Downloaded 34 times



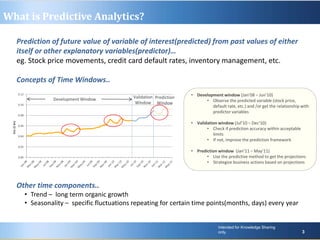

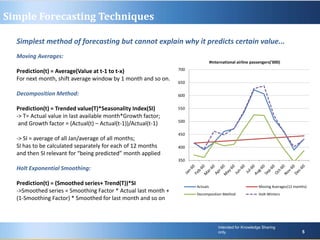
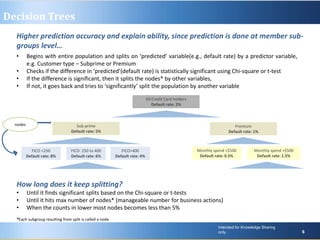



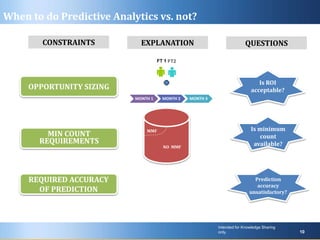


Predictive analytics uses past data to forecast future outcomes. The document discusses various predictive analytics techniques including simple forecasting methods, decision trees, and regression. Simple forecasting techniques like moving averages are easiest to implement but lack explanatory power, while decision trees and regression provide more accurate predictions at an individual level but require more complex deployment. The key is selecting the right technique based on the problem, data, and ability to implement predictive models in real-world applications.




































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











