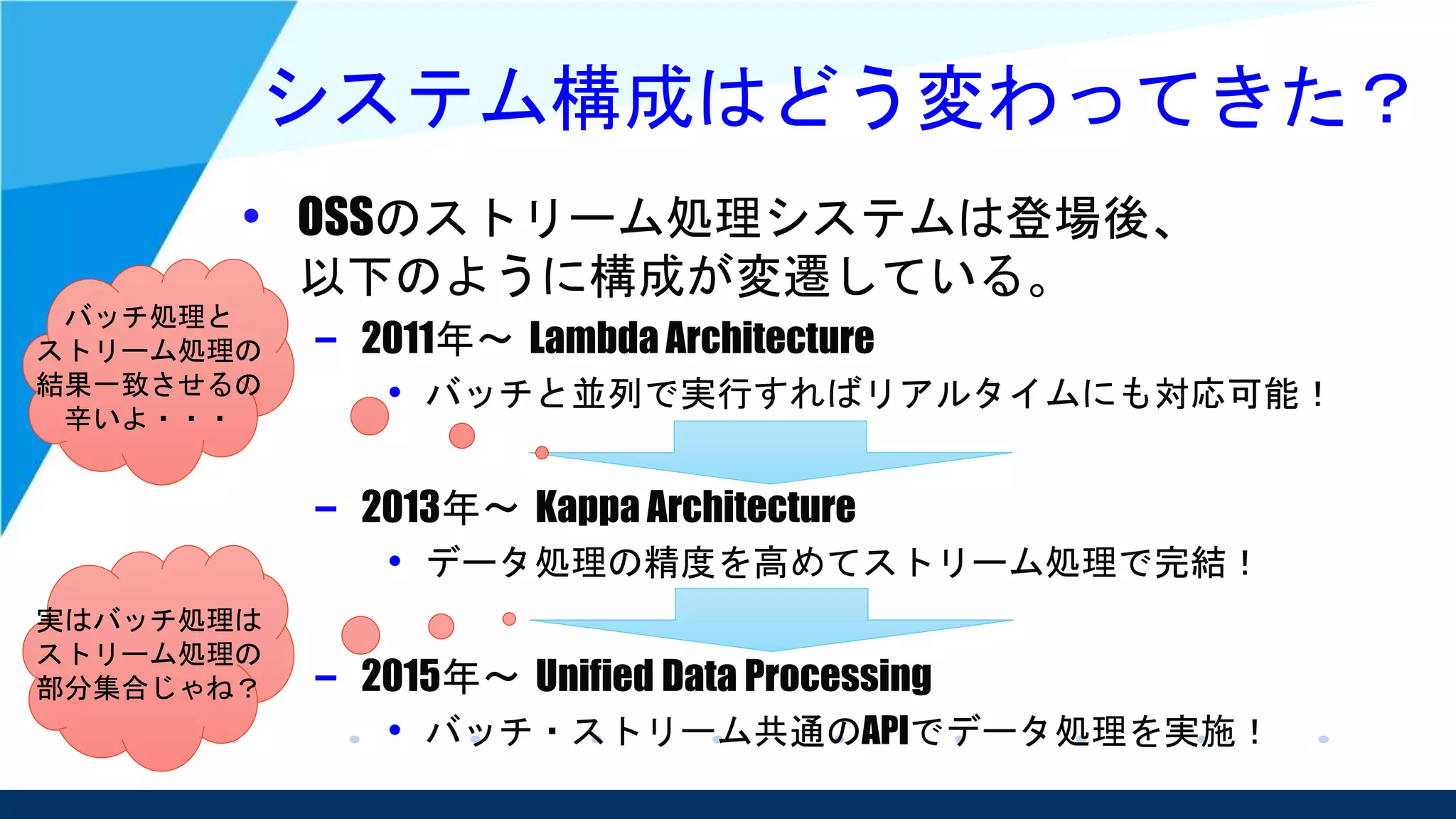
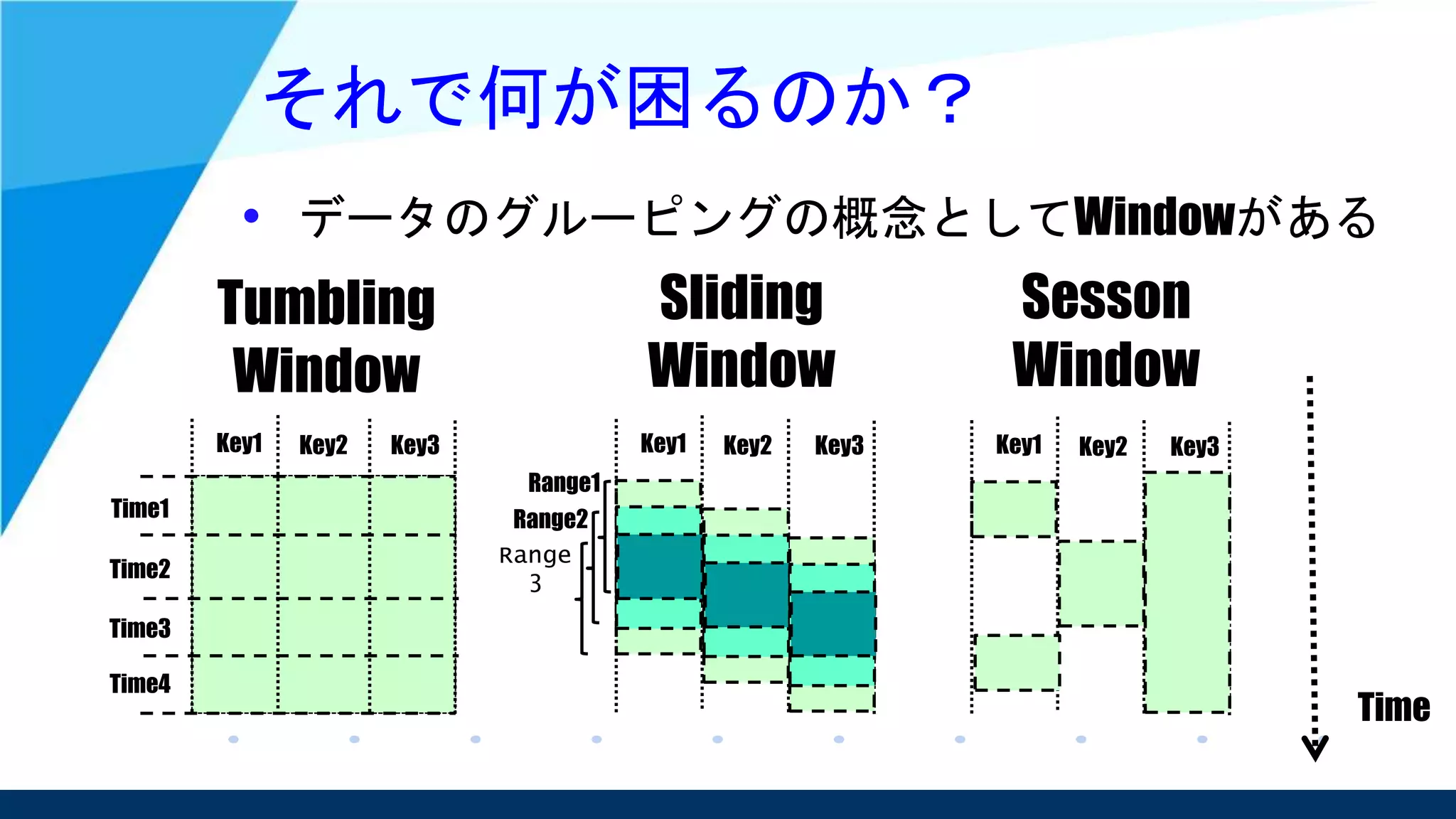
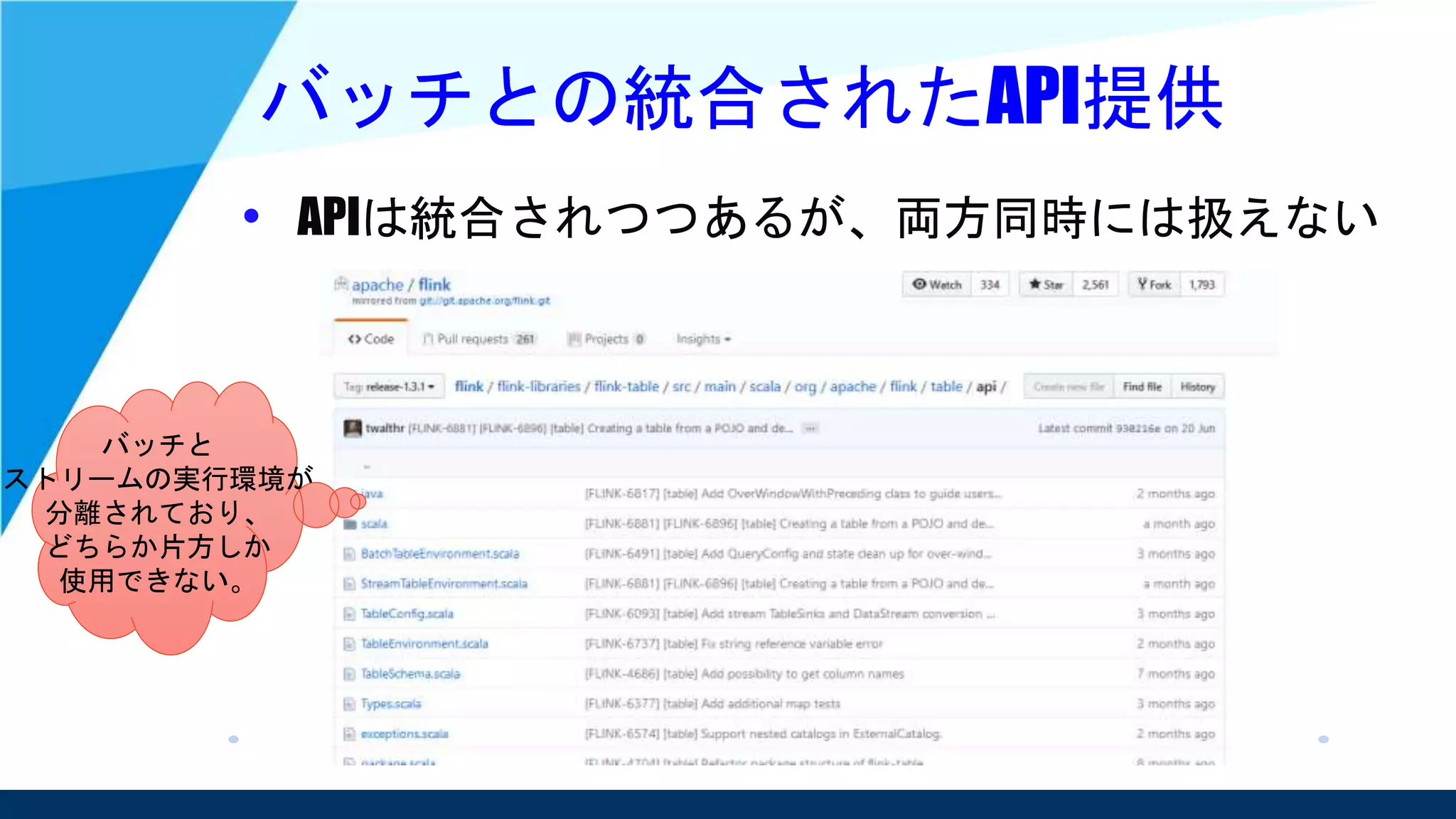
Unified Data Processing
•GoogleのTyler氏や、data Artisansの開発者が
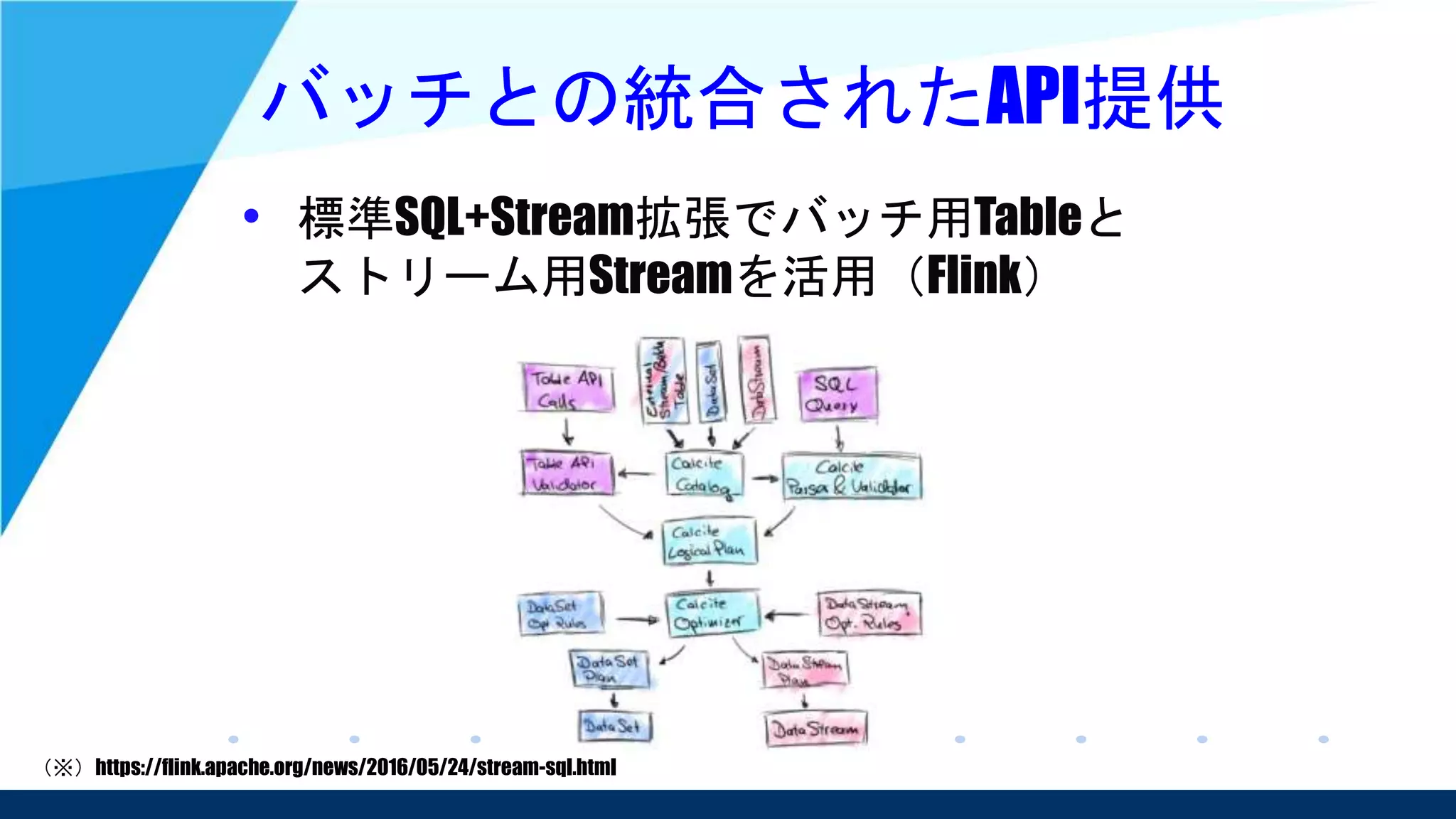
Unified Stream and Batch Processing、
ストリーム処理とバッチ処理の統合を提唱
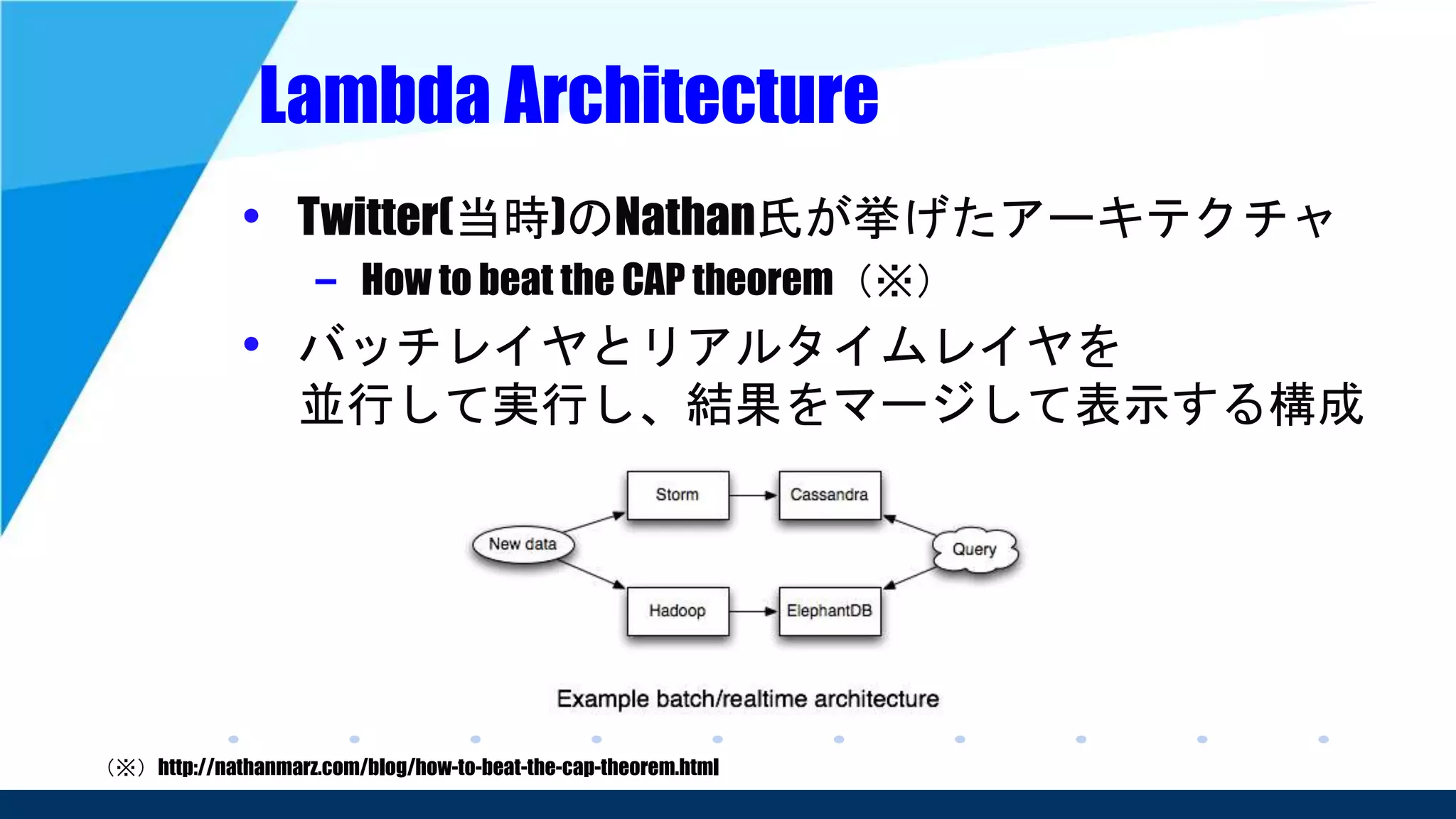
– The world beyond batch: Streaming 101 (※1)
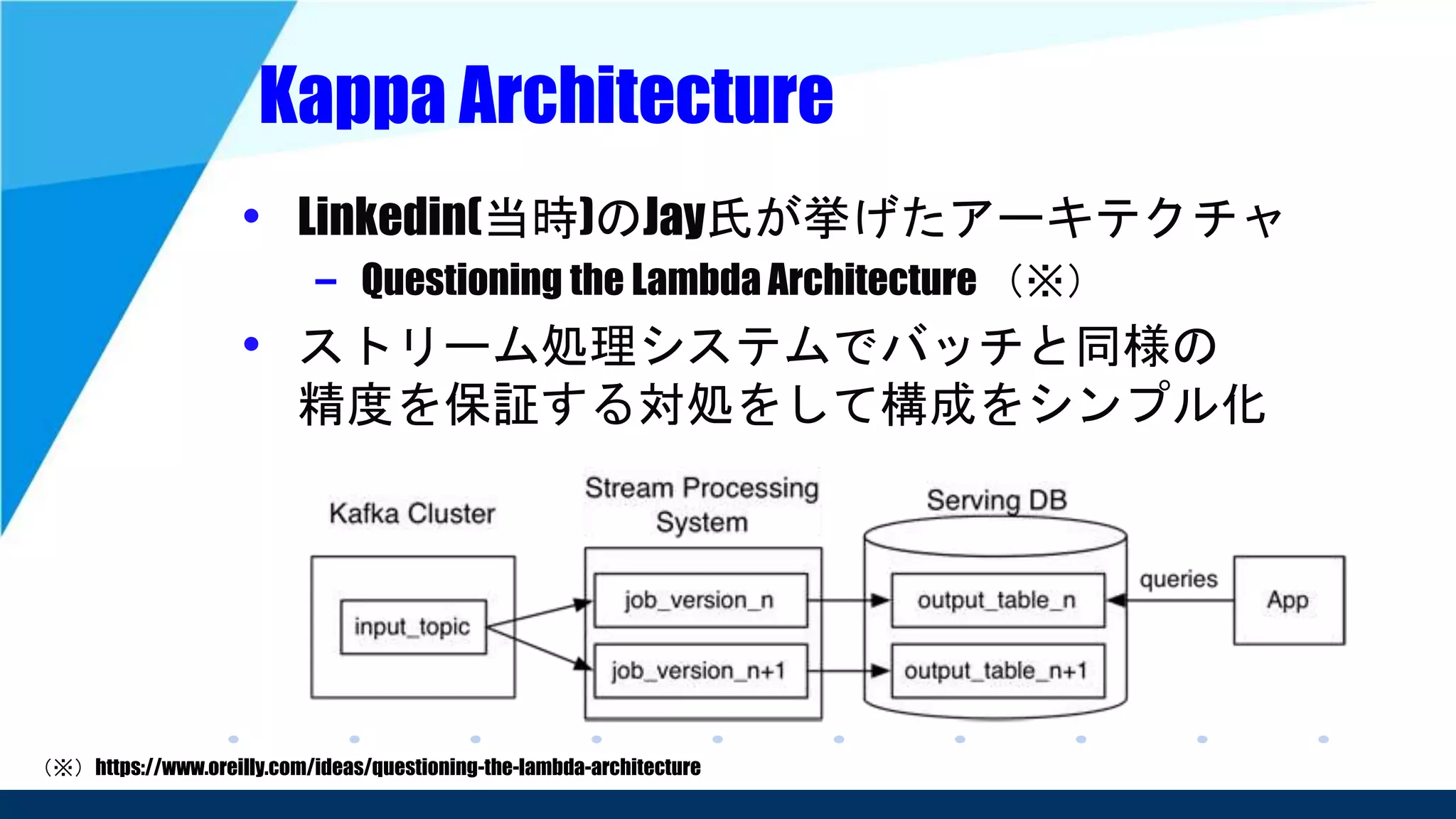
– Stream and Batch Processing in a Single Engine(※2)
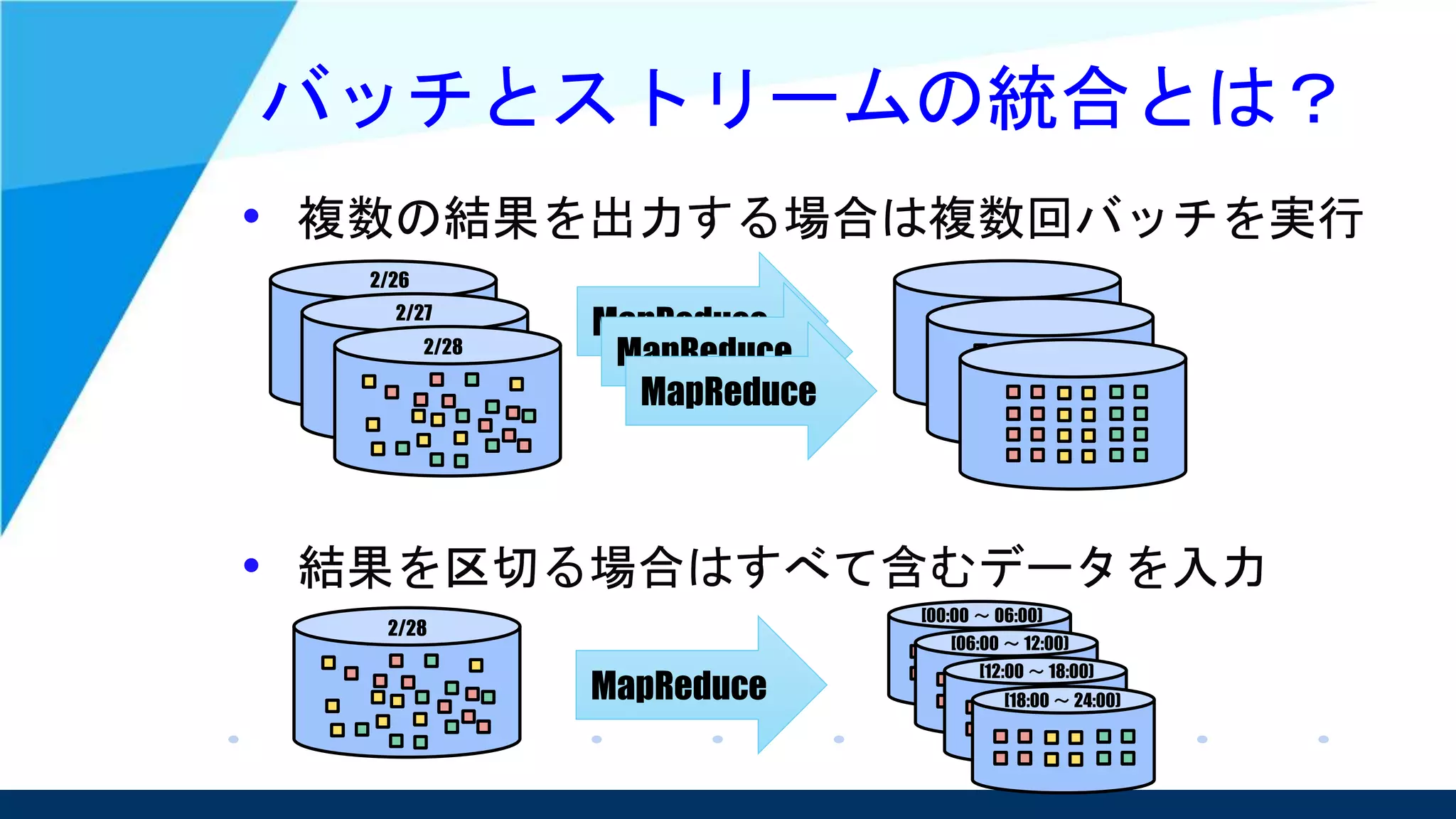
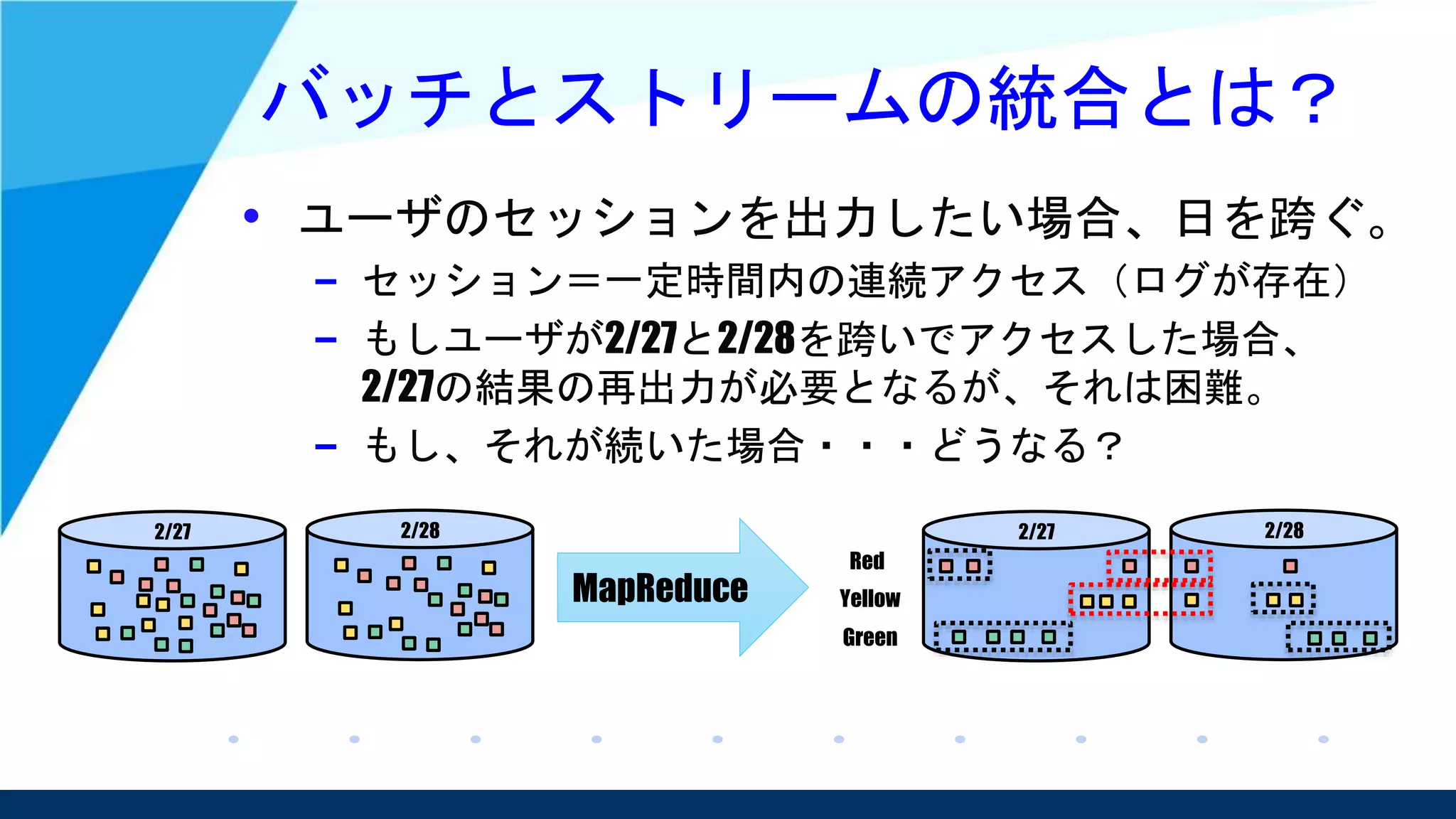
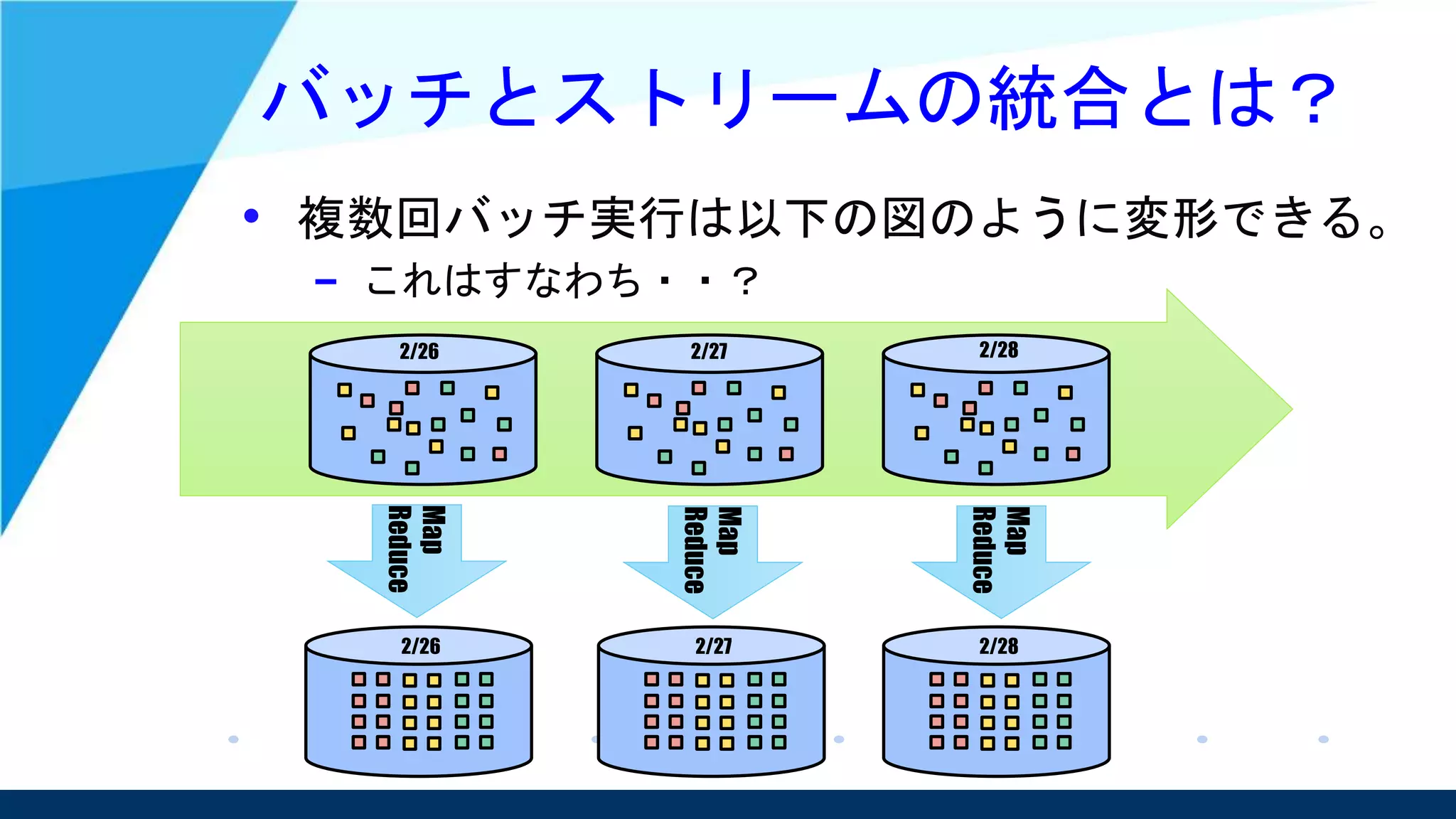
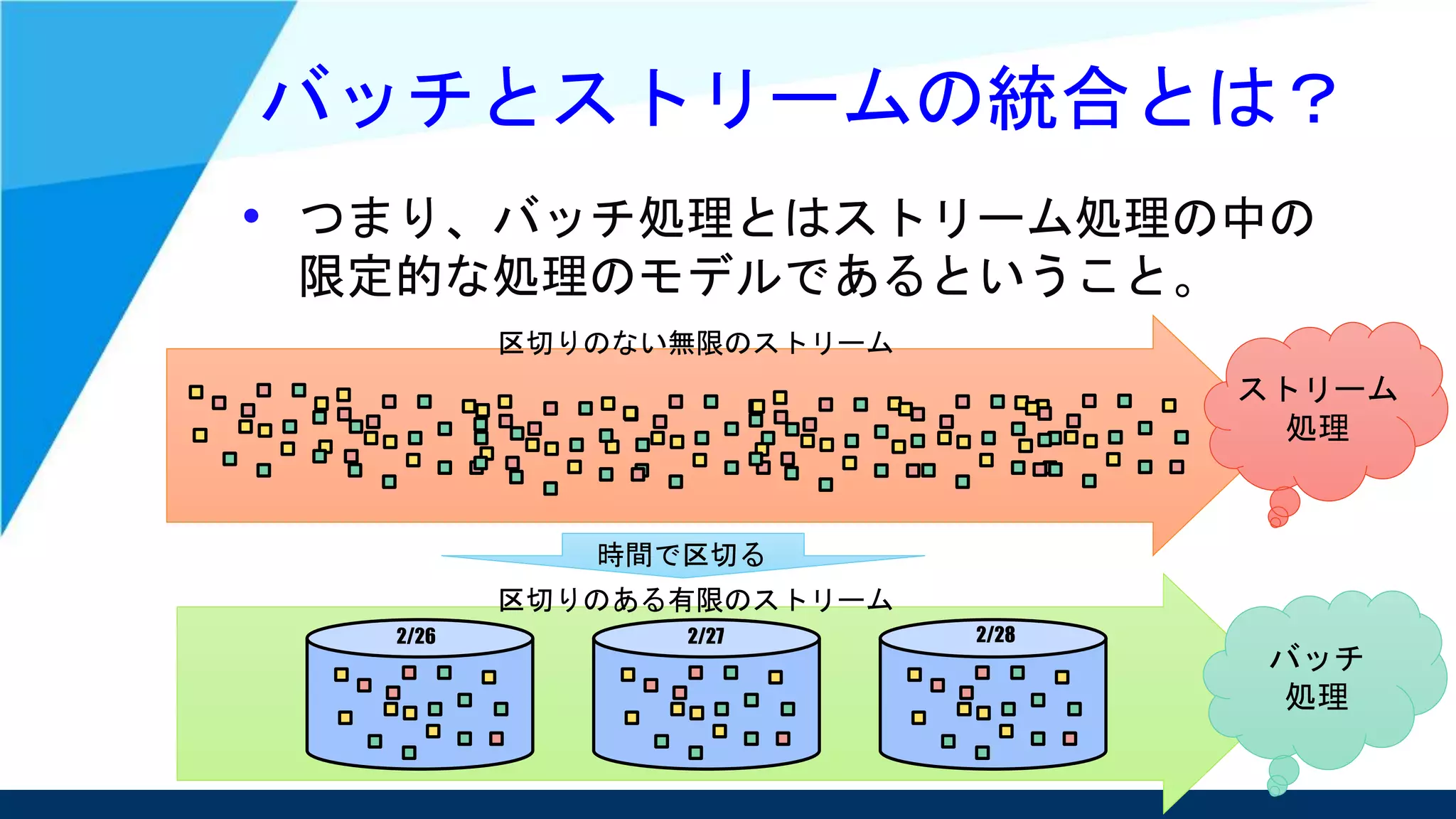
• 並行して実行されるデータ処理パイプライン
としてはこの2つは同じだという考え
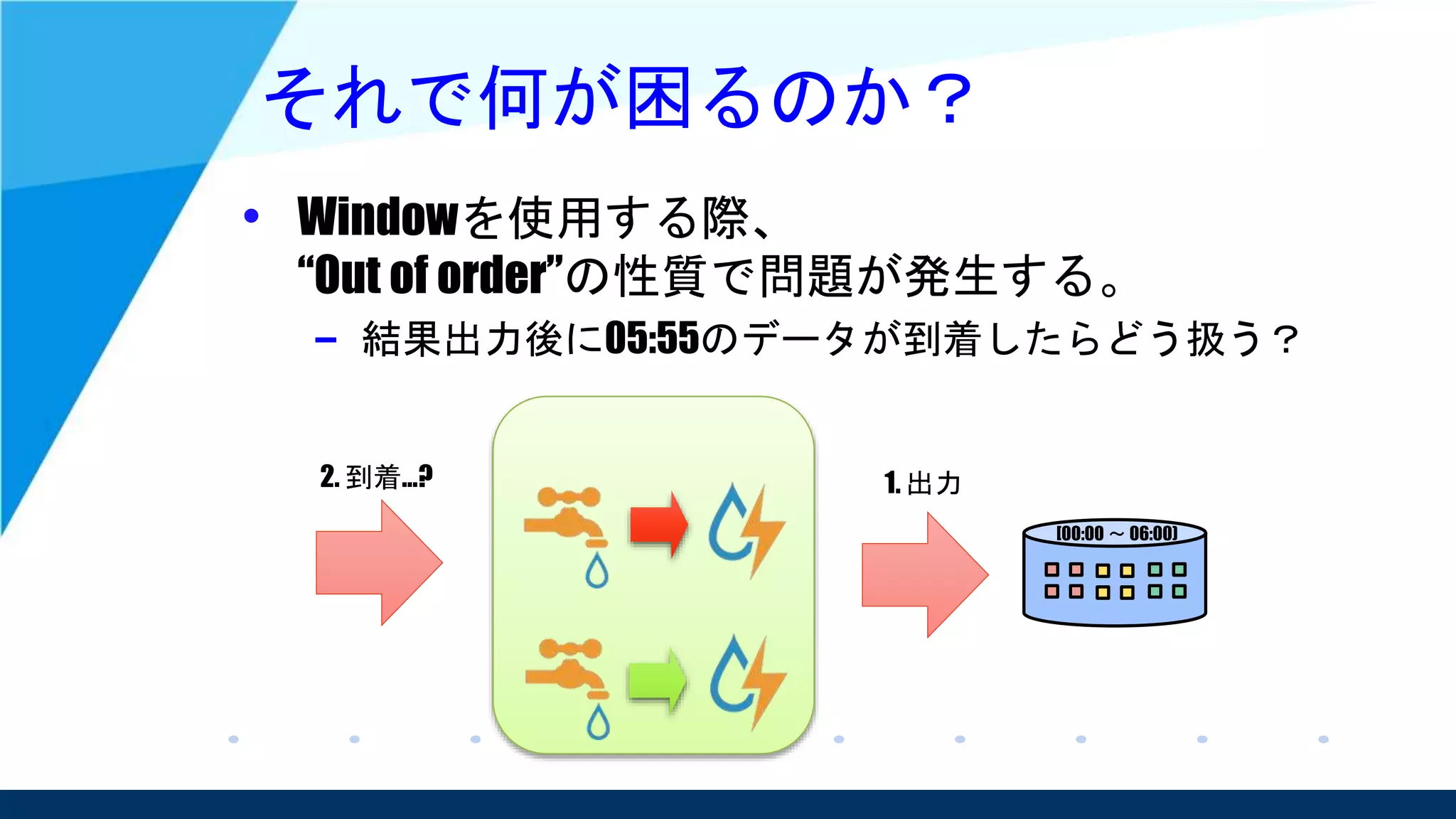
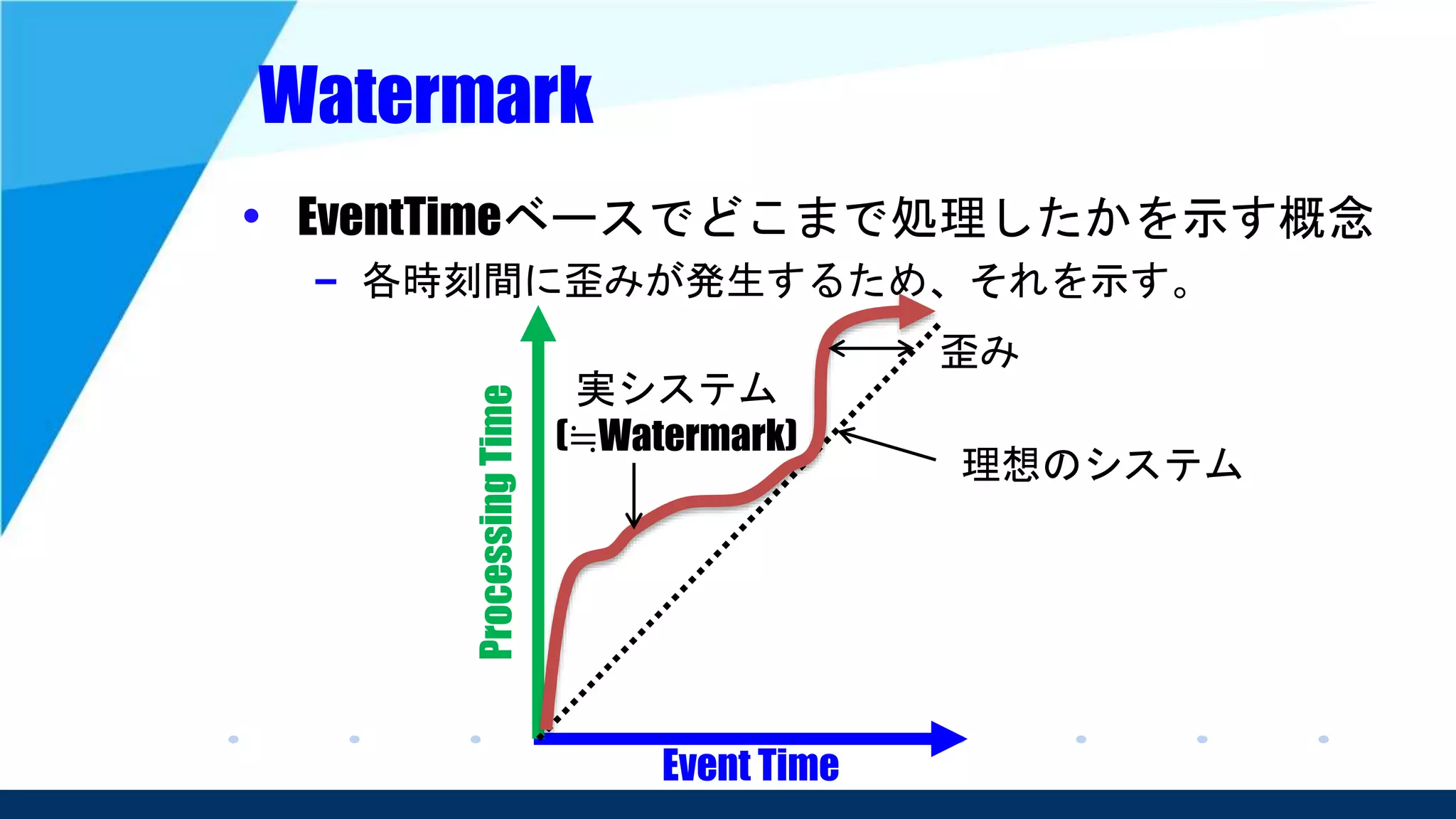
– そのため、ストリーム処理でどちらも対応可能という
スタンスを取っている。
(※1)https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
(※2)https://www.semanticscholar.org/paper/Apache-Flink-Stream-and-Batch-Processing-in-a-Sing-Carbone-Katsifodimos/2234129b45e9e2ea592e5f92c09623167ee44394



















![Spark Structured Streamingとは?
• 注意点
– Spark Streamingと同様マイクロバッチ方式であり、
レコード単位で処理するストリーム処理ではない。
– Sparkの新実行エンジンDrizzleとは独立した別の機能
• https://github.com/amplab/drizzle-spark
– Spark2.3.0で継続的に実行する方式についての提案も
挙がっているが、現状の進み具合から
おそらくSpark2.3.0では無理?
• [SPARK-20928]
Continuous Processing Mode for Structured Streaming](https://image.slidesharecdn.com/20170804-170804100055/75/Modern-stream-processing-by-Spark-Structured-Streaming-33-2048.jpg)


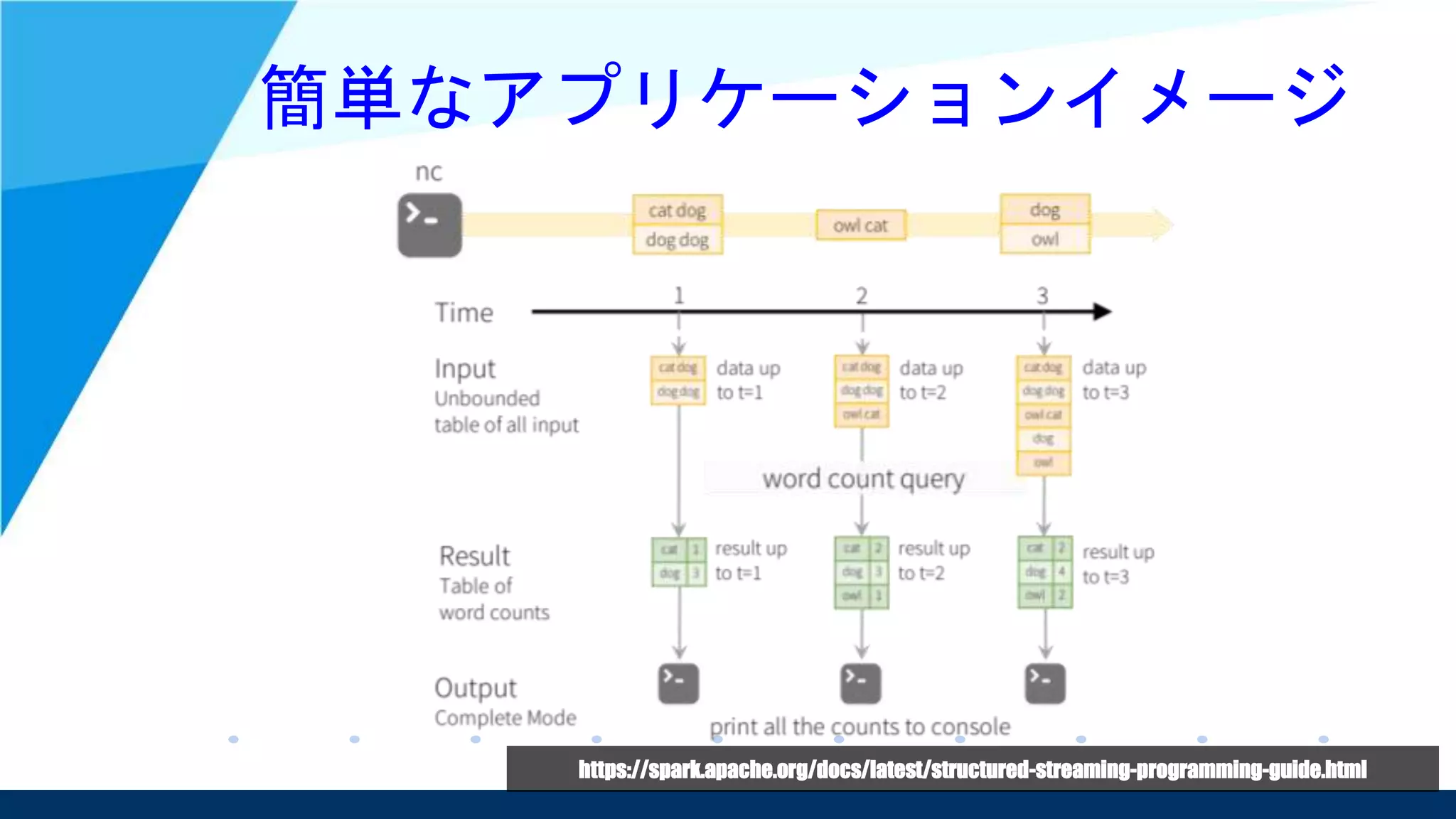
![簡単なアプリケーション例
// 入力データを単語毎に分割
val words = lines.as[String].flatMap(_.split(" "))
// 入力単語毎にカウント
val wordCounts = words.groupBy("value").count()
// 集計結果を毎回すべてコンソールに出力
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
// アプリケーションが外部から停止されるまで実行
query.awaitTermination()](https://image.slidesharecdn.com/20170804-170804100055/75/Modern-stream-processing-by-Spark-Structured-Streaming-36-2048.jpg)















![[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a34amazon-auroraamazondataservicejapan-150623010528-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[C23] 「今」を分析するストリームデータ処理技術とその可能性 by Takahiro Yokoyama](https://cdn.slidesharecdn.com/ss_thumbnails/c23hitachiyokoyama-131215225816-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)
























