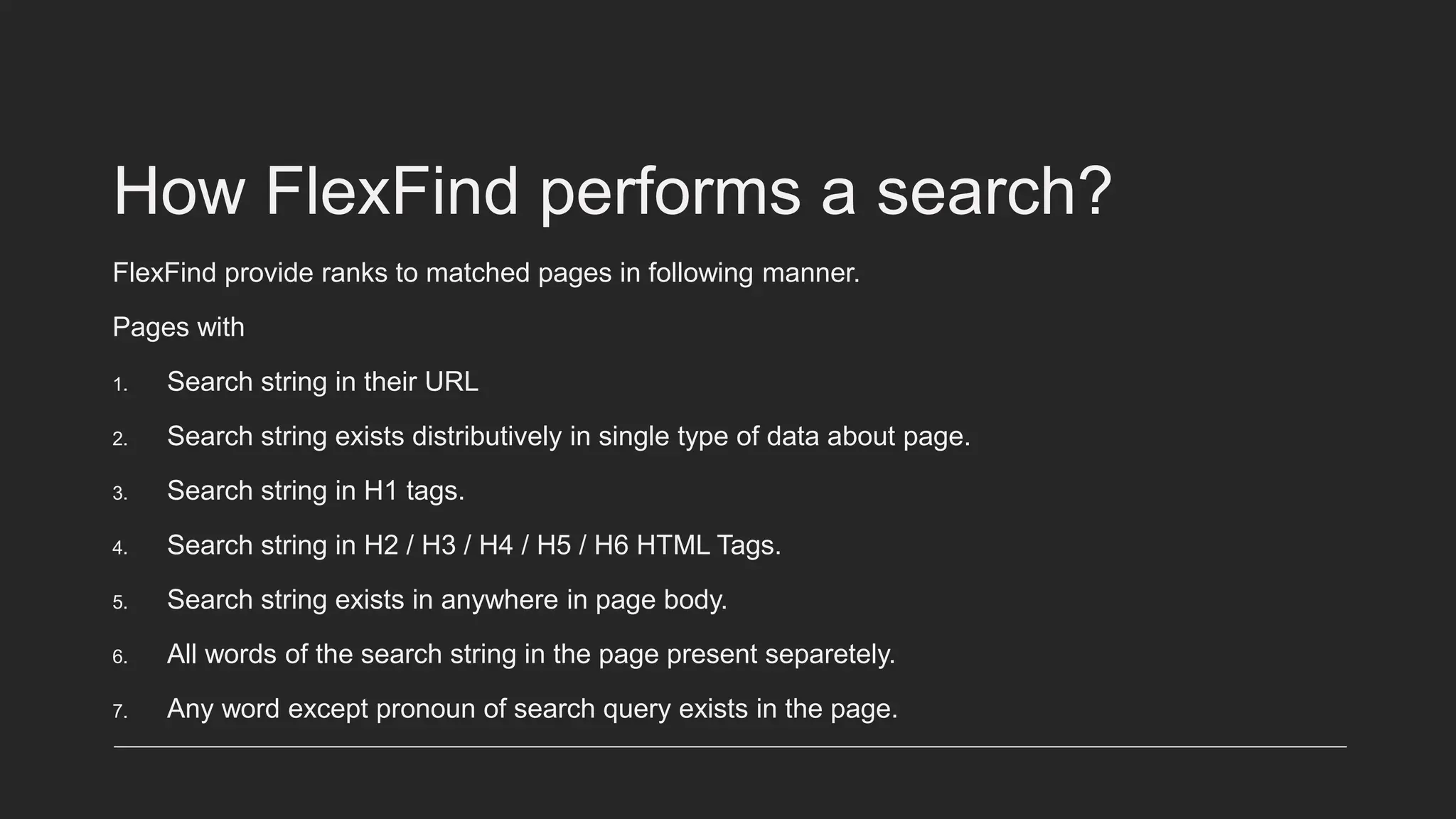
The document explains how search engines, like Google, work by utilizing crawlers to index the content of web pages into databases rather than searching the entire internet in real-time. It details the architecture of a new search engine named Flexfind, which uses Node.js and TypeScript for its crawler and MySQL for database management. Additionally, it discusses the importance of search algorithms in determining page rankings based on various factors, including backlinks and on-page optimization.