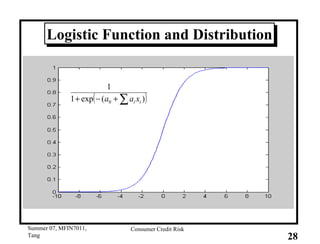
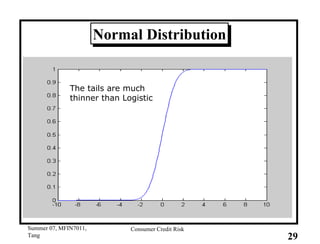
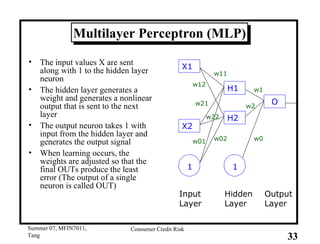
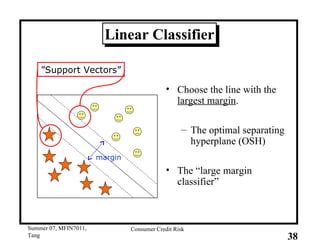
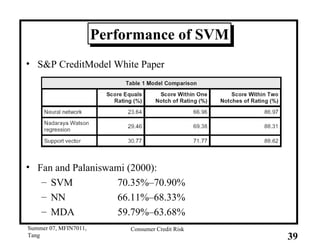
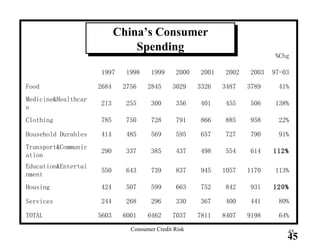
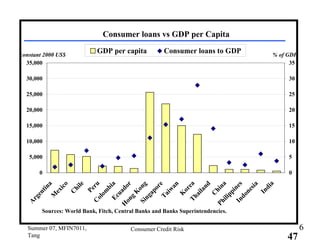
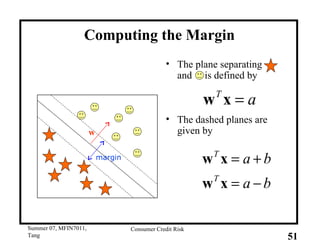
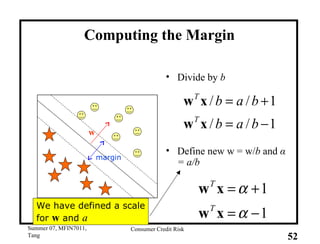
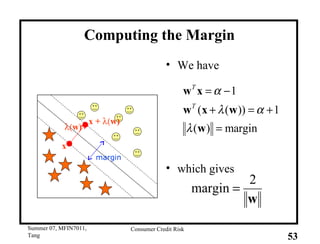
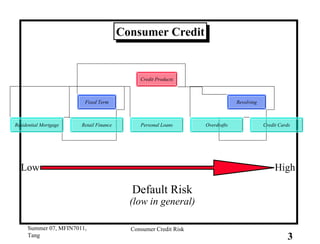
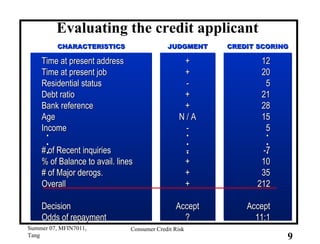
This document provides an overview of consumer credit risk modeling and scoring. It discusses various statistical methods used for credit scoring like logistic regression, neural networks, and support vector machines (SVM). For SVM, it describes how the optimal separating hyperplane is chosen to maximize the margin between different classes of data. It also discusses challenges in consumer lending and best practices for credit risk management.













![Statistical Methods: Linear Regression The regression model is like: For the true model, u can take only two values as Y; thus u can’t be normally distributed. u has heteroskedastic variances, which makes the OLS inefficient The estimated probability may well lie outside [0,1].](https://image.slidesharecdn.com/summer-07-mfin7011-tang1922-100723124617-phpapp02/85/Summer-07-mfin7011-tang1922-18-320.jpg)