Download as PDF, PPTX



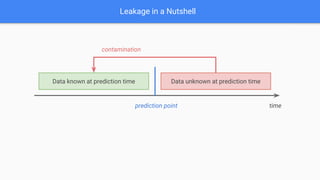
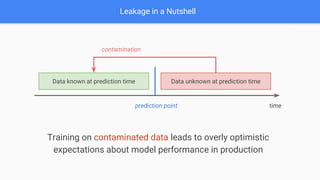









































The document discusses target leakage in machine learning, emphasizing how it can occur at various stages of the project lifecycle, including data collection, feature engineering, and model evaluation. It provides examples of leakage situations and stresses the importance of preventing leakage through measures such as maintaining strict data partitioning and understanding feature implications at prediction time. A checklist for leakage prevention is also presented, aiming to help practitioners avoid common pitfalls in model development.































































![[JEEConf 2015] Lessons from Building a Modern B2C System in Scala](https://cdn.slidesharecdn.com/ss_thumbnails/yuriyguts-lessonsfrombuildingamodernb2csysteminscalav2-150526144611-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




















