はじめに
• この発表について
• 発表者について
•発表者が聞いてきたセッション一覧
Copyright (C) 2016 Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 4
5.
この発表について
• この発表では、 HadoopSummit 2016 San Joseで聞いてきた各種
ストリーム処理実行エンジンについて紹介します
Copyright (C) 2016 Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 5
発表者が聞いてきたセッション一覧
Monday June 27,2016
• Flink Meetup
Tuesday, June 28, 2016
• What the #$* is a Business
Catalog and Why You Need It!
• Streaming in the Wild with
Apache Flink
• Governed Self Service Analytics
at eBay
• Analysis of Major Trends in Big
Data Analytics
• H2O: A Platform for Big Math
• How to Build a Successful Data
Lake
• Instrument Your Instruments:
Data-Driven Ops
Wednesday, June 29, 2016
• Blink - Improved Runtime for
Flink and its Application in
Alibaba Search
• Scalable Realtime Analytics
using Druid
• Fine-Grained Security for Spark
and Hive
• Lambda-less Stream Processing
@ Scale in LinkedIn
Thursday, June 30, 2016
• The Future of Apache Storm
• Turning the Stream Processor
into a Database: Building
Online Applications on Streams
• Managing Hadoop, HBase, and
Storm Clusters at Yahoo Scale
• Next Gen Big Data Analytics
with Apache Apex
• Apache Beam: A Unified Model
for Batch and Streaming Data
Processing
• BoF: Streaming & Data Flow
Copyright (C) 2016 Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 7
Flink
Copyright (C) 2016Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 9
出所: https://www.youtube.com/watch?v=1JV5o5g30-k
• Streaming in the Wild with Apache Flink
10.
聞いてきたセッション
• Flink Meetup(前夜祭的なもの)
• Robust Stream Processing with Apache Flink
• Streaming in the Wild with Apache Flink
• Turning the Stream Processor into a Database: Building Online
Applications on Streams
• Blink Improved Runtime for Flink and its Application in Alibaba
Search
Copyright (C) 2016 Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 10
11.
FlinkはリカバリのためにStateを管理する実行モデル
Copyright (C) 2016Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 11
出所: http://www.slideshare.net/HadoopSummit/streaming-in-the-wild-with-apache-flink-63921696
12.
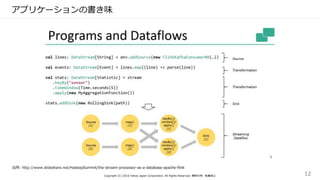
アプリケーションの書き味
Copyright (C) 2016Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 12
出所: http://www.slideshare.net/HadoopSummit/the-stream-processor-as-a-database-apache-flink
13.
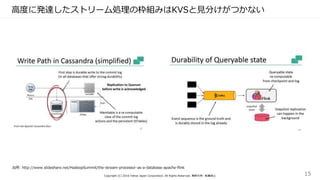
実現したいもの
• Exactly-once guarantees
•Low latency
• High throughput
• Powerful computation model
• Low overhead of the fault tolerance mechanism in the absence
of failures
• Flow control
出所: http://data-artisans.com/high-throughput-low-latency-and-exactly-once-stream-processing-with-apache-flink/
Copyright (C) 2016 Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 13
Storm vs Heron
•The Future of Apache Storm
Copyright (C) 2016 Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 20
出所: https://www.youtube.com/watch?v=_Q2uzRIkTd8
21.
Storm vs Heron
•Storm
– 2011/9のどこかでOSSとして公開される
– オリジナルはTwitterが開発
– Storm @Twitter SIGMOD’14 に詳細あり
• Heron
– 2015/6/2にTwitterのブログで存在が発表される
• https://blog.twitter.com/2015/flying-faster-with-twitter-
heron
– オリジナルはTwitterが開発
– Twitter Heron: Stream Processing at Scale SIGMOD’15 に詳細
あり
Copyright (C) 2016 Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 21
その他のフレームワーク
Copyright (C) 2016Yahoo Japan Corporation. All Rights Reserved. 無断引用・転載禁止 28
Samza
Apex
Beam/MillWheel
Cloud Dataflow
• 運用管理まわりがいけてるらしい
• See “Lambda-less Stream Processing @ Scale in LinkedIn”
• Partitionの動的最適化やアプリケーションの無停止アップグレー
ドがウリ
• See “Next Gen Big Data Analytics with Apache Apex”
• MillWheelが全ての原点といっていいほど参考にされている
• FlinkがMillWheelを超えている説も?
• See “Apache Beam: A Unified Model for Batch and Streaming Data
Processing”
Spark Streaming
• 自分の観測範囲ではDisられ侍だった
• 聞くところによるとClouderaのセッションではSpark
Streaming推しだった模様で、ベンダによっていろいろ事情が異
なるっぽい

















































































![[社内勉強会]春の嵐を巻き起こせ Storm補完計画](https://cdn.slidesharecdn.com/ss_thumbnails/storm-160304020110-thumbnail.jpg?width=640&height=640&fit=bounds)





































