Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Takanori Suzuki
PDF, PPTX
28,345 views
IoT時代におけるストリームデータ処理と急成長の Apache Flink
ビッグデータのリアルタイム処理技術勉強会 #futureofdata
Technology
◦
Read more
58
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 41
2
/ 41
3
/ 41
4
/ 41
5
/ 41
6
/ 41
7
/ 41
8
/ 41
9
/ 41
10
/ 41
11
/ 41
12
/ 41
13
/ 41
14
/ 41
15
/ 41
16
/ 41
17
/ 41
18
/ 41
19
/ 41
20
/ 41
21
/ 41
22
/ 41
23
/ 41
24
/ 41
25
/ 41
26
/ 41
27
/ 41
28
/ 41
29
/ 41
30
/ 41
31
/ 41
32
/ 41
33
/ 41
34
/ 41
35
/ 41
36
/ 41
37
/ 41
38
/ 41
39
/ 41
40
/ 41
41
/ 41
More Related Content
PDF
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
PDF
[GKE & Spanner 勉強会] Cloud Spanner の技術概要
by
Google Cloud Platform - Japan
PDF
SolrとElasticsearchを比べてみよう
by
Shinsuke Sugaya
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
[GKE & Spanner 勉強会] Cloud Spanner の技術概要
by
Google Cloud Platform - Japan
SolrとElasticsearchを比べてみよう
by
Shinsuke Sugaya
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
What's hot
PDF
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
PPT
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
PPTX
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性
by
Ohyama Masanori
PPTX
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
PDF
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PDF
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PDF
DockerとPodmanの比較
by
Akihiro Suda
PPTX
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
Apache Arrow - データ処理ツールの次世代プラットフォーム
by
Kouhei Sutou
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
ブレソルでテラバイト級データのALTERを短時間で終わらせる
by
KLab Inc. / Tech
PDF
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
PDF
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
PPTX
DockerコンテナでGitを使う
by
Kazuhiro Suga
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
監査要件を有するシステムに対する PostgreSQL 導入の課題と可能性
by
Ohyama Masanori
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
DockerとPodmanの比較
by
Akihiro Suda
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Apache Arrow - データ処理ツールの次世代プラットフォーム
by
Kouhei Sutou
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
ブレソルでテラバイト級データのALTERを短時間で終わらせる
by
KLab Inc. / Tech
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
DockerコンテナでGitを使う
by
Kazuhiro Suga
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
Similar to IoT時代におけるストリームデータ処理と急成長の Apache Flink
PDF
デブサミ2014-Stormで実現するビッグデータのリアルタイム処理プラットフォーム ~ストリームデータ処理から機械学習まで~
by
Takanori Suzuki
PPTX
StreamGraph
by
Altech Takeno
PDF
最近のストリーム処理事情振り返り
by
Sotaro Kimura
PDF
Dataworks Summit 2017 SanJose StreamProcessing - Hadoop Source Code Reading #...
by
Yahoo!デベロッパーネットワーク
PPT
S4
by
あしたのオープンソース研究所
PPTX
Modern stream processing by Spark Structured Streaming
by
Sotaro Kimura
PDF
リアルタイム処理エンジン Gearpumpの紹介
by
Sotaro Kimura
PPTX
Spark Structured Streaming with Kafka
by
Sotaro Kimura
PDF
Azure データサービスデザイン検討 (2015/10)
by
Koichiro Sasaki
PDF
マイニング探検会#10
by
Yoji Kiyota
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
Spark Streaming の基本とスケールする時系列データ処理 - Spark Meetup December 2015/12/09
by
MapR Technologies Japan
PDF
Data-Intensive Text Processing with MapReduce(Ch1,Ch2)
by
Sho Shimauchi
PPTX
Flumeを活用したAmebaにおける大規模ログ収集システム
by
Satoshi Iijima
PPTX
JVM上でのストリーム処理エンジンの変遷
by
Sotaro Kimura
PDF
Facebookのリアルタイム Big Data 処理
by
maruyama097
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
PDF
Spring3.1概要x di
by
Yuichi Hasegawa
PDF
なぜリアクティブは重要か #ScalaMatsuri
by
Yuta Okamoto
PDF
Akka stream
by
Masaki Toyoshima
デブサミ2014-Stormで実現するビッグデータのリアルタイム処理プラットフォーム ~ストリームデータ処理から機械学習まで~
by
Takanori Suzuki
StreamGraph
by
Altech Takeno
最近のストリーム処理事情振り返り
by
Sotaro Kimura
Dataworks Summit 2017 SanJose StreamProcessing - Hadoop Source Code Reading #...
by
Yahoo!デベロッパーネットワーク
S4
by
あしたのオープンソース研究所
Modern stream processing by Spark Structured Streaming
by
Sotaro Kimura
リアルタイム処理エンジン Gearpumpの紹介
by
Sotaro Kimura
Spark Structured Streaming with Kafka
by
Sotaro Kimura
Azure データサービスデザイン検討 (2015/10)
by
Koichiro Sasaki
マイニング探検会#10
by
Yoji Kiyota
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
Spark Streaming の基本とスケールする時系列データ処理 - Spark Meetup December 2015/12/09
by
MapR Technologies Japan
Data-Intensive Text Processing with MapReduce(Ch1,Ch2)
by
Sho Shimauchi
Flumeを活用したAmebaにおける大規模ログ収集システム
by
Satoshi Iijima
JVM上でのストリーム処理エンジンの変遷
by
Sotaro Kimura
Facebookのリアルタイム Big Data 処理
by
maruyama097
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
Spring3.1概要x di
by
Yuichi Hasegawa
なぜリアクティブは重要か #ScalaMatsuri
by
Yuta Okamoto
Akka stream
by
Masaki Toyoshima
More from Takanori Suzuki
PDF
SORACOM S+Cameraを利用して在庫チェックをやってみた
by
Takanori Suzuki
PDF
Karateによる UI Test Automation 革命
by
Takanori Suzuki
PDF
人生がときめくAPIテスト自動化 with Karate
by
Takanori Suzuki
PDF
マイクロサービスにおけるテスト自動化 with Karate
by
Takanori Suzuki
PDF
ServerlessConf Tokyo2018 サーバーレスなシステムのがんばらない運用監視
by
Takanori Suzuki
PDF
SQiP2012 - 質問表の活用によるプロジェクトの早期リスク検出
by
Takanori Suzuki
DOC
5WCSQ(CFP) - Quality Improvement by the Real-Time Detection of the Problems
by
Takanori Suzuki
DOC
5WCSQ(CFP) - Quality Improvement by the Real-Time Detection of the Problems
by
Takanori Suzuki
PDF
5WCSQ - Quality Improvement by the Real-Time Detection of the Problems
by
Takanori Suzuki
SORACOM S+Cameraを利用して在庫チェックをやってみた
by
Takanori Suzuki
Karateによる UI Test Automation 革命
by
Takanori Suzuki
人生がときめくAPIテスト自動化 with Karate
by
Takanori Suzuki
マイクロサービスにおけるテスト自動化 with Karate
by
Takanori Suzuki
ServerlessConf Tokyo2018 サーバーレスなシステムのがんばらない運用監視
by
Takanori Suzuki
SQiP2012 - 質問表の活用によるプロジェクトの早期リスク検出
by
Takanori Suzuki
5WCSQ(CFP) - Quality Improvement by the Real-Time Detection of the Problems
by
Takanori Suzuki
5WCSQ(CFP) - Quality Improvement by the Real-Time Detection of the Problems
by
Takanori Suzuki
5WCSQ - Quality Improvement by the Real-Time Detection of the Problems
by
Takanori Suzuki
IoT時代におけるストリームデータ処理と急成長の Apache Flink
1.
2016/10/25 Acroquest Technology 株式会社 鈴木
貴典 ビッグデータのリアルタイム処理技術勉強会 #futureofdata
2.
Copyright © Acroquest
Technology Co., Ltd. All rights reserved. 2 自己紹介 所属 • Acroquest Technology Co., Ltd. • 「働きがいのある会社」(GPTW) 従業員25~99人部門 2年連続1位 主な業務分野 • テクニカルアーキテクト • SEPG • IoTサービス開発 • ビッグデータ処理プラットフォーム 最近の興味 • サーバーレス • DevOps • Elasticsearch 鈴木 貴典 Twitter : @takanorig Qiita : http://qiita.com/takanorig
3.
Copyright © Acroquest
Technology Co., Ltd. All rights reserved. 3 本日お話する内容 #1 ビッグデータ × リアルタイム #2 ストリームデータ処理エンジン #3 ストリームデータ処理のシステムアーキテクチャ
4.
Copyright © Acroquest
Technology Co., Ltd. All rights reserved. 4 ビッグデータ × リアルタイム
5.
1. IoTでのデータの扱いの変化 Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 5 2016年 229億デバイス
6.
1. IoTでのデータの扱いの変化 Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 6 × 重要なのは デバイス数の増加ではない
7.
1. IoTでのデータの扱いの変化 Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 7 新しいビジネスの ニーズへの対応 全量分析による AIの活用 データの 即時有効活用 過去は、リアルタイムの 情報は、サンプリングで しか扱えなかった。 IoTにより、利用できる情報 が増え、全量分析すること で、リアルタイムで、 精度の高い学習・活用が 可能になった。 生データをそのまま蓄積する のではなく、様々な手段で 読み書きできる状態で保管 する「データレイク」の 考え方が広まっている。 そのためには、リアルタイム にデータを加工・変換してい く必要がある。 リアルタイムリコメンド、 セキュリティリスクの検知、 防災・異常検知、 など、時間によってコスト や人命への影響が大きい 内容に関するニーズが 増えてきた。
8.
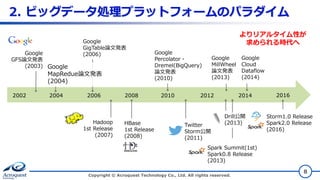
2. ビッグデータ処理プラットフォームのパラダイム Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 8 2002 2004 2006 2008 2010 2012 2014 Google GFS論文発表 (2003) Google GigTable論文発表 (2006) Google MapRedue論文発表 (2004) Google Percolator・ Dremel(BigQuery) 論文発表 (2010) Twitter Storm公開 (2011) Hadoop 1st Release (2007) HBase 1st Release (2008) よりリアルタイム性が 求められる時代へ 2016 Spark Summit(1st) Spark0.8 Release (2013) Drill公開 (2013) Storm1.0 Release Spark2.0 Release (2016) Google MillWheel 論文発表 (2013) Google Cloud Dataflow (2014)
9.
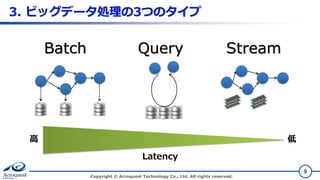
3. ビッグデータ処理の3つのタイプ Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 9 Batch StreamQuery 高 低 Latency
10.
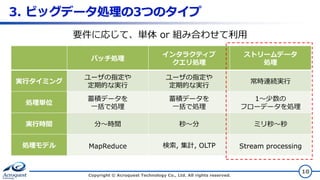
3. ビッグデータ処理の3つのタイプ Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 10 バッチ処理 インタラクティブ クエリ処理 ストリームデータ 処理 実行タイミング ユーザの指定や 定期的な実行 ユーザの指定や 定期的な実行 常時連続実行 処理単位 蓄積データを 一括で処理 蓄積データを 一括で処理 1~少数の フローデータを処理 実行時間 分~時間 秒~分 ミリ秒~秒 処理モデル MapReduce 検索, 集計, OLTP Stream processing 要件に応じて、単体 or 組み合わせて利用
11.
3. ビッグデータ処理の3つのタイプ Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 11 バッチ処理 インタラクティブ クエリ処理 ストリームデータ 処理 タイプごとの代表的なプロダクト Apache Storm Apache Spark Streaming Hadoop CDH Cloudera's Distribution Including Apache Hadoop Apache Drill Cloudera Impala Facebook Presto Spark HDP Hortonworks Data Platform CDP Converged Data Platform Tez Apache Flink Elastic Elasticsearch
12.
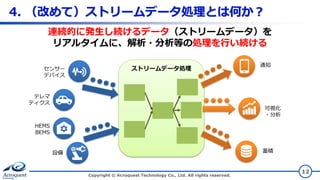
4. (改めて)ストリームデータ処理とは何か? Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 12 連続的に発生し続けるデータ(ストリームデータ)を リアルタイムに、解析・分析等の処理を行い続ける センサー デバイス テレマ ティクス HEMS BEMS ストリームデータ処理 設備 通知 可視化 ・分析 蓄積
13.
5. ストリームデータ処理エンジンに求められる要素 Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 13 1. Low Latency & High Throughput 低レイテンシ、高スループット イベント到着から数十~数百ミリ秒のレイテンシで、毎秒、数十~数百万の処理を要求され ることがあり、低レイテンシ、高スループットを実現する必要がある。 2. Scalable スケーラブル 複数ノードで構成されるクラスタ上で、並列分散的に動作し、膨大な数のメッセージに対し ても低レイテンシを維持しつつ、水平スケールする。 3. Fault tolerant 耐障害性 障害が発生し、処理中のノードがダウンした場合でも、必要に応じてタスクの再割り当てや ノードの再起動を行い、処理が完全に停止してしまうようなことがない。
14.
5. ストリームデータ処理エンジンに求められる要素 Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 14 4. Message guarantees メッセージ到達性保証 何らかの理由により、イベントの処理に失敗したり、タイムアウトが発生したりした場合で も、それを検知し、再処理するしくみが必要となる。エンジンによって、サポートする信頼 性のレベルは異なるが、すべてのイベントが処理されることを担保可能とする。 5. Flow Control フロー制御 データの流れを許可したり、禁止したりすることが可能であること。エンジンで処理した結 果のデータを受信する側で、処理が間に合わない場合に、データの送信をエンジン側で止め られることを指す。TCP/IPのパケット通信に用いられている制御方式である。 現時点では、Backpressureの機構が用いられることが多い。 6. Windowing ウィンドウ処理 ストリームデータを、一定の区間で区切り、単一のイベントではなく、複数のイベントに対 して処理を行う。過去のイベントと比較したり、集計等の演算をするのに有用な機能であり、 エンジン自体でサポートするケースが増えている。
15.
【5. ストリームデータ処理エンジンに求められる要素】 5-1. メッセージ処理モデル Copyright
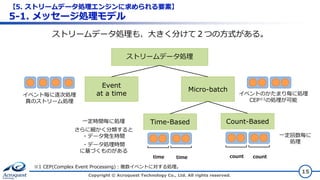
© Acroquest Technology Co., Ltd. All rights reserved. 15 ストリームデータ処理 Event at a time Micro-batch Time-Based Count-Based ストリームデータ処理も、大きく分けて2つの方式がある。 イベント毎に逐次処理 真のストリーム処理 イベントのかたまり毎に処理 CEP※1の処理が可能 time time count count 一定時間毎に処理 さらに細かく分類すると ・データ発生時間 ・データ処理時間 に基づくものがある 一定回数毎に 処理 ※1 CEP(Complex Event Processing):複数イベントに対する処理。
16.
【5. ストリームデータ処理エンジンに求められる要素】 5-2. メッセージ到達性保証 Copyright
© Acroquest Technology Co., Ltd. All rights reserved. 16 At most once (0回もしくは1回) At least once (少なくとも1回) Exactly once (正確に1回) 損失するかも 損失しない 損失しない 重複しない 重複するかも 重複しない 信頼性 性能 低 高 高 低 信頼性レベルに応じて、3つの分類がある。 エンジンによって、どのレベルをサポートしているかは異なる。
17.
【5. ストリームデータ処理エンジンに求められる要素】 5-3. Backpressure Copyright
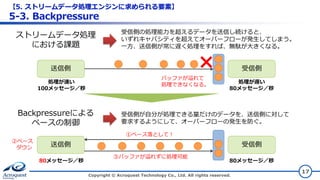
© Acroquest Technology Co., Ltd. All rights reserved. 17 送信側 受信側× バッファが溢れて 処理できなくなる。 処理が速い 100メッセージ/秒 処理が遅い 80メッセージ/秒 送信側 受信側 ③バッファが溢れずに処理可能 80メッセージ/秒 80メッセージ/秒 ①ペース落として! ②ペース ダウン ストリームデータ処理 における課題 受信側の処理能力を超えるデータを送信し続けると、 いずれキャパシティを超えてオーバーフローが発生してしまう。 一方、送信側が常に遅く処理をすれば、無駄が大きくなる。 Backpressureによる ペースの制御 受信側が自分が処理できる量だけのデータを、送信側に対して 要求するようにして、オーバーフローの発生を防ぐ。
18.
【5. ストリームデータ処理エンジンに求められる要素】 5-4. ウィンドウ処理 Copyright
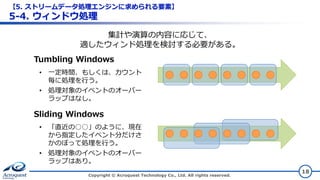
© Acroquest Technology Co., Ltd. All rights reserved. 18 Tumbling Windows Sliding Windows 集計や演算の内容に応じて、 適したウィンド処理を検討する必要がある。 • 一定時間、もしくは、カウント 毎に処理を行う。 • 処理対象のイベントのオーバー ラップはなし。 • 「直近の○○」のように、現在 から指定したイベント分だけさ かのぼって処理を行う。 • 処理対象のイベントのオーバー ラップはあり。
19.
Copyright © Acroquest
Technology Co., Ltd. All rights reserved. 19 ストリームデータ処理 エンジン
20.
1. ストリームデータ処理エンジンの戦国時代 Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 20 2011 2012 2013 2014 2015 2016 Storm 0.5 Spark Streaming 0.7 Flink 0.6 samza 0.7 Apex 3.2 Gearpump 0.8 Ignite 1.0 Beam 0.1 2014年以降、新プロダクトのリリースや、 有償プロダクトのOSS化により競争激化 Heron 0.13
21.
1. ストリームデータ処理エンジンの戦国時代 Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 21 現時点では以下の3つがメジャーな存在となっている
22.
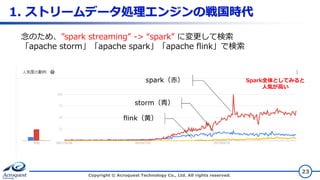
1. ストリームデータ処理エンジンの戦国時代 Copyright ©
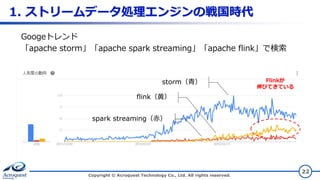
Acroquest Technology Co., Ltd. All rights reserved. 22 Googeトレンド 「apache storm」「apache spark streaming」「apache flink」で検索 storm(青) flink(黄) spark streaming(赤) Flinkが 伸びてきている
23.
1. ストリームデータ処理エンジンの戦国時代 Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 23 念のため、”spark streaming” -> “spark” に変更して検索 「apache storm」「apache spark」「apache flink」で検索 storm(青) flink(黄) spark(赤) Spark全体としてみると 人気が高い
24.
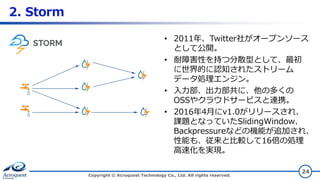
2. Storm Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 24 • 2011年、Twitter社がオープンソース として公開。 • 耐障害性を持つ分散型として、最初 に世界的に認知されたストリーム データ処理エンジン。 • 入力部、出力部共に、他の多くの OSSやクラウドサービスと連携。 • 2016年4月にv1.0がリリースされ、 課題となっていたSlidingWindow、 Backpressureなどの機能が追加され、 性能も、従来と比較して16倍の処理 高速化を実現。
25.
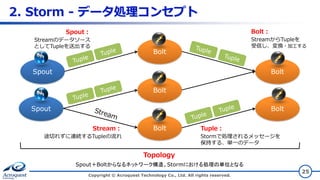
2. Storm -
データ処理コンセプト Copyright © Acroquest Technology Co., Ltd. All rights reserved. 25 Spout Spout Bolt Bolt Bolt Bolt Bolt Topology Spout: Streamのデータソース としてTupleを送出する Bolt: StreamからTupleを 受信し、変換・加工する Tuple: Stormで処理されるメッセージを 保持する、単一のデータ Stream: 途切れずに連続するTupleの流れ Spout+Boltからなるネットワーク構造。Stormにおける処理の単位となる
26.
2. Storm -
Word Count Exampe Copyright © Acroquest Technology Co., Ltd. All rights reserved. 26 TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new RandomSentenceSpout(), 5); builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout"); builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word")); Config conf = new Config(); conf.setNumWorkers(3); StormSubmitter.submitTopology(args[0], conf, builder.createTopology()); ※一部
27.
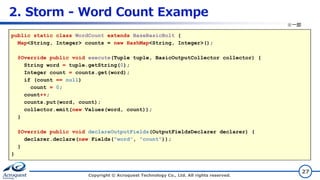
2. Storm -
Word Count Exampe Copyright © Acroquest Technology Co., Ltd. All rights reserved. 27 public static class WordCount extends BaseBasicBolt { Map<String, Integer> counts = new HashMap<String, Integer>(); @Override public void execute(Tuple tuple, BasicOutputCollector collector) { String word = tuple.getString(0); Integer count = counts.get(word); if (count == null) count = 0; count++; counts.put(word, count); collector.emit(new Values(word, count)); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word", "count")); } } ※一部
28.
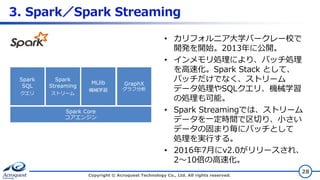
3. Spark/Spark Streaming Copyright
© Acroquest Technology Co., Ltd. All rights reserved. 28 Spark Core コアエンジン Spark SQL クエリ Spark Streaming ストリーム MLlib 機械学習 GraphX グラフ分析 • カリフォルニア大学バークレー校で 開発を開始。2013年に公開。 • インメモリ処理により、バッチ処理 を高速化。Spark Stack として、 バッチだけでなく、ストリーム データ処理やSQLクエリ、機械学習 の処理も可能。 • Spark Streamingでは、ストリーム データを一定時間で区切り、小さい データの固まり毎にバッチとして 処理を実行する。 • 2016年7月にv2.0がリリースされ、 2~10倍の高速化。
29.
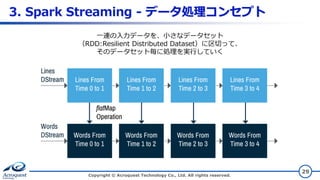
3. Spark Streaming
- データ処理コンセプト Copyright © Acroquest Technology Co., Ltd. All rights reserved. 29 一連の入力データを、小さなデータセット (RDD:Resilient Distributed Dataset)に区切って、 そのデータセット毎に処理を実行していく
30.
3. Spark Streaming
- Word Count Exampe Copyright © Acroquest Technology Co., Ltd. All rights reserved. 30 JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999); JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { @Override public Iterable<String> call(String x) { return Arrays.asList(x.split(" ")); } }); JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String s) { return new Tuple2<String, Integer>(s, 1); } }); JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey( new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer i1, Integer i2) { return i1 + i2; } });
31.
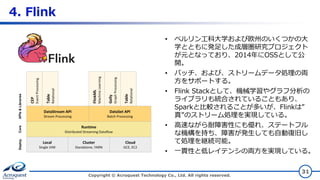
4. Flink Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 31 • ベルリン工科大学および欧州のいくつかの大 学とともに発足した成層圏研究プロジェクト が元となっており、2014年にOSSとして公 開。 • バッチ、および、ストリームデータ処理の両 方をサポートする。 • Flink Stackとして、機械学習やグラフ分析の ライブラリも統合されていることもあり、 Sparkと比較されることが多いが、Flinkは” 真”のストリーム処理を実現している。 • 高速ながら耐障害性にも優れ、ステートフル な機構を持ち、障害が発生しても自動復旧し て処理を継続可能。 • 一貫性と低レイテンシの両方を実現している。
32.
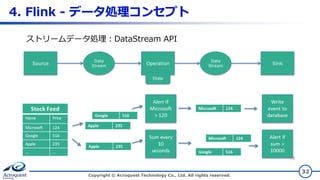
4. Flink -
データ処理コンセプト Copyright © Acroquest Technology Co., Ltd. All rights reserved. 32 Data Stream Operation Data Stream Source Sink State ストリームデータ処理:DataStream API
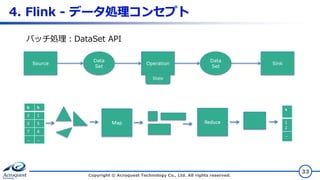
33.
4. Flink -
データ処理コンセプト Copyright © Acroquest Technology Co., Ltd. All rights reserved. 33 バッチ処理:DataSet API Data Set Operation Data Set Source Sink State
34.
4. Flink -
Word Count Exampe Copyright © Acroquest Technology Co., Ltd. All rights reserved. 34 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> text = env.readTextFile(textPath); DataStream<Tuple2<String, Integer>> counts = text.map(line -> line.toLowerCase().split("¥¥W+")) .flatMap((String[] tokens, Collector<Tuple2<String, Integer>> out) -> { Arrays.stream(tokens) .filter(t -> t.length() > 0) .forEach(t -> out.collect(new Tuple2<>(t, 1))); }) .keyBy(0) .sum(1);
35.
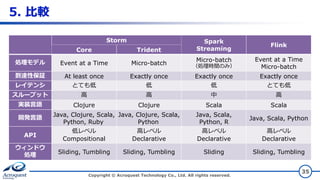
5. 比較 Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 35 Storm Spark Streaming Flink Core Trident 処理モデル Event at a Time Micro-batch Micro-batch (処理時間のみ) Event at a Time Micro-batch 到達性保証 At least once Exactly once Exactly once Exactly once レイテンシ とても低 低 低 とても低 スループット 高 高 中 高 実装言語 Clojure Clojure Scala Scala 開発言語 Java, Clojure, Scala, Python, Ruby Java, Clojure, Scala, Python Java, Scala, Python, R Java, Scala, Python API 低レベル Compositional 高レベル Declarative 高レベル Declarative 高レベル Declarative ウィンドウ 処理 Sliding, Tumbling Sliding, Tumbling Sliding Sliding, Tumbling
36.
Copyright © Acroquest
Technology Co., Ltd. All rights reserved. 36 ストリームデータ処理の システムアーキテクチャ
37.
1. 検討ポイント Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 37 ① 大量データの収集方法 • Pull or Push、プロトコル、データ形式 ② 増減するストリームデータへの対応 • ピーク性能、時間のズレに対する配慮 ③ 分散処理、および、分散の単位 • 集約キーの設計、集計、ウィンドウ処理、データ欠損への配慮 ④ 中間データの扱い • マスタデータ、一時データ ⑤ 運用 • ログの管理、ノードの管理、モニタリング、障害対応
38.
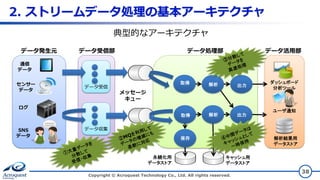
解析結果用 データストア ダッシュボード 分析ツール ユーザ通知 2. ストリームデータ処理の基本アーキテクチャ Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 38 センサー データ ログ データ受信 メッセージ キュー 通信 データ データ発生元 SNS データ データ受信部 データ処理部 データ収集 永続化用 データストア 取得 解析 出力 出力取得 保存 解析 キャッシュ用 データストア データ活用部 典型的なアーキテクチャ
39.
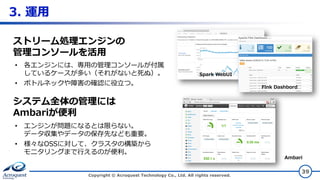
3. 運用 Copyright ©
Acroquest Technology Co., Ltd. All rights reserved. 39 • エンジンが問題になるとは限らない。 データ収集やデータの保存先なども重要。 • 様々なOSSに対して、クラスタの構築から モニタリングまで行えるのが便利。 システム全体の管理には Ambariが便利 ストリーム処理エンジンの 管理コンソールを活用 • 各エンジンには、専用の管理コンソールが付属 しているケースが多い(それがないと死ぬ)。 • ボトルネックや障害の確認に役立つ。 Spark WebUI Fink Dashbord Ambari
40.
Copyright © Acroquest
Technology Co., Ltd. All rights reserved. 40 本日のまとめ 1. ストリームデータ処理エンジンに求められる内容も高機能になってきている。 ① スケーラブル、耐障害性は必須になっている。 ② Backpressureによるフロー制御、ウィンドウ処理なども必要性が高い。 2. ストリーム処理エンジンは、戦国時代になっている。 ① Storm、Spark Streaming、Flinkが代表格。 ② Spark、Flink は、バッチとストリームの両方をサポートし、かつ、 クエリ処理や機械学習などのエコシステムを統合して提供しているのは有用。 ③ どれを利用するかは、そのエンジンの特性や強みを理解して選ぶしかない。 3. エンジンだけでなくシステム全体のアーキテクチャを考慮しよう。 ① データ収集やキュー処理、データの永続化など、一連の流れを検討する必要がある。 ② 運用のツールも揃ってきているので、うまく活用しよう。
41.
Copyright © Acroquest
Technology Co., Ltd. All rights reserved. 42 Thank you Infrastructures Evolution
Download
















![2. Storm - Word Count Exampe
Copyright © Acroquest Technology Co., Ltd. All rights reserved.
26
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
※一部](https://image.slidesharecdn.com/20161025iotapacheflink-161025113132/85/IoT-Apache-Flink-26-320.jpg)

![4. Flink - Word Count Exampe
Copyright © Acroquest Technology Co., Ltd. All rights reserved.
34
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile(textPath);
DataStream<Tuple2<String, Integer>> counts =
text.map(line -> line.toLowerCase().split("¥¥W+"))
.flatMap((String[] tokens, Collector<Tuple2<String, Integer>> out) -> {
Arrays.stream(tokens)
.filter(t -> t.length() > 0)
.forEach(t -> out.collect(new Tuple2<>(t, 1)));
})
.keyBy(0)
.sum(1);](https://image.slidesharecdn.com/20161025iotapacheflink-161025113132/85/IoT-Apache-Flink-34-320.jpg)









![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)











