Downloaded 29 times



![Vertica Cluster
MPP Relational
Data Warehouse
Native &
External
Tables
Confluent™ REST Proxy
JSON/AVRO Messages
HDFS/Hive/
ORC/Parquet
Structured
Non-relational
HDFS
/RAW/Topic/YYYY/
MM/DD/HH
Semi-
Structured
Data
OpenTSDB
HBase
Raw Data Topics in JSON, AVRO, Protobuf, Delimited, Byte[]
Processed/Transformed Data Topics
Web,
Mobile,
IoT
DBMS
Applications
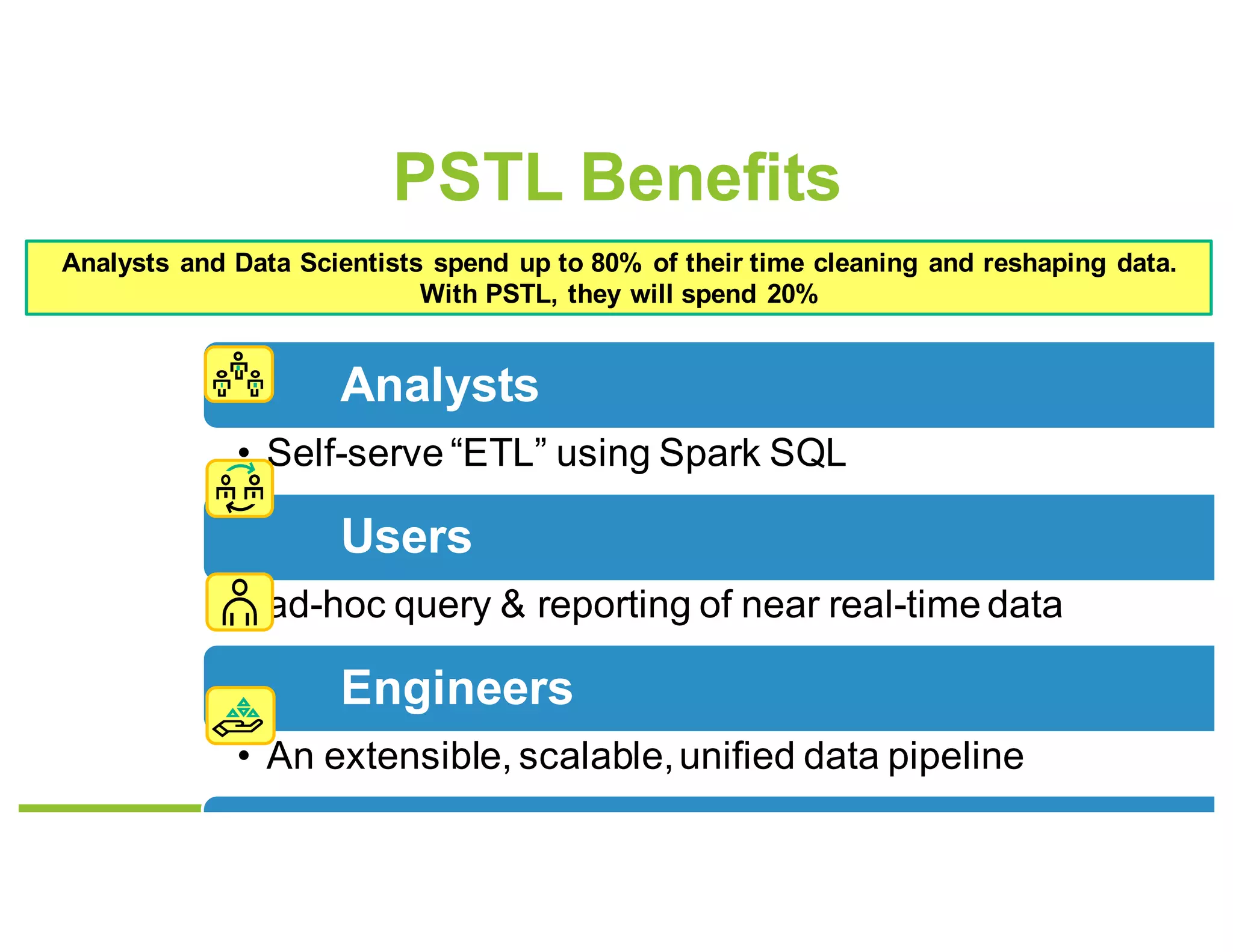
Parallel Streaming Transformation Loader
Hadoop™ Spark™ Cluster
Custom
Extensions
PSTL
CDC/SDC
Kafka™
Cluster
Centralized Data Hub
Libhdfs++
Sinks
Vertica, Hive,
OpenTSDB, Kafka, …](https://image.slidesharecdn.com/148jackgudenkauf-170615211157/75/Structured-Streaming-for-Columnar-Data-Warehouses-with-Jack-Gudenkauf-5-2048.jpg)
![job {
structured-streaming {
sources {
logs {
format= kafka
options {
kafka.bootstrap.servers = "kafka:9092"
subscribe = kafkatopic
} } }
transforms = """
CREATE TEMPORARY VIEW transform01 AS
SELECT topic, partition, offset,timestamp,
split(cast(value as string),'|') values
FROM logs;
CREATE TEMPORARY VIEW transform02 AS
SELECT vhash(values[0] ,values[1]) uniqueKey,
values[0] col0,values[1] col1
FROM transform01; """
sinks {
store_vertica {
format= vertica
dependsOn = transform02
options {
vertica.url = "jdbc:vertica://vertica:5433/db"
vertica.table = "public.logs"
vertica.property.user = dbadmin
vertica.property.password = changeMe!
kafka.topic = vertica-logs
kafka.property.bootstrap.servers = "kafka:9092"
} } } } }
We also support static sources (e.g., hdfs) refreshed on time intervals
Additional sinks
Kafka, S3, hdfs (ORC, Parquet), OpenTSDB/Hbase, console, …
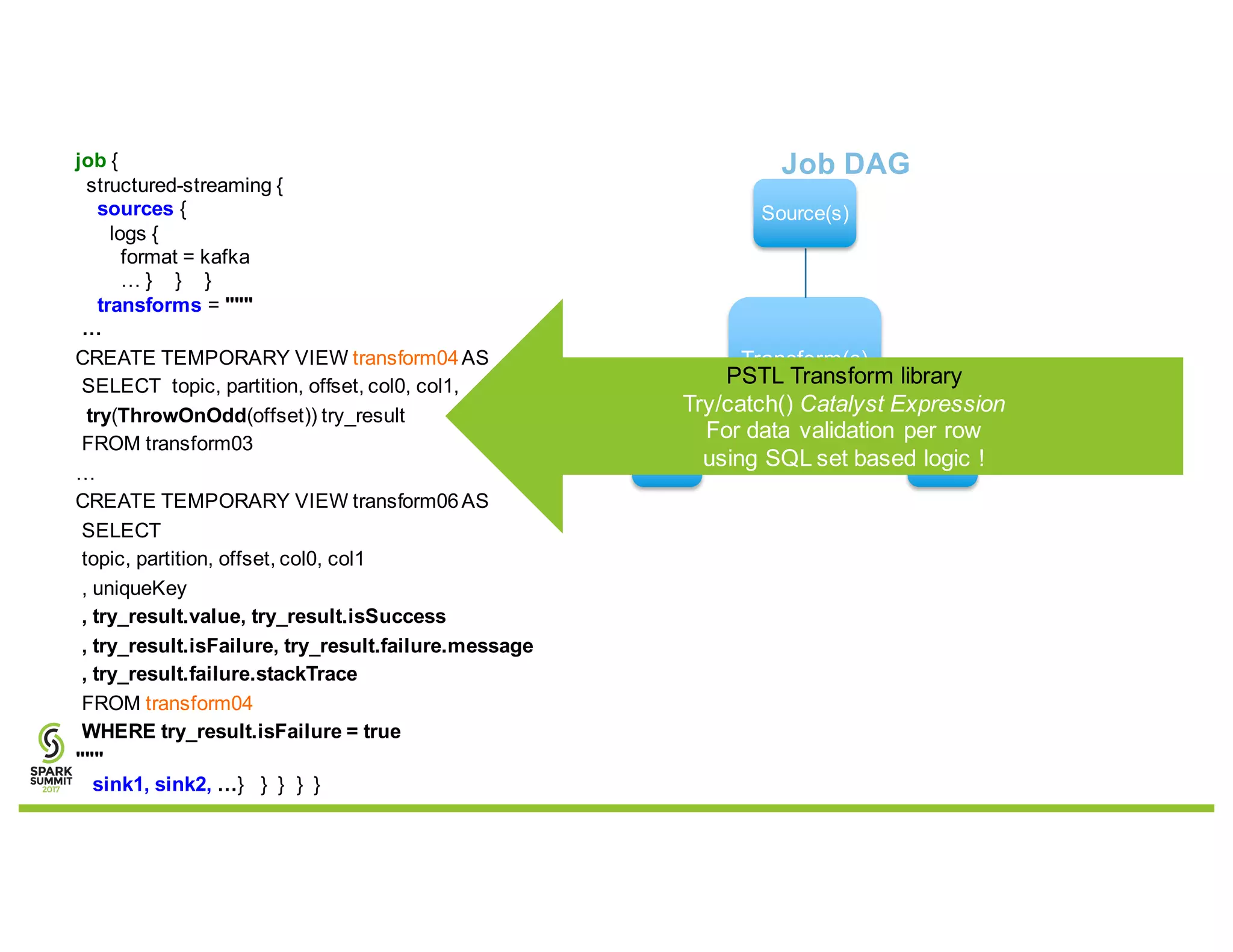
Additional Transforms (Catalyst Expressions)
fprotobuf(), favro(), fconfluent(), fJSON()
tavro(), try(), vhash(vertica hash), hive udf(), …
bin/pstl-jobs --initial-contacts 127.0.0.1:2552
--start --job-id job.conf
Each job is a simple config file of Sources, Transforms & Sinks](https://image.slidesharecdn.com/148jackgudenkauf-170615211157/75/Structured-Streaming-for-Columnar-Data-Warehouses-with-Jack-Gudenkauf-6-2048.jpg)
![job {
structured-streaming {
sources {
logs { format = kafka … } } }
transforms = """
CREATE TEMPORARY VIEW transform01AS
SELECT
topic, partition, offset, kafkaMsgCreatedAt
, structCol.*, posexplode(anArray)
FROM (
SELECT
topic, partition, offset, timestamp as kafkaMsgCreatedAt,
favro('{"type":"record","name":"testAllAvroData","namespace":"com.mynamespace","fields":[{"name":"c1_nul
l","type":["null","string"]},…
,{"name":"anArray","type":{"type":"array","items":{"type":"record","name":"anArray","fields":[{"name":"a_name
","type":"string”…’
, value) as structCol
FROM logs)
"””
sinks …} } } } }](https://image.slidesharecdn.com/148jackgudenkauf-170615211157/75/Structured-Streaming-for-Columnar-Data-Warehouses-with-Jack-Gudenkauf-8-2048.jpg)




The document outlines a solution called PSTL (Parallel Streaming Transformation Loader) for structured streaming in big data that aims to simplify ETL processes for analysts and data scientists, allowing them to focus more on analysis rather than data cleaning. It highlights the key benefits, features, and architecture of PSTL, including its no-code approach, observability, and support for various data formats and sinks. The document also provides details on how to configure jobs using PSTL for efficient data transformation and loading.





































































![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)
