Downloaded 21 times









![Stemmed word distribution with Hadoop streaming, reducer.py
Stem_distribution_by_date/reducer.py
import sys
import json
from itertools import groupby
from operator import itemgetter
from nltk.probability import FreqDist
def read(f):
for line in f:
line = line.strip()
yield line.split(';')
data = read(sys.stdin)
for current_stem, group in groupby(data, itemgetter(0)):
values = [item[1] for item in group]
freq_dist = FreqDist()
print "%s;%s" % (current_stem, json.dumps(freq_dist))
20](https://image.slidesharecdn.com/healthinsurancepredictiveanalysis-v1-121204042721-phpapp02/75/Analyse-predictive-en-assurance-sante-par-Julien-Cabot-20-2048.jpg)






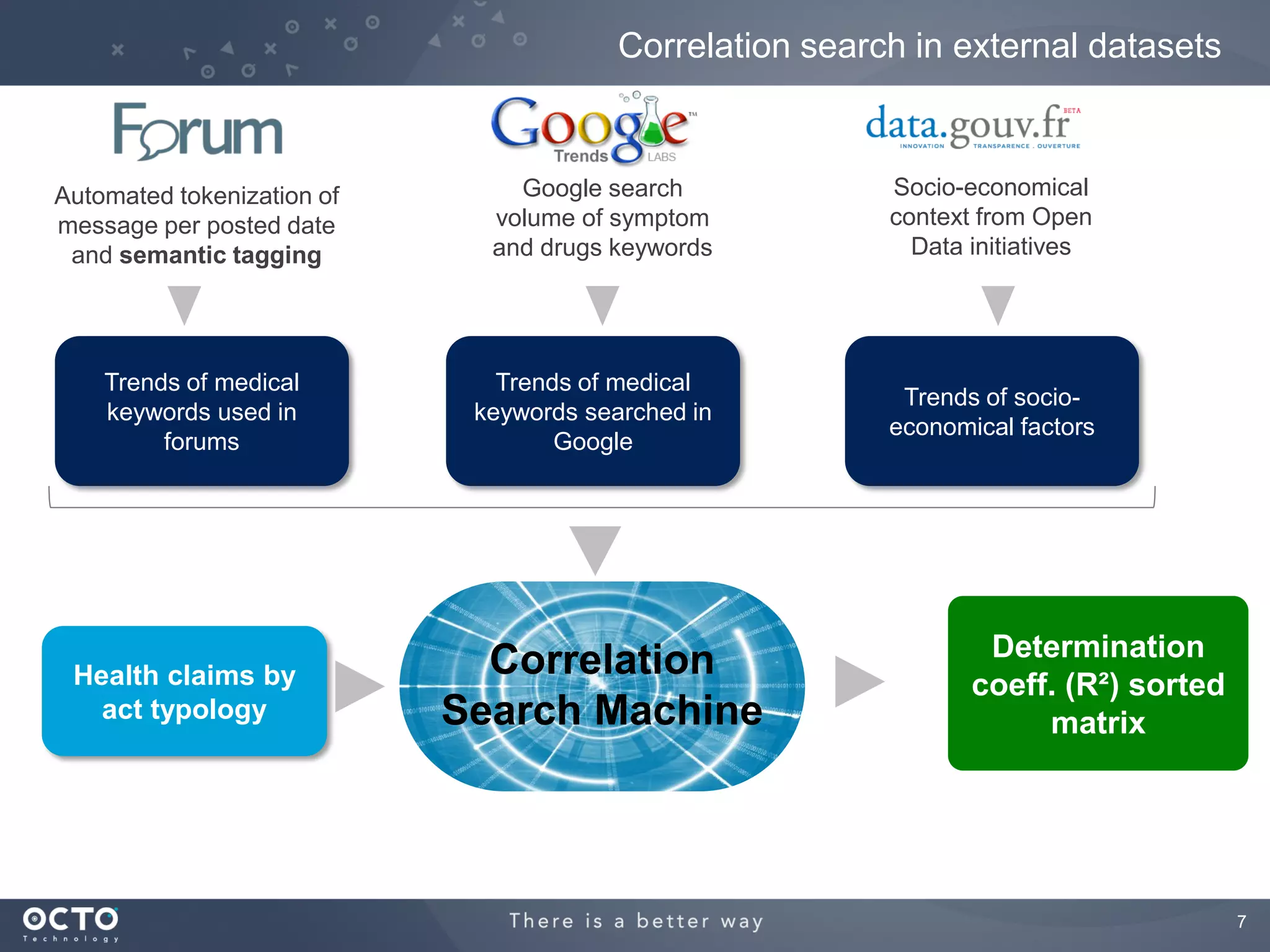
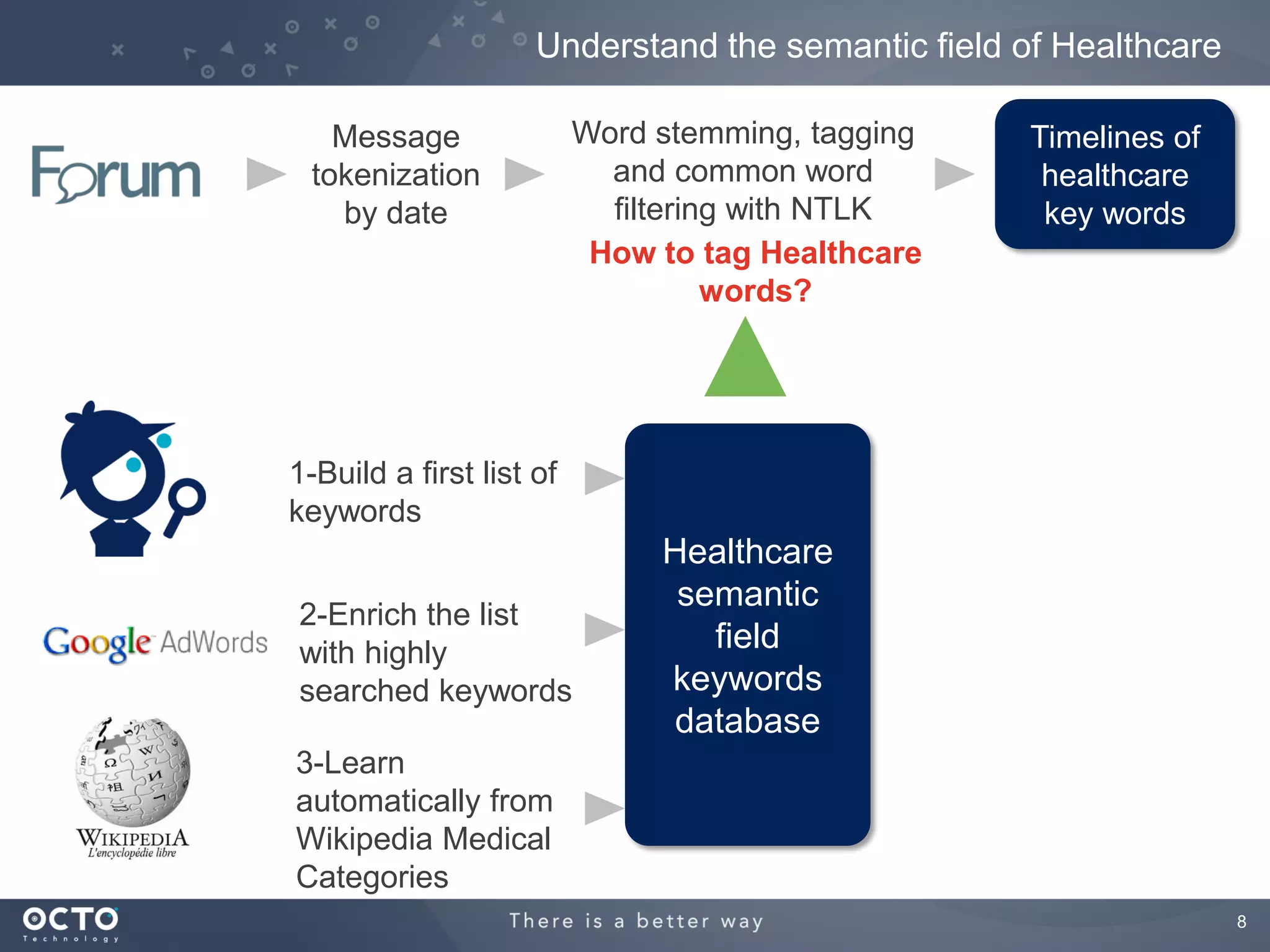
This document discusses using machine learning and MapReduce with Hadoop to perform predictive analysis on health insurance claims data. It proposes extracting data from online forums, searching for correlations between medical keywords and claims, and using support vector regression to build a predictive model. The analysis would be run on Amazon Elastic MapReduce for scalability and cost efficiency. Future work may include additional data sources and model enhancements.






















































































