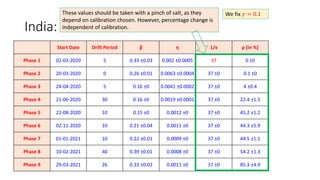
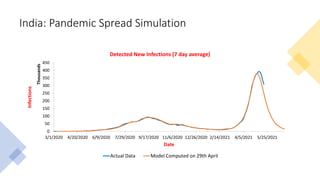
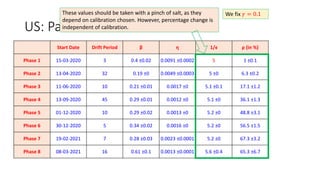
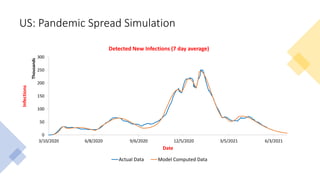
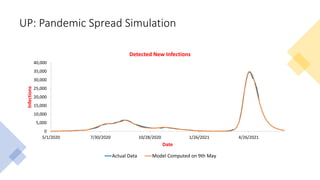
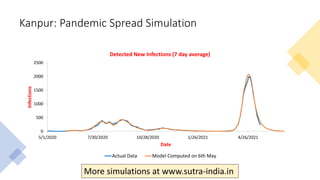
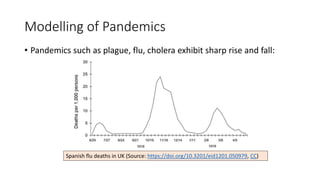
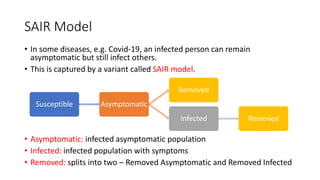
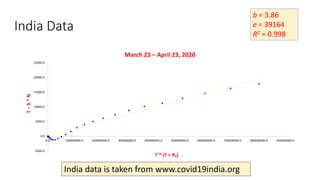
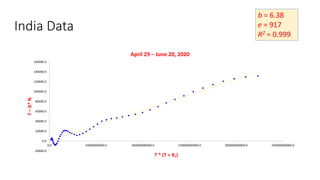
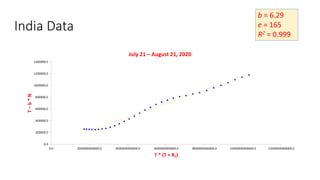
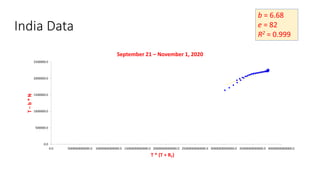
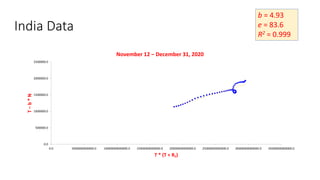
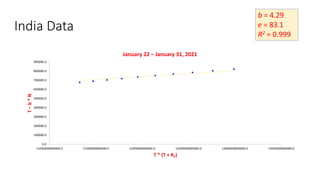
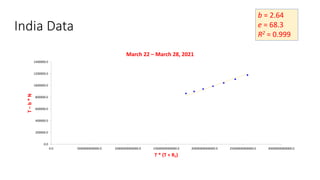
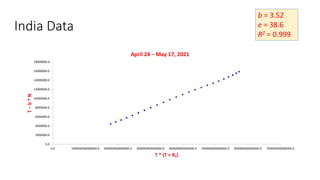
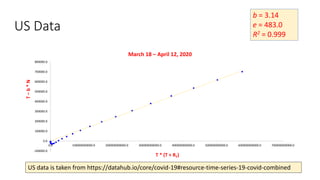
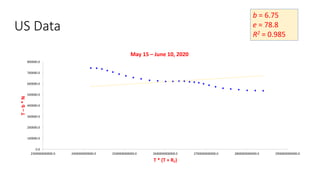
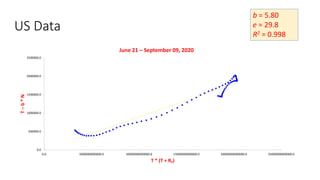
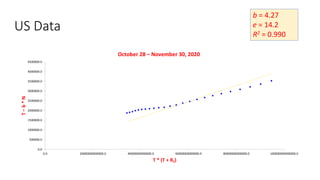
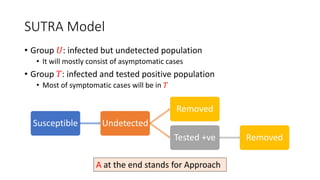
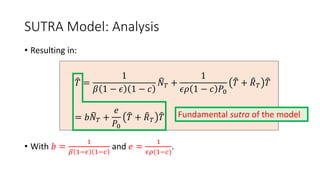
The document discusses mathematical models for pandemics like COVID-19. It summarizes existing SIR, SEIR, and SAIR models and proposes a new model. For this new model, it finds that reported daily infections (NT), active infections (T), and cumulative removed cases (RT) for many locations over time follow a linear relationship of T = bNT + e/(P0)*(T + RT), suggesting this could be used to estimate the transmission rate parameter. Analysis of data from India, US and other locations at different phases supports this relationship.


















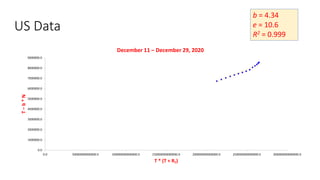
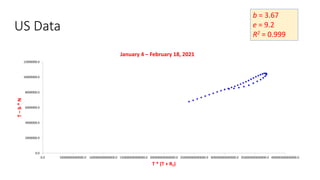
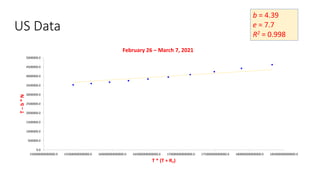
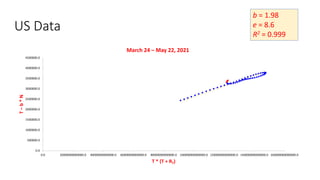













![Estimation of Parameters
• How does one estimate 𝛽 and 𝜌 from
1
𝑏
= 𝛽(1 − 𝜖)(1 − 𝑐) and
1
𝑒
=
𝜖𝜌(1 − 𝑐)?
• Define function 𝑓: 0,1 × [−1,1] as:
• On input (𝑟, 𝑠), set 𝜌 = 𝑟 and 𝑐 = 𝑠, compute 𝛽 and 𝜖, and use it to compute
trajectory of 𝑈 and 𝑅𝑈 for current phase. Compare with 𝑇 and 𝑅𝑇 to estimate
𝑇 + 𝑅𝑇 =
1
𝑎
𝑈 + 𝑅𝑈 + 𝑠′. Output (
𝑎+1
𝑒𝑎 1−𝑠′ , 𝑠′).
• Value (𝜌, 𝑐) is a fix-point of 𝑓.
Experimentally, it is found that 𝑓 has unique fix-point that can be
found quickly by iterating 𝑓 fifteen times from a random point.](https://image.slidesharecdn.com/sutramodel-ibm-220213133319/85/Sutra-model-ibm-52-320.jpg)